boostcamp5week
1.[Transformer 논문리뷰](Attention is all you need)
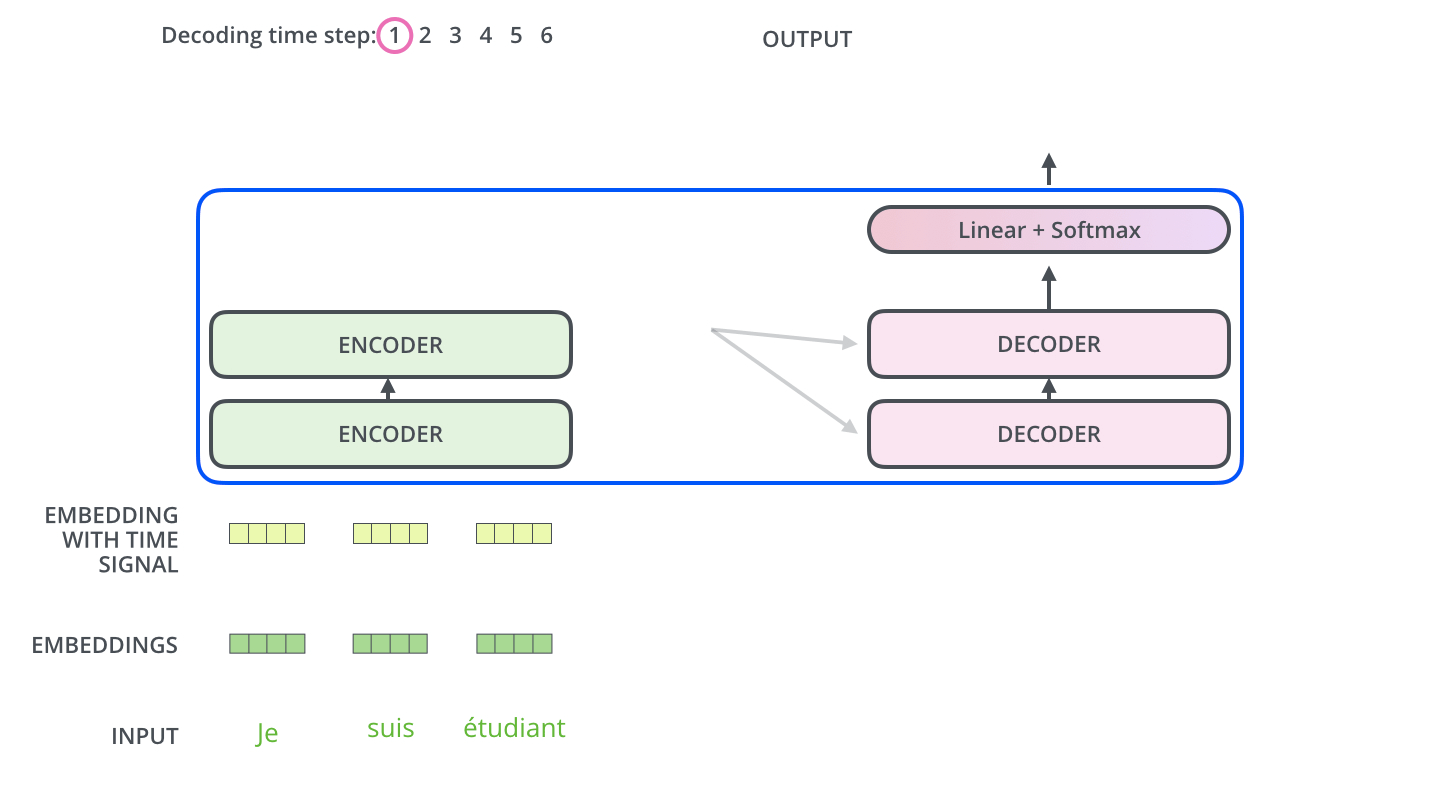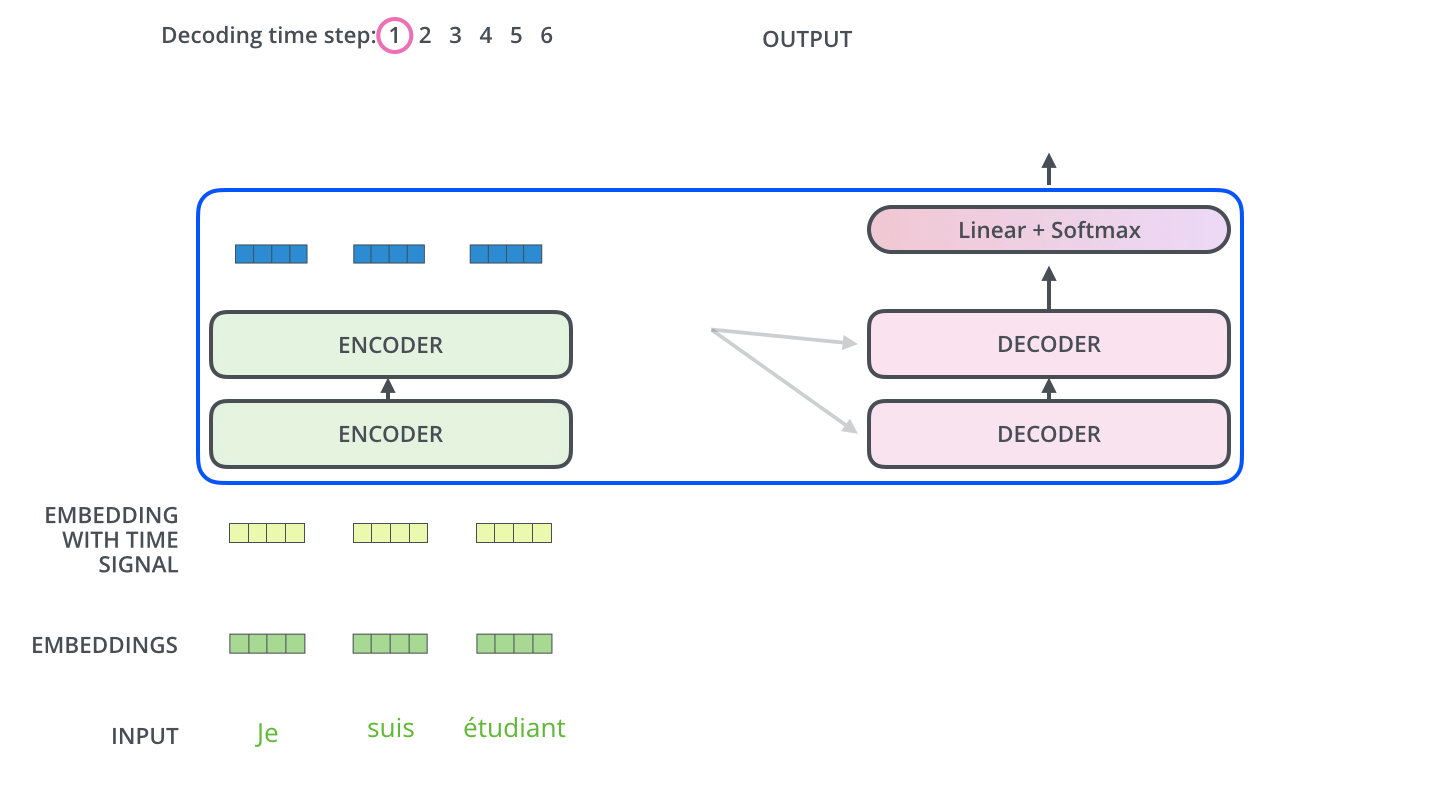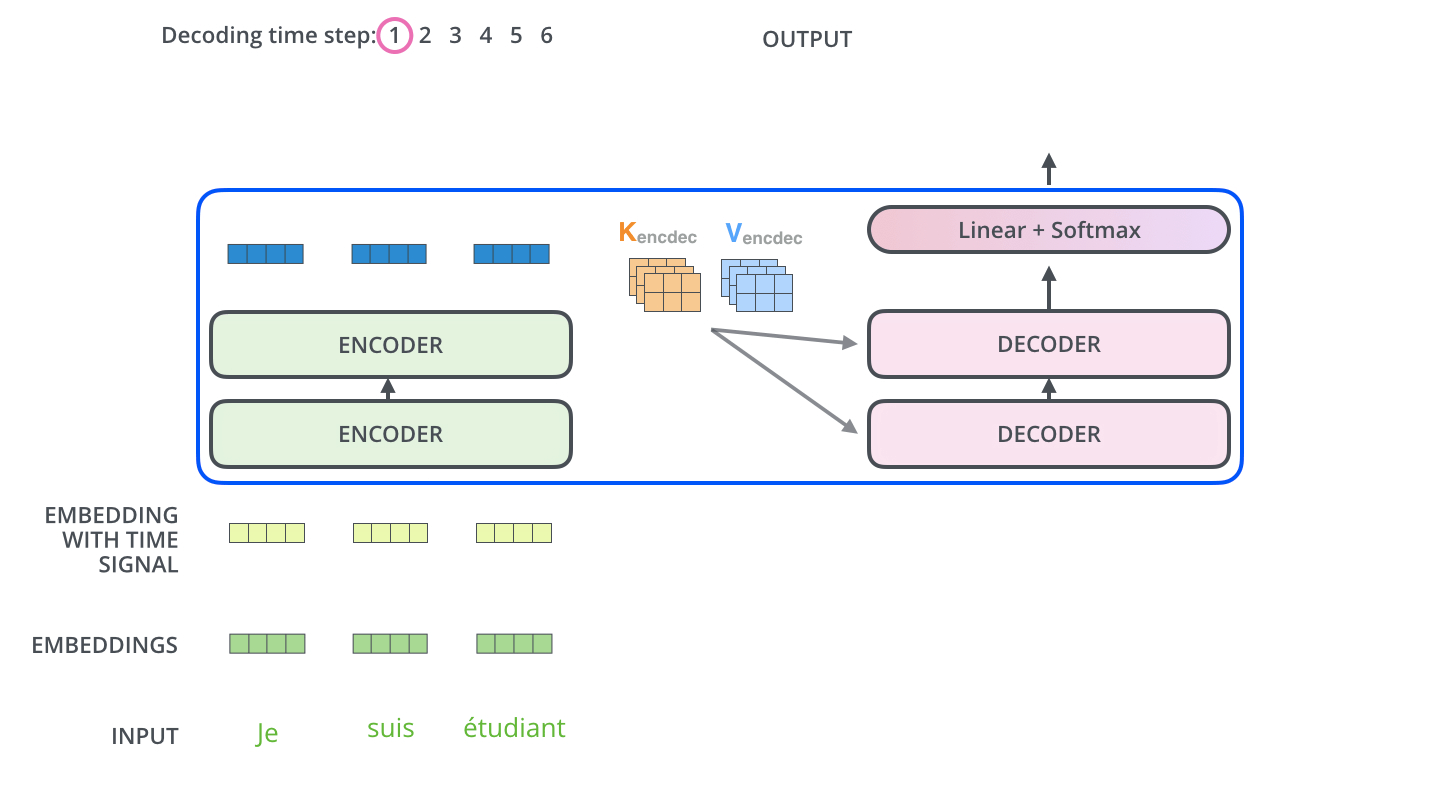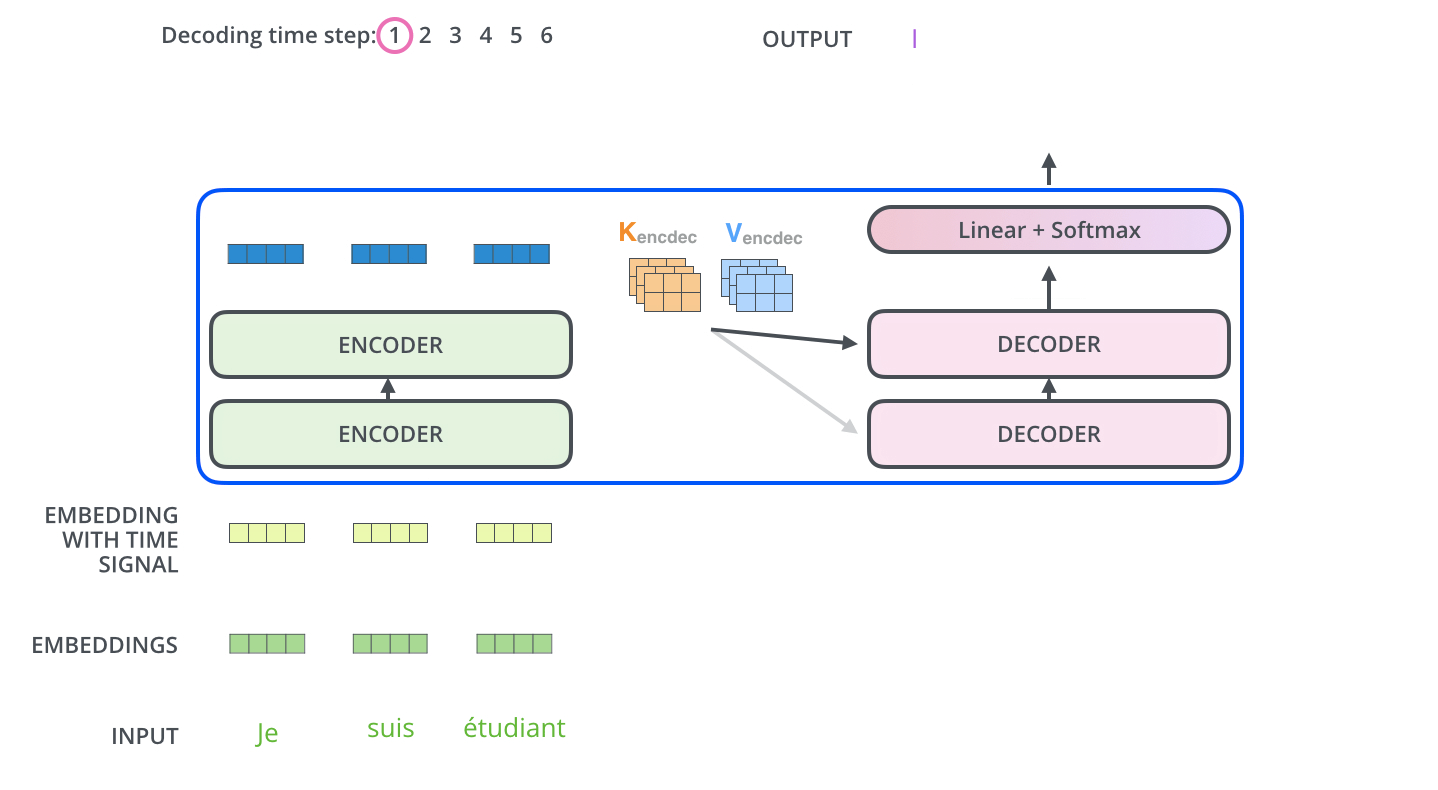
\*본 템플릿은 DSBA 연구실 이유경 박사과정의 템플릿을 토대로 하고 있습니다. Task: Recurrent와 Convolution을 배제한 Attention 메커니즘 모델 Transformer이전의 시퀀스 변형 모델은 RNN과 CNN을 기반으로 인코더와 디코더를
2023년 4월 23일
2.네이버 부스트캠프 5기 5주차 주간 회고

NLP Word Embedding One-hot vector >각 Token을 자기 자신을 1로 만들고 나머지를 0으로 만든다. 이떄 각 Token의 길이는 전체 Vocab size가 됨으로 각 token간의 차원이 매우 커짐으로써 차원의 저주에 걸리게 된다. Wo
2023년 4월 23일