1. 데이터 가져오기
이번에 분석할 데이터는 kaggle에서 가져왔다.
https://www.kaggle.com/datasets/ruchi798/data-science-job-salaries
kaggle에는 공개된 데이터가 정말 많아 실습용으로 사용하기 좋다.
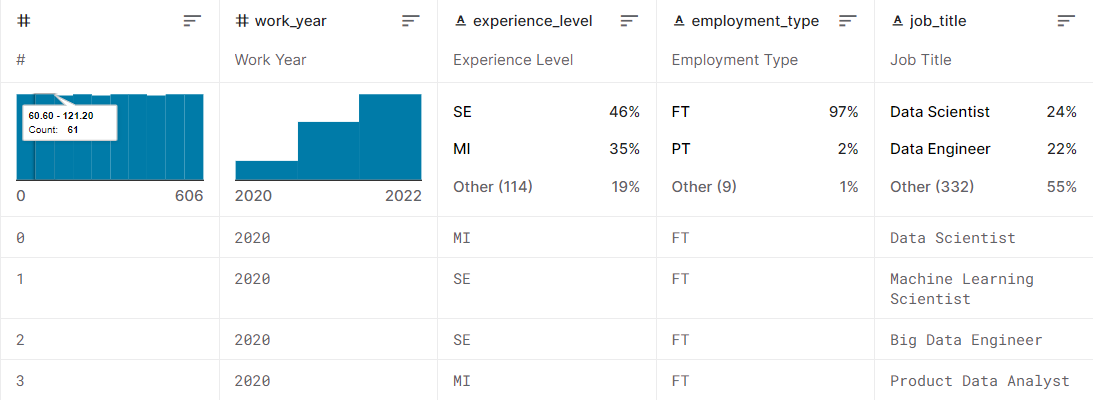
가져온 데이터는 Data Science Job Salaries이란 데이터 세트인데, 데이터 사이언스 관련 직업들의 연봉에 관한 데이터다.
어떤 직업의 평균 급여가 제일 많을지 분석해보겠다.
2. 스크립트
from pyspark import SparkConf,SparkContext
Job_id={}
def loadJob():
Job_list={}
cnt=0
with open("ds_salaries.text") as f :
for line in f:
fields=line.split(",")
if fields[4] not in Job_list.values():
cnt+=1
Job_list[cnt]=fields[4]
Job_id[fields[4]]=cnt
return Job_list
def parseInput(line):
fields=line.split(",")
return (Job_id[fields[4]],(float(fields[5]),1.0))
if __name__=="__main__":
conf = SparkConf().setAppName("lucrative job")
sc = SparkContext(conf = conf)
Job_list = loadJob()
lines = sc.textFile("hdfs:///~~~~~/ds_salaries.text")
job_salary = lines.map(parseInput)
ratingTotalsAndCount = job_salary.reduceByKey(lambda job1,job2 : (job1[0]+job2[0],job1[1]+job2[1]) )
averageSalary = ratingTotalsAndCount.mapValues(lambda totalCount : totalCount[0]/totalCount[1])
sortedJob = averageSalary.sortBy(lambda x: -x[1])
results = sortedJob.take(len(Job_list))
for result in results:
print(Job_list[result[0]],result[1])1. Job_id={}, Job_list={}
Job_id에는 key로 직업명이, value로 cnt(구분값)이 들어간다.
Job_list에는 key로 cnt(구분값)가, value로 직업명이 들어간다.
2. loadJob()
HDFS에 있는 "ds_salaries.text"에서 한줄씩 가져와 쉼표를 기준으로 데이터를 쪼갠다. 그후 조건에 부합하면 Job_id와 Job_list를 업데이트 한다.
3. parseInput()
마찬가지로 한줄씩 가져와 쉼표를 기준으로 데이터를 쪼갠 후, (직업명, (연봉), 1.0)을 return한다. 이때 직업명이 key, (연봉), 1.0이 value가 된다. 이 함수에서 가져올 데이터를 HDFS에 넣어놨다. 주소를 잘 설정하면 된다.
4. main
main에서는 필요한 세팅을 모두하고 loadJob() 함수와 parseInput() 함수를 이용해 데이터를 가져온다. 그리고 key(직업명)을 기준으로 총 연봉, 나온 횟수를 계산한다.
마지막으로 총 연봉을 나온 횟수로 나누면 평균 연봉이 되고 연봉이 높은순으로 sort를 하면 된다.
3. 결과
spark-submit 실행할 스크립트.py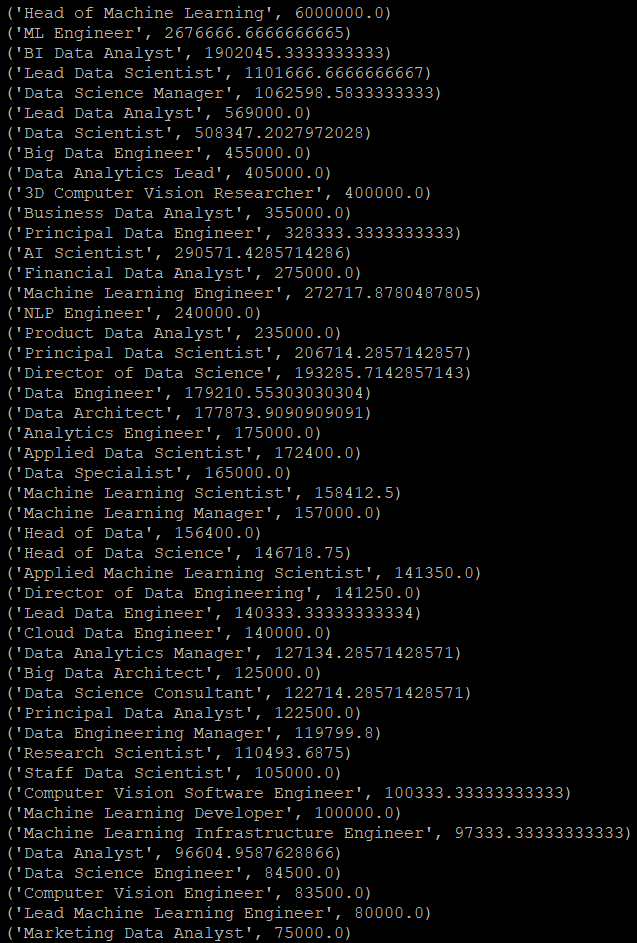
Head of Machine Learning이 제일 돈을 많이 번다.
공부 열심히 해서 Head of Machine Learning이 되자.
