1. 데이터
이전에 사용했던 kaggle의 Data Science Job Salaries 데이터세트를 사용하겠다. https://www.kaggle.com/datasets/ruchi798/data-science-job-salaries
2. 스크립트
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql import functions
Job_id={}
def loadJob():
cnt=0
Job_list = {}
with open("ds_salaries.text") as f:
for line in f:
fields = line.split(',')
if fields[4] not in Job_list.values():
cnt+=1
Job_list[cnt] = fields[4]
Job_id[fields[4]]=cnt
return Job_list
def parseInput(line):
fields = line.split(',')
return Row(JOBID = (fields[4]), salary = float(fields[5]))
if __name__ == "__main__":
# Create a SparkSession (the config bit is only for Windows!)
spark = SparkSession.builder.appName("ds_best_salary").getOrCreate()
JOBNames = loadJob()
lines = spark.sparkContext.textFile("hdfs:///~~~~ds_salaries.text")
jobs = lines.map(parseInput)
jobsDataset = spark.createDataFrame(jobs)
averageRatings = jobsDataset.groupBy("JOBID").avg("salary")
counts = jobsDataset.groupBy("JOBID").count()
avg(rating), and count columns)
averagesAndCounts = counts.join(averageRatings, "JOBID")
top = averagesAndCounts.orderBy("avg(salary)").take(len(JOBNames))
for job in top:
print (job[0], job[2])
spark.stop()1. Spark와 Spark 2.0의 차이점
가장 큰 차이점은 Spark 2.0에서는 SQL문법을 사용할 수 있다는 점이다. 스크립트를 보면 groupBy같은 함수가 보일 것이다. 이전 버전보다 좀더 명확하고 간단하게 표현할 수 있게 되었다.
2. parseInput()
이전 버전에서는 튜플을 반환했는데 여기서는 이름을 가진 행 객체를 반환한다. parseInput()를 실행하면 직업의 이름과, 급여가 들어있는 row를 반환한다.
3. averageRatings
직업마다 모든 급여를 더해 평균 급여를 구했던 방법과 달리 groupBy와 avg 한줄로 이전에 했던 작업들을 대신할 수 있다.
jobsDataset.groupBy("JOBID").avg("salary")이 코드를 통해 직업별로 평균 급여를 구할 수 있다.
3. 결과
# Spark 2.0을 사용한다고 명시
export SPARK_MAJOR_VERSION=2
spark-submit 실행할 파일.py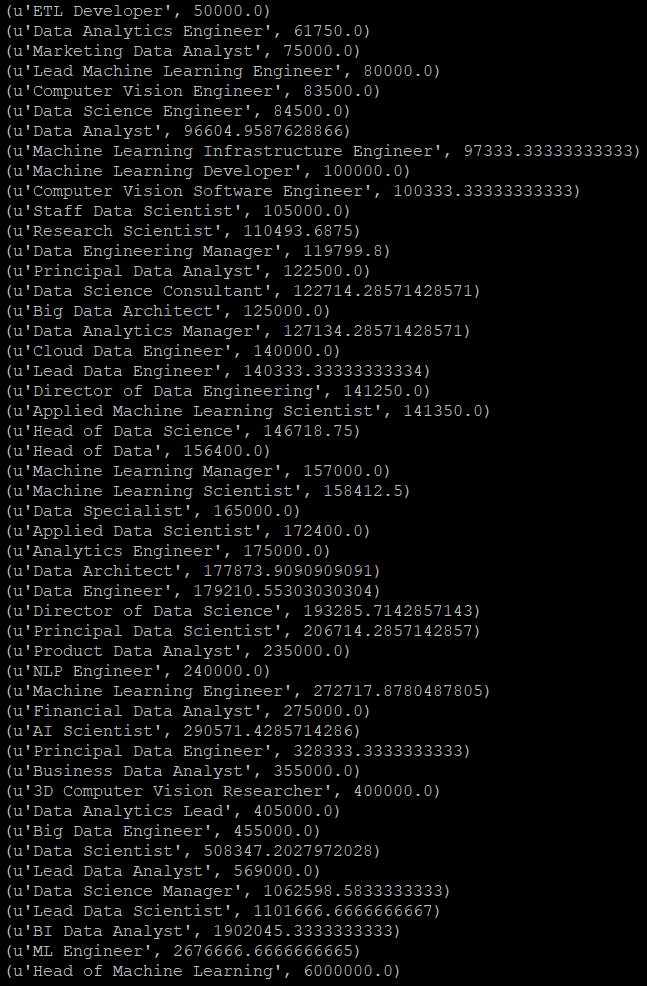
이번에는 오름차순으로 출력했다.
Spark 1의 결과와 순서와 반대이고 값들은 모두 똑같다.
끝

~