Debug 를 통한 코드 분석
- 최근 백기선님 강좌를 보다가 Debug 를 어떻게 사용하는지를 가볍게 알게되어서 요즘 계속해서 사용하려고 노력중이다. Effective Java Study 중에
volatile과synchronized내용이 나와서 사용하게 되었는데 아래 그림과 같이 디버깅을 사용했다.
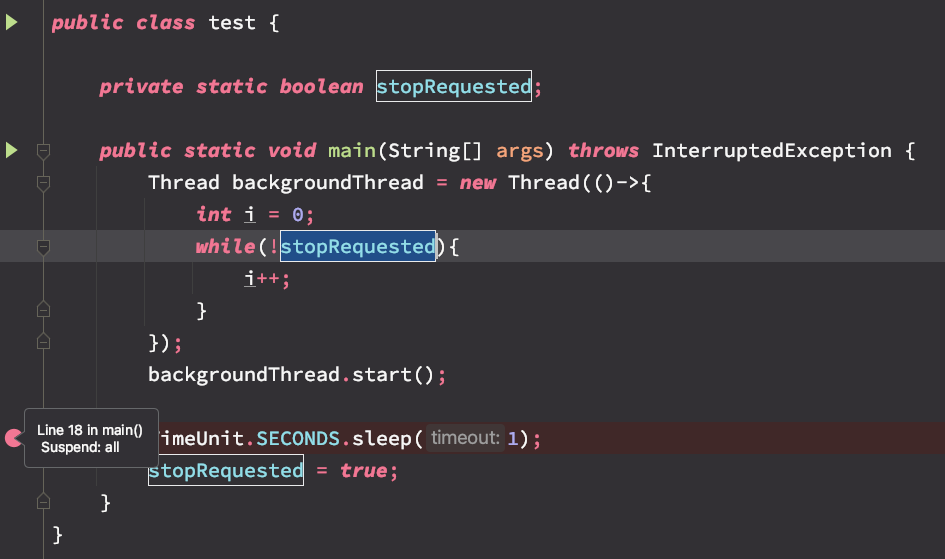
아래와 같이 TimeUnit 에서 1초 걸릴때를 breakTime 으로 잡고 코드의 절차과정을 보고 싶었다.
volatile
아직 1초가 지나기전 각 스레드의 stopRequested 상태값이다.
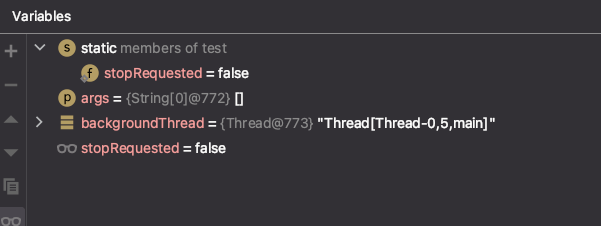
현재 stopRequsted 는 false 이다 근데 stepOver 를 하게되면
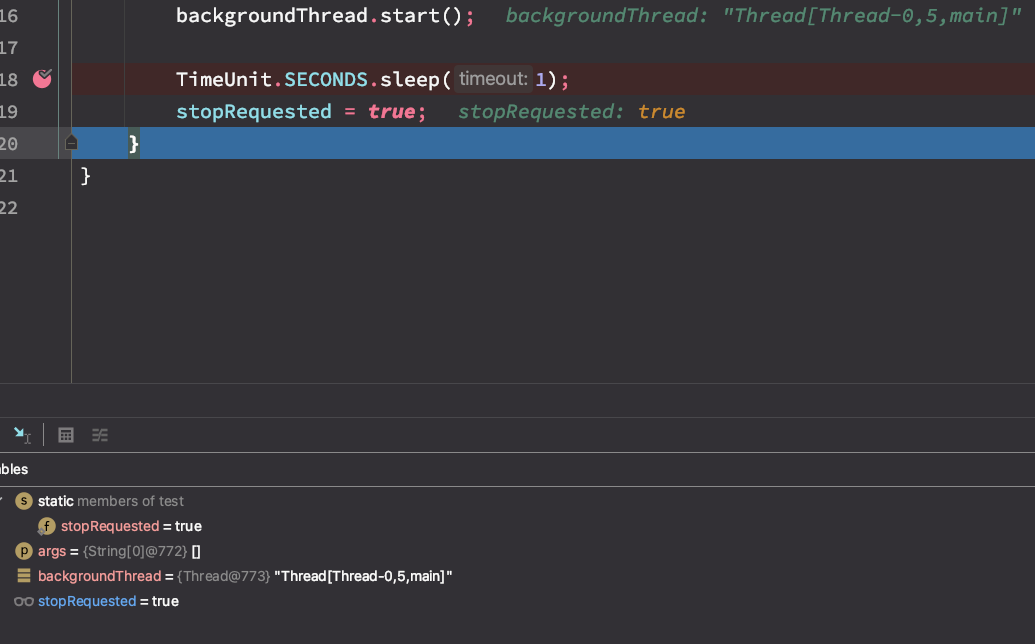
다음 단계인 stopRequested = true; 로 stepinto 로 가게되면 stopRequested 가 true 로 바뀐것을 알 수 있다. 하지만 해당 코드는 끝나지 않는다. 왜일까?
오늘 스터디하고, 따로 찾아보다가 조금 알게 된 사실인데 (틀린 내용이 있을 수도 있어요~~! 있다면 댓글로 부탁드립니다!)
음 간단히 내가 이해한 바로는 메모리에 값을 쓰고 다음 명령어를 실행해야 하는데 이 과정에서 드는 비용이 생각보다 길다. 그래서 Cache 라는 걸 만들어서 거기에 땡하고 넣고 다음으로 넘어갈 수 있게 만드는데 이게 내 코드에서는 백그라운드 스레드와 메인 스레드가 하나의 stopRequested 를 자신의 Cache에 가지고 있는 것이다. 그래서 만약에 main 에서 stopRequested 를 바꿨다고 해도 지금 backGroundThread 는 자신의 Cache에 있는 stopRequested 로만 판단하기에 현재 반복문이 끝나지 않는다고 판단을 했다.
사실 primitive 타입 중 long, double 을 제외하고는 원자적 수행을 보장하는 것으로 알고 있는데, 이 원자적 수행이란것도 어떻게 보면 바이트 코드상에서 하나의 연산만 수행되기에 다른 스레드가 끼어들 수 없고, 그렇기에 원자적 수행을 보장한다는 생각이 든다. 간단한 예시로는 (i++) 의 경우에는 i 를 Load 하고 해당 값에 +1 을 하고 적재하는 과정이 바이트 코드상으로도 여러코드가 나올것이고, 해당 과정에서 다른 스레드가 끼어들 수 있을 것이라는 생각이 든다고 생각한다. 그래서 해당 연산은 원자적 수행을 보장하지 못하는 것일테니까.
그래서 volatile 은 이제 내가 이해한 내용으로는 스레드 간의 상태를 공유할때 그 상태가 일단 원자적 수행을 보장하는 필드고(위의 stopRequested 처럼), 그 해당 함수를 Thread 간의 통신을 보장해주기 위해서 사용하는데 오늘 스터디 간 나온 내용들로 이해하자면, 아까 위에서 말하는 Cache 에 넣는 과정을 하지않고, 메모리에 write 해서 성능은 저하될 수 있지만, 읽어 왔을때 최근값을 읽지 않을까란 생각을 했다.
그래서 아래와 같이 코드에 volatile 을 넣으면 정상적으로 1초가 지나면 종료된다.
public class test2 {
private static volatile boolean stopRequested;
public static void main(String[] args) throws InterruptedException {
Thread backgroundThread = new Thread(()->{
int i = 0;
while(!stopRequested){
i++;
}
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
stopRequested = true;
}
}synchronized
이건 volatile 이랑 다른데 mutax 로 이해하면 된다고 생각한다.
뭐 간단히 적자면 우리가 Position 에 x, y 값을 찍는게 있다면 A Thread 가 값을 찍는 동안에는 해당
Position 에 lock 을 걸어두고 어떠한 Thread 도 접근할 수 없으며, A 의 작업이 끝나면 locK 이 풀리고 B 가 작업을 시작한다.
DB
좀 다른 책들을 못읽다가 학부생 과정에서 할법한 책들을 읽으니까 괜찮게 DB 를 점점 배우고 있다는 생각이 드는데, 며칠 간 정리를 못해서 오늘 부터는 TIL 을 조금 씩이나마 쓰면서 공부 내용을 좀 정리하고 나중에 찾기 쉽게하려고 한다.
가장 중요하게 생각하는 키워드는 개체 무결성 제약조건 과 참조 무결성 제약조건 이라고 생각한다.
이 두개를 잘 모르고 있었는데 이전까지는 이 두개가 사실 DB 의 모든 규약을 정해주는 것 같다는 생각이 요즘 들어 강하게 든다. 이러한 개념들이 확장되서 CASCADE 나 이런게 등장한것이 아닐까? 라는 생각이 든다. 그리고 DB 연산 SELECT 나 Project 등등을 여태까지는 조금 등한시 했는데 이런걸 공부하니까 더 잘들어오는것 같다. 오늘 스터디에서 David 가 B+Tree 를 구현해봤다고 했는데, 나도 나중에 해보고 싶다는 생각이 들었다.
간략 느낀점
- Debug 는 공부해두는게 좋다. 라이브러리 하나하나씩 파보면 재미있다. 사실 오늘 배운 주제 중에 추상화에 맞는 예외를 던지는 내용이 있었는데, 그 내용은 진행자여서 정리하다보니, 여기엔 적지 않았다. 관심있다면 이펙티브 자바스터디 여기 눌러서 한번 보길 바란다~ Item75인가? 여튼 그 언저리 이다. 백엔드는 DB를 잘해야 한다는데.. DB도 코드스쿼드 스프링 과정 들어가기전에 개론책은 끝내고 싶다.
