회사에 있을 때 사내 efk 스택 개발을 맡은 적이 있었다 아래에 해당 업무에 대해 간략하게 정리해보았다
EFK 도입한 이유
- msa 환경에서는 분산된 마이크로서비스 각각에서 로그가 생성된다.
모놀리식 아키텍쳐의 경우 로그 source가 한 곳이라 상관없지만 msa 환경에서는 분산된 로그를 한데 모아서 종합적으로 관리하는 중앙 집중형 스택이 필요하다.
-
분산된 마이크로서비스 간 트랜잭션 추적이나 에러 추적을 위해 필요하다.
특히 msa 환경에서는 마이크로서비스 서버 한 군데에서 에러가 발생할 경우 다른 서버로 전파되기 쉽다. 이렇게 전파된 에러를 추적하기 위해서는 추적용 Id(transaction_id 혹은 trace_id)를 통해 해당 에러가 어디서부터 시작됐는지, 그 원인은 무엇인지 추적해야 한다. 이러한 Id가 붙은 로그를 수집하여 모니터링 할 수 있는 스택이 필요하다. 여러 마이크로서비스 간 발생한 트랜잭션을 추적하기 위해서도 동일한 이유로 필요하다.
- 데이터독과 같은 툴이 시중에 나와있지만 이런 third-party의 툴을 사용하면 유저 개인정보와 같은 데이터가 외부로 나간다. 따라서 사내에 efk를 만드는 걸로 결정했다.
- elasticsearch 및 kibana를 통해 로그 데이터를 시각화할 수 있다. 이를 통해 어플리케이션 모니터링을 할 수 있고 데이터를 분석하여 유의미한 인사이트를 얻을 수 있다.
EFK 아키텍처 1안
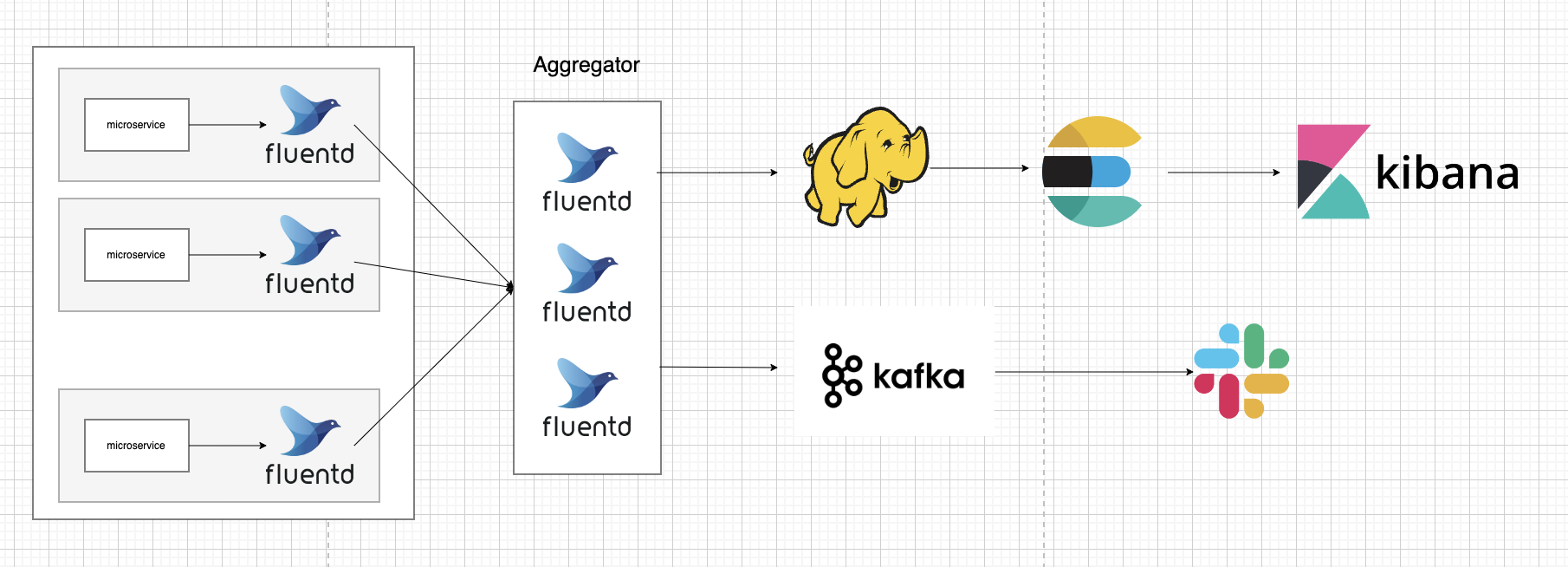
- fluentd가 각 마이크로서비스 서버에서 로그를 수집함
- fluentd로 구성된 aggregator에 수집한 로그가 전달됨 (카프카가 하지 못하는 필터링, 데이터 정제 등에 보다 세밀한 데이터 작업을 위해 필요)
- 3-1) aggregator에서 모아진 데이터가 카프카로 전송되고, 카프카에서 슬랙으로 모니터링 알람이 감
3-2) aggregator에서 모아진 데이터가 하둡으로 이동, 하둡에서 elasticsearch 및 kibana로 다시 전송되어서 kibana 웹브라우저를 통해 시각화
개선할 점
- elasticsearch와 aggragator 간 하둡의 필요성
- kafka에서 slack으로 메시지를 전송하기 위해서는 따로 프로그램을 개발해야함
- 마이크로서비스에서 로그를 collcect하는 fluentd를 fluent bit로 변경 (fluentd보다 더 가볍고 데이터를 단순히 수집하고 전달하는 역할에 적합함)
EFK 아키텍처 2안
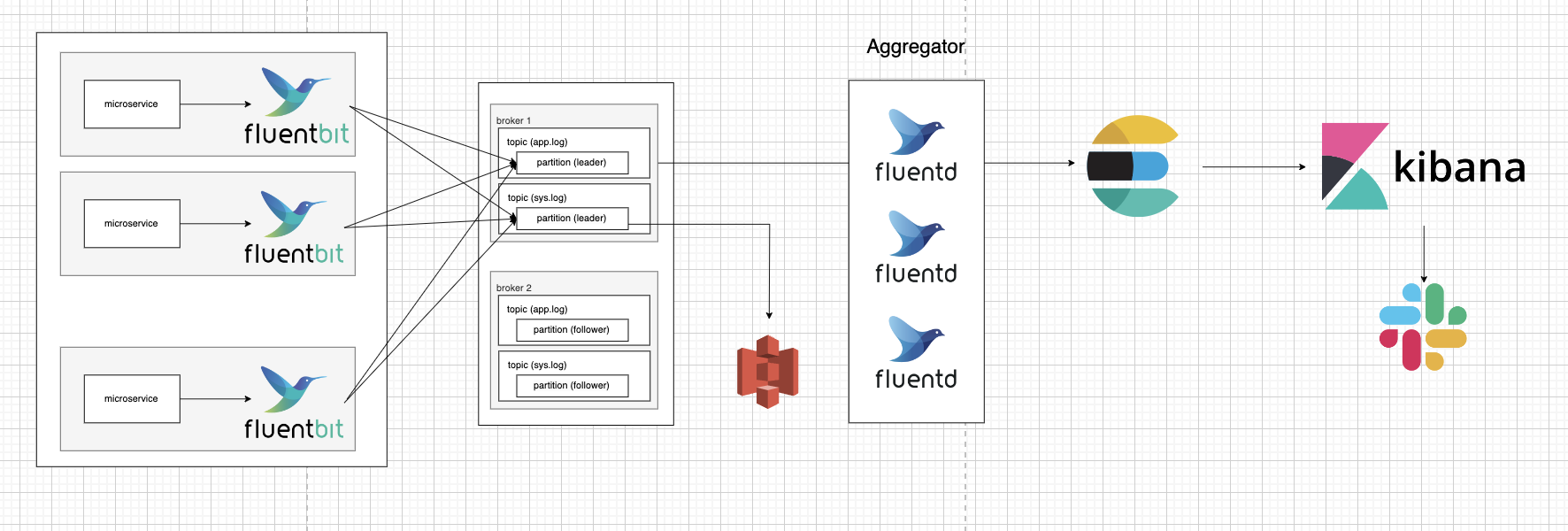
- fluent bit가 각 마이크로서비스 서버에서 로그를 수집함 (어플리케이션 로그, 시스템 로그 둘 다)
- 수집된 로그가 MSK에 전달됨
카프카 토픽은 어플리케이션 로그와 시스템 로그로 따라 구분, 토픽당 leader 파티션 1개에 follower partiton 1개씩 배치 - fluentd로 구성된 aggregator에 수집한 로그가 전달됨
- 4-1) 시스템 로그: aggregator에서 모아진 데이터가 aws s3 스토리지에 전송되어 저장됨 (법적 이유로 일정 기간 이상 저장 필수)
4-2) 어플리케이션 로그: aggregator에서 모아진 데이터가 elasticsearch로 이동, 색인된 데이터가 kibana 웹브라우저를 통해 시각화
개선할 점:
- MSK에서 바로 s3로 전송 시 raw 데이터가 저장되므로 fluentd에서 정제한 데이터를 s3로 전송하는 방향으로 변경해야함
또한 시스템 로그와 어플리케이션 로그 둘 다 s3에 보관
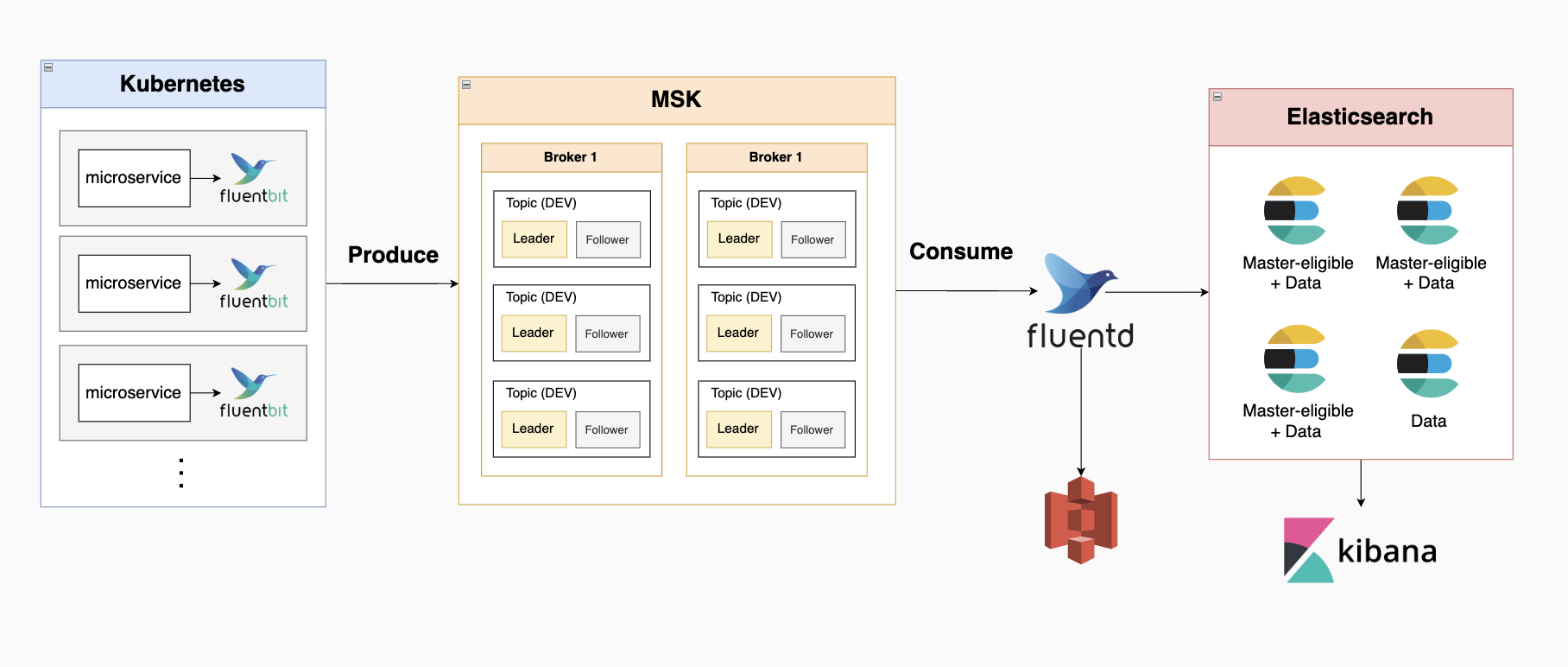
EFK 아키텍처 최종
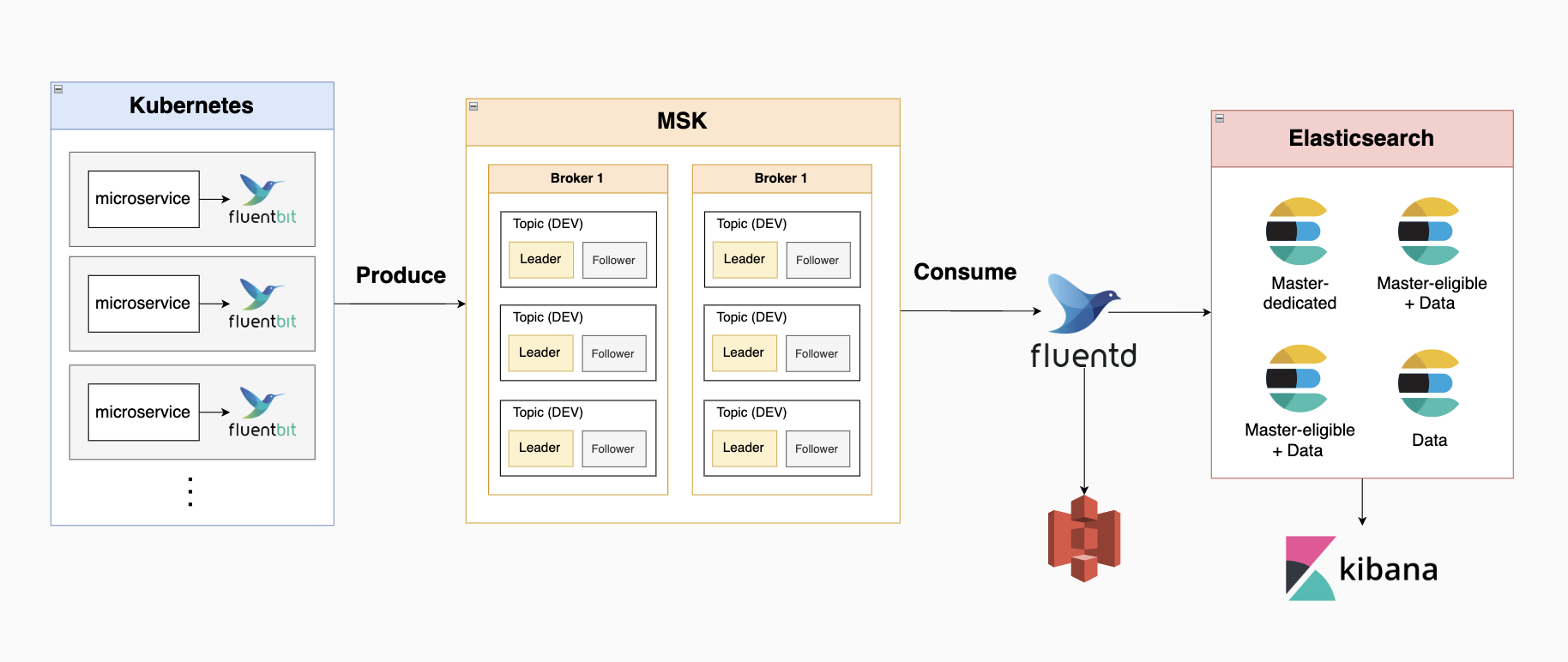
- fluent bit가 각 마이크로서비스 서버에서 로그를 수집함
시스템 로그는 프로메테우스에서 관리되는 걸로 변경됨에 따라 어플리케이션 로그만 수집 - 수집된 로그가 MSK에 전달됨
환경별 2개의 토픽으로 배정, 토픽 하나당 leader, follower partiton 1개씩 배치
총 6개 토픽, 12개 파티션 - fluentd로 구성된 aggregator에 수집한 로그가 전달됨
worker 8개로 구성 - 4-1) aggregator에서 모아진 데이터가 aws s3 스토리지에 전송되어 저장됨
4-2) 어플리케이션 로그: aggregator에서 모아진 데이터가 elasticsearch로 이동, 색인된 데이터가 kibana 웹브라우저를 통해 시각화
elasticsearch 클러스터는 노드 4개로 구성
(node 1 - master dedicated node / node 2 & node 3 - 마스터 후보 노드+데이터 노드 / node 4 - 데이터 노드 1개)
데이터 노드 1개로
키바나->슬랙 메시지 전송은 버전 7 이후로부터 유료 요금제를 구매해야 구현 가능해진 관계로 제외, 각 마이크로서비스의 프로그램상에서 구현하는 방향으로 변경
위 플로우에 따르면 사용된 각각의 툴의 역할은 아래와 같다
- fluent bit - 마이크로서비스 하나에 붙어 로그를 수집하기 위해 필요
- MSK - fluent bit로 분산된 서버 환경에서 수집한 로그를 한 군데로 모으기 위해 필요
- fluentd - MSK에 전달된 raw data를 정제 및 필터링하기 위해 필요 + elasticsearch 노드는 한번에 많은 양의 데이터가 들어올 때 다운되기 쉽기 때문에 앞에 부하를 한번 줄여주는 툴이 필요함 fluentd로 구성된 aggregator가 이 역할을 수행
- s3 - 정책상의 이유로 일정 기간 동안 데이터 저장 필요
- elasticsearch & kibana - 어플리케이션 모니터링 및 데이터 시각화를 위해 필요
개선할 점:
efk를 구축한 이후 사내 인프라 팀이 생기면서 본격적으로 인프라 작업에 들어가던 때였다. 그때 aws에서 컨설팅을 받았었다고 하는데 아래와 같은 피드백이 나왔다고 한다.
-
elasticsearch 클러스터를 유지 및 관리하는게 까다로움. 관리에 투입되는 인적 비용을 생각했을 때 elasticsearch를 직접 관리하지 말고 amazon elasticsearch service를 쓰는게 더 경제적임
사실 이건 aws 직원분이 말한 얘기라는걸 감안해야되지만 다른 인프라 기업에서 오신 직원분도 amazon elasticsearch service를 사용할 걸 추천하셨었다. -
이미 중간에 aggregator로 fluentd가 있어 elasticsearch로 들어오는 부하를 줄여주고 있는데 굳이 msk를 쓸 필요는 없어보임
