안녕하세요! 오늘은 2017년 Facebook AI Research에서 발표한 Feature Pyramid Network에 대해서 알아보고 Pytorch로 구현까지 해보겠습니다. 이 Network는 Feature pyramid를 활용하여 적은 비용으로도 다양한 scale에서의 Object Detection을 가능하게 하였습니다.
Paper Review
본 논문의 저자는 Objection Detection 모델의 고질적인 문제를 해결하고자 pyramid 구조의 model architecture를 활용하고자 하였습니다. 지금까지 Feature Pyramid를 활용한 모델이 없었던 것은 아닙니다.
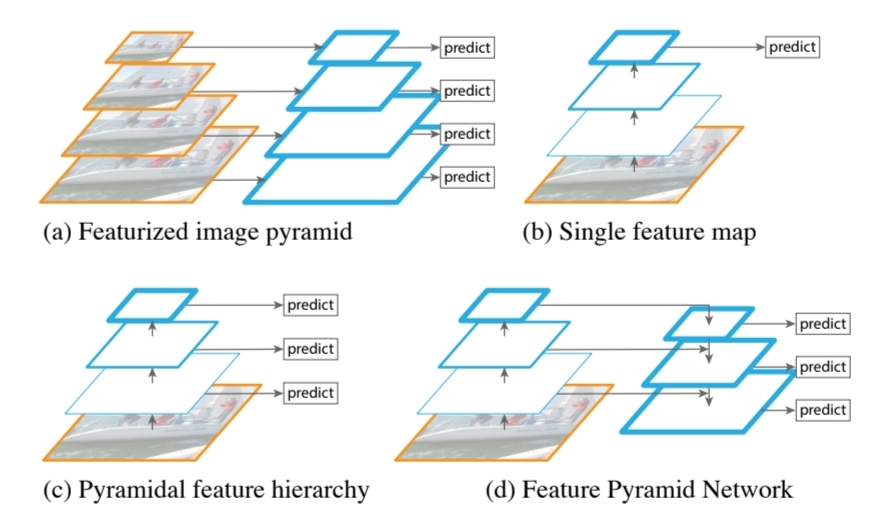
논문에서는 위와 같은 그림을 통해 지금까지 제안되어 왔던 Feature Pyramid를 활용한 모델들을 소개합니다. 그러나 이 모델들은 속도가 느리거나 다양한 scale의 object detection에는 불리한 점들이 있었습니다. 따라서 본 논문에서는 다양한 scale의 object에 대해서 정확히 식별하는 것을 목표로 하는 Pyramid Network를 제안하고자 합니다.
Method
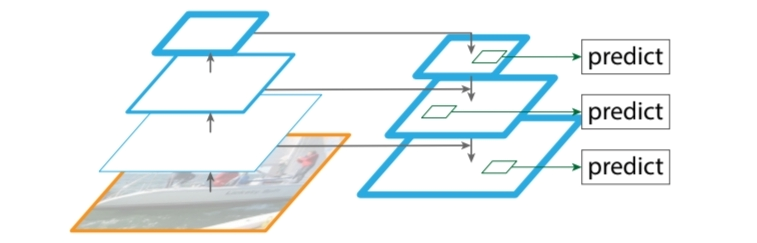
FPN은 위와 같이 Top-down 방식과 Bottom up 방식의 Feature Pyramid를 활용하고 이 두 Pyramid를 적절하게 연결하면서 resolution과 설명력 간의 trade-off를 해소하여 feature pyramid의 단점을 극복하였습니다. 이제 좀 더 자세히 알아보며 단점들을 어떻게 해결하였는지 알아보겠습니다.
Bottom-up pathway
bottom-up pathway는 Convnet의 backbone과 같이 다양한 scale에서의 feed-forward 연산들 이뤄집니다. 이 과정에서 feature map의 scale이 2배씩 줄어드는 feature hierarchy architecture를 갖게 됩니다.
Buttom-up Feature Pyramid에서 다양한 output feature map이 있겠지만 논문에서는 같은 scale로 이뤄진 연산은 하나의 stage로 보고 각 stage의 마지막 layer의 output만을 reference로 활용하여 다음 stage 혹은 residual block으로 활용하였습니다.
Top-down pathway and lateral connection
Top-down pathway는 이전 stage의 feature map을 upsampling하고 이전 Bottom-up pyramid에서 같은 scale의 feature map과 연결하여 점점 큰 크기의 feature map을 만들어내는 과정입니다.
이전 stage의 Feature map을 2배씩 upsampling 하여 Feature map들의 크기를 맞춰주는데 이때 Nearest Neighbor Upsampling 방식을 이용합니다.
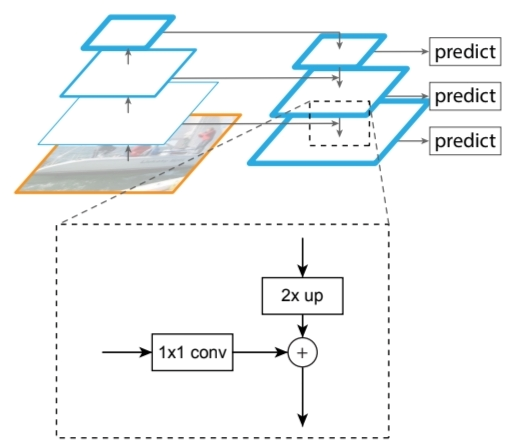
위 그림의 점선으로 된 박스를 통해 Buttom up pathway 의 feature map이 Top-down pathway의 feature map와 lateral connection을 통해 합쳐짐을 알 수 있습니다. Buttom up은 input image를 2배씩 down scale하면서 feature map을 생성했고, Top-down은 Buttom up 과정에서 생성된 feature map 중 가장 작은 feature map(논문에선 coarsest resolution map으로 지칭) 부터 2배씩 upscaling하는 과정을 통해 feature map을 생성했기 때문에 동일한 scale의 feature map 끼리는 merge가 가능했습니다. 이 과정을 통해 semantic함과 다양한 resolution의 local한 정보를 잘 학습할 수 있다고 합니다.
Robust model
논문에서는 모든 feature들의 dimenstion을 256으로 고정하였으며, 위에서 쓰인 convolution layer을 제외하고는 다른 lineary layer는 전혀 없이 simplicity한 모델이라고 설명합니다. 이를 통해 FPN은 다방면에서 Robust함을 확보함과 동시에 다양한 과제에 이용 가능한 Base line으로 활용되고 있습니다.
Code Review
FPN은 앞서 설명했다시피 Object Detection의 Backbone으로 개발된 Network입니다. 논문에서도 FPN을 독자적으로 Detection에 활용하지 않고 RPN이나 Fast-RCNN에서 Backbone으로 적용하는 과정을 설명해놓았습니다. 본 리뷰에서는 Detection이 아닌 Segmentation 과제를 수행해보며 FPN을 Backbone으로 활용해보겠습니다. 전체적인 Code는 Github 에 올려놓겠습니다. 그 동안 Review는 Jupyter notebook을 이용한 .jpynb파일로 구현했었는데, 앞으로는 VS code를 익숙하게 하기 위해서 python 파일로 Github를 채워보도록 하겠습니다.
FPN을 구현하는 과정은 다음과 같습니다.
- Buttom-up pathway
- Top-down pathway
- segmentation
- Dataset
- Training
FPN Architecture
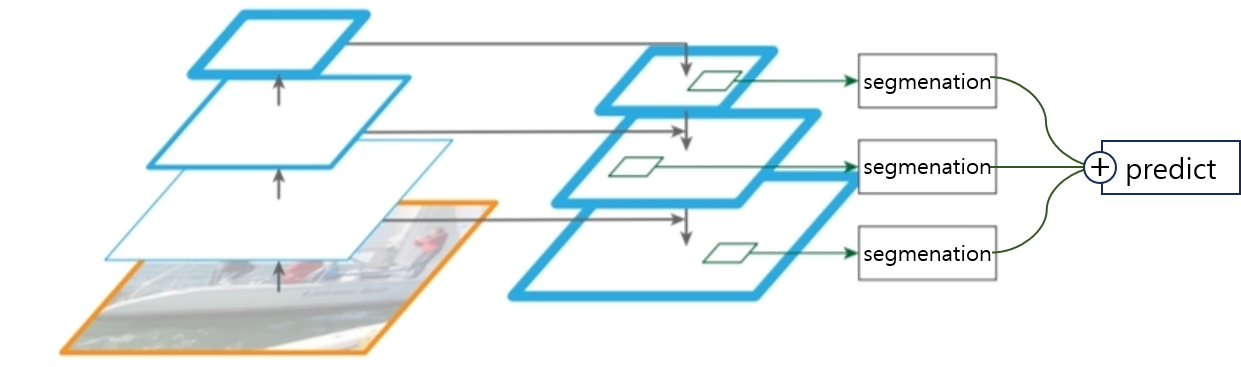 본 리뷰에서 활용한 FPN의 Architecture는 위의 그림과 같이 Buttom-up pathway와 Top-down pathway를 거친 후 각 scale별 feature map에 segmentation block을 추가한 뒤 이를 다 더하여 최종 segmentation predict 하는 과정입니다.
본 리뷰에서 활용한 FPN의 Architecture는 위의 그림과 같이 Buttom-up pathway와 Top-down pathway를 거친 후 각 scale별 feature map에 segmentation block을 추가한 뒤 이를 다 더하여 최종 segmentation predict 하는 과정입니다.
Bottom-up pathway
Bottom-up pathway는 RetinaNet(2017)을 참고하여 Pre-trained 된 Resnet을 활용하였습니다. ResNet의 각 stage별 마지막 layer의 output을 Top-down에 input으로 하기 위해 5개의 output이 있습니다.
class FPNEncoder(nn.Module):
def __init__(self, encoder):
super().__init__()
self.encoder = encoder
def forward(self,x):
x0 = self.encoder.conv1(x)
x0 = self.encoder.bn1(x0)
x0 = self.encoder.relu(x0)
x1 = self.encoder.maxpool(x0)
x1 = self.encoder.layer1(x1)
x2 = self.encoder.layer2(x1)
x3 = self.encoder.layer3(x2)
x4 = self.encoder.layer4(x3)
x = x4,x3,x2,x1,x0
return xTop-down pathway
Buttom-up pathway를 통해 생성된 가장 함축된 feature map(coarsest feature map) 에서 시작하여 점점 upscaling하고, lateral connection 하는 과정입니다. 논문에서 설명한대로 buttom-up pathway의 feature map은 lateral connection 전 1*1 convlayer를 거치고, connection 이후에는 3*3 conv layer를 통해 final feature map을 생성합니다.
class FPNBlock(nn.Module):
def __init__(self,pyramid_channels,skip_channels):
super().__init__()
#encoding output feature connection with conv1*1
self.skip_conv = nn.Conv2d(skip_channels,pyramid_channels,kernel_size=1)
self.afterup_conv = nn.Conv2d(pyramid_channels,pyramid_channels,kernel_size=(3,3),stride=1,padding=1,bias=False)
def forward(self,x):
x, skip = x #pyramid output과 encoding output으로 나눔
x = F.interpolate(x,scale_factor=2,mode="nearest")
skip = self.skip_conv(skip)
x=x+skip
x = self.afterup_conv(x)
return xSegmentation block
segmentation block은 각기 다른 scale의 feature map의 size를 다시 동일하게 upscaling 해주고, 3*3 Convolution 연산을 통해 각각 본래 image의 scale과 동일한 최종 feature map을 생성합니다. 그리고 이 final feature map에 pixel-wise summation을 통해 각 pixel별 segmentation이 이뤄지게 됩니다.
class SegmentationBlock(nn.Module):
def __init__(self, in_channels,out_channels,n_upsamples=0):
super().__init__()
blocks = [
Conv3x3block(in_channels,out_channels,upsample=bool(n_upsamples))
]
if n_upsamples >1:
for _ in range (1,n_upsamples):
blocks.append(Conv3x3block(out_channels,out_channels,upsample=True))
self.block = nn.Sequential(*blocks)
def forward(self,x):
return self.block(x)Top-down pathway와 Segmentation Block은 FPN Decoder라는 이름으로 Block들을 모아 Moduel화 하였습니다.
class FPNDecoder(Model):
def __init__(self,
encoder_channels,
pyramid_channels=64,
segmentation_channels=32,
final_upsampling=4,
final_channels=1,
dropout=0.2,
merge_policy ='add'
):
super().__init__()
if merge_policy not in ['add','cat']:
raise ValueError("merge_policy must be one of: ['add','cat']")
self.merge_policy = merge_policy
self.final_upsampling = final_upsampling
self.conv1 = nn.Conv2d(encoder_channels[1],pyramid_channels,kernel_size=(1,1))
self.p4 = FPNBlock(pyramid_channels,encoder_channels[2])
self.p3 = FPNBlock(pyramid_channels,encoder_channels[3])
self.p2 = FPNBlock(pyramid_channels,encoder_channels[4])
self.s5 = SegmentationBlock(pyramid_channels,segmentation_channels,n_upsamples=3)
self.s4 = SegmentationBlock(pyramid_channels,segmentation_channels,n_upsamples=2)
self.s3 = SegmentationBlock(pyramid_channels,segmentation_channels,n_upsamples=1)
self.s2 = SegmentationBlock(pyramid_channels,segmentation_channels,n_upsamples=0)
self.dropout = nn.Dropout2d(p=dropout,inplace=True)
if self.merge_policy == "cat":
segmentation_channels *= 4
self.final_conv = nn.Conv2d(segmentation_channels,final_channels,kernel_size=1,padding=0)
self.initialize()
def forward(self, x):
c5,c4,c3,c2,_ = x
p5 = self.conv1(c5)
p4 = self.p4([p5,c4])
p3 = self.p3([p4,c3])
p2 = self.p2([p3,c2])
s5 = self.s5(p5)
s4 = self.s4(p4)
s3 = self.s3(p3)
s2 = self.s2(p2)
if self.merge_policy == "add":
x = s5+s4+s3+s2
elif self.merge_policy == "cat":
x = torch.cat([s5,s4,s3,s2],dim=1)
x = self.dropout(x)
x = self.final_conv(x)
if self.final_upsampling is not None and self.final_upsampling>1:
x = F.interpolate(x,scale_factor=self.final_upsampling,mode='bilinear',align_corners = True)
return xDataset
Dataset은 Kaggle의 Cloth Image Segmentation Dataset을 이용하였습니다.
class Customdataset(Dataset):
def __init__(self,
img_path,
mask_path,
transform = True,
device='cuda'
):
super().__init__()
self.img_path = img_path
self.mask_path = mask_path
self.transform = transform
self.device = device
def transformation(self,img):
my_transform=transforms.Compose([
transforms.Resize((256,256)),
transforms.ToTensor()])
return my_transform(img)
def __getitem__(self,index):
img_open_path = str(self.img_path) + 'img_' + '0'*(4-len(str(index+1))) + str(index+1) + '.jpeg'
mask_open_path = str(self.mask_path) + 'seg_' + '0'*(4-len(str(index+1))) + str(index+1) + '.jpeg'
img = Image.open(img_open_path).convert("RGB")
mask = Image.open(mask_open_path)
if self.transform:
img = self.transformation(img)
mask = self.transformation(mask)
img = img.to(self.device)
mask = mask.to(self.device)
return img,mask
def __len__(self):
return len(os.listdir(self.img_path)) #listdir: list file in folder
Training
Training 과정에서는 앞서 모듈화했던 모델들과 Dataset을 불러와 학습하였습니다. pytorch의 random_split 함수를 이용하여 기존 dataset을 train data와 valid data로 나누고, 학습하였습니다.
Loss Function으로는 Segmentation의 대표적인 loss인 Dice를 활용하였고, 이 loss에 대해서는 추후에 추가 포스팅을 통해 다루도록 하겠습니다.
def train(train_loader=train_loader, valid_loader = val_loader, model=model):
for epoch in range(num_epochs):
loop = tqdm(train_loader, leave=True)
mean_loss=[]
t_loss=0
model.train()
for b_id, (x,y) in enumerate(loop):
optimizer.zero_grad()
pred = model(x)
t_loss = loss_dice(pred,y,59)
t_loss.backward()
optimizer.step()
l = t_loss.item()
mean_loss.append(l)
loop.set_postfix(loss = l)
print(f"Mean loss was {sum(mean_loss)/len(mean_loss)}")
model.eval()
with torch.no_grad():
v_loss=0
mean_v_loss=[]
for b_id, (x,y) in enumerate(valid_loader):
pred = model(x)
v_loss = loss_dice(pred,y,59)
v_l = v_loss.item()
mean_v_loss.append(v_l)
print(f"Mean Valid Loss was {sum(mean_v_loss)/len(mean_v_loss)}")비록 Training의 결과가 크게 수렴하거나 결과가 좋게 나오지는 않았지만 FPN 논문을 구현하는 과정에서 pre-trained된 Model을 이용하기도 하였고, 모델을 Module화 하여 활용해보았다는 점에서 점점 논문 구현 스킬이 늘고 있는 것 같습니다. 다음에는 좀 더 고도화된 모델을 리뷰하고 구현해보면서 한 단계 더 성장해보도록 하겠습니다.
Reference
paper: chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://arxiv.org/pdf/1612.03144
Blog: https://github.com/0ju-un/pytorch-fpn-segmentation
