Spring batch 기본 개념 정리
spring batch에 대해 알아보기 앞서 일단 batch라는 개념 자체를 알고가자.
batch는 쉽게 말해 bulk processing을 말한다. 실시간으로 한건씩 요청말고 한번에 여러개의 요청을 처리해야 하는 벌크 작업에 사용된다.
Spring batch는 spring을 기반으로 한 가벼운 batch framework이다. JSON, XML, SQL database 등과 같은 다양한 Input & Output Option을 제공한다.
아래와 같은 상황에서 주로 사용한다
- 데이터베이스, 파일 또는 큐에서 많은 수의 레코드를 읽을 때
- 수정된 형식으로 데이터를 다시 쓸 때
- 주기적으로 일괄 처리를 커밋할 때
- 동시 일괄 처리: 작업을 병렬로 처리할 때
- 대규모 병렬 배치 처리 시
...
Job과 Step에 대한 기본 개념
job이란 전체 배치 프로세스를 캡슐화한 엔티티이다. 스프링 배치에서 job은 step instance를 위한 컨테이너라고 볼 수 있다. 모든 스탭에 대한 글로벌한 설정을 줄 수 있다.
batch 작업의 대표적인 예시로 은행에서 트래픽이 적은 시간대에 한번에 돈을 송금 처리하는 과정을 예로 들어보자
job이 하나의 transaction이라고 한다면 이 transaction은 아래와 같은 세부적인 step으로 나눌 수 있다.
ㄴstep1 - 다른 은행과 communicate
ㄴstep2 - 돈 송금
ㄴstep3 - 고객에게 email 보내기
Job Instance, Job Parameter
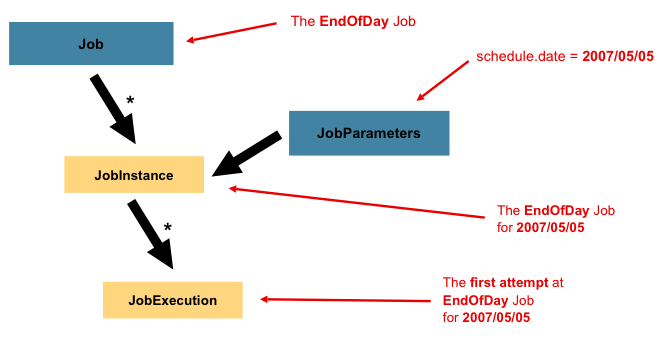
batch 프로세싱에서는 job이 최상위 인스턴스로 있고 그 하위에 JobInstance 있다. 각 인스턴스는 JobParameter로 구분한다. JobParameter로 해당 JobInstance가 언제 시행되었는지에 대한 날짜 및 시간 정보를 받아서 각각의 instance를 구분한다.
ex) 인터넷 뱅킹에서 특정인에게 돈을 송금하는 프로세스를 대규모로 처리하는 batch application이 하나의 job이라면, 9월 1일에 이 app을 돌렸을 때 job instance가 생성되고 9월 2일에 돌렸을 때 1일과는 다른 job instance가 생성됨
만일 9월 1일에 실행한 job이 실패하고 9월 2일에 다시 이 job을 돌리면, 기존에 실패한 9월 1일자 jobInstance로 실행이 됨
JobInstance는 여러번 실행될 수 있으며(실패한 경우) JobParameter로 구분되어 주어진 시간에 하나의 JobInstance만 실행될 수 있다.
참고: 모든 JobParameter가 JobInstance를 구분하는데 사용되는 것은 아니다. (기본 설정만 그럼)
공식문서 참고:
Not all job parameters are required to contribute to the identification of a JobInstance. By default, they do so. However, the framework also allows the submission of a Job with parameters that do not contribute to the identity of a JobInstance.
Job execution
또한 job instance가 수행된 경우 이에 대한 메타 데이터를 담는 job execution이 생성된다.
job이 성공적으로 수행된 경우 - job execution 상태가 successful로 된다.
job이 실패한 경우 - job execution 상태가 failed로 된다.
9월 1일자 job을 돌렸을 때, job이 실패로 끝난다면 job execution failed로 된다. 이 job을 다시 돌렸을 때 9월 1일자 job instance는 1개이지만 이 인스턴스에 대응하는 job execution은 2개가 된다. (기존에 failed한 경우에 대한 Job execution 1개, 새로 돌리는 Job execution 1개)
job execution이 성공 상태로 완료되지 않은 이상 이 execution에 대응하는 job instance는 완료되지 않은 걸로 간주한다.
job execution은 아래와 같은 Property를 갖는다
Status, startTime, endTime, exitStatus, createTime, lastUpdated, executionContext, failureExceptions ...
정리하자면 job , job instance, job execution은 아래와 같은 관계를 갖는다
- job: 처리하려는 job이 무엇인지, 그리고 이것이 어떻게 실행되는지 정의
- job instance: job 실행을 그룹화하는 조직적인 object
- jon execution: 실행 중에 발생한 메타 데이터 저장
Step
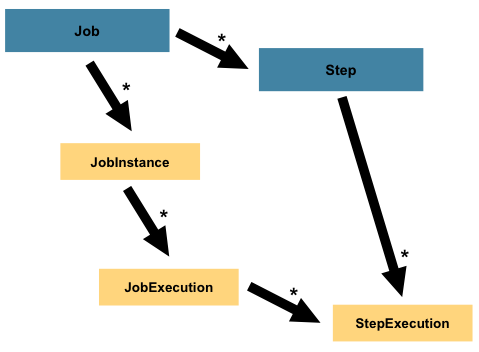
독립적인, 시퀀셜한 batch job의 각 단계를 캡슐화한 도매인 객체이다. step은 단순히 파일을 데이터베이스로 로드하는 것일 수 있고 더 복잡하게는 복잡한 비즈니스 로직이 적용된 단계일 수 있다.
Step execution
하나의 Step 하위에 발생하여 해당 step이 처리된 시간이나 성공 여부 등과 같은 메타 데이터를 담는 객체를 말한다.
jobExecution과 유사하게 step이 실행될 때마다 생성되는데, 이전 step이 실패해서 step이 실행 실패하는 경우 해당 step에 대한 실행이 지속되지 않는다.
step execution은 아래와 같은 Property를 갖는다
Status, startTime, endTime, executionContext, readCount, writeCount, commitCount, rollbackCount, readSkipCount, processSkipCount, filterCount, writeSkipCount ...
Step execution context 역시 해당 step level이기 때문에 그 step에서 접근 가능이 가능하다
ExecutionContext
spring batch 프레임워크에 의해 영속되고 관리되는 key-value fair의 컬렉션이다. StepExecution이나 JobExecution object의 데이터를 저장하여 같은 스코프(job or step) 내에서 공유할 수 있도록 하는 데이터 저장소이다. StepExecutionContext와 JobExecutionContext 두 가지 종류가 있다.
ExecutionContext의 가장 좋은 사용 예제는 재시작을 용이하게 하는데에 있다. 파일 input을 받아서 각각의 line을 처리하면서 line을 읽을 때마다 현재 읽은 line의 숫자를 Execution Context에 저장한다고 하자.
spring batch framework는 주기적으로 ExecutionContext를 커밋 시점에 저장한다. 이렇게 하면 실행 중 에러가 발생해도 ItemReader의 상태를 저장할 수 있도록 한다.
해당 배치 작업이 실행 중에 실패한다면 이후 ExecutionContext를 통해 아래와 같이 몇 번째 line까지 저장이 되었는지 확인할 수 있다.

이렇게하면 후에 실패한 job을 재시작했을 때 마지막으로 읽은 line 이후로부터 다시 작업을 재개하도록 만들 수 있다.
주의:
1. JobExecutionContext은 Step 끼리 공유할 수 있다. 다만 StepExecutionContext은 Step 끼리 공유할 수 없고 Job끼리만 공유가 가능하다.
2.ExecutionContext는 이를 사용하려는 클라이언트(ExecutionContext로 개발하려는 개발자) 간 공유하는 공간를 생성하므로 주의해야한다. 따라서 값을 입력할 때 데이터를 덮어쓰지 않아야 한다.
step들 간 특정 정보를 패스하고 싶으면 job execution context를, 하나의 step 내애서 정보를 패스하고 싶으면 step execution context를 사용하면 된다
tasklet Step & chunk step
tasklet step - step에서 (비교적) 간단한 업무 수행
chunk oriented step - chunk size를 정해서 해당 그 사이즈 만큼 읽어온 다음에 업무 수행
ex) 레코드 100000개인 csv 파일을 spring batch app을 통해 파일을 읽어서 가공한 뒤 mysql에 적재
chunk size를 3으로 지정했다면, 레코드 3개씩 읽어서 mysql에 적재함
ItemReader, ItemProcessor, ItemWriter
ItemReader: 여러 다른 타입의 input source로부터 데이터를 읽어온다. (input 예시: Flat File, XML, Database... )
ItemProcessor: ItemReader에서 받아온 값을 특정 비즈니스 로직에 맞춰 가공하거나 처리한다. 해당 job이 데이터 가공 없이 단순히 source에서 destination으로 옮기는 작업만 수행한다면 생략 가능하다.
ItemWriter: ItemReader와는 반대로 data를 쓰는 연산을 진행한다. 데이터베이스나 파일 등 다른 destination source에 ItemReader 혹은 ItemProcessor에서 받은 값을 쓰는 연산을 진행한다.
위 chunk step 예제를 다시 보자면
ex) 레코드 100000개인 csv 파일을 spring batch app을 통해 파일을 읽어서 가공한 뒤 mysql에 적재
chunk size를 3으로 지정했다면, 레코드 3개씩 읽어서 mysql에 적재함
여기서 ItemReader - csv, ItemProcessor - spring batch app, ItemWriter - MySQL이 됨
- ItemReader가 정해진 chunk size대로 읽어옴
- ItemReader의 아웃풋을 ItemProcessor가 받아서 처리
- ItemProcessor의 아웃풋을 ItemWriter가 받아서 작성
chunk oriented step에서 ItemReader랑 ItemWriter만 있어도 됨
예시)
chunk size가 3인 경우
Inside Item Reader // 1번째 레코드 읽음
Inside Item Reader // 2번째 레코드 읽음
Inside Item Reader // 3번째 레코드 읽음
Inside Item Processor // 1번째 레코드 처리
Inside Item Processor // 2번째 레코드 처리
Inside Item Processor // 3번째 레코드 처리
Inside Item Writer // 1번째, 2번째, 3번째 모두 write
...
각 스텝마다 하는 일이 간단하고 작은 볼륨일 때 - tasklet 방식 사용
큰 볼륨의 업무를 수행할 때 - chunk 방식 사용
JobRepository
metadata 정보를 저장하는 역할 (어떤 job이 언제 시작하고 언제 끝났고 어디서 에러가 왜 발생했는지 등등,,)
Job execution context에 step 전반에 걸쳐 필요한 정보를 저장할 수 있음(map 형태로 저장). Job execution context는 job level이기 때문에 step들 중 어디에서든 Job execution context에 접근 가능하기 때문
이러한 Job의 step들이 끝나고 spring batch는 Job execution context를 메타 데이터로서 db에 저장함
ex)
9월 1일에 job 수행, job instance 생성
-> job execution 생성
성공하는 경우 - 해당 9월 1일자의 job instance 하위의 또 다른 job execution은 실행되지 않음
중복된 작업으로 인지하고 실행이 안됨. DB에 보면 id값이 다른 execution값이 들어가긴 하지만 실행되지는 않음 step execution 테이블에 가보면 처음 job execution의 id만 갖는 걸 확인할 수 있음
정리하자면 다음과 같음
9월 1일자 job instance 데이터가 db에 들어감
-> job execution 실행 시 db에 들어감. 상태는 completed
-> 해당 job execution에 대한 step execution 데이터 들어감
-> job execution 또 실행 시 db에 들어가지만 실행은 안됨. EXID_MESSAGE로 All steps already completed or no steps configured for this job.가 뜸
-> 해당 job execution에 대한 step execution 데이터는 db에 없음(job 자체가 실행 안되었으므로 step이 실행되지 않으므로)
실패하는 경우 - 이후에 해당 job instance 하위의 또 다른 job execution 실행 가능. (저번 execution은 실패했었으므로)
실습 예제: Spring batch-mysql 연결
application.properties에 spring.batch.jdbc.initialize-schema=always 설정해주고 db랑 연결하면 mysql에 다음과 같은 테이블이 생성된다

application을 실행하면 각 테이블에 해당하는 데이터가 저장된다
Job listener & Step listener
각각 job이나 step이 수행되기 전과 후에 해야될 작업을 수행하게 해줌
StepExecutionListener나 JobExecutionListener를 상속받아서 구현
Job 실행을 제어하는 방법
springboot batch application을 실행하면 해당 어플리케이션에 있는 모든 job이 수행됨
실제 프로덕션 레벨에서는 3시간마다 or 특정 api가 호출할 때마다 job이 구동되기를 원함
job 실행을 제어하는 방법
- Rest API가 호출될 때마다 실행 - JobExecution의 run 메소드로 실행
- Spring Scheduler 사용 - @Scheduled 사용해서 1시간마다, 하루마다 등 특정 기간마다 실행되도록 지정
Item Reader 종류
flat file Item Reader
두 가지를 설정해주어야 함
- source location 설정. 읽어올 데이터의 위치를 설정해줌
- Line mapper를 설정해서 한 줄씩 읽어오도록 함. Line mapper은 Line tokenizer와 Bean mapper를 설정해주어야 함
public FlatFileItemReader<StudentCSV> flatFileItemReader() {
FlatFileItemReader<StudentCSV> flatFileItemReader = new FlatFileItemReader<StudentCSV>();
flatFileItemReader.setResource(new FileSystemResource(
new File("파일 위치")
));// csv 파일 위치 설정
flatFileItemReader.setLineMapper(new DefaultLineMapper<>(){
{
setLineTokenizer(new DelimitedLineTokenizer() {
{
// 라인 별로 구분하는 구분자 설정은 콤마가 기본값이라 생략
setNames("ID", "First Name", "Last Name", "Email");
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<>(){
{
setTargetType(StudentCSV.class);
}
});
}
});
flatFileItemReader.setLinesToSkip(1); // 첫번째 줄은 skip하고 읽지 않음
return flatFileItemReader;JpaPagingItemReader
Cursor 기반의 ItemReader의 경우, 데이터베이스 커넥션을 지속적으로 독점으로 사용하여 처리가 완료되는 시점까지 커넥션을 놓아주지 않기 때문에, 경우에 따라 성능상에 영향을 줄 수 있다. 처리 해야 할 데이터가 크다면 Cursor 기반이 아닌 Pagination 기반의 구현을 사용하는 것이 유리하다.
Pagination 기반의 ItemReader의 구현체는 JdbcPagingItemReader, JpaPagingItemReader이 있다.
JpaPagingItemReader를 통하여 지정한 페이지 사이즈만큼 데이터를 가져와서 처리 가능하다.
조회한 데이터는 JPA 영속성 컨텍스트상에서 DETACH상태이기 때문에, 영속성 컨텍스트의 관리 대상에서 벗어나게 된다.
JpaPagingItemReaderBuilder를 통하여 생성 가능하며, JpaPagingItemReader를 직접 생성하는 것도 가능하다.
출처:
https://stylishc.tistory.com/125 [Choi's Blog:티스토리]
https://docs.spring.io/spring-batch/reference/domain.html
https://www.udemy.com/course/data-batch-processing-with-spring-batch-spring-boot-spring-framework/ (강의 내용 정리)
피드백은 언제나 환영입니다!
