
무엇을 배웠을까?💡
AI, ML, DL은 어떻게 다를까?

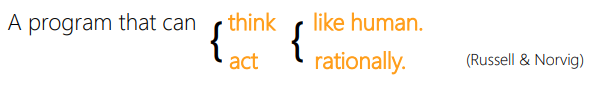
AI란 사람처럼 혹은 합리적으로 생각하거나 혹은 행동할 수 있는 프로그램을 통칭한다.
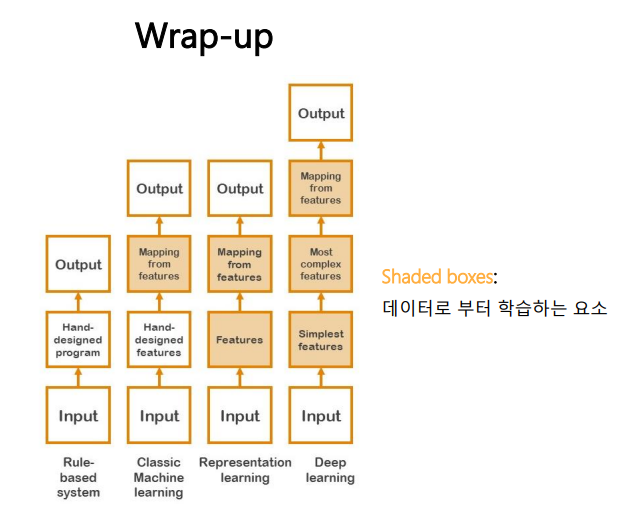
traditional AI에는 규칙 기반 시스템, Search Algorithms, Propositional Logic, First-Order Logic, Planning 등이 있다.
Machine Learning은 명시적 프로그램의 한계에서 부터 출발했다. 머신러닝의 핵심은 데이터로 부터 학습하는데에 있다. 학습이란 '세상에 대한 관측을 통해 미래의 과제에 대한 성능을 높이는 것이다.' 따라서 머신러닝이 전통적 AI방법과 가장 차별화 되는 점은 학습 데이터가 많아질수록 성능이 좋아진다는 점이다.
Deep Learning은 Hierarchical representation learning이라고도 부르는데, 인풋 데이터가 뉴럴 네트워크를 통과함에 따라서 low level feature에서 부터 high level feature까지 계층적으로 학습한다는 것이다. 예를 들어서 input으로 이미지가 들어왔을 때 뉴럴네트워크의 앞단에서는 엣지, 코너 등과 관련된 feature를 추출하고 중간 부분에서는 물체의 부분 부분들, 뒤에서는 전체적인 물체를 구분하는 feature를 학습한다. 딥러닝이 최근 폭발적으로 성장할 수 있었던 것에는 세 가지의 key component가 있다. Deep Neural network, Big data, Hardware이다.
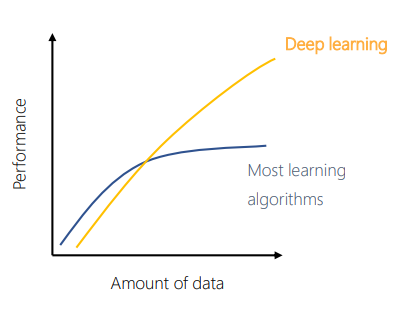
Deep Learning이 현재 뛰어난 성능을 보이는 적용 분야도 있지만 그렇지 않은 분야도 있다. 예를 들어서 특정 task에 특화되지 않은 범용 인공지능이나 medical과 같은 데이터가 귀하고 전문가에 의존하는 분야에서는 인간 이하의 성능을 보이고 있다. visual, speech recognition등 일부 perception 문제에는 인간 수준의 성능을 보이고 있고, Structured Big DATA가 있는 경우에는 인간 이상의 성능을 보이고 있다. ex)추천 알고리즘
머신러닝 Basics
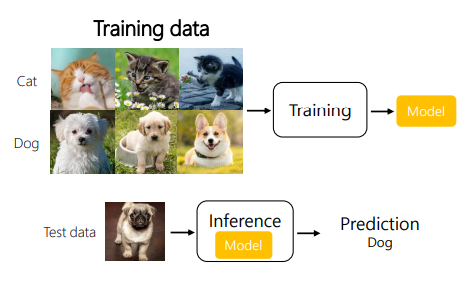
머신러닝은 크게 두 개의 스텝을 통해 이루어진다.
Training(learning): Fit a model with a training data
여기서 모델은 뉴럴네트워크나 디시전트리 등이 될 수 있다.
Test(Inference): Apply the trained model with test data, measure the performance.
전체 데이터셋을 training set, validation set, test set으로 나눠서 사용한다. validation set은 여러 모델들의 성능을 측정해서 최종 모델을 선정하기 위한 set이고 test set은 선정된 최종 모델에 대해서 성능을 측정하기 위한 set이다. 보통 작은 사이즈의 data set은 6:2:2 정도로 나누고, 100만개 이상 정도의 큰 데이터셋에서는 98:1:1로 나눈다.
K-fold cross validation (교차검정법)
데이터셋이 충분히 크지 않은 경우에는 우연히 데이터가 어떻게 나뉘었냐에 따라서 모델의 성능이 달라질 수 있다. 이럴 때 k-fold cross validation을 사용한다.
데이터셋을 k개의 부분집합으로 분화하고 그 중 하나의 부분집합을 테스트셋으로, 나머지를 트레이닝셋으로 K개의 모델을 학습하고 성능을 K개 모델의 평균 테스트셋 에러로 계산하는 방법이다.
Peformance measure: Loss function(손실함수)

분류 문제에서는 정확도 or Error rate를 사용한다.
training set에서의 error rate =
dev set에서의 error rate =
test set에서의 error rate =
머신러닝의 목적
ML의 궁극적인 목표는 새로운 unseen 인풋 데이터가 들어오더라도 좋은 성능을 내는 모델을 학습시키는 것이다. ( 으로 표현할 수 있다.)
그러나 을 측정할 방법이 마땅치 않기 때문에 을 사용한다.
이를 두 개로 쪼개어서 트레이닝 셋에대한 에러 레이트를 줄이면서 동시에 테스트셋에 대한 에러레이트가 트레이닝 셋에대한 에러 레이트와 비슷해지기를 원한다.
목적1:
optimization과 더 복잡한 모델을 써서 트레이닝 셋을 학습시킨다. 여기에서 실패해서 이 0보다 훨씬 크게 되면 Underfitting되었다고 하고, Bias가 크다고 표현한다.
목적2:
모델의 복잡도를 줄이는 regularization방법들을 사용하고, 트레이닝 데이터를 추가하여 학습시킨다. 여기에서 실패해서 과 의 차이가 커지게 되면 Overfitting되었다고 하고, Variance가 크다고 표현한다.
좋은 모델을 고르는 법
Occam's razor : 데이터와 잘 부합하는 모델 중 가장 단순한 모델을 고르는 것


capacity를 크게(더 복잡한 모델)하면 generalization이 잘 안되고, capacity를 작게(더 단순한 모델)하면 approximation 성능이 떨어지고 training error가 더 커진다.
해결책
좋은 optimization, regularization 테크닉들이 개발되었고 neural network라는 capacity가 큰 모델이 있고 추가로 빅데이터까지 있어서 optimal zone을 잘 찾아낼 수 있다.
머신러닝 문제의 분류
Classification(분류)
Data Set이 (인풋 데이터 , 클래스 레이블 )에 개로 구성되어 있을 때 인풋 데이터 로 부터 해당 인풋 데이터가 각 클래스 레이블에 속할 확률을 예측하는 모델을 학습해서 새로운 인풋 데이터가 해당하는 레이블을 찾는 것이 목표이다.
Regression(회귀)
Data Set이 (인풋 데이터 , 아웃풋 데이터 )에 개로 구성되어 있을 때 인풋 데이터를 아웃풋 데이터로 랩핑하는 모델 를 찾는 것이 목표이다.
ex) Linear Regression, Logistic Regression
Density Estimation
Data Set이 인풋 데이터 로만 이루어져 있고, 인풋데이터 의 확률 분포를 찾아내는 것이 목표이다. 인풋데이터에 숨어있는 패턴을 파악하는 과정이라고 볼 수 있다.
학습 방법의 분류
Supervised Learning(지도학습)
labeled datasets로 학습하는 경우
인풋 데이터에 대한 아웃풋 값이 페어로 주어져 있어서 둘 사이의 맵핑을 찾아내는 것이 목표이다. 아웃풋 가 유한한 값 중에 하나인지, 연속적인 값인 지에 따라서 classification과 regression으로 구분된다. labeling이 정확하게 잘 이루어져 있으면 학습의 성능은 잘 보장되는 방식이다.
Unsupervised Learning(비지도학습)
unlabeled datasets로 학습하는 경우
인풋 데이터에서 의미있는 패턴을 찾는 것이 목표이다. 인풋데이터만의 분포를 학습하기 때문에 분류 등에 바로 적용하면 Accuracy(정확도)가 낮지만 효율적인 학습을 위한 pre training이나 feature extraction등 다양한 목적으로 활용될 수 있다.
Reinforcement Learning(강화학습)
모델의 예측에 대해서 주어지는 피드백(rewards or punishments)을 이용해서 학습하는 경우
observation을 Agent가 관측했을 때 Action을 직접 알려주는 것이 아니라 어떠한 Action을 취하면 그 것에 대한 Reward값을 알려줌으로써 Agent를 학습시킨다. 다른 학습들과는 달리 sequential하게 decision making문제를 푸는 것이 특징이다.
느낀점 ✏️
전반적으로 학교 수업에서 배웠거나 하는 등의 개념이 많아서 큰 개념들은 이미 알고 있는 경우가 많았다. 그러나 용어부분에서 영어가 많아서 바로바로 이해가 되기 어려운 부분도 있었다😢
