
무엇을 배웠을까?💡
정답이 없는 문제는 그럼 어떻게 풀까?
Unsupervised Learning(비지도학습)
target variable 가 빠져있는, 즉 정답 레이블이 없는 트레이닝 셋이 주어진다. 따라서 y를 예측하는 것이 목표가 아니라 input feature에서 의미있는 패턴을 찾는 것이 목표이다.
대표적인 task로 Dimensionality Reduction(차원 축소), Clustering(군집화)등이 있다.
Unsupervised learning in AI Engineering Process
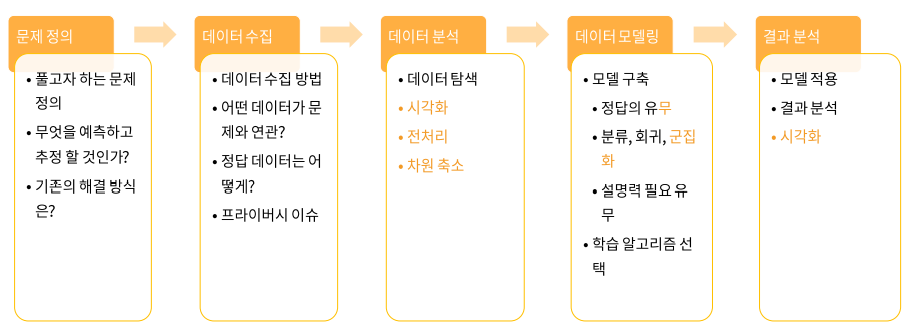 시각화, 전처리, 차원 축소를 할 때 상당히 중요하게 사용이 되고, 데이터 모델링 과정에서도 정답이 없을 수 있기 때문에 직접적으로 사용될 수 있다.
시각화, 전처리, 차원 축소를 할 때 상당히 중요하게 사용이 되고, 데이터 모델링 과정에서도 정답이 없을 수 있기 때문에 직접적으로 사용될 수 있다.
Dimensionality Reduction(차원축소)
실제 데이터들 중에는 고차원의 데이터가 많다.
ex) 추천 시스템: (num of users) * (num of movies) 행렬
이미지, 동영상: H X W X 3 (X Frames)
Curse of Dimensionality(차원의 저주)
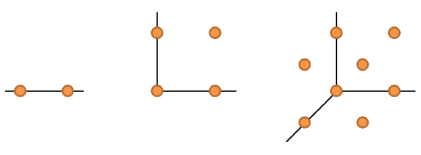 데이터가 고차원일수록 같은 성능의 모델 학습을 위해 더 많은 데이터가 필요하다.
데이터가 고차원일수록 같은 성능의 모델 학습을 위해 더 많은 데이터가 필요하다.
따라서 고차원의 데이터는 아주 많은 개수의 데이터가 있다고 해도 학습에 사용하는 것이 매우 까다롭다.
그러나 고차원으로 표현된 데이터도 본질적으로는 저차원의 공간에서 설명 가능한 경우가 많다.
 각 이미지는 8x8 즉 64개의 픽셀로 이루어진 이미지이다. 이 64차원의 이미지에서 얻는 의미있는 정보는 0부터 5까지의 여섯 개의 숫자 중 하나라는 정보이다. 따라서 6차원의 데이터로도 충분히 표현할 수 있다.
각 이미지는 8x8 즉 64개의 픽셀로 이루어진 이미지이다. 이 64차원의 이미지에서 얻는 의미있는 정보는 0부터 5까지의 여섯 개의 숫자 중 하나라는 정보이다. 따라서 6차원의 데이터로도 충분히 표현할 수 있다.
차원 축소의 방법
PCA: 데이터의 variance를 보존하면서 차원 축소
MDS: 데이터간의 거리 정보를 보존하면서 차원 축소
t-SNE: 로컬 거리 정보를 보존하면서 차원 축소 및 시각화 목적
Principal Components Analysis(PCA) - 주성분분석
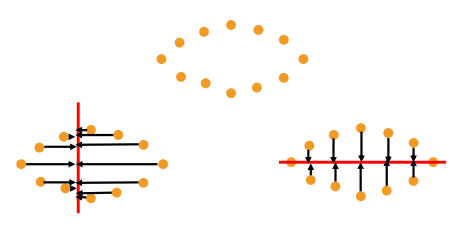 데이터에서 가장 중요한 성분을 순서대로 추출하는 것이 목표이다.
데이터에서 가장 중요한 성분을 순서대로 추출하는 것이 목표이다.
어떻게?
projection이후 variance를 최대화하는 축을 찾으면 된다.
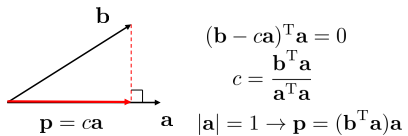 b라는 벡터를 길이가 1인 단위벡터 a에 projection하면 a라는 좌표 축에 대해서 좌표 값이 가 된다.
b라는 벡터를 길이가 1인 단위벡터 a에 projection하면 a라는 좌표 축에 대해서 좌표 값이 가 된다.
이를 데이터 행렬에 적용하면 n개의 데이터 x 각각 d차원을 갖고 있다고 하면 는 d x n 행렬이 된다. (데이터의 평균값은 제로 벡터라고 가정) 위의 a 역할을 하는 축을 w라고 하면 w는 d x 1 의 유닛 벡터이고 는 1 x n의 행렬이 된다. 즉 좌표축 w에 대한 각 데이터 n개 각각의 데이터에 대한 새로운 좌표가 된다.
w라는 좌표축에 프로젝션을 하고 난 뒤에 새롭게 계산된 좌표들의 variance를 계산하면 이 되는데 여기서 는 Covariance matrix S, 즉 공분산 행렬이 된다.
따라서 w라는 유닛 벡터 축에 원래 데이터를 projection하면 새로운 좌표들의 variance값은 ,S,w를 곱한 값이 된다.
목표는 분산값을 최대로 하는 좌표축 w를 찾는 것이다. 그러한 w는 공분산행렬 S를 고윳값 분해를 해서 나오는 고윳값과 고유벡터 중에 가장 큰 고윳값 에 해당하는 고유벡터 을 찾는 것과 같다.
이렇게 찾은 을 first principal component라고 부른다. 이 때 분산은 이 된다.
n-th principal component(n번째 주성분)은 n번째로 큰 고윳값에 해당하는 고유벡터가 되고 앞선 축들과 수직하다. 이 때 variance는 이 된다.
얼마나 많은 components를 사용해야 할까?
first principal component가 가장 많은 분산을 설명하는 축이라고 하지만 1개의 component만 사용한다는 것은 d차원의 데이터를 1차원으로 축소함을 의미한다. 따라서 적당히 많은 개수의 components를 사용해야 하는데, 여기서 등장하는 개념이 Proportion of Variance Explained(PVE) 이다. 이는 k번째 주성분이 설명하는 분산의 비율이다.
 Scree plot에서 "Elbow Point"를 찾는 식으로 component의 개수를 결정한다. Elbow Point는 Scree plot에서 기울기가 급격히 꺾이는 순간이다.
Scree plot에서 "Elbow Point"를 찾는 식으로 component의 개수를 결정한다. Elbow Point는 Scree plot에서 기울기가 급격히 꺾이는 순간이다.
혹은 미리 정한 크기의 분산을 설명하는 가장 작은 components를 사용하는 것이다.
PCA의 한계점
variance에 초점이 맞춰져 있기 때문에 PCA를 하고 나서 저차원의 데이터로 classification을 학습한다고 하면 도움이 되지 않을 수 있다. 또한 데이터의 분포가 여러 방향으로 퍼져있을 경우 의미있는 정보를 뽑아 내기 힘들다.
Multidimensional Scaling(MDS)
데이터의 분산을 보전하는 것 대신 데이터간의 거리를 보전하는 차원 축소법이다.
데이터 간의 거리를 담고 있는 n x n의 distance matrix D 에서 출발한다. Euclidean distance를 사용하는 경우 distance matrix의 r번째 행에 s번째 열의 성분 이 되고 거리 행렬 D로부터 각 성분이 인풋 데이터간의 inner product가 되는 n x n의 행렬 B를 계산해주게 되고 d차원으로 차원 축소를 한다고 하면 n x d 크기의 행렬 X를 B로부터 계산한다.
MDS는 PCA와 달리 곧바로 d차원의 좌표를 계산한다.
t-Distribute Stochastic Neighbor Embedding(t-SNE)
고차원 데이터 시각화에 많이 쓰이는 방법이다. Local neighborhood를 잘 보전하면서 차원 축소를 하는 방법이다.
 거리가 가까울 수록 neighbor일 확률이 높은데 그 확률이 가우시안 분포를 따른다는 것이다.
거리가 가까울 수록 neighbor일 확률이 높은데 그 확률이 가우시안 분포를 따른다는 것이다.
t-SNE에서는 i번째 데이터가 주어졌을 때, j번째 데이터가 i번째 데이터의 neighbor일 확률을 계산한다.
차원 축소 이전 j번째 데이터가 i번째 데이터의 neighbor일 확률을 라고 하고 차원 축소 이후 j번째 데이터가 i번째 데이터의 neighbor일 확률을 라고 하면 와 의 분포가 같아지도록 하는 를 학습하게 된다.
즉 차원 축소 이후에 i번째 데이터와 j번째 데이터의 거리를 유지하는게 아니라 j번째 데이터가 i번째 데이터의 neighbor일 확률을 보전하도록 하는 방식이다.
Clustering(군집화)
데이터셋 안에서 군집을 찾는 것
- 동일한 군집에 소속된 데이터들은 서로 유사할수록 좋음
- 다른 군집에 소속된 데이터들은 서로 다를수록 좋음
Classification vs Clustering
Classification은 class의 수와 각 데이트의 class를 사전에 알 수 있으며 새로운 데이터에 대한 class를 예측하는 것이고(supervised learning), Clustering은 군집 수, 데이터의 class 등을 알지 못하는 상태에서 최적의 구분을 예측하는 것이다(unsupervised learning).
Clustering 알고리즘의 종류
Partitioning Clustering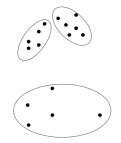 전체 데이터 영역을 특정 기준에 의해서 구분하는 것. 각 데이터는 사전에 정의된 숫자의 군집 중 하나에 소속되게 된다.
전체 데이터 영역을 특정 기준에 의해서 구분하는 것. 각 데이터는 사전에 정의된 숫자의 군집 중 하나에 소속되게 된다.
Hierarchical Clustering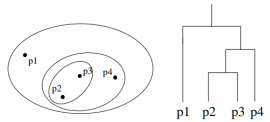 군집이 계층적인 구조를 갖고있다. 데이터들을 가까운 집단부터 차근차근 묶어가는 방식으로 군집을 형성한다.
군집이 계층적인 구조를 갖고있다. 데이터들을 가까운 집단부터 차근차근 묶어가는 방식으로 군집을 형성한다.
Density-based Clustering 밀도를 기반으로 임의의 형태의 군집을 찾을 수 있다.
밀도를 기반으로 임의의 형태의 군집을 찾을 수 있다.
Hard Clustering vs Soft Clustering
한 데이터가 하나의 군집에만 소속될 수 있는지 vs 여러 개의 군집에 소속이 가능한지
K-Means Clustering
각 군집이 하나의 중심(centroid)를 가진다. 각 데이터는 가장 가까운 중심에 할당되고, 같은 중심에 할당된 개체들이 하나의 군집을 형성하게 된다. 따라서 사전에 군집의 수 가 정해져야 하는 알고리즘이다. Sum of Squared Errors(SSE)를 최소화 하는 Partition을 찾는 것이 목적이다.
K-Means Clustering은 군집의 수 K의 개수에 따라서 꽤 다른 결과가 나오기 때문에 SSE를 사용해서 K를 정하는 룰이 존재한다. PCA에서 number of components를 정할 때와 같은 방식으로 elbow point의 k를 군집의 개수로 사용한다.
PCA에서 number of components를 정할 때와 같은 방식으로 elbow point의 k를 군집의 개수로 사용한다.
K-Means Clustering의 수행 절차
1. assignment 초기화: 각 데이터에 랜덤하게 K개 중 하나의 군집을 할당한다.
2. assignment가 바뀌지 않을 때 까지 반복
2-1. 각각의 군집에서 중심(centroid)를 계산
2-2. 각 데이터에서 가장 가까운 중심에 해당하는 군집으로 assignment를 update
K-Means Clustering의 한계점
- 적절한 군집의 개수 K를 미리 정해줘야한다.
- 초기에 random assignment를 하게 되는데 이 때 assignment에 따라서 결과가 달라진다.
- 무엇보다 각 군집의 크기나 밀도가 다르거나 군집의 모양이 구형이 아닌 경우에 어려움을 겪는다.
Agglomerative Clustering(응집군집화)
Hierarchical Clustering의 대표적인 방식이다.
Agglomerative Clustering의 수행 절차
1. 모든 데이터를 개별 군집으로 정의하고 군집 간 거리를 계산한다.
2. 모든 데이터가 하나의 군집으로 통합될 때 까지 반복한다.
2-1. 가장 가까운 두 개의 군집을 하나의 군집으로 결합한다.
2-2. 군집 간 거리 계산을 업데이트한다.
거리 계산 방식에 따라서 다양한 결합 방식이 존재한다.
Min distance : 각각의 클러스터에서 데이터들 간의 거리 중에 가장 짧은 거리를 기준으로 결합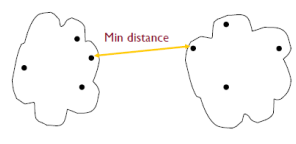
Max distance : 각각의 클러스터에서 데이터들 간의 거리 중에 가장 먼 거리를 군집 간의 거리로 정의
Average distance : 모든 데이터 쌍의 거리를 다 계산해 준 다음 평균 값을 군집 간의 거리로 정의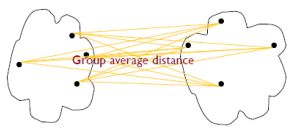
Centroids distance : 각 군집에서 중심점을 계산한 다음 중심점 간의 거리를 군집 간의 거리로 정의
Agglomerative Clustering의 한계점
- 계산복잡도가 아주 큰 알고리즘이다.
- 한 번 잘못 군집화 하면, 되돌릴 수 없다.
- linkage type에 따라 장단점이 존재한다.
DBSCAN
데이터의 density가 높은 영역과 그렇지 않은 영역으로 공간을 구분한다.
- density: 반지름 의 원 안의 data point 개수
- dense region: MinPts(최소한의 data point의 개수)개 이상의 데이터를 포함하는 반지름 의 원
- neighborhood: 두 data point간의 거리가 이하인 경우
- core point: 반지름 안에 MinPts 개 이상의 데이터를 포함하고 있는 data point
- border point: 반지름 안에 MinPts 개 미만의 데이터를 포함하지만, core point와 neighborhood인 point
- noise point: core point, border point 모두에 속하지 않는 point
- density dege: 두 data point가 neighborhood일 경우 둘 사이에 density edge를 둔다.
- density-connected: 두 data point가 일련의 edge들을 통해 연결되는 경우
DBSCAN의 수행절차
1. data point들을 core, border, noise 중 하나로 labeling한다.
2. noise point들을 없앤다.
3. 군집에 assign되지 않은 모든 core point x에 대해 다음을 반복한다.
3-1. point x및 point x와 denisty-connected된 모든 point들에 새로운 군집을 assign한다.
4. border point는 가장 가까운 core point의 군집으로 assign한다.
DBSCAN의 수행 예시
- noise에 강인하며 다양한 모양의 군집을 다룰 수 있다.
- density가 다른 경우 잘 안될 수 있다.
요약
- Unsupervised Learning은 데이터의 구조를 이해하는 데 매우 중요하며, Supervised Learning을 위한 전처리, 데이터 시각화 등에 유용하게 사용될 수 있다.
- 대표적으로 두 가지의 task를 가진다. Dimensionality Reduction, Clustering
- 정답 데이터(label)이 없고, 목적도 정해져 있지 않기 때문에 supervised learning 보다 훨씬 어렵다.
느낀점 ✏️
갑자기 엄청 수학적인 내용이 많아진 것 같다. 대학교 1학년 때 배운 선형대수가 이런 식으로 쓰일 줄 몰랐다. 이럴 줄 알았으면 선형대수를 더 열심히 공부했을 것 같다. 심지어 "a벡터를 b벡터에 내적하면"이라는 말을 들었을 때 순간 내적이 뭐였지..? 라고 생각했다. 고등학교 때야 내적을 그냥 하라니까 했는데 이렇게 마주치니 당황스러웠다. 수학적인 개념들을 접한지 오래돼서 그런지 이해하는 데 시간이 걸린 부분이 많았다.
