인프라
1.EFK? ELK? 각각은 무엇이고 왜 써야할까?
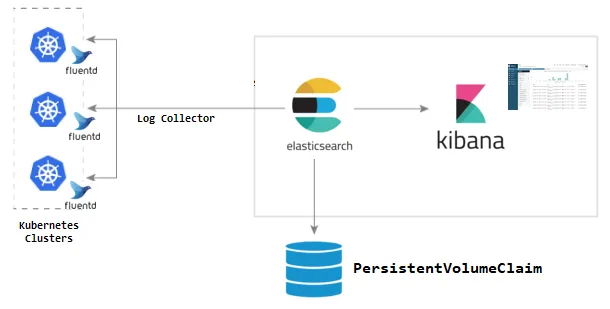
EFK란? Elasticsearch, Fluentd, Kibana 라는 각각의 툴을 사용한 데이터 수집 및 시각화 스택을 말한다. 여기서 말하는 데이터는 어느 종류든 상관없다. 시스템 로그든 비즈니스 매트릭 데이터든 원하는 데이터를 EFK를 통해 수집 및 분석할 수 있
2.[Elasticsearch] es 초기 시스템 세팅

elasticsearch(이하 es)를 처음 설치하고 기동시킬 때 필수적으로 세팅해두어야할 configuration에 관한 포스팅이다 로컬에서만 돌아가는 develop 버전으로 es를 사용하는거라면 굳이 설정해줄 필요는 없다아래 공식 문서를 참고하여 Configurin
3.[Elasticsearch] es 기본 개념 정리 - 클러스터, 노드, 인덱스 등
es를 사용하기 전 반드시 알아야 하는 기본 개념을 정리하는 포스팅이다. 클러스터와 노드 es는 하나 이상의 노드로 이루어진 클러스터로 구성된다. 클러스터에 노드를 하나 이상 둠으로써 노드 하나가 다운되어도 다른 노드들이 계속 es에 들어오는 요청을 처리할 수 있도록
4.[Elasticsearch] Discovery와 Voting Configuration
아래 공식문서에서 discovery 파트와 Quorum-based decision making, Voting configurations 부분을 참고하였다 (버전 7.x)https://www.elastic.co/guide/en/elasticsearch/refer
5.[Elasticsearch] 로그 데이터 수집용 클러스터 및 인덱스 전략
회사에서 일할 당시 로그 데이터 관리 용도로 efk 스택을 만들어야 했었다. 업무 초반 elasticsearch의 클러스터와 인덱스를 어떻게 구성할 것인지 정했어야 했고, elasticsearch 측면에서 아래와 같은 사항을 반영해야 한다고 생각했다. efk를 사용하
6.EFK 도입 이유와 아키텍쳐
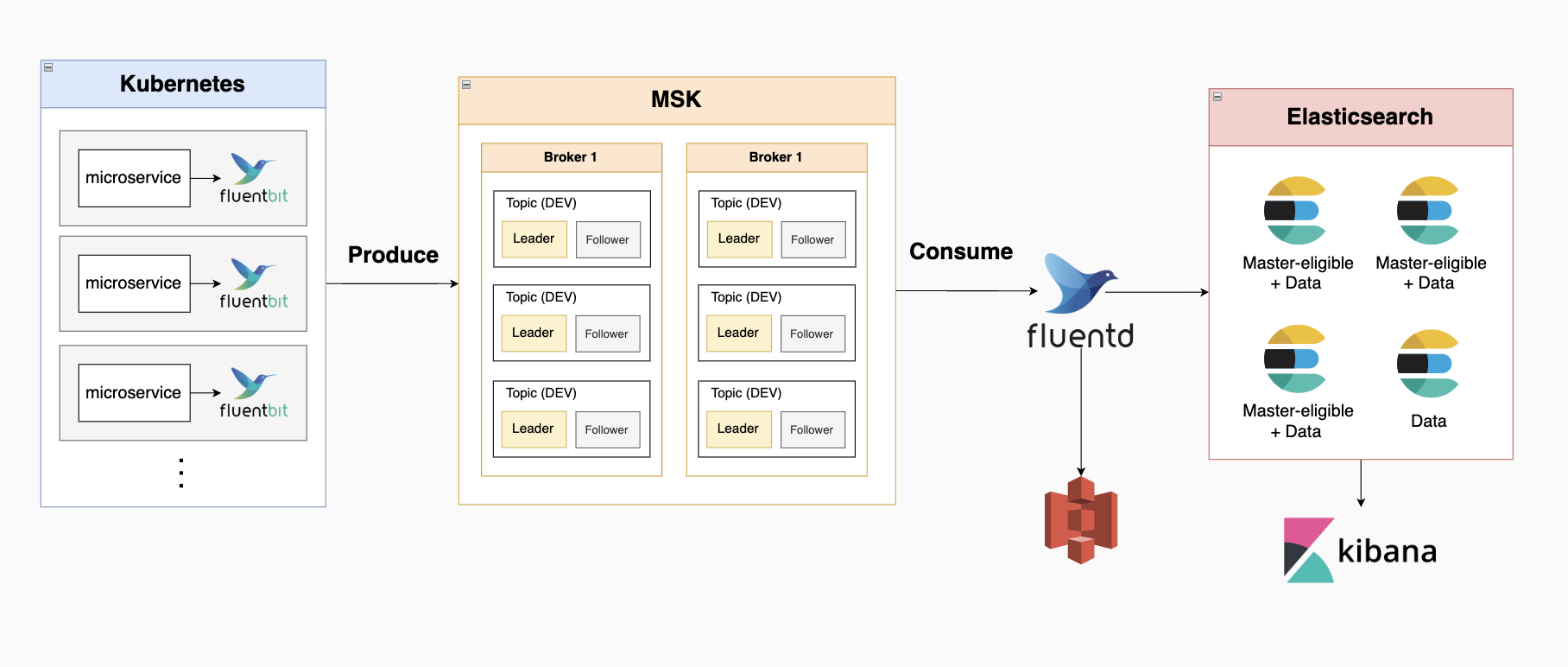
회사에 있을 때 사내 efk 스택 개발을 맡은 적이 있었다 아래에 해당 업무에 대해 간략하게 정리해보았다 EFK 도입한 이유 이거 다시 제대로 정리 msa 환경에서는 분산된 마이크로서비스 각각에서 로그가 생성하는데, 이 로그를 한데 모아서 종합적으로 관리하는 중앙