1. Summary
1-1. 연구 목적
이 연구의 목적은 LLM, ChatGPT를 사용하여 자동화된 정신 건강 분석의 성능을 평가하였다. 기존 관련한 연구의 경우 평가의 부적절성 그리고 프롬프트의 전략 부족(단순히 출력값 고정을 위한 프롬프팅, 설명 가능성에 대한 가능성)으로 인해 다양한 프롬프트를 테스트하며 감정 기반 정보가 LLM의 정신 건강 분석 능력에 미치는 영향을 조사하였다.
1-2. 연구 내용
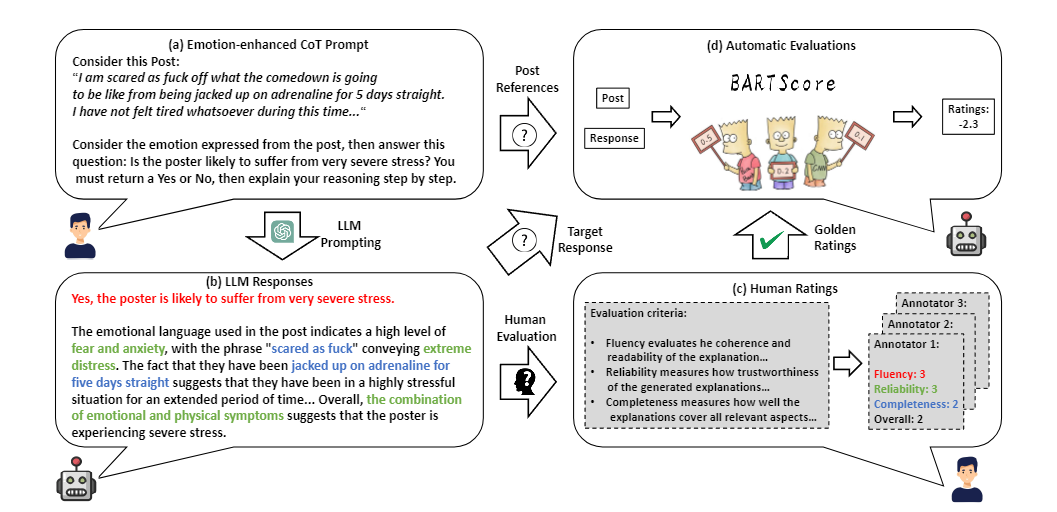
이 연구에서는 11개의 데이터셋을 사용하여 5가지 작업에 걸쳐 LLM의 정신 건강 분석 및 감정 추론 능력을 평가했다. 평가된 LLM에는 ChatGPT, InstructGPT-3, LLaMA-13B, LLaMA-7B가 포함된다. 작업은 이진/다중 클래스 정신 건강 상태 감지, 정신 건강 상태 원인/요인 감지, 대화에서의 감정 인식 및 인과 감정 함축을 포함하였다.
연구는 또한 Emotion-enhanced Prompts, Supervised emotion-enhanced prompting, CoT, Few-shot Emotion enhanced Prompts 과 같은 다양한 프롬프트의 효과를 탐구했다. 마지막으로, LLM이 정신 건강 분석 결과에 대한 자연어 설명을 생성하도록 지시하여 해석 가능한 정신 건강 분석 능력을 탐구했다. 이러한 설명의 품질을 평가하는 인간 평가를 수행했다. BART Score로 인간과 유사해야한다.
Prompt Example
binary mental health condition detection prompt
- Post: "[Post]". Consider this post to answer the question: Is the poster likely to suffer from very severe [Condition]? Only return Yes or No.
Emotion-enhanced Prompts
- Post: "[Post]". Consider the emotions ex- pressed from this post to answer the question:
Is the poster likely to suffer from very severe [Condition]? Only return Yes or No, then ex- plain your reasoning step by step.
Few-shot Emotion- enhanced Prompts
- You will be presented with a post. Consider the emotions expressed in this post to identify whether the poster suffers from [condition]. Only return Yes or No, then explain your reasoning step by step. Here are N examples:
Post: [example 1]
Response: [response 1]
...
Post: [example N]
Response: [response N]
Post: [Post]
Response:
1-3. 결과
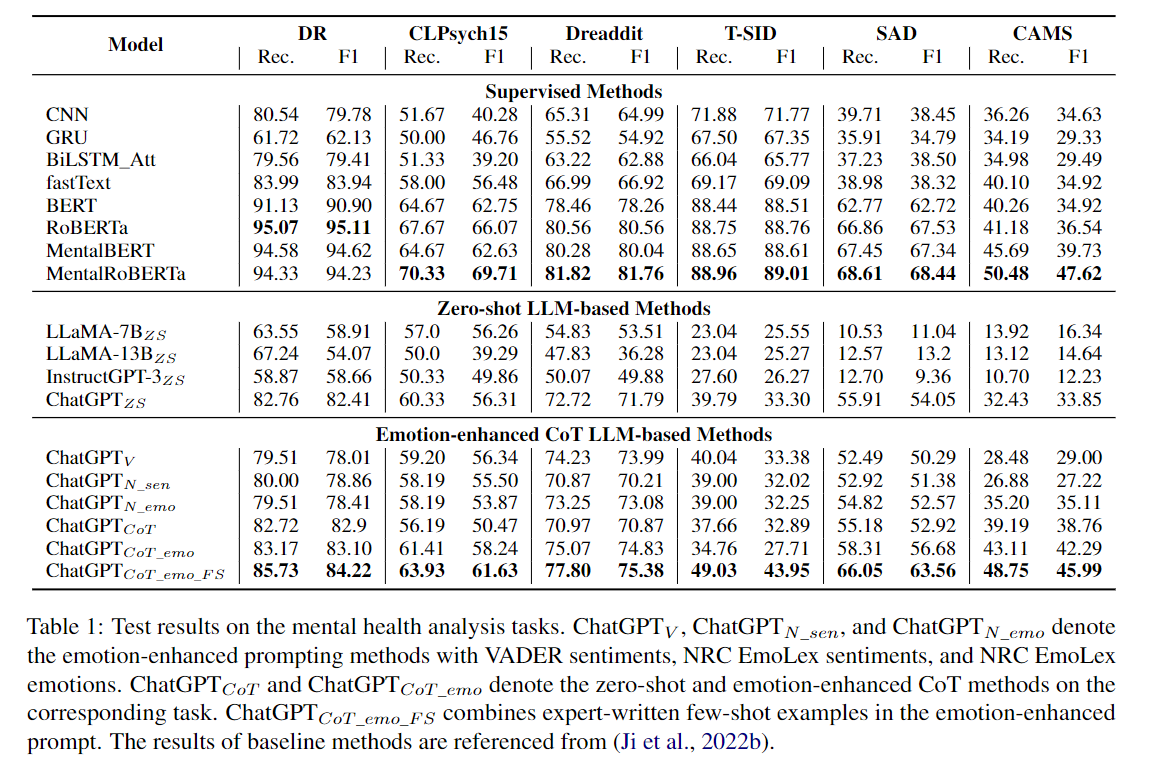
ChatGPT는 평가된 모든 LLM 중에서 최고의 성능을 발휘했지만 여전히 expert model에 비해 크게 뒤처졌다. 프롬프트 엔지니어링이 emotion을 활용하여 성능을 향상시키는 데 중요하며, Few-shot Emotion- enhanced Prompts이 모델 성능을 크게 향상시켰다.
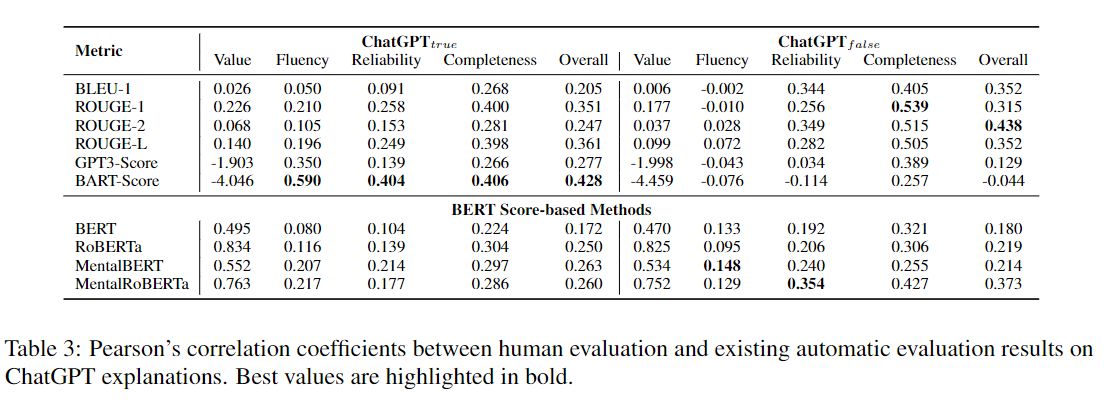
이에 대한 분석으로 True는 맞는 ChatGPT가 정신 건강 상태 감지 작업에서 맞추는 경우고 False는 ChatGPT가 틀린 경우이다.
결국 True일때는 BART 모델로 측정한 BART score이 높으며 False일떄는 BㅁART score의 성능이 떨어져 BERT가 더 설명을 매트릭으로 더 참고하기 좋다고 보여준다.
ChatGPT는 그 분류에 대한 인간 수준에 가까운 설명을 생성할 수 있어 해석 가능성을 높일 수 있는 잠재력을 보여주었다. 그러나 ChatGPT는 부정확한 추론과 불안정한 예측과 같은 제한 사항도 갖고 있어 향후 연구에서 개선이 필요함을 시사했다.
2. Conculsion
이 연구는 LLM이 특히 ChatGPT가 정신 건강 분석에서 전반적으로 좋은 성능을 보이지만, 여전히 고급 감독 학습 방법에 비해 성능이 부족하다는 것을 확인했다. Emotion을 포함한 프롬프트 엔지니어링과 Few-shot Emotion- enhanced Prompts가 LLM의 성능을 크게 향상시킬 수 있음을 보여주었다. ChatGPT는 인간 수준에 가까운 설명을 생성할 수 있는 잠재력을 가지고 있으나, 부정확한 추론과 불안정한 예측 문제를 해결하기 위해 도메인 특화된 미세 조정이 필요하다. 향후 연구에서는 이러한 문제를 해결하고, LLM의 해석 가능성을 다른 연구 분야로 확장하는 것이 필요하다

2개의 댓글

Taking care of your mental health is just as important as physical health! Try daily mindfulness, stay active, and talk about your feelings. If you're in Zaragoza, https://psicologiaycoachingzaragoza.es/psicologia-infantil-zaragoza/ offers expert child psychology services to support emotional well-being. Small steps make a big difference!
As mental health analysis increasingly relies on advanced technologies, large language models (LLMs) are becoming crucial tools for interpreting complex data. These models, equipped with sophisticated algorithms, offer a promising approach for making mental health insights more accessible and understandable. By integrating LLMs, researchers can enhance the accuracy and clarity of their analyses, leading to more effective interventions. For instance, integrating resources like https://medwholesalesupplies.com/product/orthovisc-eng/ in mental health studies could provide valuable data points, further refining the interpretability and relevance of mental health evaluations.