JPA 소개
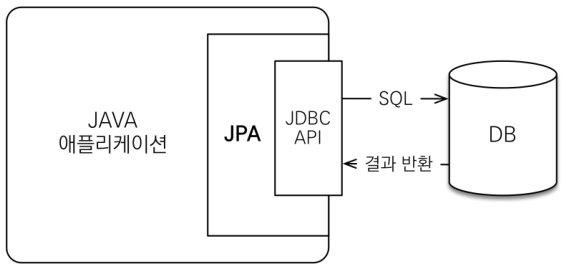
JPA(Java Persistent API)는 자바 진영의 ORM 기술 표준입니다. ORM(Object Relational Mapping)이란 객체는 객체대로, 관계형 DB는 관계형 DB대로 설계하고 중간에서 ORM 프레임워크가 매핑 역할을 수행하는 것을 가르킵니다. JPA는 Application과 JDBC(Java Database Connectivity) 사이에서 동작합니다.
왜 JPA를 사용해야 하는가
-
SQL 중심적인 개발 → 객체 중심적인 개발
JPA가 등장하기 전, 객체를 관계형 DB에 관리하기 위해서는 반복적인 SQL을 써야합니다. 더불어서 객체 Field가 수정된다면 그에 맞추어 SQL도 수정해야 합니다. 이는 결국 개발을 SQL에 의존적으로 하게끔 되었습니다.
-
생산성
CRUD 작업이 많이 간결화됩니다.
- Create:
jpa.persist(member) - Read:
Member member = jpa.find(memberId) - Update:
member.setName("변경할 이름") - Delete:
jpa.remove(member)
- Create:
-
유지보수
어느 객체의 Field가 변경되면 관련 모든 SQL을 수정하는 것에서 단순히 Field만 추가하면 JPA가 알아서 SQL를 맞게 수정합니다.
-
패러다임의 불일치 해결
객체 지향 프로그래밍은 추상화, 캡슐화, 정보은닉, 상속, 다형성 등의 다양한 장치들을 제공합니다. 그리고 이러한 객체를 보관하는 현실적인 대안은 관계형 DB입니다. 여기서 다음과 같은 객체와 관계형 DB의 차이로 인해 SQL 매핑이 필요합니다.
-
상속
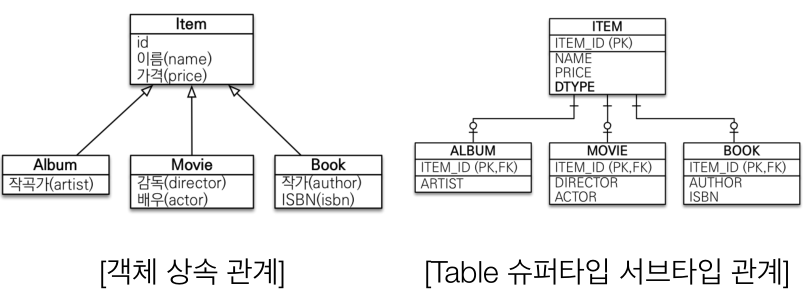
만약
Item객체를 상속받는Album객체를 DB에 저장한다면, 객체를 테이블에 맞추어 분해하고 각 테이블에INSERTSQL을 날려줘야 합니다. 그리고Album객체를 DB에서 조회한다면, 각각의 테이블에 따른JOINSQL을 작성하고 객체를 생성 후 합치는 과정을 거쳐야 합니다. -
연관관계
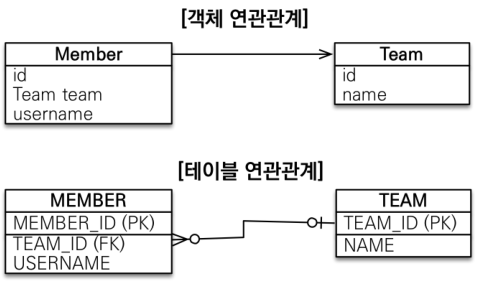
객체의 경우
참조를 사용해서member.getTeam()처럼 연관관계를 정하지만, 테이블은 FK(Foreign Key)를 사용하여JOIN ON M.TEAM_ID = T.TEAM_ID처럼 표현합니다. 때문에 객체를 개발할 때 테이블에 맞추어 모델링을 하는 경우가 많습니다. 즉,Team teamField 대신에 FK인Long teamIdField를 두어서 설계합니다. 결국 점점 SQL에 의존적으로 진행됩니다. -
객체 그래프 탐색과 Entity 신뢰 문제
객체는 자유롭게 객체 그래프를 탐색할 수 있어야 합니다. 하지만 DB와의 연관관계 차이때문에 신뢰 문제가 발생합니다.
SELECT M.*, T.* FROM MEMBER M JOIN TEAM T ON M.TEAM_ID = T.TEAM_IDclass MemberService { ... public void process(String memberId) { Member member = memberDAO.find(memberId); member.getTeam(); // OK? member.getOrder().getDelivery(); // ??? } }처음 실행하는 SQL에 따라 탐색할 범위를 결정하고 그에 맞추어 객체를 생성하여 사용합니다. 그러나 연관관계에 있는 모든 객체들을 미리 로딩할 수는 없기 때문에, SQL을 날린 시점에 객체에 어느 연관관계가 존재하고 존재하지 않는 지에 대해 판단할 수 없는 문제가 발생하여 Entity를 신뢰할 수 없게 됩니다. 결국 계층형 아키텍처를 설계하더라도 진정한 의미의 계층 분할이 어렵습니다.
-
객체 비교
String memberId = "100"; Member member1 = memberDAO.getMember(memberId); Member member2 = memberDAO.getMember(memberId); // member1 == member2 ??? 두 객체는 다르다. public Member getMember(String memberId) { String sql = "SELECT * FROM MEMBER WHERE MEMBER_ID = ?"; // JDBC API, SQL 실행 return new Memeber(...); }기존의 방식으로 같은 ID를 가진 객체를 조회하려고 하더라도, 매번 새로운 객체를 생성하기 때문에 서로 다른 객체가 반환됩니다.
정리해보면, 객체답게 모델링 할수록 SQL과 매핑하는 작업만 늘어나게 되어 SQL에 의존적으로 설계하게 되는 문제가 발생합니다. JPA는 객체를 마치
List와 같은 자바 컬렉션에 저장하듯이 DB에 저장해서 문제를 해결합니다. -
-
성능
-
1차 캐시와 동일성 보장
String memberId = "100"; Member member1 = jpa.find(Member.class, memberId); // SQL Member member2 = jpa.find(Member.class, memberId); // Cache같은 트랜잭션 안에서는 캐싱을 통해 같은 Entity를 반환합니다.
-
트랜잭션을 지원하는 쓰기 지연(Transactional Write-behind)
transcation.begin(); // 트랜잭션 시작 em.persist(memberA); em.persist(memberB); em.persist(memberC); // 여기까지 INSERT SQL을 DB에 보내지 않고 모은다. transaction.commit(); // 트랜잭션 커밋하는 순간 DB에 SQL을 보낸다.트랜잭션을 커밋할 때까지 SQL을 모으다가 JDBC BATCH SQL 기능을 사용해서 모은 SQL을 한번에 전송합니다.
-
즉시 로딩과 지연 로딩
Member member = memberDAO.find(memberId); Team team = member.getTeam(); String teamName = team.getName();/* 즉시 로딩 */ -- find() 실행 시 SELECT M.*, T.* FROM MEMBER JOIN TEAM ... /* 지연 로딩 */ -- find() 실행 시 SELECT * FROM MEMBER -- team name이 변수에 저장될 때 SELECT * FROM TEAM즉시 로딩은JOINSQL로 한번에 연관된 객체까지 미리 조회하고,지연 로딩은 객체가 실제로 사용될 때 로딩됩니다.
-
-
데이터 접근 추상화 벤더 독립성
JPA는
interface들의 집합으로써 특정 DB에 종속적이지 않습니다. 각각의 DB가 제공하는 SQL 문법과 함수는 조금씩 다르기 때문에 Application 개발 시 사용하는 DB에 맞추어 JPA에 DB Dialect(방언)을 설정해주면 대부분의 DB를 사용할 수 있습니다.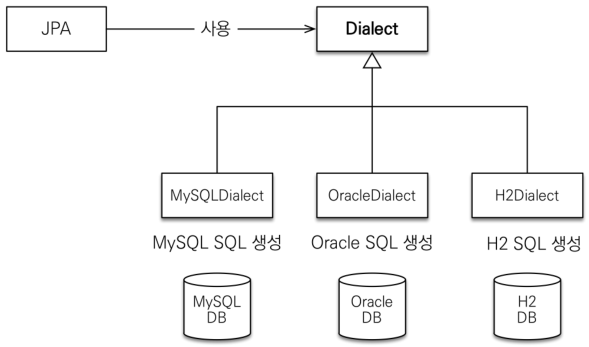
JPA 기본 세팅
JPA 설정 정보
어떻게 JPA를 사용하겠다라는 정보를 persistence.xml 파일에 적어줘야 합니다.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<property name="javax.persistence.jdbc.driver" value="org.h2.Driver"/>
<property name="javax.persistence.jdbc.user" value="sa"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/~/test"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<!-- 옵션 -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.use_sql_comments" value="true"/>
<!--<property name="hibernate.hbm2ddl.auto" value="create" />-->
</properties>
</persistence-unit>
</persistence>- 이 파일은
/META-INF/경로에 위치해야합니다. persistence-unit의name속성으로 이름을 지정합니다.property로 사용할 DB와 드라이버 정보를 설정합니다.
JPA 구동 방식
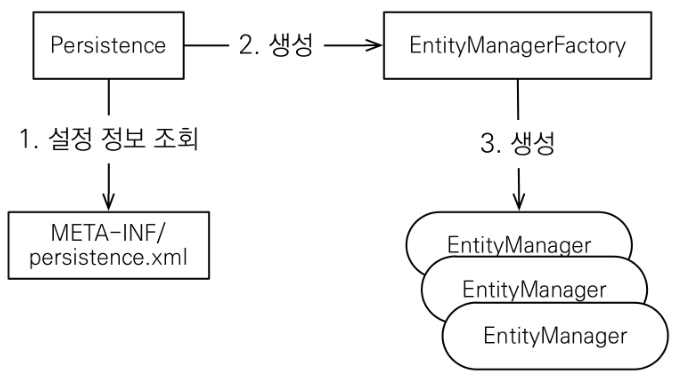
- 먼저
persistence.xml파일을 조회해서 설정에 맞게 DB를 구성합니다. - DB에 접근할 때 매번 커넥션을 생성해주는
EntityManagerFactory를 생성합니다. 이는 각 DB당 하나만 생성해서 Application 전체에서 공유해야 합니다. - 각 커넥션(액세스) 때마다
EntityManager가 생성되어 트랜잭션을 처리한 후 소멸됩니다. 이는 쓰레드 간에 공유하면 안되며 각각의 커녁션마다 생성하고 다 사용했다면 버려야 합니다.
JPA 동작 확인
public static void main(String[] args) {
// persistence.xml의 persistence-unit name 속성과 일치해야 한다.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
// 각 액세스마다 생성한다.
EntityManager em = emf.createEntityManager();
// JPA의 모든 데이터 변경은 트랜잭션 안에서 실행되어야 한다.
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
/*
* create new member
*/
Member newMember = new Member();
newMember.setId(1L);
newMember.setName("memberA");
em.persist(newMember);
/*
* read member
*/
Member findMember = em.find(Member.class, 1L);
System.out.println("findMember = " + findMember.getId() + ": " + findMember.getName());
/*
* update member
*/
Member updateMember = em.find(Member.class, 1L);
updateMember.setName("memberX");
/*
* delete member
*/
Member deleteMember = em.find(Member.class, 1L);
em.remove(deleteMember);
/*
* read all members by JPQL
* SQL은 DB 테이블을 대상으로 쿼리를 작성하지만
* JPQL은 객체를 대상으로 검색하는 객체 지향 쿼리이다.
*/
List<Member> members = em.createQuery("select m from Member as m", Member.class)
.getResultList();
for (Member member: members) {
System.out.println("member = " + member.getId() + ": " + member.getName());
}
// SQL을 모와서 한번에 보낸다.
tx.commit();
} catch (Exception e) {
// error가 발생한다면 DB를 롤백한다.
tx.rollback();
} finally {
// DB 커넥션을 닫는다.
em.close();
}
emf.close();
}영속성 관리
JPA에서 가장 중요한 2가지는 영속성 Context과 객체와 관계형 DB 매핑입니다.
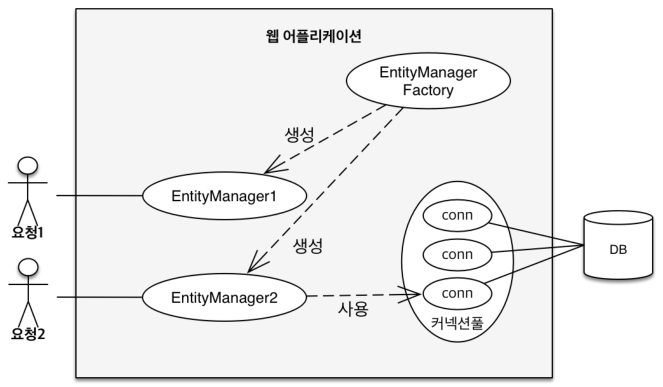
영속성 Context
Entity를 영구 저장하는 환경이라는 의미로, 눈에 보이지 않는 논리적인 개념입니다. EntityManage를 통해서 영속성 Context에 접근합니다. 이를 구조도로 표현하면 아래와 같습니다.
영속성 생명주기
-
비영속(new/transient)영속성 Context와 전혀 관계가 없는 새로운 상태를 의미합니다.
-
영속(managed)JPA를 통해 객체가 영구 저장(DB에서 관리)된 상태를 의미합니다.
-
준영속(detached)영속 상태였던 객체를 영속성 Context에서 분리한 상태를 의미합니다.
-
삭제(removed)객체를 삭제한 상태를 의미합니다.
// 객체를 생성: 비영속 Member member = new Member(); member.setId("membeA"); member.setName("Joon"); EntityManager em = emf.createEntityManager(); em.getTransaction().begin(); // 객체를 저장: 영속 em.persist(member); // 객체를 분리: 준영속 em.detach(member); // 객체를 제거: 삭제 em.remove(member);
사용 시 이점
대부분 위에서 설명한 JPA 사용 시의 이점과 유사합니다.
-
1차 캐시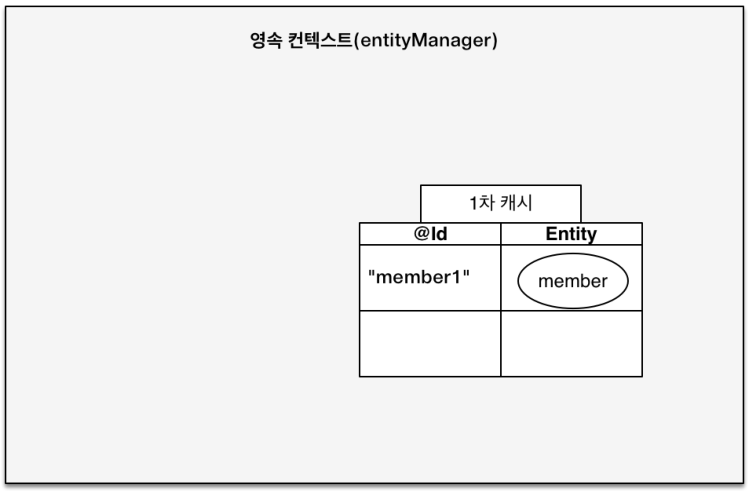
em.persist(member)로 객체를 영속화하면 각EntityManager에서 관리하는 1차 캐시에 객체를 저장합니다. 실제 DB에 저장되는 시점은 트랜잭션이 Commit될 때이므로 같은 트랜잭션에서 객체가 변경되는 정보들을 모와서 한번에 쿼리를 날립니다.Member member = new Member(); member.setId("memberA"); // 1차 캐시에 저장 em.persist(member); // 1차 캐시에서 조회 (SELECT query 필요 x) Member findMember1 = em.find(Member.class, "memberA"); // DB에서 조회 (SELECT query 실행) Member findMember2 = em.find(Member.class, "memberB");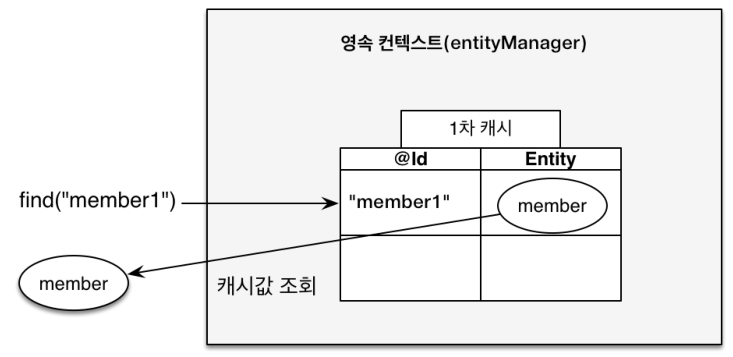
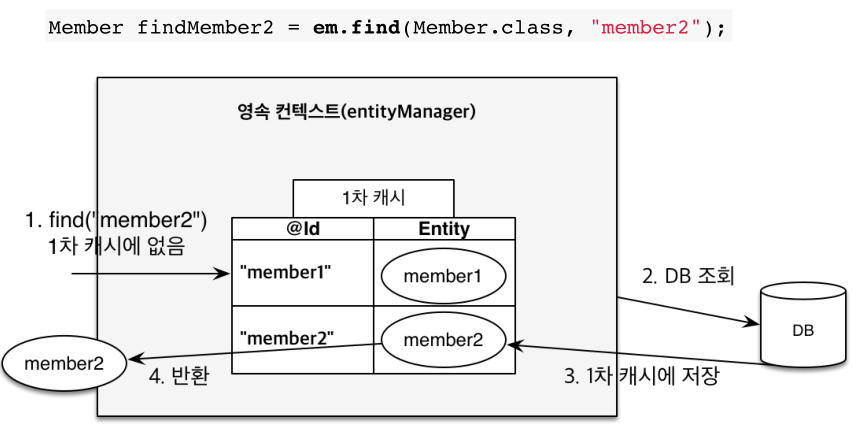
그리고 객체를 가져오는 방법은 먼저 1차 캐시에서 조회한 후, 캐시에 없다면 DB에 접근해서 조회합니다.
이 개념을 조금 더 깊이 생각해보면 객체를 비교하는 두 가지 경우를 생각해볼 수 있습니다.
-
같은
EntityManager에서 비교하는 경우Member findMember1 = em.find(Member.class, "memberA"); // DB에서 조회 (SELECT query 실행) System.out.println("findMember1 = " + findMember1.getId() + ": " + findMember1.getName()); // print "findMember1 = memberA: Joon" Member findMember2 = em.find(Member.class, "memberA"); // 1차 캐시에서 조회 (SQL 필요 x) System.out.println("findMembe2r = " + findMember2.getId() + ": " + findMember2.getName()); // print "findMember2 = memberA: Joon" System.out.println("is Equal ? " + (findMember1 == findMember2)); // true -
다른
EntityManager에서 비교하는 경우Member findMember1 = em1.find(Member.class, "memberA"); // DB에서 조회 (SELECT query 실행) System.out.println("findMember1 = " + findMember1.getId() + ": " + findMember1.getName()); // print "findMember1 = memberA: Joon" Member findMember2 = em2.find(Member.class, "memberA"); // DB에서 조회 (SELECT query 실행) System.out.println("findMember2 = " + findMember2.getId() + ": " + findMember2.getName()); // print "findMember2 = memberA: Joon" System.out.println("is Equal ? " + (findMember1 == findMember2)); // false두 경우 모두 출력되는 결과는 같지만 같은
EntityManager에서 조회한 경우 동일한 객체이고, 다른EntityManager에서 조회한 경우 다른 객체입니다.
-
-
트랜잭션을 지원하는 쓰기 지연(transcational write-behind)EntityManager em = enf.createEntityManager(); EntityTransaction tx = em.getTransaction(); tx.begin(); // EntityManager는 데이터 변경 시 트랜잭션을 시작해야 한다. em.persist(memberA); em.persist(memberB); // 여기까지 DB에 SQL을 보내지 않는다. tx.commit(); // Commit하는 순간 DB에 SQL을 한 번에 보낸다.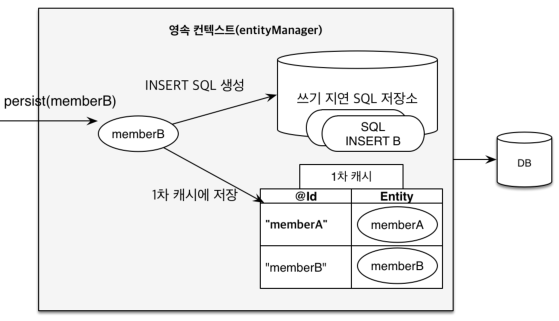
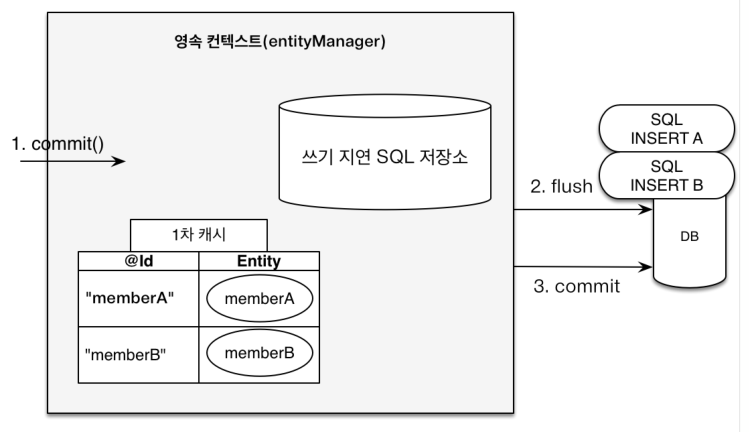
하나의 트랜잭션을 기준으로 영속성 Context가 관리하는 객체에 변경된 정보들을 모두 모와서
쓰기 지연 SQL 저장소에 각 SQL을 저장해놓고, Commit되는 순간 DB에 SQL을 보냅니다. -
변경 감지(Dirty checking)EntityManager em = enf.createEntityManager(); EntityTransaction tx = em.getTransaction(); tx.begin(); Member member = em.find(Member.class, "memberA"); // 영속 Entity 조회 member.setName("PSH"); // 영속 Entity 수정 // em.update(member)와 같은 코드가 추가로 필요하지 않다. member.setName("psh"); // 영속 Entity 수정 // 아직까지는 SQL가 보내지지 않는다. tx.commit(); // flush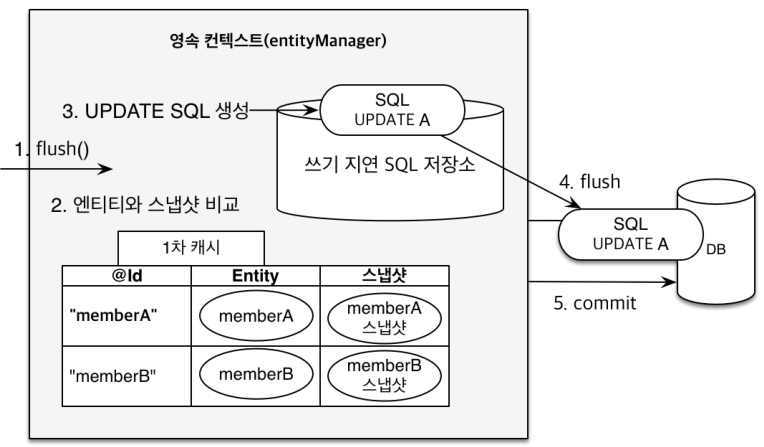
영속성 Context에서 관리하는 객체에 정보 변경이 생긴 경우, 1차 캐시에 저장되어 있는 스냅샷과 비교를 하고 달라진 부분에 맞게 SQL을 생성해서
쓰기 지연 SQL 저장소에 저장합니다. 그리고 Commit되는 순간 Flush합니다.여기서
Flush란 영속성 Context의 변경 내용을 DB에 반영하는 것을 의미합니다. 종종 용어 때문에 반영 후 1차 캐시를 비우는 것으로 오해하는 경우가 있는데,Flush되더라도 1차 캐시는EntityManager의close()혹은clear()등의 메서드가 호출되지 않는 이상 유지됩니다.em.flush()호출되거나, 트랜잭션이 Commit되거나, JPQL이 실행되는 경우Flush가 동작합니다.
아래는 영속성 Context 개념을 활용한 예제 코드입니다.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em1 = emf.createEntityManager();
EntityTransaction tx1 = em1.getTransaction();
tx1.begin();
Member member1 = em1.find(Member.class, "memberA"); // SELECT query 실행, em1의 1차 캐시에 저장
System.out.println("member1 = " + member1.getId() + ": " + member1.getName());
// print "member1 = memberA: Joon"
member1.setName("PSH"); // em1의 1차 캐시에 반영, UPDATE query 아직 실행 x
System.out.println("member1 = " + member1.getId() + ": " + member1.getName());
// print "member1 = memberA: PSH"
EntityManager em2 = emf.createEntityManager();
EntityTransaction tx2 = em2.getTransaction();
tx2.begin();
Member member2 = em2.find(Member.class, "memberA"); // SELECT query 실행, em2의 1차 캐시에 저장
System.out.println("member2 = " + member2.getId() + ": " + member2.getName());
// print "member2 = memberA: Joon" (위의 tx는 commmit되지 않았으므로 field가 update되지 않음)
tx1.commit(); // UPDATE query 실행
em1.close();
member2 = em2.merge(member1); // em2의 1차 캐시에 반영, UPDATE query 아직 실행 x
System.out.println("member2 = " + member2.getId() + ": " + member2.getName());
// print "member2 = memberA: PSH"
tx2.commit(); // UPDATE query 실행 (실제로는 DB와 같은 객체이지만 1차 캐시의 스냅샷과 다르므로 flush)
em2.close();
System.out.println("is Equal ? " + (member1 == member2));
// print "is Equal ? false"
emf.close();Entity 매핑
객체와 테이블 매핑
@Entity가 붙은 클래스는 JPA가 관리하며, 이를 Entity라고 합니다. Entity의 경우 기본 생성자가 필수이며 당연하게도final과 같은 field가 있으면 안됩니다.@Table은 Entity와 매핑할 테이블 지정합니다.name속성으로 매핑할 테이블 이름을 정할 수 있고, 기본값은 Entity 이름입니다. 이외에도catalog,schema,uniqueConstraints등의 옵션이 있습니다.
JPA는 DB schema 자동 생성 옵션이 있습니다. 해당 옵션에 따라서 DB Dialect를 활용해서 DDL(Data Define Language)을 애플리케이션 실행 시점에 자동으로 생성해줍니다. persistence.xml 설정 파일에서 정할 수 있습니다.
-
create<!-- 기존 테이블 삭제 후 다시 생성한다. --> <property name="hibernate.hbm2ddl.auto" value="create" /> -
create-drop<!-- create와 유사하나 종료 시점에 테이블을 삭제한다. --> <property name="hibernate.hbm2ddl.auto" value="create-drop" /> -
update<!-- 변경분만 반영 Field가 추가되면 alter DDL을 보낸다. Field가 삭제되더라도 별도의 DDL을 보내지 않는다. --> <property name="hibernate.hbm2ddl.auto" value="update" /> -
validate<!-- Entity와 테이블이 정상 매핑되었는지만 확인 Entity의 Field와 테이블의 Column이 다르면 Error 발생 --> <property name="hibernate.hbm2ddl.auto" value="validate" />
실제 운영 장비에는 create, create-drop, update 옵션을 사용하면 기존 테이블을 삭제하거나 변경하므로 절대 사용하면 안되고 웬만하면 Schema 자동 생성 옵션을 사용하지 않는 것이 좋습니다.
Field와 Column 매핑
Entity의 Field와 DB의 Column을 매핑할 때 사용하는 annotation과 속성이 있습니다.
@Entity
@Table(name = "MEMBER")
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(name = "name", nullable = false)
private String username;
private Integer age;
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
private LocalDateTime lastModifiedDate;
@Lob
private String description;
@Transient
private int temp;
}-
@Column속성 설명 기본값 name Field와 매핑할 테이블의 Column 이름 객체의 Field 이름 insertable / updatable 등록 / 변경 가능 여부 TRUE nullable(DDL) null 값의 허용 어부를 결정 TRUE unique(DDL) 하나의 Column에 unique 제약 조건을 설정
(@Table의uniqueConstraints와 역할은 유사)columnDefinition(DDL) DB Column 정보를 직접 설정
(ex. "varchar(100) default 'EMPTY'")length(DDL) String 타입의 문자 길이 제약 조건 설정 255 precision / scale (DDL) BigDecimal 타입에서 표현 정도를 설정 precision=19 / scale=2 -
@Temporal자바 날짜 타입을 매핑할 때 사용합니다. 근래 들어서는
LocalDate,LocalDateTime을 타입으로 하면, 최신 하이버네이트가 지원하기 때문에 annotation을 생략할 수 있습니다.속성 설명 value - TemporalType.DATE: 날짜 / DB의 date타입과 매핑 (ex. 2021-01-04)
- TemporalType.TIME: 시간 / DB의time타입과 매핑 (ex. 08:55:42)
- TemporalType.TIMESTAMP: 날짜와 시간 / DB의timestamp타입과 매핑 (ex. 2021-01-04 08:55:42) -
@Enumerated자바
enum타입을 매핑할 때 사용합니다. 다만 추후 요소가 추가될 경우를 대비해, DB 공간을 조금 더 차지하더라도EnumType.STRING을 사용해야 합니다.속성 설명 기본값 value - EnumType.ORDINAL: enum순서를 DB에 저장
- EnumType.STRING:enum이름을 DB에 저장EnumType.ORDINAL -
@LobDB의
BLOB,CLOB타입과 매핑합니다. 이 annotation에는 별도로 지정할 수 있는 속성이 없습니다. 매핑하는 Field 타입이 문자면CLOB, 나머지는BLOB으로 매핑합니다. -
@Transient주로 메모리상에서만 임시로 어떤 값을 보관하고 싶은 경우처럼, 매핑하지 않을 Field에 사용합니다.
기본 Key 매핑
Entity를 식별할 수 있는 Key를 매핑할 때 사용할 수 있는 annotation(@Id, @GeneratedValue)과 속성(전략)이 있습니다.
-
직접 할당
@Entity public class Member { @Id private Long id; }Key로 매핑할 Field에
@Idannotation만 사용하면 됩니다. -
자동 생성
Entity 객체 생성 시 자동으로 Key를 정해주는 방법으로, 각 전략에 따라서 자동 생성됩니다.
-
IDENTITY
@Entity public class Member { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; }기본 Key 생성을 DB에 위임하는 전략입니다.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello"); EntityManager em = emf.createEntityManager(); EntityTransaction tx = em.getTransaction(); tx.begin(); Member member = new Member(); em.persist(member); // 원래는 아직은 SQL이 보내지지 않지만, IDENTITY 전략을 사용할 경우 바로 SQL이 실행된다. tx.commit();다만 여기서 문제는 해당 Entity를 DB에 저장해야만 기본 Key를 알 수 있다는 점입니다. JPA는 트랜잭션을 Commit 하기 전까지 1차 캐시에 Entity들을 보관하는데,
IDENTITY전략으로 Key가 자동 생성된다면 Commit하기 전까지 Key를 알 수 없게 되어, 1차 캐시 활용을 제대로 못하기 때문입니다. 따라서 예외적으로 이 전략으로 설정된 Entity의 경우, JPA는persist()메서드 호출되면 바로 SQL을 보내서 Key를 받아옵니다. -
SEQUENCE
@Entity @SequenceGenerator( name = "MEMBER_SEQ_GENERATOR", sequenceName = "MEMBER_SEQ", // 매핑할 DB Sequence 이름 initialValue = 1, allocationSize = 1) public class Member { @Id @GeneratedValue( strategy = GenerationType.SEQUENCE, generator = "MEMBER_SEQ_GENERATOR") private Long id; }Key에 알맞는 유일한 값을 순서대로 생성하는 특별한 DB Object인 DB Sequence를 이용해 자동 생성하는 전략입니다.
@SequenceGenerator에 사용할 수 있는 속성은 다음과 같습니다.속성 설명 기본값 name 식별자 생성기 이름 필수 sequenceName DB에 등록되어 있는 Sequence 이름 hibernate_sequence initialValue Sequence DDL을 생성할 때 시작하는 수 지정
(DDL 생성 시에만 사용)1 allocationSize Sequence 호출 한 번에 증가하는 수
(DB Sequence 값이 하나씩 증가하도록 설정되어 있다면
이 값을 반드시 1로 설정)50 catalog / schema DB catalog, schema 이름 여기서
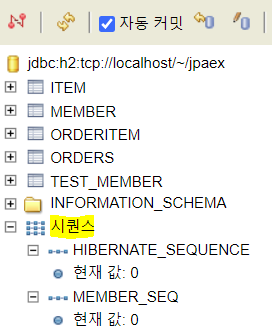
allocationSize의 기본값이 50인 이유는 성능 최적화를 위함입니다.SEQUENCE전략도 위와 마찬가지로 DB에 Entity를 저장해야만 Key를 알 수 있는데, 이는 매번 저장할 때마다 SQL을 보내야함을 의미합니다. 때문에 성능 문제를 고려하여 JPA는 한 번에 Sequence를 DB로 부터 받아와서 Entity의 Key Field에 할당 가능한 Sequence를 메모리에 보관합니다.initialValue가 1인 경우,allocationSize에 크기만큼 Sequence를 받아오고, DB Sequence에는 size만큼 증가시켜놓습니다. Size가 너무 큰 경우, 중간에 Sequence가 낭비될 수 있기 때문에 주로 50 혹은 100으로 정해서 사용합니다.EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello"); EntityManager em = emf.createEntityManager(); EntityTransaction tx = em.getTransaction(); tx.begin(); Member member1 = new Member(); em.persist(member1); // call next value for MEMBER_SEQ: DB Sequence로 부터 정해진 Size만큼 받아온다. System.out.println("member = " + member1.getId()); // print "member = 1": 할당 가능한 범위 내에서 Entity의 Key Field에 값 순서대로 설정 Member member2 = new Member(); em.persist(member2); // call 필요 없음 System.out.println("member = " + member2.getId()); // print "member = 2": 할당 가능한 범위 내에서 Entity의 Key Field에 값 순서대로 설정 Member member3 = new Member(); em.persist(member3); // call 필요 없음 System.out.println("member = " + member3.getId()); // print "member = 3": 할당 가능한 범위 내에서 Entity의 Key Field에 값 순서대로 설정 tx.commit();H2의 경우, DB Sequence는 다음처럼 확인 가능합니다.
-
-
TABLE
@Entity @TableGenerator( name = "MEMBER_SEQ_GENERATOR", table = "MY_SEQUENCES", pkColumnValue = "MEMBER_SEQ", allocationSize = 1) public class Member { @Id @GeneratedValue( strategy = GenerationType.TABLE, generator = "MEMBER_SEQ_GENERATOR") private Long id; }Key 생성 전용 테이블을 하나 만들어서, DB Sequence를 흉내내는 전략입니다. 모든 DB에 적용 가능하지만, 성능 문제가 발생할 수 있습니다.
@TableGenerator에 사용할 수 있는 속성은 다음과 같습니다.속성 설명 기본값 name 식별자 생성기 이름 필수 table Key 생성 테이블 명 hibernate_sequences pkColumnName Sequence Column 명 sequence_name valueColumnNa Sequence 값 Column 명 next_val initialValue 시작하는 수 지정 0 allocationSize Sequence 호출 한 번에 증가하는 수 50 catalog / schema DB catalog / schema uniqueConstraints(DDL) Unique 제약 조건 지정 -
AUTO
기본 전략으로, DB Dialect에 따라 자동 지정됩니다.
연관관계 매핑 기초
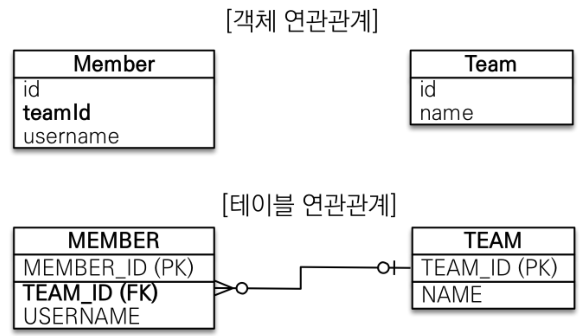
이 파트에서는 무엇보다도 객체와 관계형 DB의 테이블 연관관계의 차이를 이해하는 것이 핵심입니다. 먼저 테이블 연관관계에만 중점을 둬서 객체를 모델링 해보겠습니다. 예시로 회원 Entity와 팀 Entity가 있고, 테이블 상에서는 MEMBER 테이블이 TEAM 테이블을 참조하여 연관관계가 짜여 있는 경우에는 아래처럼 모델링됩니다.
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBR_ID")
private Long id;
private String name;
@Column(name = "TEAM_ID")
private Long teamId;
}@Entity
public class Team {
@Id
@GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
}Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setName("memberA");
member.setTeamId(team.getId());
em.persiste(member);
Member findMember = em.find(Member.class, member.getId());
Team findTeam = em.find(Team.class, team.getId());
// 두 객체 간의 연관관계가 없다.코드를 보면 알 수 있듯이, FK(Foreign Key)를 Field로 두어서 객체를 테이블에 맞추어 모델링을 합니다. 이렇게 모델링이 되면 비즈니스 로직에서는 객체 간의 연관관계는 없는 상태가 됩니다. 테이블의 경우 FK로 JOIN해서 연관된 테이블을 찾고, 객체의 경우 참조를 통해 연관된 객체를 찾는, 서로 다른 연관관계 패러다임 때문입니다.
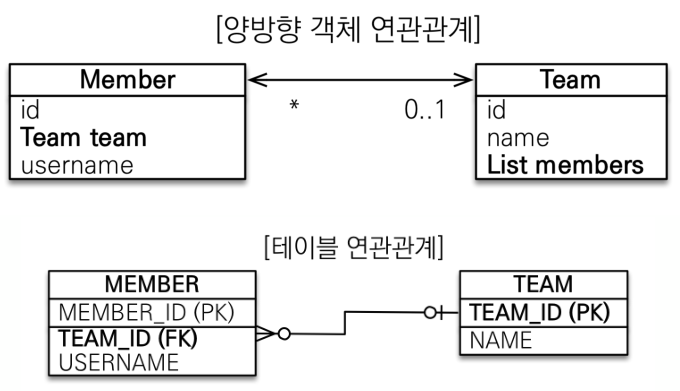
따라서 JPA에서는 객체의 연관관계를 사용하여 객체 지향 모델링을 지원합니다. 이번 예시는 회원 Entity와 팀 Entity가 N:1 관계로 서로를 양방향 참조하는 걸로 설명하겠습니다.
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}@Entity
public class Team {
@Id
@GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<>();
}Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setName("memberA");
member.setTeam(team);
em.persiste(member);
Member findMember = em.find(Member.class, member.getId());
Team findTeam = findMember.getTeam();
System.out.println("isEqual = " + (team == findTeam)); // true (1차 캐시에서 가져오기 때문)
List<Member> members = findTeam.getMembers();
for (Member m: members) {
System.out.println("m = " + m.getName());
}
// 참조를 사용해서 연관관계 조회 (객체 그래프 탐색 가능)회원 Entity에는 연관관계를 갖는 Team 객체 Field를 갖고, 팀 Entity에도 연관관계를 갖는 Member 객체 Field를 갖습니다. 이때 회원과 팀은 N:1 관계이므로 @ManyToOne, @OneToMany annotation으로 설정합니다. 여기서 중요한 부분은 두 Entity 연관관계의 주인을 정하는 것입니다.
연관관계의 주인이란, 비즈니스 로직 상의 상하관계와는 별도로, 단순히 테이블 구조 상에서 FK를 관리하는 Entity를 의미합니다. 위 예시에서 객체 연관관계는 사실 양방향 관계가 아니라 서로 다른 단반향 관계 2개인 것으로, 회원-->팀 1개와 팀-->회원 1개로 총 2개입니다. 그러나 테이블에서는 FK 하나로 두 테이블의 관계를 관리하여(사실 방향이라는 개념이 없습니다.), JOIN문으로 양쪽 정보를 가질 수 있습니다. 따라서 두 종류의 Entity 중 하나가 FK를 관리하도록 설정해야 합니다. 이게 연관관계의 주인인 것이고, 주인만이 FK를 관리하고, 주인이 아닌 쪽은 읽기만 가능합니다.
그래서 Member Entity의 Team Field에는 @JoinColumn으로 주인임을 나타내고, Team Field에는 mappedBy 속성으로 주인이 아님을 나타냅니다. 더불어서 이처럼 연관관계 매핑 되었을 때 생길 수 있는 문제를 살펴보겠습니다.
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member1 = new Member();
member1.setName("memberA");
member1.setTeam(team);
em.persist(member1);
Member member2 = new Member();
member2.setName("memberB");
member2.setTeam(team);
em.persist(member2);
Member member3 = new Member();
member3.setName("memberC");
team.getMembers().add(member3); // 역방향
em.persist(member3);
Team findTeam = em.find(Team.class, team.getId());
// flush되기 전이므로, 순수 객체상태로 member3만 list에 존재
List<Member> findTeamMembers = findTeam.getMembers();
for (Member m : findTeamMembers) {
System.out.println("m = " + m.getId() + ": " + m.getName());
}
em.flush();
em.clear();
// flush된 후이고 연관관계 주인은 Member이므로, member1과 member2만 list에
List<Member> members = findMember.getTeam().getMembers();
for (Member m : members) {
System.out.println("m = " + m.getId() + ": " + m.getName());
}현재 연관관계 주인은 회원이므로 영속화된 Entity는 FK를 갖고 있는 회원에 의해 관리되고 팀 Entity는 갱신된 회원 Entity에서 가져오는 것만(읽기만) 가능합니다. Flush되기 전, team이 참조하는 member로는 순수 객체 상태인 member3뿐이지만, Flush가 되어 영속화되면 역방향으로 참조한 member3는 무시되고 member1과 member2만 연관관계를 갖게 됩니다. 이 문제를 해결하기 위해, setTeam으로 단방향으로만 Field값을 주입하는 것 대신에 양쪽 모두 값을 넣어주는 연관관계 편의 메서드를 생성해서 설정해야합니다.
@Entity
public class Member {
...
public void addTeam(Team team) {
this.team = team;
team.getMembers().add(this);
}
}Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member1 = new Member();
member1.setName("memberA");
// member1.setTeam(team);
member1.addTeam(team);
em.persist(member1);
Member member2 = new Member();
member2.setName("memberB");
// member2.setTeam(team);
member2.addTeam(team);
em.persist(member2);
Member member3 = new Member();
member3.setName("memberC");
// team.getMembers().add(member3); // 역방향
member3.addTeam(team);
em.persist(member3);
Team findTeam = em.find(Team.class, team.getId());
// 양방향 모두 값을 설정해줬기 때문에, member1, member2, member3 모두 list에 존재
List<Member> findTeamMembers = findTeam.getMembers();
for (Member m : findTeamMembers) {
System.out.println("m = " + m.getId() + ": " + m.getName());
}
em.flush();
em.clear();
// flush된 후에도 양쪽 모두 값 설정이 되어 있기 때문에, member1, member2, member3 모두 list에 존재
List<Member> members = findMember.getTeam().getMembers();
for (Member m : members) {
System.out.println("m = " + m.getId() + ": " + m.getName());
}N:1 관계뿐만 아니라, 다른 관계 표현도 유사하게 나타낼 수 있습니다. 각 관계마다 유의할 점만 짚고 넘어가겠습니다.
-
N:1관계FK가 있는 쪽이 연관관계의 주인이 됩니다.
-
1:N관계이 경우
1이 연관관계의 주인이 되지만, 테이블의1:N관계는 항상N이 FK를 가지기 때문에 특이한 구조가 됩니다. 따라서 이를 위해 추가로UPDATESQL이 필요합니다. 이보다는,N:1양방향 매핑으로 풀어내는 것이 좋습니다. -
1:1관계두 테이블에 모두 FK가 위치할 수 있습니다. 주 테이블에 FK를 갖도록 모델링하는 게 일반적이며, 해당 Entity가 연관관계의 주인으로 설정합니다. 하지만 DBA 입장에서는 연관관계가 존재하지 않을 경우 FK에 null 값이 허용되기 때문에 상호 협의하여 모델링하는 게 좋습니다.
-
N:M관계관계형 DB에서는 정규화된 테이블 2개로
N:M관계를 표현할 수 없습니다. 중간에 연결 테이블을 추가해서1:N,M:1관계로 풀어내서 해결합니다. 하지만 JPA에서는 표준 기술 규격 문서에서@ManyToMany를 지원하며@JoinTable로 연결 테이블을 지정할 수 있습니다. 이는 편리해 보이지만 실무에서는 사용하면 안됩니다. 실제로는 연결 테이블이 단순히 연결 역할만 하고 끝나는 게 아니고 다른 데이터가 들어올 수 있기 때문에, 연결 테이블용 Entity를 추가하는 게 좋습니다.@Entity @Table(name = "ORDERS") public class Order { @Id @GeneratedValue @Column(name = "ORDER_ID") private Long id; @OneToMany(mappedBy = "order") private List<OrderItem> orderItems = new ArrayList<>(); @Enumerated(EnumType.STRING) private OrderStatus status; }@Entity public class Item { @Id @GeneratedValue @Column(name = "ITEM_ID") private Long id; private String name; private int price; private int stockQuantity; }@Entity public class OrderItem { @Id @GeneratedValue @Column(name = "ORDER_ITEM_ID") private Long id; @ManyToOne @JoinColumn(name = "ORDER_ID") private Order order; @ManyToOne @JoinColumn(name = "ITEM_ID") private Item item; private int orderPrice; private int count; }위의 예시처럼
Order와Item의 관계는N:M이기 때문에, 중간 연결 테이블 역할을 수행하는OrderItemEntity를 만들어서1:N,M:1관계로 풀어서 설정합니다. 물론 FK를 가지는 쪽이OrderItem이기 떄문에 연관관계의 주인은OrderItem이 됩니다. 이렇게 모델링하면, 연결 테이블에 필요한 Field를 추가할 수 있습니다.
심화 매핑
-
상속관계 매핑
관계형 DB는 상속 관계라는 것이 없지만, 슈퍼타입과 서브타입 관계는 객체 상속과 유사한 면이 있습니다. 즉 상속관계 매핑은 객체의 상속과 DB의 슈퍼타입/서브타입 관계를 매핑하는 것을 의미합니다. 아래 예시로 설명하겠습니다.
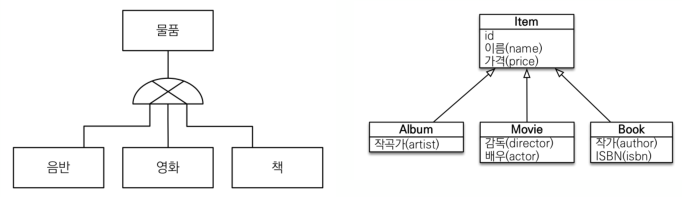
이런 논리 모델을 실제 물리 모델로 구현하는 방법은 크게 3가지가 있습니다.
-
JOINED전략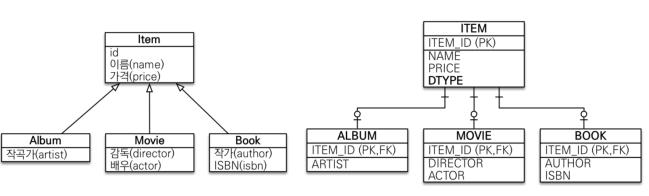
Entity들을 각각 테이블로 변환하는 방법입니다. 테이블이 정규화되고 효율적이지만, 값을 가져오거나 저장시 조금 복잡하고 성능이 저하될 수 있습니다.
-
SINGLE_TABLE전략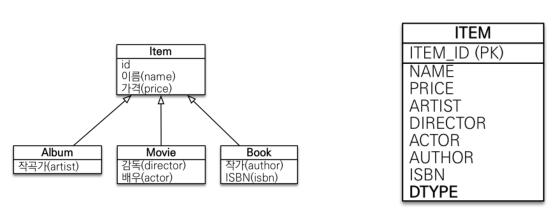
하나의 테이블로 묶어버리는 방법입니다. 단순화된 구조 때문에 조회 성능이 빠르지만, 자식 Entity가 매핑한 Column은 모두 null 허용이고 테이블 크기가 커질 수 있습니다.
-
TABLE_PER_CLASS전략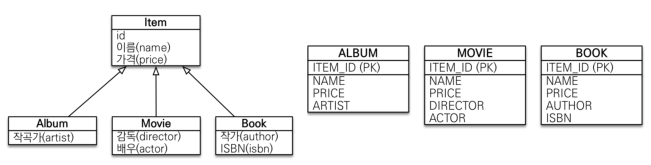
구현 클래스마다 테이블을 만드는 전략입니다. 이런 방법이 있구나 정도로 알고 넘어가고, 직접 사용하는 것은 권장하지 않습니다.
@Entity @Inheritance(strategy = InheritanceType.JOINED) @DiscriminatorColumn public abstract class Item { @Id @GeneratedValue @Column(name = "ITEM_ID") private Long id; private String name; private int price; private int stockQuantity; }@Entity @DiscriminatorValue(value = "Album") public class Album extends Item { private String artist; private String etc; }@Entity @DiscriminatorValue(value = "Book") public class Book extends Item { private String author; private String isbn; }@Entity @DiscriminatorValue(value = "Movie") public class Movie extends Item { private String director; private String actor; }예시 코드처럼
@Inheritanceannotation에 사용할 전략을 속성으로 정하면 됩니다. 그리고@DiscriminatorColumn은 부모 Entity만을 보고서도 어떤 자식 Entity를 가르키는 지 알 수 있도록 구별하는DTYPEColumn을 추가해줍니다. 더불어서@DiscriminatorValue으로DTYPE에 들어갈 값을 지정할 수 있습니다. -
-
@MappedSuperclass여러 Entity에서 반복되는 Field가 있는 경우 이 annotation을 사용해서 공통의 매핑 정보를 모을 수 있습니다. 이는 상속관계의 매핑이 전혀 아니며, 더불어서 Entity 또한 아닙니다. 단지 자식 클래스에 매핑할 정보만을 제공합니다.
@MappedSuperclass public abstract class BaseEntity { private String createdBy; private LocalDateTime createdDate; private String modifiedBy; private LocalDateTime modifiedDate; }@Entity public class Member extends BaseEntity { ... }
프록시와 연관관계 관리
JPA의 즉시 로딩과 지연 로딩을 이해하기 위해서는 먼저 프록시에 대해 이해해야 합니다.
프록시
프록시 클래스는 실제 클래스를 상속 받아서 만들어지며 겉 모양이 같습니다. 다만 실제 값이 필요할 때까지 DB 조회를 미룰 수 있어서, 한 Entity와 연관된 다른 Entity들을 모두 가져올 필요 없을 때 프록시를 사용합니다.

프록시 객체는 실제 객체의 참조를 보관을 해서, 애플리케이션에서 프록시 객체를 호출하면 프록시 객체는 실제 객체의 메소드를 호출하게 됩니다. 아래는 회원과 팀 연관관계 상에서의 프록시 객체를 활용한 예시 코드입니다.
Team team = new Team();
team.setName("teamA");
Member member = new Member();
member.setName("memberA");
member.setTeam(team);
em.persist(team);
em.persist(member);
em.flush(); // SQL 보냄
em.clear(); // 영속성 Context 1차 캐시 초기화
Member referMember = em.getReference(Member.class, member.getId()); // 프록시 객체 가져옴
System.out.println("referMember = " + referMember.getId() + ": " + referMember.getName());
// referMember.getId() 값은 메모리에 있던 값이기 때문에 DB 조회를 하지 않는다.
// referMember.getName() 값을 요청할 때 비로소 DB에 SELECT query를 보내서 값을 가져온다.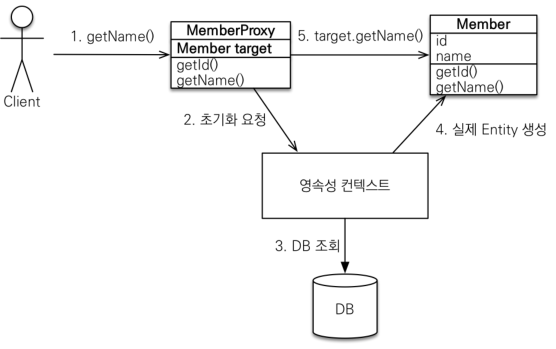
프록시 객체가 메서드를 호출하기 위해 실제 객체의 참조를 갖기 위해서 영속성 Context를 통해 DB에 조회를 합니다. 가져온 정보로 실제 Entity를 생성하고, 프록시 객체가 해당 Entity를 가르키도록 설정합니다. 그리고 프록시 특징은 다음과 같습니다.
-
프록시 객체는 처음 사용할 때 한 번만 초기화됩니다.
-
프록시 객체 초기화시, 프록시 객체가 실제 Entity로 바뀌는 것이 아닌 참조를 통해 동작합니다.
-
프록시 객체는 원본 Entity를 상속받는 상태이므로 타입 체크시
==대신instance of를 사용하는 것이 좋습니다.JPA는 하나의 트랜잭션 내에서는
==이 알맞게 동작하도록 상황에 따라 다르게 작동합니다.-
실제 Entity를 조회 후 프록시 객체를 조회하는 경우
Member findMember = em.find(Member.class, member.getId()); System.out.println("findMember.getClass() = " + findMember.getClass()); // 실제 Entity Member referMember = em.getReference(Member.class, member.getId()); System.out.println("referMember.getClass() = " + referMember.getClass()); // 실제 Entity System.out.println("isEqualClass ? = " + (referMember.getClass() == findMember.getClass())); // print "isEqualClass ? = true"em.find()로 1차 캐시에 실제 Entity가 존재하기 때문에em.getReference()하더라도 실제 Entity가 반환됩니다. 따라서 두 객체의 클래스 타입은 동일합니다. -
프록시 객체를 조회 후 실제 Entity를 조회하는 경우
Member referMember = em.getReference(Member.class, member.getId()); System.out.println("referMember.getClass() = " + referMember.getClass()); // 프록시 객체 Member findMember = em.find(Member.class, member.getId()); System.out.println("findMember.getClass() = " + findMember.getClass()); // 프록시 객체 System.out.println("isEqualClass ? = " + (referMember.getClass() == findMember.getClass())); // print "isEqualClass ? = true"JPA는 한 트랜잭션 내에서 실제 Entity 객체와 프록시 객체의 비교 연산 동작의 완전성을 보장하기 위해, 프록시 객체 조회 후 실제 Entity를 조회하는 경우라도, 두 객체가 모두 프록시 객체를 반환받도록 합니다. 따라서 두 객체의 클래스 타입은 동일합니다.
System.out.println("instanceof = " + (referMember instanceof Member)); // true System.out.println("instanceof = " + (findMember instanceof Member)); // true동일한 트랜잭션이 아닌 경우,
==을 사용한다면 상황에 따라 결과가 달라질 있기 때문에instanceof를 사용하는 것이 좋습니다. -
-
영속성 Context에 찾고자 하는 Entity가 이미 있다면
em.getReference()하더라도 실제 Entity가 반환됩니다. -
영속성 Context의 도움을 받을 수 없는 준영속 상태인 경우, 프록시 객체를 초기화하려하면 Exception이 발생합니다.
Member referMember = em.getReference(Member.class, member.getId()); em.detach(referMember); // 영속성 Context에서 분리 System.out.println("referMember = " + referMember.getId() + ": " + referMember.getName());예시 코드처럼 영속성 Context에서 더이상 관리하지 않는 준영속 상태의 객체의 값을 가져오려 하는 경우,
LazyInitializationException예외가 발생합니다.
프록시 관련 메서드에 관한 예시 코드 입니다.
Member referMember = em.getReference(Member.class, member.getId());
System.out.println("isLoaded ? = " + emf.getPersistenceUnitUtil().isLoaded(referMember));
// print "isLoaded ? = false"
Hibernate.initialize(referMember); // 프록시 객체 강제 초기화
System.out.println("isLoaded ? = " + emf.getPersistenceUnitUtil().isLoaded(referMember));
// print "isLoaded ? = true"
System.out.println("referMember = " + referMember.getId() + ": " + referMember.getName());
// 강제 초기화를 이미 했기 때문에 getName()하더라도 DB에 query가 보내지지 않고 1차 캐시에서 값을 가져옴즉시 로딩과 지연 로딩
회원과 팀 예시로 설명하겠습니다. 비즈니스 로직 상에서 단순히 회원 정보만 필요하고 팀 정보는 필요없는 경우, 회원을 조회할 때 팀을 함께 조회하는 것은 성능 상 손해입니다. 이를 지연 로딩으로 설정하면 연관관계에 관한 값을 요청할 때 DB에 query를 보내는 방식으로 동작합니다.
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEAM_ID")
private Team team;
}Member member = em.find(Member.class, 1L);
// Member의 id, name Field만을 가져옴
System.out.println("member = " + member.getId() + ": " + member.getName());
Team team = member.getTeam();
// 연관관계에 관한 값을 요청할 경우, 그때서야 DB에 query를 보내서 team Field를 가져옴
System.out.println("team = " + team.getId() + ": " + team.getName());만약 회원과 팀이 대부분 함께 사용되는 경우에는 즉시 로딩으로 살정해서 항상 같이 조회되도록 설정하면 됩니다.
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String name;
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "TEAM_ID")
private Team team;
}Member member = em.find(Member.class, 1L);
// Member의 모든 Field를 다 가져옴
System.out.println("member = " + member.getId() + ": " + member.getName());
Team team = member.getTeam();
// 단순히 member 객체의 Field에서 참조
System.out.println("team = " + team.getId() + ": " + team.getName());실무에서는 가급적 지연 로딩만 사용하는 게 권장됩니다. 즉시 로딩을 적용하면 예상치 못한 SQL이 발생하고, 특히 JPQL에서 N+1 문제를 일으킵니다. 따라서 @ManyToOne, @OneToOne의 경우 기본값이 즉시 로딩이므로 지연 로딩으로 설정해서 써야 합니다.
영속성 전이
특정 Entity를 영속 상태로 만들 때, 연관된 Entity도 함께 영속 상태로 만들고 싶을 때 사용하는 방법입니다. 영속성 전이는 연관관계를 매핑하는 것과 아무 관련이 없고, 단지 Entity를 영속화할 때 연관된 Entity도 함께 영속화하는 편리함을 제공할 뿐입니다.
고아 객체
부모 Entity와 연관관계가 끊어진 자식 Entity를 의미합니다. 이 경우 고아 객체를 제거하게끔 설정할 수 있습니다.
아래 코드는 영속성 전이와 고아 객체에 대한 예시입니다.
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEAM_ID")
private Team team;
}@Entity
public class Team {
@Id
@GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
@OneToMany(mappedBy = "team", cascade = CascadeType.ALL, orphanRemoval = true)
List<Member> members = new ArrayList<>();
public void addMember(Member member) {
this.members.add(member);
member.setTeam(this);
}
}Member member1 = new Member();
Member member2 = new Member();
Team team = new Team();
team.setName("teamA");
team.addMember(member1);
team.addMember(member2);
em.persist(team);
// Team의 members Field는 전이 설정이 되어있기 때문에, team을 영속화하면 list에 속한 member도 영속화된다.
team.getMembers().remove(0);
// 부모 Entity에서 첫번째 자식 Entity와의 연관관계를 끊었으므로 member1은 고아 객체가 된다.
// orphanRemval = true 설정이 되어있기 때문에 고아 객체는 자동으로 삭제된다.영속성 전이와 고아 객체의 생명주기
- 두 개념은 특정 Entity(
Team)만이 해당 Entity(Member)를 소유하는 경우에만 사용해야합니다. 그렇지 않은 경우, 다른 Entity에서 예상치 못하게 추가되거나 삭제될 수 있기 떄문입니다. - 두 개념을 모두 사용하면 부모 Entity를 통해서 자식의 생명주기를 관리할 수 있게 되어 도메인 주도 설계의
Aggregate Root개념을 구현할 때 유용합니다.
값 타입
JPA의 데이터 타입은 크게 2가지가 있습니다.
- Entity 타입
@Entity로 정의하는 객체- 데이터가 변해도 식별자를 통해 지속해서 추적 가능
- 값 타입
- 단순히 값으로 사용하는 자바 기본 타입/객체
- 식별자가 없고 값만 있으므로 변경시 추적 불가
- 값 타입을 소유한 Entity에 생명주기를 의존
기본 값 타입,Embedded 타입,Collection 값 타입등으로 분류
기본 값 타입
int age; // 자바 기본 타입(primitive type)
Integer count; // Wrapper 클래스
String name;자바 기본 타입, Wrapper 클래스, String 등이 있고, 기본 값 타입의 생명주기는 Entity에 의존적입니다. 예를 들어 한 회원을 삭제하면 해당 Entity의 기본 값 타입의 Field도 함께 삭제됩니다. 따라서 값 타입은 외부에 공유하면 안됩니다. 기본적으로 자바의 기본 타입은 항상 값을 복사하도록 동작하고, Wrapper 클래스나 String과 같은 특수한 클래스는 공유는 가능하더라도 불변 객체로 동작하여 한 번 만들어진 객체는 데이터 수정이 불가합니다.
Embedded 타입
주로 기본 값 타입을 모아서, 새로운 값 타입을 직접 정의하는 것을 의미합니다. 용도에 맞게 값 타입을 구성할 수 있으므로 재사용이 가능하고 응집도가 높습니다.
@Embeddable
public class Address {
private String city;
private String street;
private String zipcode;
public Address() {
}
}@Entity
public class Member {
...
@Embedded
private Address homeAddress;
}값 타입을 정의하는 곳에 @Embeddable 그리고 값 타입을 사용하는 곳에 @Embedded로 표현할 수 있고 더불어, Embedded 타입으로 사용할 클래스에는 기본 생성자가 필수로 존재해야 합니다. Embedded 타입은 Entity의 값일 뿐이므로, 이 타입을 사용하더라도 매핑하는 테이블은 변함이 없어야 합니다.
불변 객체
값 타입을 여러 Entity에서 공유하면 예상치 못한 부작용(side effect)가 발생할 수 있습니다. 자바 기본 타입에 값을 대입하면 항상 복사하지만, Embedded 타입과 같이 직접 정의한 값 타입은 객체 타입이기 때문에 값을 대입하면 참조 값이 공유됩니다. 이 자체를 막을 수는 없지만, 공유되더라도 값을 바꿀 수 없도록 불변 객체로 설정함으로써 부작용을 막을 수는 있습니다.
@Embeddable
public class Address {
private String city;
private String street;
private String zipcode;
public Address() {
}
public Address(String city, String street, String zipcode) {
this.city = city;
this.street = street;
this.zipcode = zipcode;
}
private void setCity(String city) {
this.city = city;
}
private void setStreet(String street) {
this.street = street;
}
private void setZipcode(String zipcode) {
this.zipcode = zipcode;
}
}불변 객체는 생성 시점 이후 절대 값을 변경할 수 없는 객체라는 의미로, 생성자로만 값을 설정하고 수정자(Setter)를 만들지 않거나 private으로 접 구현 가능합니다.
Collection 값 타입
값 타입을 하나 이상 저장할 때, List나 Set과 같은 Collection을 사용합니다. 하지만 DB에는 Coleecton을 하나의 테이블에 저장할 수 없기 때문에 Collection을 저장하기 위한 별도의 테이블이 필요합니다.
@Entity
public class Member {
...
@Embedded
private Address homeAddress;
@ElementCollection
@CollectionTable(
name = "ADDRESS",
joinColumns = @JoinColumn(name = "MEMBER_ID")
)
private List<Address> addressHistory = new ArrayList<>();
}예시 코드처럼 annotation으로 테이블 설정을 할 수 있습니다. Collection을 위한 테이블은 원래 Entity의 PK를 기준으로 JOIN합니다. 하지만 Collection 값 타입은 다음과 같은 제약 사항 때문에 사용하는 걸 권하지 않습니다.
- 값 타입은 Entity와는 달리 식별자 개념이 없습니다.
- 값은 변경하면 추적이 어렵습니다.
- 값 타입 Collection에 변경 사항이 발생하면, 주인 Entity와 연관된 모든 데이터를 삭제하고, 값 타입 Collection에 있는 현재 값을 모두 다시 저장합니다.
- 값 타입 Collection을 매핑하는 테이블은 null 값을 허용하면 안되고, 중복 저장 방지를 위해 모든 Column을 묶어서 PK를 구성해야 합니다.
따라서 실무에서는 이 대신 1:N 연관관계 설정을 고려하는 게 좋습니다.
@Entity
public class AddressEntity {
@Id
@GeneratedValue
private Long id;
private Address address;
}@Entity
public class Member {
...
@Embedded
private Address homeAddress;
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "MEMBER_ID")
private List<AddressEntity> addressHistory = new ArrayList<>();
}1:N 관계를 위한 Entity를 만들고, 해당 Entity에서 값 타입을 사용하도록 구현하며, 영속성 전이와 고아 객체 제거 옵션을 사용해서 값 타입 Collection처럼 사용합니다.
JPQL (Java Persistence Query Language)
JPA를 사용하면 Entity 객체를 중심으로 개발할 수 있지만, 문제는 DB를 검색할 때의 query입니다. 검색할 때도 테이블이 아닌 Entity 객체를 대상으로 검색하도록 JPQL를 사용합니다. JPA는 SQL을 추상화한 객체 지향 쿼리 언어인 JPQL을 제공합니다. JPQL은 특정 DB SQL에 의존하지 않는다는 점이 특징이며, 추상화되었더라도 결국에는 보내질 때는 SQL로 변환됩니다.
기본 문법
-
Entity와 속성은 대소문자를 구분합니다. (ex.
Member,username) -
JPQL 키워드는 대소문자를 구분하지 않습니다. (ex.
SELECT,From) -
테이블 이름이 아닌 Entity 이름을 사용합니다.
-
별칭은 필수로 사용해야 합니다. (
as는 생략 가능) -
반환 타입이 명확할 때는
TypedQuery를, 그렇지 않을 때는Query를 사용합니다.TypedQuery<Member> query = em.createQuery("select m from Member as m", Member.class); Query query = em.createQuery("select m.name, m.age from Member m"); -
Query 결과가 하나 이상일 때는
getResultList()를, 정확히 하나일 때는getSingleResult()를 사용합니다.TypedQuery<Member> query = em.createQuery("select m from Member as m", Member.class); Member singleResult = query.getSingleResult(); List<Member> resultList = query.getResultList(); -
파라미터는 이름 기준으로
=:를 사용해서 설정할 수 있습니다.TypedQuery<Member> query = em.createQuery("select m from Member as m where m.name=:name", Member.class) .setParameter("name", "memberA");
Projection
SELECT 절에 조회할 대상을 지정하는 것을 의미합니다. 그 대상으로는 Entity, Embedded 타입, 스칼라 타입 등이 있습니다. DISTINCT 로 중복을 제거할 수 있습니다. 더불어, 여러 종류의 대상을 조회할 수도 있습니다.
-
Object[]타입으로 조회List<Object[]> resultList = em.createQuery("select m.name, m.id from Member m") .getResultList(); for (Object[] o: resultList) { System.out.println("o = " + o[0] + ", " + o[1]); } -
DTO로 바로 조회
public class MemberDTO { private String name; private int age; public MemberDTO(String name, int age) { this.name = name; this.age = age; } }String query = "select new hellojpa.MemberDTO(m.name, m.age) from Member m" List<MemberDTO> resultList = em.createQuery(query, MemberDTO.class) .getResultList(); for (MemberDTO m: resultList) { System.out.println("m = " + m.getName() + ", " + m.getAge()); }이 경우에는 패키지 명을 포함한 전체 클래스 명을 입력해야 하고, 순서와 타입이 일치하는 생성자가 존재해야 합니다.
Pasing
List<Member> resultList = em.createQuery("select m from Member m order by m.age desc", Member.class)
.setFirstResult(0)
.setMaxResults(10)
.getResultList();필요한 데이터만 나눠서 가져오는 것을 의미합니다. 조회 시작 위치와 조회할 데이터 수를 지정해주면 간단히 가능합니다.
Join
List<Member> resultList= em.createQuery("select m from Member m inner join m.team t", Member.class)
.getResultList(); // 'inner'는 생략 가능
List<Member> resultList = em.createQuery("select m from Member m left outer join m.team t", Member.class)
.getResultList(); // 'outer'는 생략 가능
List<Member> resultList = em.createQuery("select m from Member m, Team t where m.name = t.name", Member.class)
.getResultList();Inner Join, Outer Joinm Theta Join을 할 수 있고, ON절을 활용한 Join도 가능합니다.
-
Join 대상 필터링
String query = "select m from Member m join m.team t on m.name = t.name"; List<Member> resultList = em.createQuery(query, Member.class) .getResultList(); -
연관관계 없는 Entity Outer Join
String query = "select m from Member m left join Team t on m.name = t.name"; List<Member> resultList = em.createQuery(query, Member.class) .getResultList();
Sub Query
[NOT] EXISTS, ALL, ANY, SOME, [NOT] IN 등의 함수를 이용하여 Sub Query를 작성할 수 있습니다. 표준 JPA에서는 WHERE, HAVING절에서만 사용 가능하지만, 하이버네이트에서는 SELECT절도 가능합니다. FROM절의 Sub Query는 현재 JPQL에서 불가능합니다.
String query = "select m from Member m where m.team = any (select t from Team t)";
List<Member> resultList = em.createQuery(query, Member.class)
.getResultList();조건식
-
CASE식String query = "select " + "case when m.age > 10 then '학생요금'" + " else '일반요금'" + "end " + "from Member m"; -
COALESCEString query = "select coalesce(m.name, '이름 없는 회원') from Member m";하나씩 조회한 후
null이 아니면 반환하고,null이면 두 번째 파라미터를 반환합니다. -
NULLIFString query = "select nullif(m.name, 'memberA') from Member m";파라미터 두 값이 같으면
null을 반환하고, 다르면 첫 번째 파라미터를 반환합니다.
JPQL 함수
-
기본 함수
CONCAT,SUBSTRING,TRIM,LOWER,UPPER,LENGTH,LOCATE,ABS,MOD,SIZE,INDEX등의 함수를 기본으로 제공합니다.String query = "select concat('a', 'b') from Member m"; String query = "select upper(m.name) from Member m"; String query = "select size(t.members) from Team t"; -
사용자 정의 함수
하이버네이트의 경우 사용자 정의 함수를 미리 방언에 추가한 후 사용할 수 있습니다.
public class MyH2Dialect extends H2Dialect { public MyH2Dialect() { registerFunction("group_concat", new StandardSQLFunction("group_concat", StandardBasicTypes.STRING)); } }<properties> <property name="hibernate.dialect" value="hellojpa.MyH2Dialect"/> </properties>String query = "select function('group_concat', m.name) from Member m";
경로 표현식
.을 찍어서 객체 그래프를 탐색하는 것을 의미합니다.
-
상태 Field
String query = "select m.name from Member m"; List<String> resultList = em.createQuery(query, String.class) .getResultList();Entity의 Field 중에서 단순히 값을 저장하기 위한 Field를 의미합니다. (ex.
member.name) 경로 탐색의 끝으로, 추가적인 탐색을 할 수 없습니다. -
단일 값 연관 Field
String query = "select m.team from Member m"; // "select t from Member m join m.team t" 처럼 명시적 Join으로 표현 가능 // "select m.team.name from Member m" 처럼 추가 탐색 가능 List<Team> resultList = em.createQuery(query, Team.class) .getResultList();select m.* from Member m inner join Team t on m.team_id = t.team_id@ManyToOne,@OneToOne연관관계인 경우로 탐색 대상이 Entity인 Field를 의미합니다. (ex.member.team) 묵시적으로 Inner Join이 발생하며, 추가적인 탐색을 할 수 있습니다. -
Collection 값 연관 Field
String query = "select m.orders from Member m"; // "select m.orders.address from Member m" 와 같은 추가 탐색 불가능 // "select o.address" from Member m join m.orders o" 처럼 명시적 Join으로 추가 탐색 가능 List<Order> resultList = em.createQuery(query, Order.class) .getResultList();@OneToMany,@ManyToMany연관관계인 경우로 탐색 대상이 Collection인 Field를 의미합니다. (ex.member.orders) 묵시적으로 Inner Join이 발생하며, 추가적인 탐색을 할 수 없습니다. 다만,FROM절에서 명시적 Join을 통해 별칭을 얻으면 그를 통해 탐색이 가능합니다.
실무에서는 가급적 묵시적 JOIN 대신에 명시적 JOIN을 사용하는 편이 좋습니다. JOIN은 SQL 튜닝에 중요한 표인트인데, 묵시적 JOIN은 한눈에 파악하기 어려운 부분이 있기 때문에 혼란을 낳을 수 있습니다.
Fetch Join
성능 최적화 관점에서, 실무에서 정말 중요한 부분입니다.
연관된 Entity 혹은 Collection을 SQL 한 번으로 함께 조회하는 기능입니다.
String query1 = "select m from Member m join m.team"; // 일반 join문
List<Member> resultList = em.createQuery(query1, Member.class)
.getResultList();
for (Member m: resultList) {
System.out.println("m = " + m.getName());
// FetchType.LAZY이므로, 영속성 Context에는 아직 team을 위한 정보가 없는 상태
System.out.println("t = " + m.getTeam().getName());
// team 관련된 정보 요청이 들어오면 그때서야 SELECT query를 보내 정보를 가져옴
}
String query2 = "select m from Member m join fetch m.team"; // fetch join문
List<Member> resultList = em.createQuery(query2, Member.class)
.getResultList();
for (Member m: resultList) {
System.out.println("m = " + m.getName());
// join fetch했므로, 영속성 Context에는 member 그리고 연관된 team 정보가 모두 있는 상태
System.out.println("t = " + m.getTeam().getName());
// 1차 캐시에서 정보를 가져옴
}만약 꽤 규모가 큰 Application에서 일반 JOIN문으로 한 Entity와 연관된 Entity 정보를 가져온다면, N+1 문제가 발생할 수 있습니다. Fetch Join을 사용하면 연관된 Entity 정보들을 한 번에 가져오므로 N+1 문제를 방지할 수 있습니다. 즉. Fetch Join은 글로벌 로딩 전략보다 우선적으로, 즉시 로딩 속성으로 Entity를 조회하는 것입니다. 따라서 객체 그래프를 SQL 한 번으로 조회할 때 주로 사용합니다.
이번에는 distinct를 사용하는 예시입니다.
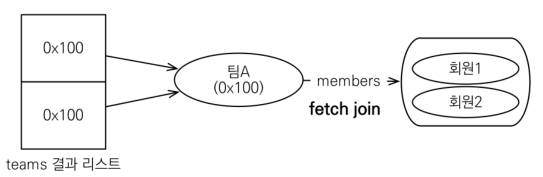
String query1 = "select t from Team t join fetch t.members where t.name='teamA'";
List<Team> resultList = em.createQuery(query1, Team.class)
.getResultList();
for (Team t: resultList) {
System.out.println("t = " + t.getId() + ": " + t.getName());
for (Member m: t.getMembers()) {
System.out.println(" m = " + m.getName());
}
}
// 각 team에 속한 member 수만큼 반복해서 결과 출력
String query2 = "select distinct t from Team t join fetch t.members where t.name='teamA'";
List<Team> resultList = em.createQuery(query2, Team.class)
.getResultList();
for (Team t: resultList) {
System.out.println("t = " + t.getId() + ": " + t.getName());
for (Member m: t.getMembers()) {
System.out.println(" m = " + m.getName());
}
}
// 각 team 한 번씩만 결과 출력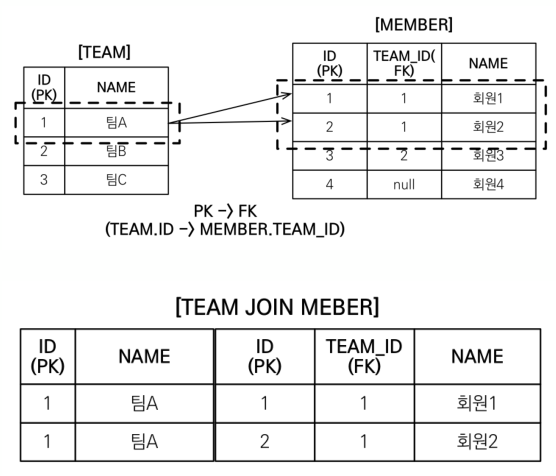
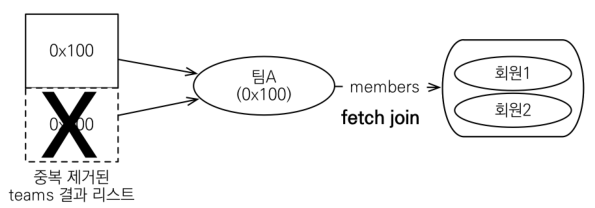
SQL에서 distinct는 중복된 결과를 제거하는 명령이라면, JPA에서는 SQL에 distinct를 추가하고 Application에서 중복 Entity를 제거해줍니다.
다음은 Fetch Join의 한계입니다.
- Fetch Join 대상에 별칭을 줄 수 없습니다. 하이버네이트에서는 가능하지만, 가급적 사용하지 않는 것이 좋습니다.
- 둘 이상의 Collection은 Fetch Join할 수 없습니다.
- Collection을 Fetch Join하면 Pasing API를 사용할 수 없습니다.
만약 여러 테이블을 JOIN해서 Entity가 가진 형태가 아닌 다른 결과가 필요하다면, Fetch Join보다는 일반 Join을 사용하고 그에 맞는 DTO로 반환하는 것이 효과적일 수 있습니다.
다형성 Query
-
Type
조회 대상을 특정 자식으로 한정할 때 사용합니다. 아래는
Item중에Book과Movie를 조회하는 예시 JPQL입니다.String query = "select i from Item i where type(i) IN (Book, Movie)"; -
Treat
자바의 TypeCasting과 유사한 개념으로, 상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용합니다. 아래는 부모인
Item과 자식인Book에 대한 예시 JPQL입니다.String query = "select i from Item i where treat(i as Book).author = 'joon'";
Named Query
미리 정의해서 이름을 부여해두고 사용하는 JPQL로, 정적인 Query입니다. Application 로딩 시점에 초기화 후 캐시해서 재사용되어 성능 상 이점이 있고, 더불어 로딩 시점에 Query를 검증해줍니다.
@Entity
@NamedQuery(
name = "Member.findByName",
query = "select m from Member m where m.name = :name")
public class Member {
...
}List<Member> resultList = em.createNamedQuery("Member.findByName", Member.class)
.setParameter("name", "memberA")
.getResultList();벌크 연산
Query 한 번으로 테이블의 여러 Entity를 변경할 때 사용합니다. 대량의 Field 값 갱신이 필요한 경우에 일반 UPDATE문으로 한다면 엄청 많은 UPDATE SQL이 실행됩니다. 벌크 연산으로는 한 번의 Query로 가능합니다.
String query = "update Member m " +
"set m.age = age * 2 " +
"where m.age > 0";
int resultCount = em.createQuery(query)
.executeUpdate();UPDATE, DELETE를 지원하며, 실행 결과는 영향받은 Entity 수를 반환합니다. 벌크 연산은 영속성 Context를 무시하고 DB에 직접 Query를 보내는 점을 유의해서 사용해야 합니다.

안녕하세요 ~ 현업 에서 주 업무로 안드로이드 하지만 서브 잡으로 스프링을 잡게 되었는데 jpa 공부 도중에 정말 좋은글을 발견해서 모두 완독했습니다 ㅎㅎ 정리 감사합니다.