
NLP
Word Embedding
One-hot vector
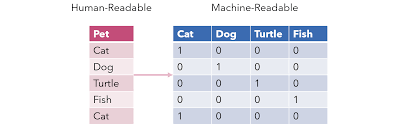
각 Token을 자기 자신을 1로 만들고 나머지를 0으로 만든다. 이떄 각 Token의 길이는 전체 Vocab size가 됨으로 각 token간의 차원이 매우 커짐으로써 차원의 저주에 걸리게 된다. 또한 각 단어들의 연관성을 표현할수 없어 이는 딥러닝에 상당히 큰 문제점이 생기며 vocab사이즈 만큼의 차원이므로 연산량도 상당히 많게 된다.
Word2Vec
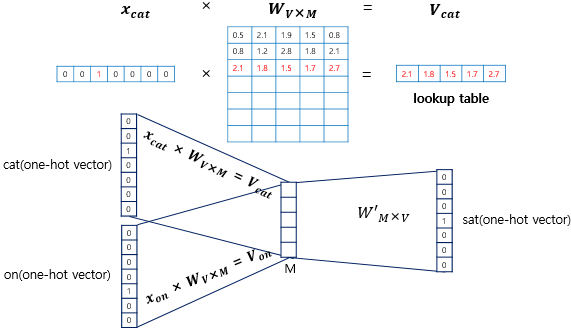
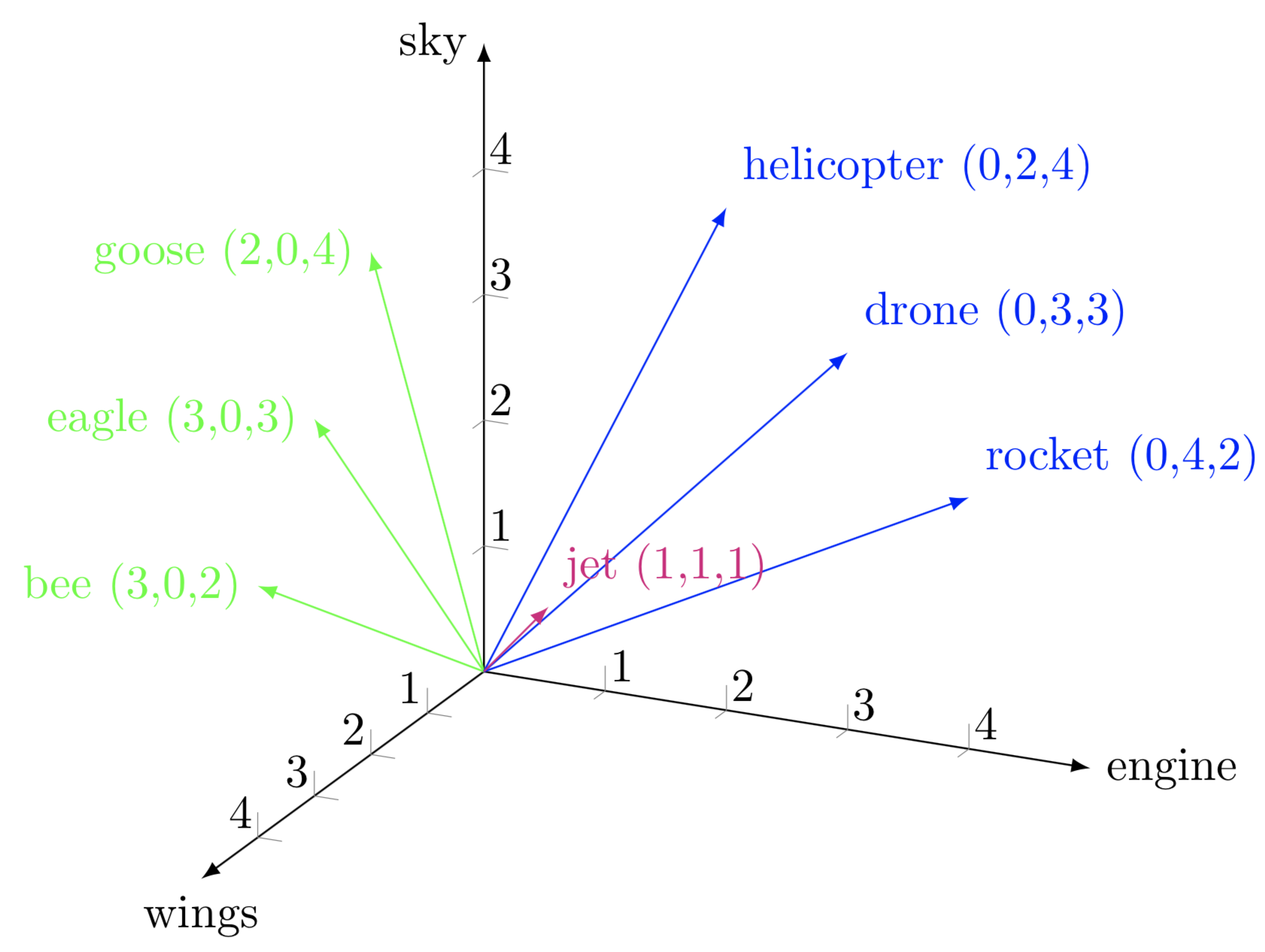
기존 One-hot-vector의 문제점을 회피하기 위해 단순 정수(1,0,0,0,0,)인코딩이 아닌 벡터로 표현하게 된다. 실제 구현에서는 각 토큰이 한개의 정수로 표현되며 이를 nn.Embedding을 통하여 일정 차원 (batch_soize,token,embedding)차원으로 표현하게 된다 즉 기존 One-hot 방식은 각 토큰이 Vocab Size 만큼의 차원을 가지게 되는데 Embedding을 통하여 Embedding 만큼의 차원으로 표현함으로 차원의 저주와 연산량 그리고 그림처럼 단어들의 연관성을 해결하였다.
LSTM GRU
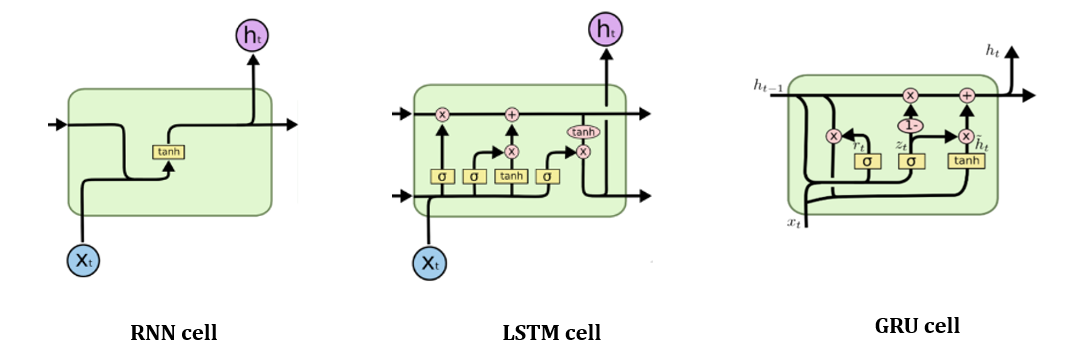
기존 다른글에서도 설명이 되어있지만 이전 글
기본적으로 LSTM과 GRU 모두 동일하게 RNN의 Long-Term Dependency를 해결하기 위해 고안되었다.
RNN의 경우 이전 가 영향을 주게 되며 이 정보가 중첩적으로 쌓이게 되는데 이렇게 되면 가장 처음에 나온 정보들이 점점 사라지게 된다. 또한 역전파시 합성함수 미분의 과정에서 time step 마다 접선의 기울기가 곱해져 Gradient Exploding 이 발생하게 된다.
LSTM은 기본적으로 Forget gate, Input gate, Output gate로 구성되어 있으며 기존의 말고도 가 추가되어 정보의 손실을 더 적게 만든다.
GRU는 LSTM이 높은 연산량을 가지는 반면 이를 경량화한 버전이라고 볼 수 있다.
기본적으로 Reset Gate, Update Gate로 이루어져 있으며 핵심으로 우리나라의 '조경현' 박사님이 제안한 구조다
Seq2Seq with attention
Seq2Seq 와 Seq2Seq with Attention은 기존의 논문리뷰로 대체하겠습니다.(좋음 ★★★)
Transformer
Transformer 같은 경우 글과 논문리뷰로 대체하겠습니다.(좋음 ★★★★★)
Self-supervised Pre-training Models
기존 방식과 다르게 label이 지정되지 않아있어도 대량의 데이터로 부터 학습할 수 있는 기법이다.
NLP 모델들로는 크게 BERT,GPT가 있으며 BERT는 Masking 기법으로 주로 문장의 빈칸을 채우는 기법으로 학습되었으며 GPT는 기계 독해를 기반으로 학습을 진행한다.
BERT
추후 논문 리뷰로 대체 예정
https://velog.io/@tm011899/BERT-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0%EC%93%B0%EB%8A%94%EC%A4%91
GPT
추후 논문 리뷰로 대체 예정
개인 회고
대회랑 논문리뷰때문에 하루하루 글을 쓰는것이 불가능하다고 판단하여 일주일에 1개씩 쓰는거로 변경을 하였다.
내가 너무 게으르게 하는지는 잘 모르겠지만 일단은 주에 하나라도 기록을 남기는 습관을 들여놔야겠다..
대부분의 이번주차 내용은 기존의 논문리뷰로 진행되었으며 추후 BERT와 GPT 모두 논문 리뷰를 할 예정이라 그때 더 자세히 써놔야겠다. 내용자체는 솔직히 LSTM보다 트랜스포머가 이해하기가 더 쉬운편인거 같은 느낌이 든다.. 하루하루 머리에 늘어나는건 많은데 정리가 조금 덜된느낌이지만 그래도 얼른 더 배워서 멀티모달에 쓰고싶다.
