이미지 분류 대회
6주차와 7주차, 2주에 걸쳐 이미지 분류 (Image Classification) 대회가 진행되었다. 대회 형식으로 진행되기는 하였지만 캠퍼들이 현재까지 배운 내용들을 모두 활용하여 직접 데이터를 만져보며 이미지 분류 모델을 만드는 실습을 해보는 기간을 준 것 같다.
데이터 개요

마스크를 착용하는 건 COIVD-19의 확산을 방지하는데 중요한 역할을 합니다. 제공되는 이 데이터셋은 사람이 마스크를 착용하였는지 판별하는 모델을 학습할 수 있게 해줍니다. 모든 데이터셋은 아시아인 남녀로 구성되어 있고 나이는 20대부터 70대까지 다양하게 분포하고 있습니다. 간략한 통계는 다음과 같습니다.
전체 사람 명 수 : 4,500
한 사람당 사진의 개수: 7 [마스크 착용 5장, 이상하게 착용(코스크, 턱스크) 1장, 미착용 1장]
이미지 크기: (384, 512)
전체 데이터셋 중에서 60%는 학습 데이터셋으로 활용됩니다.
입력값. 마스크 착용 사진, 미착용 사진, 혹은 이상하게 착용한 사진(코스크, 턱스크)
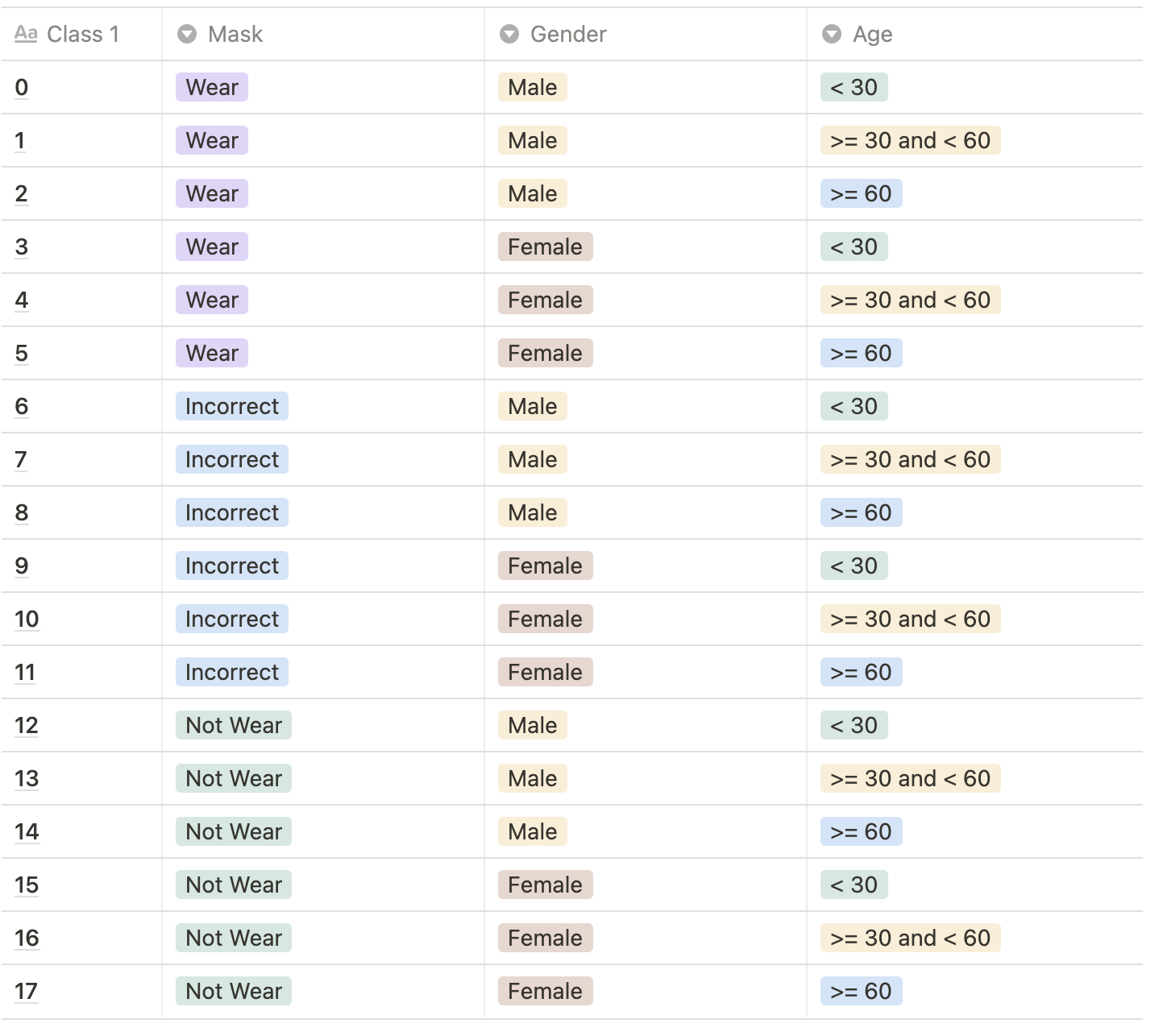
결과값. 총 18개의 class를 예측해야합니다. 결과값으로 0~17에 해당되는 숫자가 각 이미지 당 하나씩 나와야합니다.
Class Description:
마스크 착용여부, 성별, 나이를 기준으로 총 18개의 클래스가 있습니다.
기획
우리 팀은 이번 프로젝트를 수행함에 있어 분류해야하는 task는 크게 세 분류로 나누어지며 세부적으로 18개로의 클래스로 구분되므로, 한 개의 모델로 동시에 3개의 task를 수행해 내는 것에 어려움이 존재할 것으로 생각했다. 이에 따라, 큰 분류인 마스크 착용 상태, 연령대, 성별로 모델을 분리하여 개발을 진행하기로 결정하였다.
Age Classification
나는 마스크 착용 여부, 성별, 나이 분류의 3가지 task 중에서 나이 분류 task를 담당했다.
사진 속 인물들을 각각 30세 미만, 30세 이상 60세 미만, 60세 이상의 세 class로 분류한다.
EDA
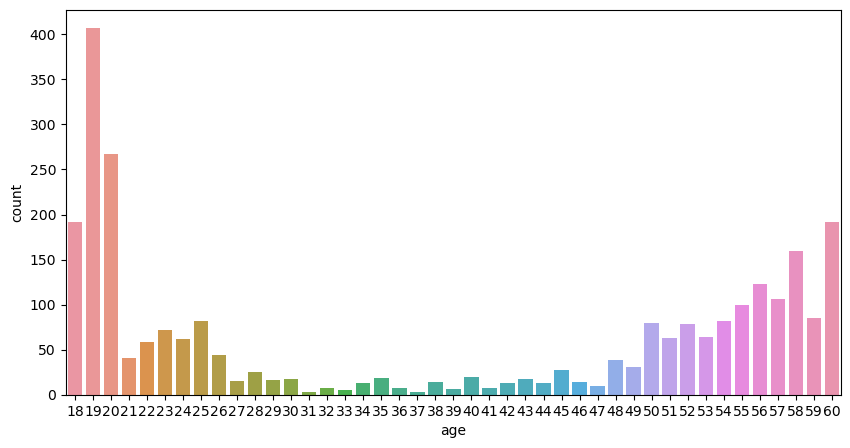
데이터의 나이 분포를 알아보기 위해 EDA를 진행하였다.
- 데이터 전체 나이 분포
- 각 클래스별 분포
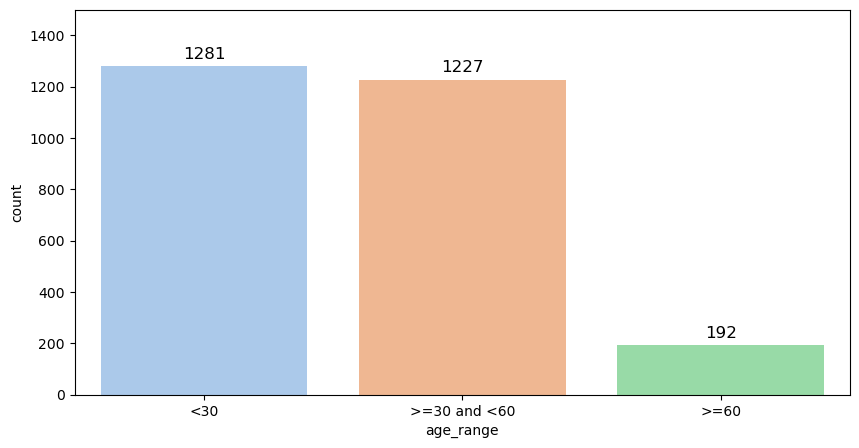
각 클래스 별 분포를 보면 알 수 있듯 데이터 불균형이 굉장히 심하다. 나이 class 분류에 있어서 이 불균형을 잘 해결하는 것이 주된 문제로 생각하고 진행하였다.
Criterion 선정
데이터의 클래스 불균형이 심해 Cross Entropy Loss 보다는 F1-Loss나 Focal Loss를 사용하기로 결정하였다. 또한, 대회의 평가 방식이 F1-score를 기준이기 때문에 최종 Criterion으로 F1-Loss를 사용하였다.
모델 선정
베이스라인 코드를 기준으로 그 어떤 수정도 하지 않고 pretrained 모델만 바꿔가며 성능 테스트를 해보았다.
- ResNet50, ResNet152, EfficientNetB0, VGG19 모델 비교
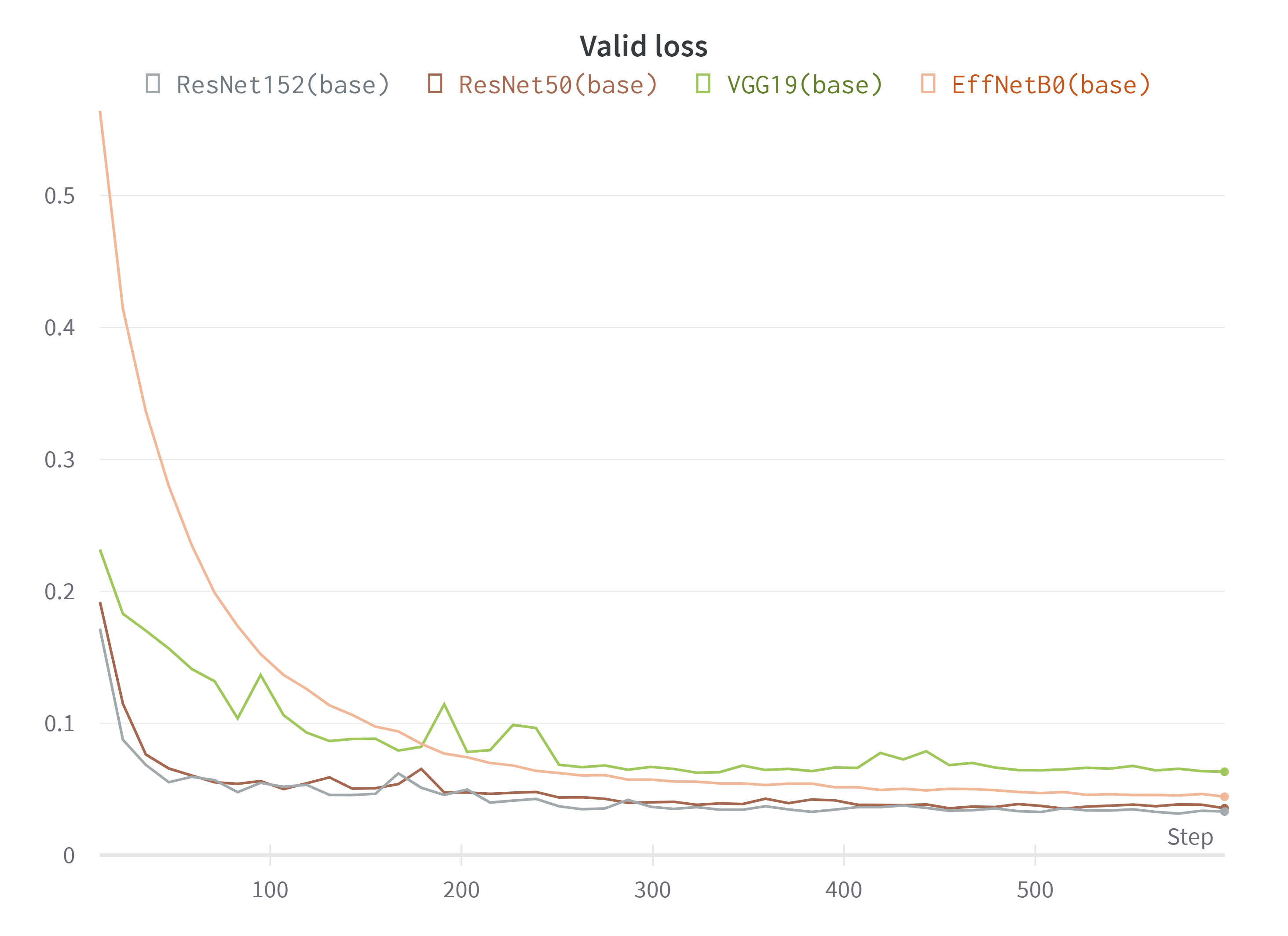
F1-Loss 기준 ResNet50과 ResNet152가 가장 낮은 Loss 값을 보여줬기에 ResNet을 사용해보기로 하였다. 깊이가 깊은 모델인 만큼 이미지의 세세한 부분의 feature들까지 잡아내어 인물의 주름과 같은 얼굴의 특성들을 잘 학습한 것 같다. ResNet152의 모델 사이즈가 커 한 번 학습을 시키는데 긴 시간이 걸려 비교를 위한 실험을 할 시에 ResNet50을 활용하기도 하였다.
Image Input Size 선정
사진을 보고 나이를 추정 할 수 있는 가장 큰 요인은 주름이라고 생각했다. 그래서 주름의 feature를 잘 잡아내도록 학습하는 것이 중요하다고 생각했고 그러기 위해서는 입력 이미지의 해상도를 높여볼 필요가 있다고 생각했다. BaseLine에서 제시한 [128, 96]의 size 대신 height와 width를 각각 2배씩 늘린 [256, 192]의 size로 학습을 시켜보았다.
- ResNet50과 ResNet152의 input size에 따른 Valid Loss 값 비교
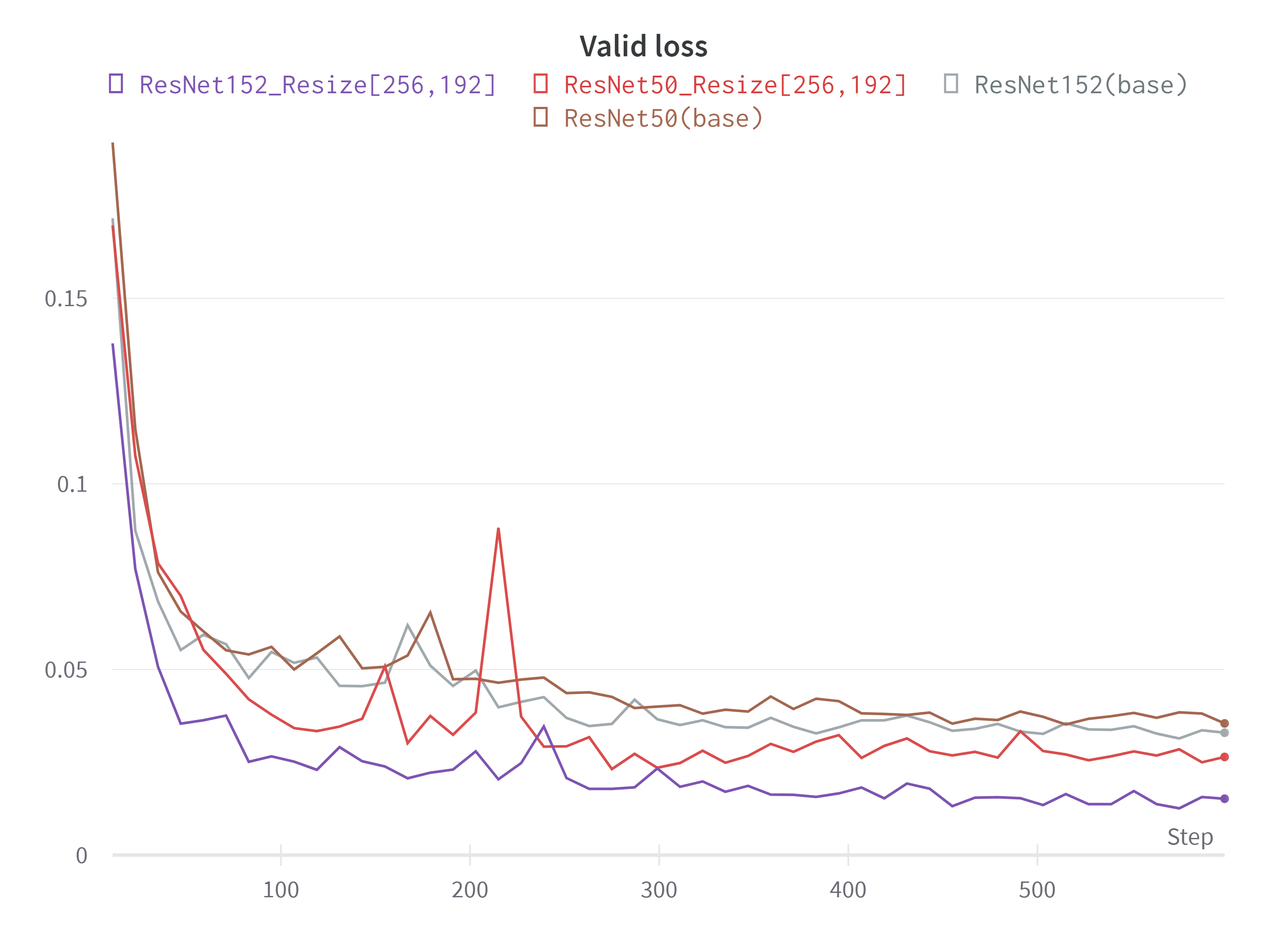
Size를 늘려 학습을 시킨 결과 Valid Loss가 유의미하게 낮아졌음을 알 수 있었다. 아무래도 해상도가 높아짐에 따라 인물의 얼굴에서 세세한 주름이라는 특징을 더 잘 학습 할 수 있었던 것 같다.
Mislabeled Data
사실 Age Class에서 Mislabeled 된 데이터가 있겠나라고 생각하고 대충 훑어보고 넘어갔었다. 하지만 감사하게도 캠퍼분 한분이 대회 게시판에 Mislabeled 된 데이터를 정리해서 올려주셨다. 정리해 주신 Mislabeled 된 데이터를 살펴보니 학습에 충분히 방해가 될 만한 데이터들인 것 같아 데이터셋에서 제외 한 후 학습시켰다.
Tomek's Link Method
사실 나이대 분류를 하는 것은 인간이 하기도 쉽지 않은 일이라고 생각한다. 특히 class 분류의 경계에 있는 나이의 사람들을 구분하기는 더욱 어렵다. 더구나 데이터의 분포를 보면 50대와 60세의 데이터가 상당한 양을 차지하고있다. 이러한 사진들을 60세 미만과 60세 이상으로 구분하기는 상당히 어렵다.
이런 문제를 해결하고자 Tomek Link's Method를 활용해보기로 하였다.
토멕링크(Tomek’s link)란 서로 다른 클래스에 속하는 한 쌍의 데이터 (x+,x−)로 서로에게 더 가까운 다른 데이터가 존재하지 않는 것이다. 즉 클래스가 다른 두 데이터가 아주 가까이 붙어있으면 토멕링크가 된다. 토멕링크 방법은 이러한 토멕링크를 찾은 다음 그 중에서 다수 클래스에 속하는 데이터를 제외하는 방법으로 경계선을 다수 클래스쪽으로 밀어붙이는 효과가 있다.
출처 : https://datascienceschool.net/03%20machine%20learning/14.02%20%EB%B9%84%EB%8C%80%EC%B9%AD%20%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EB%AC%B8%EC%A0%9C.html
그래서 모델이 해당 데이터들의 경계를 좀 더 잘 구분 할 수 있도록 하기 위해 55세부터 59세까지의 데이터를 제외시킨 후 학습시켜보았다.
- Mislabeled Data와 Tomek's Link Method를 활용하기 전후 Valid Loss 값 비교
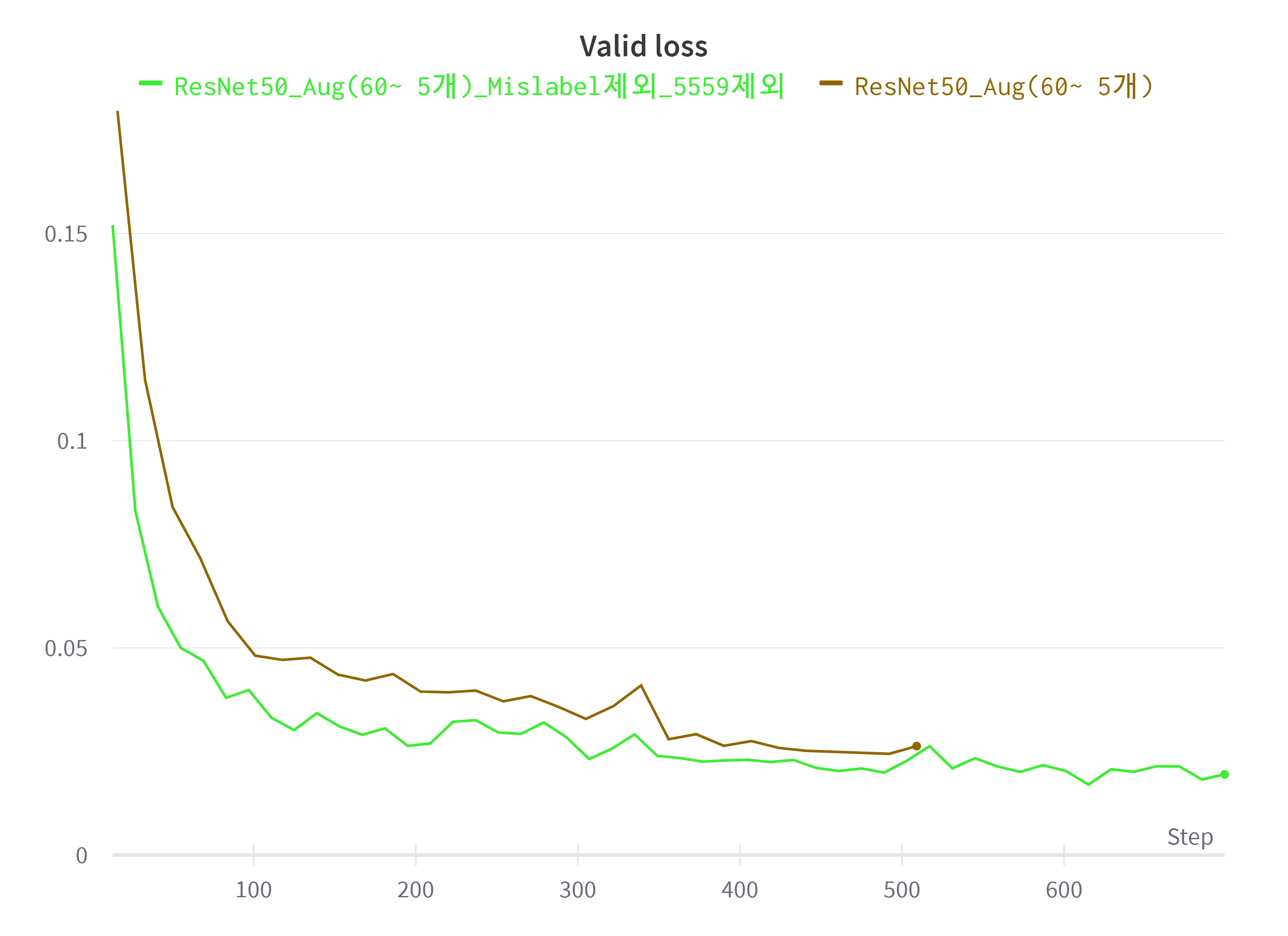
Mislabeled Data와 55세부터 59세 까지의 데이터를 제외 시킨 후 학습 시킨 모델은 기존의 모델보다 더 좋은 성능을 보였다.
데이터 불균형 문제 - Oversampling
Age Classification Task의 가장 큰 문제 중 하나인 데이터 불균형 문제를 어떻게 해결해야 할까 고민을 많이 했다.
우리는 이런 클래스 불균형을 해결하기 위해 클래스 별로 따로 Augmentation 기법들을 적용해 oversampling을 시도해 보기로 하였다. 데이터 수가 적은 클래스에는 Flip, Rotation, ColorJitter 등의 더 다양한 Augmentation을 적용해 데이터 수를 늘려주는 방식으로 각 데이터의 갯수를 맞춰주고자 하였다.
- 60세 이상 데이터의 oversampling에 따른 Valid Loss 값 비교
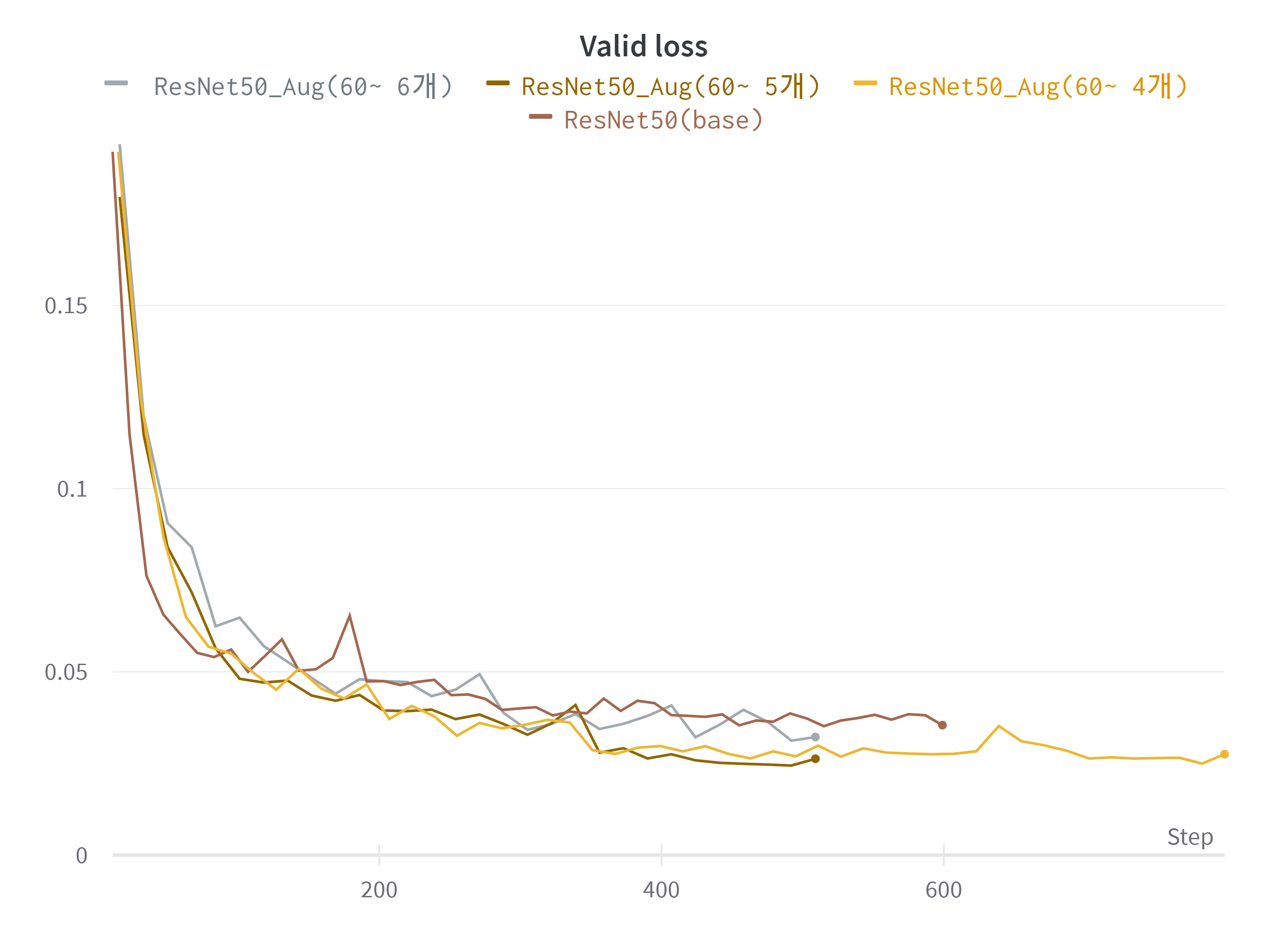
점차적으로 데이터 수를 맞춰주기 위해 60세 이상의 데이터를 Augmentation을 통해 4번, 5번, 6번 늘려주고(각각 5배, 6배, 7배 증강이 된다) 실험을 해보았다. 결과적으로는 Augmentation을 5번 한 결과가 가장 좋은 성능을 보였다. 6배 증강을 했을 시에 가장 데이터 수의 균형이 맞아 이러한 결과가 나온 것이 아닐까 싶다.
55세부터 59세 사이의 데이터와 Mislabeled Data를 제외 시키고 난 후의 데이터 분포는 크게 변화했다. 30세 이상 60세 미만의 데이터가 약 절반가량을 줄어들었다. 30세 이상 60세 미만의 데이터 또한 수를 맞춰주기 위해 Data Augmentation을 통해 2배 증강 시켜주었다.
- 30세 이상 60세 미만 데이터 2배 증강 전후 Valid Loss 비교
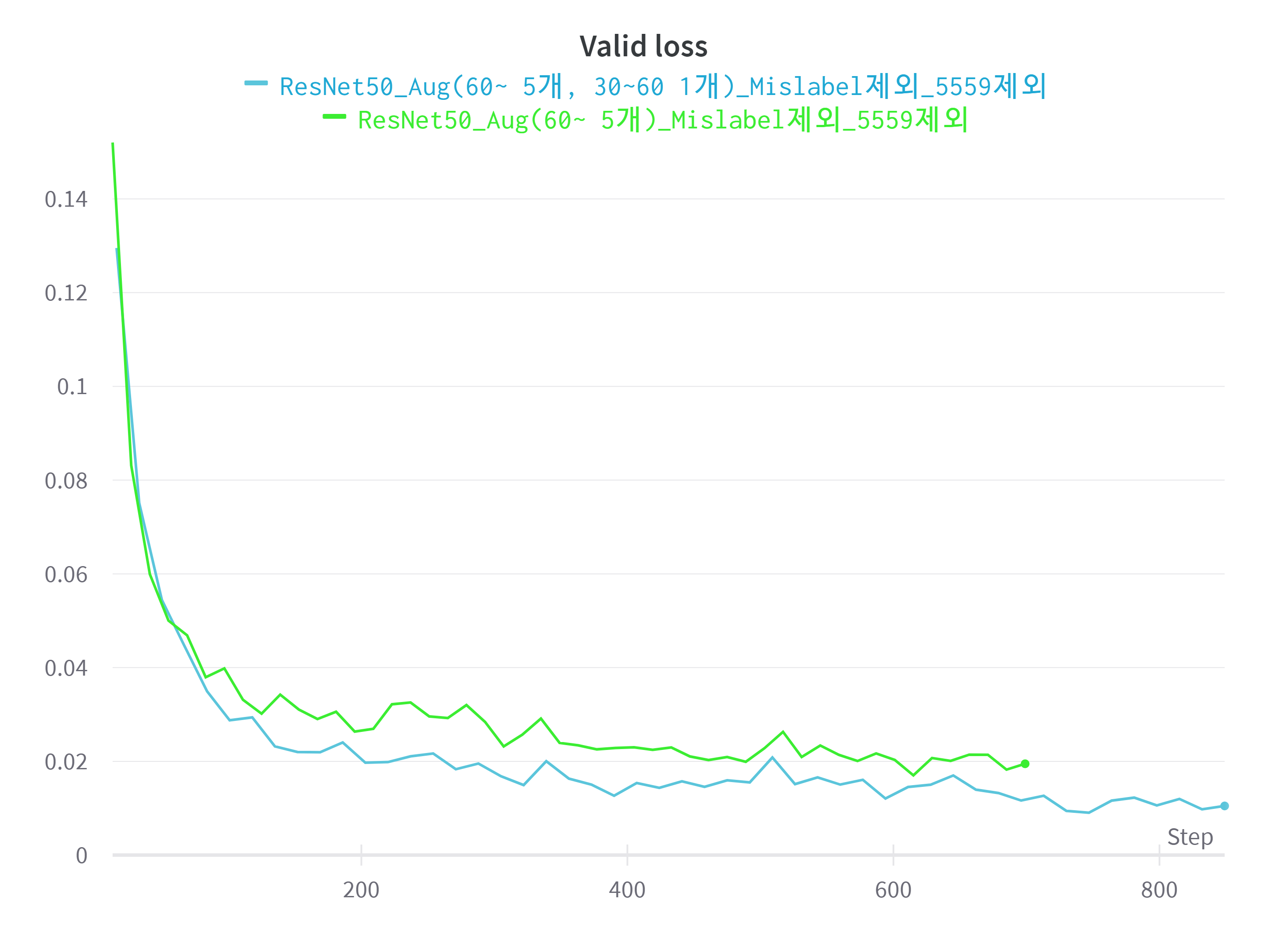
30세 이상 60세 미만의 데이터를 2배 증강 시킨 후 학습을 시켜보았더니 Valid Loss가 유의미하게 낮아졌음을 알 수 있었다.
데이터 수의 균형을 맞춰주는 것이 학습 및 성능 향상에 큰 도움을 주었다.
- class 별 데이터 분포 정리
----BASE(사람 수)---- <30 1281 >=30 and <60 1227 >=60 192 55~59세 : 573명의 데이터 ----55~59세 제외---- <30 1281 >=30 and <60 654 >=60 192 Mislabel : 18개 (모두 30세 이상 60세 미만 데이터) 55~59세와 겹치는거: 15개 ----55~59제외, Mislabel 제외---- <30 1281 >=30 and <60 651 >=60 192 ----사람 수 X IMAGES 수(각 7장)---- <30 8967 >=30 and <60 4557 >=60 1344 ----TRAIN SET 분리 (0.8)---- <30 7174 >=30 and <60 3646 >=60 1075 ----AFTER AUGMENTATION---- <30 7174 >=30 and <60 3646 * 2 = 7292 >=60 1075 * 6 = 6450
시도해보았지만 잘 되지 않았던 것
- 더 큰 Resolution을 가지면 더 세세한 feature들을 잡아 낼 수 있을 거라 생각해 ResNet152 기준 Resize 크기를 [384, 288]로 늘려 실험해보았지만 시간만 훨씬 오래 걸리고 오히려 성능이 나빠졌다.
- Augmentation을 수정하는 과정에서 나름의 논리적인 생각을 가지고 적용해 보았지만 오히려 성능이 나오지 않았다. 30세 이상 60세 미만의 데이터와 60세 이상의 데이터의 거리를 늘려보고자 두 클래스의 데이터에 Contrast를 조절하는 Augmentation을 적용시켰다. Contrast를 조절해 30세 이상 60세 미만의 데이터 이미지 속 인물들의 주름을 덜 보이도록 하고 60세 이상의 데이터 이미지 속 인물들의 주름을 더 강조하도록 하였다. 하지만 이 방법 또한 오히려 성능의 하락을 보였다.
- Focal Loss 또한 불균형한 데이터를 학습 시킬 때 많이 활용되는 Loss이다. Focal Loss를 사용하여 실험해보았는데 Test시의 F1-score가 향상되지는 않았다.
최종 모델
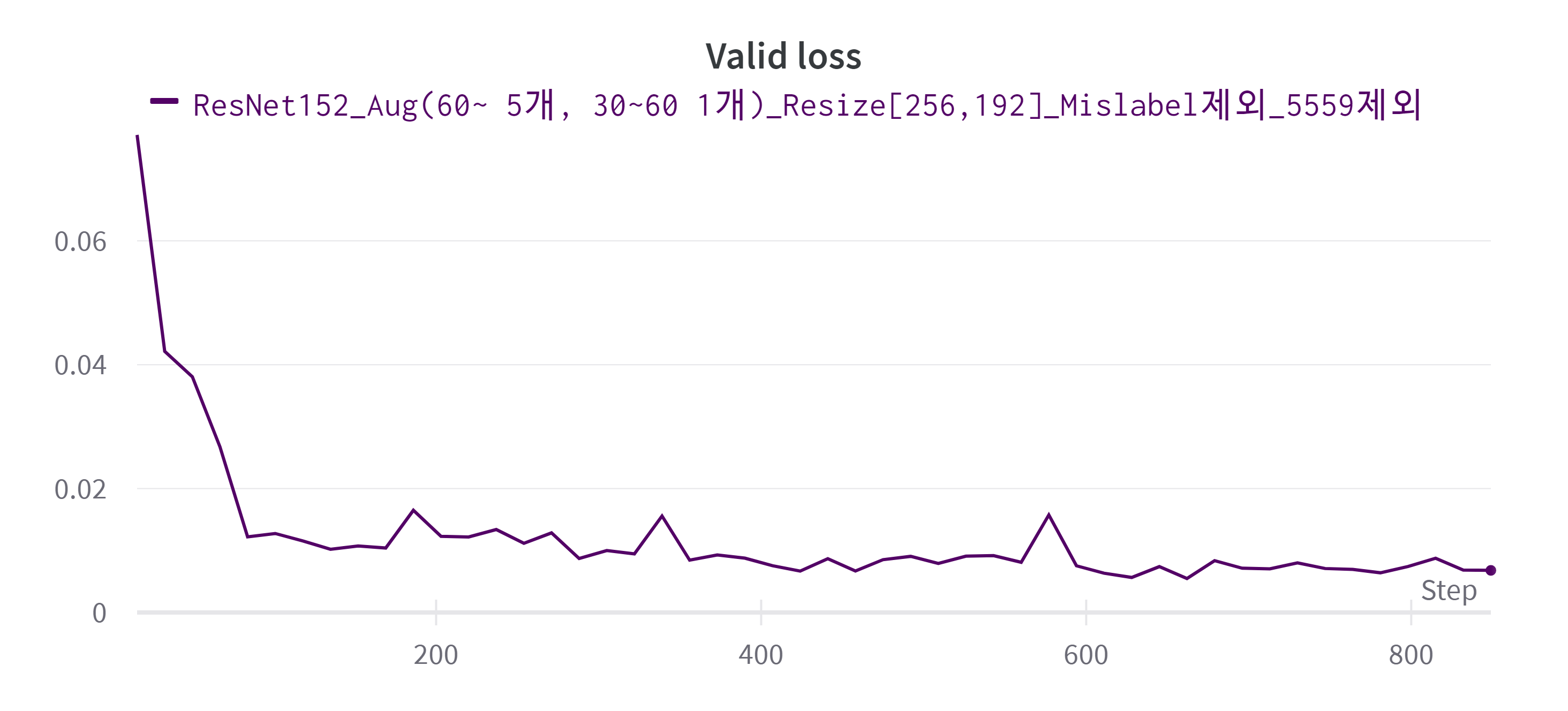
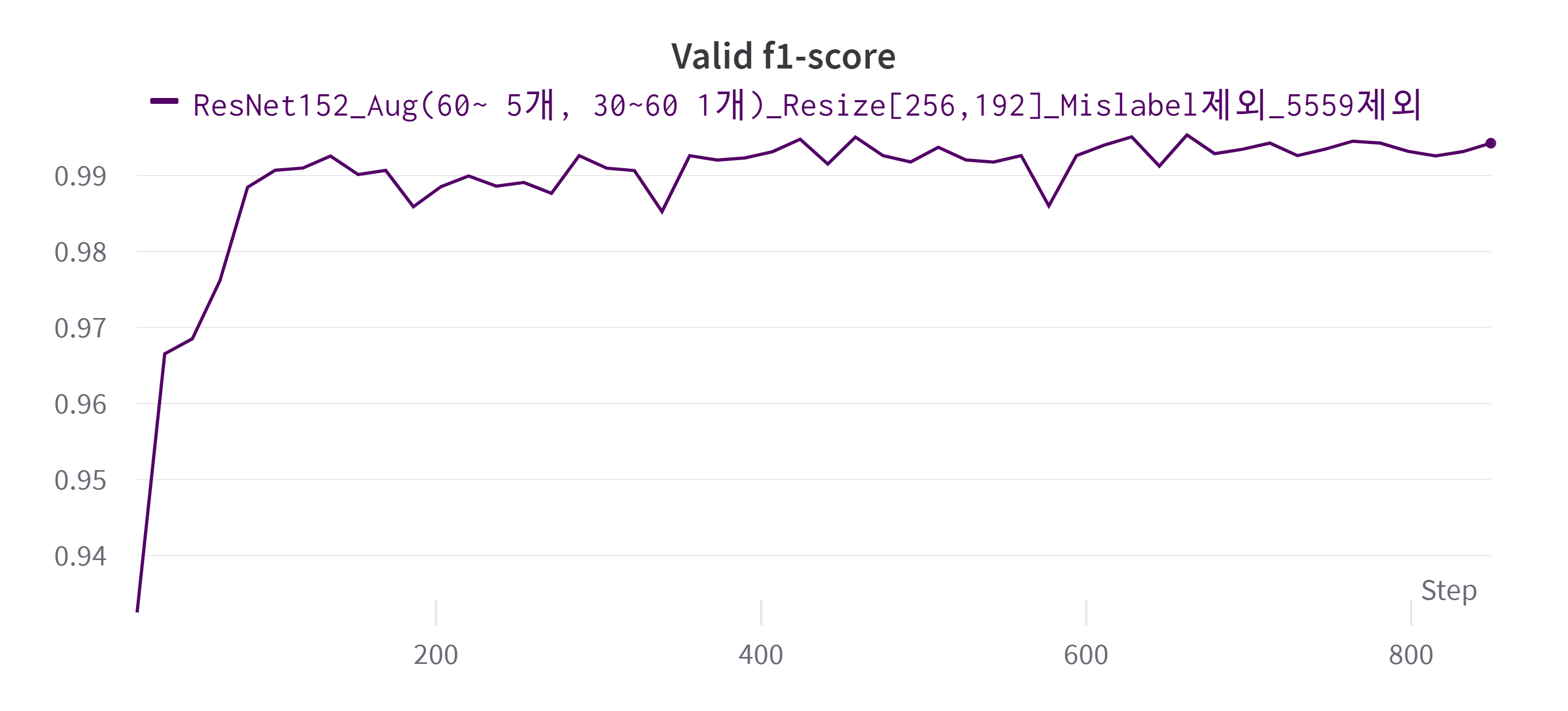
ResNet152를 기반으로 input image size는 [256,192], Mislabeled Data와 55세부터 59세 데이터 제외, 60세 이상은 6배 / 30세 이상 60세 미만은 2배 데이터 증강 한 채로 학습을 시켰다. 이렇게 학습 시킨 모델을 최종적인 모델로 정하여 제출하였다.
- 최종 모델의 Valid Loss
- 최종 모델의 Valid f1-score
Mask Classification & Gender Classification
두 task는 내가 담당해서 진행하지 않았지만 간단하게 나마 어떻게 modeling이 진행되었는지 적어보고자 한다.
EDA
- Mask : 이미지 데이터가 인물 당 마스크 정상착용/미착용/오착용이 각각 5장/1장/1장의 총 7장씩 주어졌다. 즉 전체 데이터는 마스크 정상착용/미착용/오착용이 각각 5:1:1의 비율로 주어져 데이터 불균형을 해결해야 했다.
- Gender : 남여 비율이 약 3:7로 데이터 불균형을 해결해야했다.
모델 선정
-
Mask : EfficientNetB0를 사용하였다. ResNet50, ResNet152의 경우 Overfitting이 발생하였으며, GoogLeNet과 VGG19는 무겁고 깊다보니 학습에 효과적이지 않다고 판단. 따라서 적당한 수렴속도와 빠른 학습속도를 통해 시간을 효율적으로 활용하기 위하여 EfficientNetB0를 활용하였다.
-
Gender : EfficientNetB3를 상요하였다. ResNet이나 DenseNet을 활용하려 했으나, 성능적으로 EfficientNet이 더 우수하여 결정하게 되었다. 또한, B0보다 좀 더 깊은 모델을 활용해 본 결과 B3에서 가장 좋은 결과를 얻을 수 있었다.
모델 개선
-
Mask : Data Augmentaion을 통해 데이터 수 증강 및 데이터 비율을 맞춰주었다. wear 클래스는 grayscale을 적용한 데이터들을 추가해 2배로 늘려주었고 나머지 두 클래스들은 데이터 수를 맞춰주기 위해 grayscale과 rotation을 이용해 데이터 수를 10배로 늘려주었다. 또한 손수건 형태의 마스크(Bandana)가 포함된 학습데이터는 200건이 채 되지 않고 학습데이터와 차이가 큰 형상의 테스트 데이터가 확인됨에 따라 별도 Augmentation을 적용하여 성능을 개선하였다.
-
Gender : Data Augmentaion을 통해 데이터 수 증강 및 데이터 비율을 맞춰주었다. 또한 Inference 과정에서 화려한 마스크나 옷을 입은 인물이 여자로 자주 분류되는 것을 확인하고 화려한 의상을 입은 남성도 남성인 것을 학습시키기 위해 밝은 방향으로 color jitter를 적용하여 Augmentation을 진행하여 성능을 향상시켰다. 더해, 마스크가 아닌 손수건을 마스크처럼 착용한 인물들의 성별 분류가 원활하게 이루어지지 않는 점을 확인하였다. 손수건을 착용한 인물들의 Dataset을 따로 만들어내어 추가적으로 Augmentation을 활용하여 데이터를 증강시킨 후 학습을 시켜보았더니 F1-Score가 높아졌다.
최종 모델
-
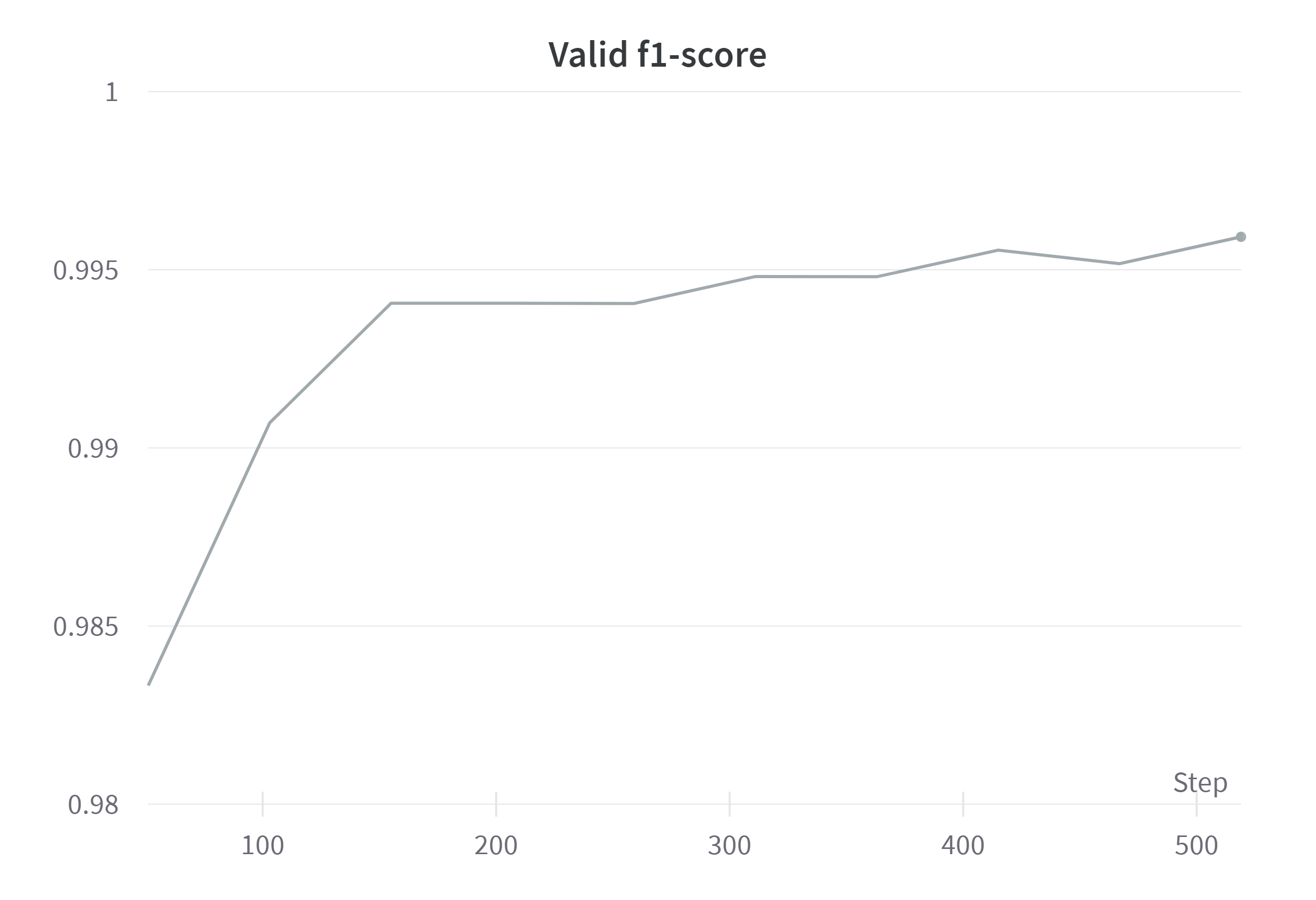
Mask Model의 Valid f1-score
-
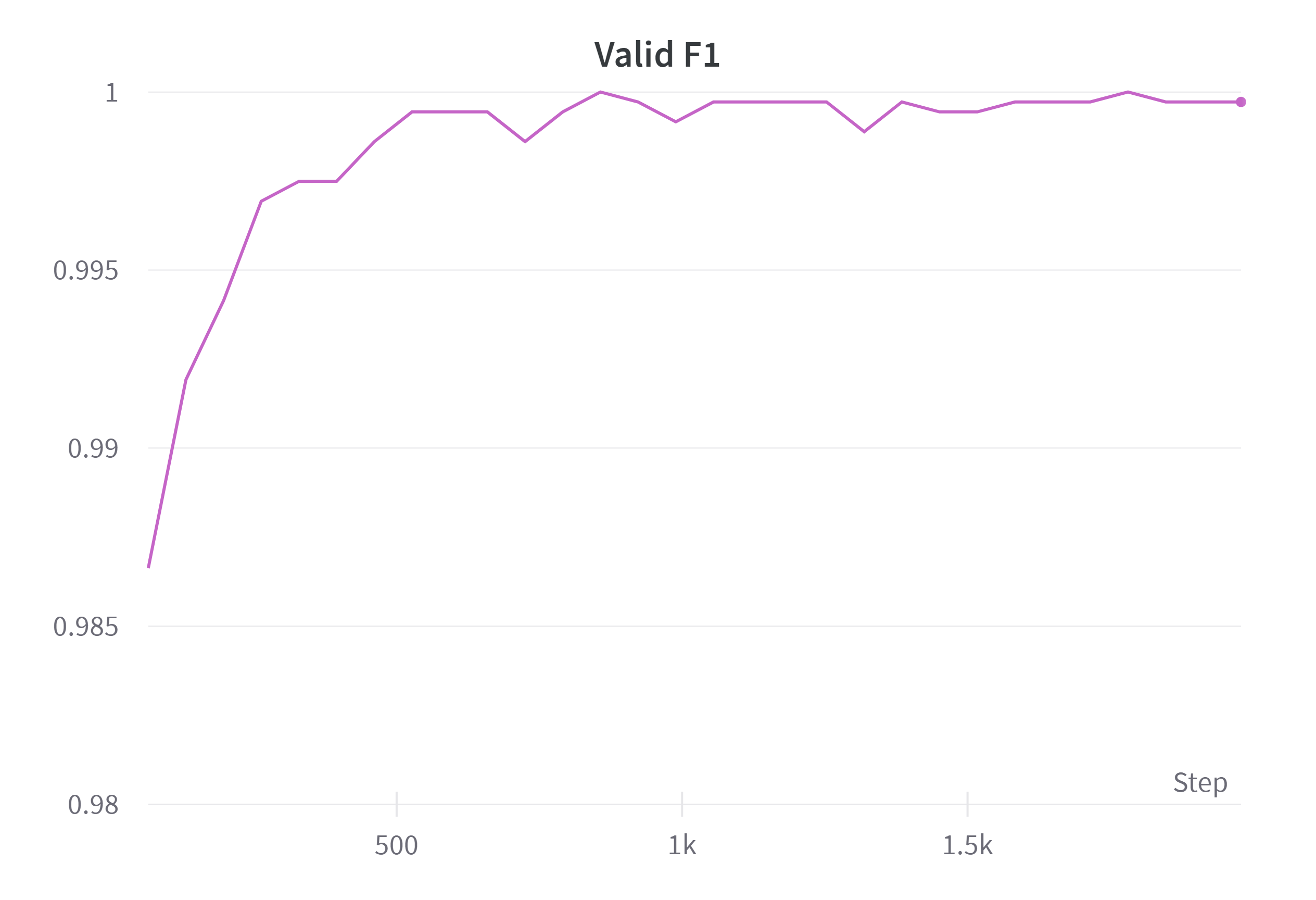
Gender Model의 Valid f1-score
대회 결과
사실 결과보다는 과정이 중요하겠지만...

- 최종 모델 성능
- F1-Score : 0.7693
- Accuracy : 81.3175%
정말 생각지도 못하게 높은 순위를 기록하였다. 순위 상위권을 노리고 대회를 시작하지 않았지만 높은 순위로 대회를 마무리 할 수 있어서 기분이 좋았다. 대회 기간동안 열심히 해준 팀원들에게 매우 감사하다.
회고
아쉬웠던 점
-
전체적으로 시간이 좀 부족했다는 느낌을 많이 받았다. 물론 대회 형식이라 정해진 시간 내에 좋은 성능을 내는 것이 목표이지만 시간이 좀 넉넉했다면 다른 다양한 시도를 많이 해 볼 수 있었을 것 같아 아쉬움이 남았다.
-
모델을 너무 무거운 모델을 선택한 것 같아 실험을 많이 못한 것이 아쉬웠다. 아무래도 시간이 부족하다고 느낀 가장 큰 원인이지 않을까 싶다. 처음 모델을 선정하기 위해 여러 모델을 돌렸을 때 ResNet152의 성능이 가장 좋아 계속 실험을 ResNet152를 이용했고, 또한 이미지 크기를 늘렸을 때 성능이 좋아 ResNet152에 큰 이미지로 실험을 하다보니 한 번 학습을 시키는데 오랜 시간이 걸렸다. 좀 다양한 시도를 해보고 싶었는데 한 번 실험을 하는데 오래 걸려 더 다양한 시도를 못한 것이 아쉬웠다. 성능보다는 효율에 신경을 써서 조금 더 가벼운 모델을 활용하는 것도 좋았을 것 같다.
-
Validation Set 설정을 조금 더 디테일하게 했다면 더 좋았을 것 같다. 55~59세의 데이터를 제외시키는 과정에서 Valid Set에서도 해당 데이터들이 제외가 되었다. Validation 과정에서 55~59세의 데이터를 분류 해 볼 수 없었고 그렇다보니 best model을 찾는 과정에서도 55~59세의 데이터를 잘 분류하는 best model을 찾을 수 없었을 것 같았다. 이 문제를 대회가 끝나기 하루 전에 알아차려 수정하고 실험해볼만한 여유가 없었던 것이 아쉬웠다. 또한 Validation Set 또한 전체 Data set에서 Random으로 Split 하였기 때문에 같은 인물의 다른 사진이 Train Set과 Valid Set에 나눠 들어간 경우가 있었을 것이라고 생각한다. 그렇다보니 학습을 시킬 수록 Train Set 뿐만 아니라 Vaild Set에 대해서도 Overfitting 현상이 일어나 오히려 성능 향상에 방해가 되었을 수도 있었을 것 같다.
-
제출을 많이 못 했던 것도 아쉬움이 남았다. 팀 제출 횟수가 상당히 적은 편이었다. 모델을 제출 해 보는 것은 Validation 뿐만 아니라 직접 Test Data에 적용 시켜 볼 수 있는 기회라 일반화 성능을 더 정확히 실험 해 볼 수 있는 좋은 기회였다. 하지만 모델을 제출 해 보는 것이 부담스럽다고 느껴지기도 하였고 팀적 합의가 이루어져야 낼 수 있다고 생각했기에 적극적인 제출을 못했던 것 같다. Valid Set을 통한 평가 뿐만 아니라 제출을 통해 Test Data로도 모델을 평가해 보는 것이 더 좋은 실험이 되었을 것 같다.
-
기록의 중요성을 다시 한 번 느꼈다. 나름 기록을 한다고 Wandb라는 tool을 이용해 내가 한 실험들을 팀원들과 공유하며 기록했다. 하지만 이런 것을 해보았다 정도만 기록이 되었을 뿐, 구체적으로 어떤 것이 어떻게 바뀌었는지, 또 어떤 값을 어디에 적용했는지 등의 자세한 내용은 기록이 되지 못했다. 또한 Wandb라는 강력한 실험 기록 tool을 100% 활용하지 못했다. 아무래도 처음 써보기도 하였지만 다른 많은 기능들을 같이 활용해 보았다면 더욱 좋았을 것 같다. 그리고 기록의 공유가 더 잘 되었다면 좋았을 것 같다. WandB로 실험 기록을 공유 할 수 있었지만 TestData로 제출하였을 때의 기록은 따로 남겨두지 않았다. 제출 할 때의 기록을 전후 비교를 잘 해놓았더라면 더 결과 비교를 해보기 좋았을 것 같아 아쉬움이 남는다.
-
너무 아무 생각없이 실험만 했다는 생각이 많이 들었다. 대회 초반에는 정말 다양한 길이 있다고 생각하고 시작했지만, 몇 번의 실험 후 점수가 잘 나오니까 그 상태에서 어떤 걸 바꿔볼지, 어떻게 변형하면 더 잘 될지를 위주로 생각했던 것 같다. 점수가 잘 나오더라도 다른 방향의 방법 또한 생각해보고 시도해보았다면 더 좋은 경험이 되고 더 많은 것들을 해보고 배울 수 있었을 것 같아 아쉬움이 남는다.
-
사실 대회 초반 팀원들 사이에서 많은 아이디어가 오갔었다. RetinaFace 등을 이용해 Face Detection을 한 후 사진을 잘라 데이터를 만들어 보자는 이야기도 있었고, cGAN을 이용해 Face Aging 모델을 도입해서 60세 이상의 데이터를 늘려보자는 아이디어도 있었다. Cross-Validation을 활용해보자는 이야기도 있었다. 하지만 이런 좋은 아이디어들을 결국 활용하지 못했다. 시간의 부족, 구현 능력의 부족 등으로 인해 이런 아이디어를 접어야 했던 것이 아쉬웠다.
-
대회의 후반부에 가서는 정말 점수 올리기에만 신경을 썼던 것 같다. 사실 앞서 말한 아쉬운 점들의 대부분이 이 점수로 인해 생긴일이 아닌가 싶다. 계속 점수를 올리는데 신경을 쓰다보니 빨리 다른거도 해봐야지 하는 생각에 실험기록보다는 많은 실험을 하는데 집중하였던 것 같다. 그러다보니 내가 하고 있는 실험 외에 다른 길도 있다는 생각을 할 틈이 없었던 것 같다. 실험이 잘 되지 않으면 어떤 것이 잘못되었는지 생각하기보다는 잘 안되니까 다른거 해보자는 생각이 주를 이루었던 것 같다. 대회 전이나 대회 중에도 운영진 분들이나 멘토님께서도 점수에 매몰되지 말라는 조언을 많이 해주셨는데 그러지 못했던 것이 아쉬웠다. 점수보다는 내가 많이 배우는데 집중을 더 했으면 좋았을 것 같다.
배운 점
이번 이미지 분류 대회는 나에게 있어 처음으로 진행해보는 프로젝트였다. 부스트캠프 참여 전에는 혼자 독학하며 공부를 해보았을 뿐 프로젝트를 진행해보거나 대회에 참여한 적이 없었다. 처음 해보는 프로젝트였기에 시작부터 끝까지 새로 배운 점이 정말 많았다.
-
데이터 전처리 과정을 해볼 수 있었다. 복잡한 EDA를 해본 것은 아니지만 아주 정제된 데이터가 아닌 조금 더러운 데이터를 만져 볼 수 있었다(그래도 대회용 데이터는 깔끔한 편이라고 한다...). 또한 비록 비정형 데이터이지만 나름의 전처리를 하여 모델의 성능을 높일 수 있었다. 많은 것을 해본 것은 아니지만 이렇게 직접 데이터를 만져보고 처리 해보는 것을 배울 수 있었다.
-
모델을 직접 다뤄보았다. 지금까지는 강의를 들으면서 노트북 환경에서 주어진 코드를 따라 치며 모델을 사용해 본 것이 전부였다. 이번 프로젝트를 진행하면서 어떤 모델을 사용해볼지 생각하고, 또 직접 사용해보면서 모델이 어떻게 돌아가는지 더 잘 이해할 수 있었다.
-
모델링의 중요성 외에도 정확한 데이터셋 분석과 이에 적합한 Data Augmentation 기법을 적용하는 것으로도 좋은 성능을 얻을 수 있다는 점을 알 수 있었다. 사실 우리 팀이 다른 특별한 기법을 적용했다고 생각하지 않는다. 다른 팀들의 이야기로는 Detection 모델 등 다른 기법들을 활용한 경우도 많다고 들었다. 물론 이러한 기법들이 성능 향상에 도움이 되었겠지만 복잡한 과정 대신 단순히 Data Augmentation으로도 성능을 충분히 끌어올릴 수 있다는 것을 깨달았다.
-
서버 환경에서 작업하는 법을 배웠다. CS적 백그라운드가 부족했던 나로써는 서버 환경에서 코드를 만지는 작업을 할 일이 없었다. 또한 부스트캠프 강의를 들으면서도 노트북 환경에서 실습을 해본 것이 전부였다. 하지만 대회를 진행하면서 GPU 서버를 인당 하나씩 제공을 해주었고 모델을 학습시키기 위해 서버 환경에서 작업을 해야했다. 서버 환경 구축에 있어서 어떻게 해야할지 몰라 불안했는데 운영진 분들과 팀원 분들이 너무나도 친절하게 사용법을 알려주셨다. 또한 부스트캠프 Slack에서도 많은 캠퍼 분들이 서버 활용법을 공유해주신 덕분에 따라하며 서버에서 작업하는 법을 배울 수 있었다.
-
Github를 활용하여 버전을 관리하고 협업을 하는 법을 배웠다. 지난 Github 특강에서 이론을 배우고 실제로 사용해 보는 것은 처음이었다. 더구나 혼자의 기록이 아닌 팀원들과의 협업을 해야했다. Github 관련해서는 이런저런 얘기를 많이 들어서 혼자 코드를 고치고 push 하기가 굉장히 무서웠다. 하지만 다행히 팀원분들이 Github를 통해 협업하는 법과 어떻게 branch를 관리하는지, 또 어떤 식으로 활용하면 되는지 정말 차근차근 알려주었다. 덕분에 팀원들과 나의 프로젝트 기록을 Github에 잘 남기고 관리 할 수 있었던 것 같다. Github를 알려주고 잘 활용할 수 있게 해준 팀원들에게 매우 감사하다.
-
Wandb라는 실험 기록 tool을 사용하는 법을 배웠다. 팀원들과 함께 wandb를 사용해 실험 내용과 결과를 확인할 수 있었는데 그래프를 통해 시각화된 결과를 확인하고 다른 실험과 비교할 수 있었고 학습 도중 실시간으로 정확도를 확인할 수도 있는 등 유용한 실험 관리 도구를 이번 기회에 사용해볼 수 있었다. 모델의 파라미터를 바꿔가며 실험을 여러번 해도 다 기록을 남겨주니 어떻게 실험 했을 때 좋은 성능을 보였는지 확인하기 편했다. Wandb는 수업 때 알려주셔서 알게 되었는데 이렇게 프로젝트를 하면서 활용해보니 좋았다.
마스크 착용 상태 분류 대회 - 팀 GitHub Repository
https://github.com/boostcampaitech4cv1/level1_imageclassification_cv-level1-cv-03
참고
https://sjpyo.tistory.com/49
https://datascienceschool.net/03%20machine%20learning/14.02%20%EB%B9%84%EB%8C%80%EC%B9%AD%20%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EB%AC%B8%EC%A0%9C.html
