DROID-SLAM 완전 정리: Optical Flow를 SLAM으로 바꾸는 법
이 글은 DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras를 정리한 글이다. deep-learning SLAM이 핫하기에..
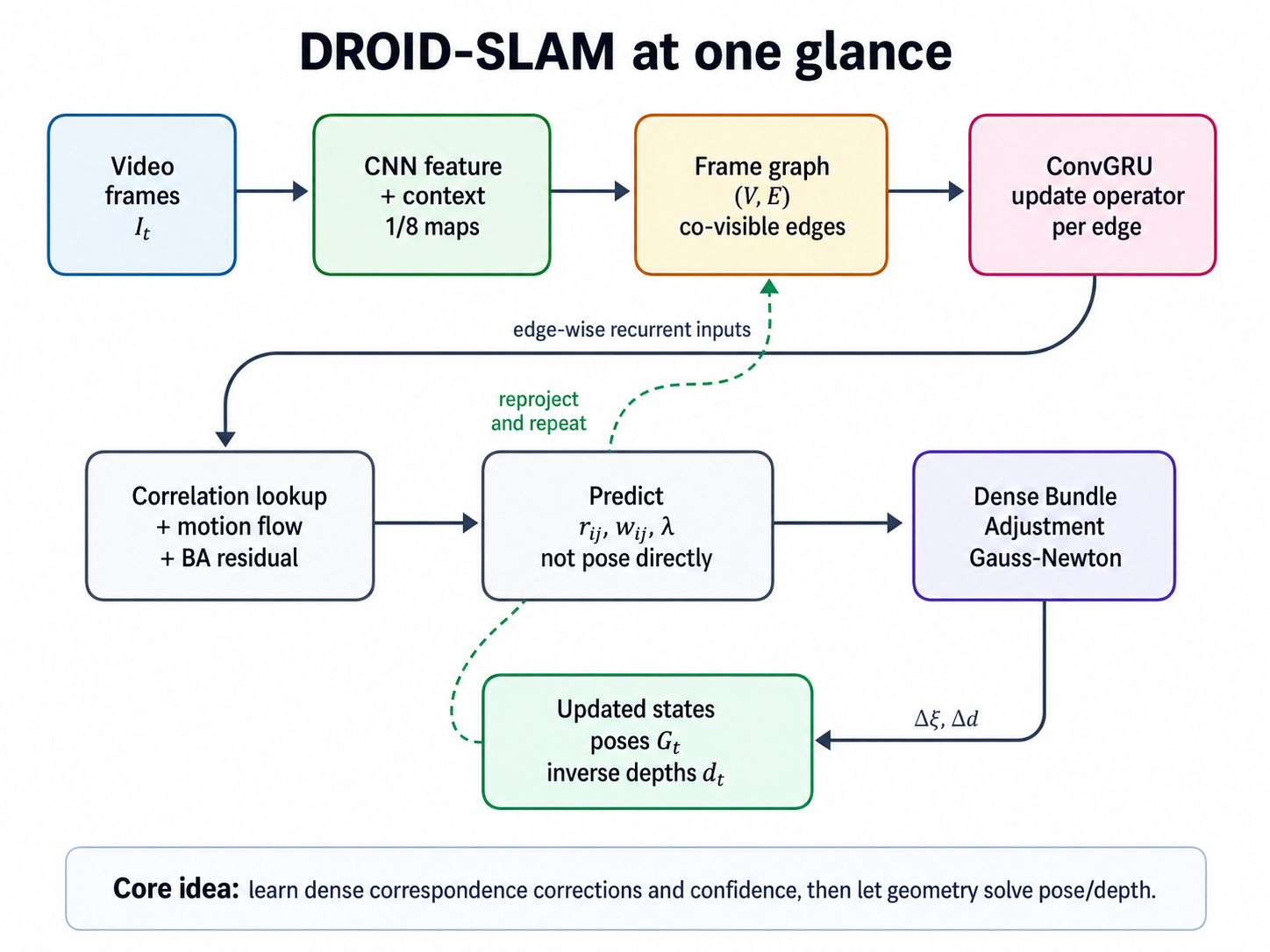
핵심은 단순하다. DROID-SLAM은 pose를 네트워크가 직접 찍어내는 방식이 아니다. 네트워크는 dense correspondence의 수정량과 신뢰도를 예측하고, 실제 pose/depth 업데이트는 Dense Bundle Adjustment(DBA)가 기하학적으로 푼다.
0. 한 문장으로 요약하면
DROID-SLAM은 각 프레임의 camera pose와 pixel-wise inverse depth를 상태 변수로 두고, 프레임 사이 dense correspondence를 반복적으로 수정하면서, 그 correspondence를 가장 잘 만족하는 pose/depth를 differentiable Dense Bundle Adjustment로 갱신하는 visual SLAM 시스템이다.
조금 더 직관적으로 말하면 다음과 같다.
“현재 pose와 depth로 보면 이 픽셀은 다음 프레임의 여기로 가야 한다.”
“그런데 feature correlation을 보니 조금 틀린 것 같다.”
“그러면 correspondence를 이만큼 고치고, 이 residual을 믿을 정도도 같이 예측하자.”
“이 수정된 correspondence들을 가장 잘 만족하도록 pose와 depth를 BA로 다시 풀자.”
“이 과정을 반복하자.”
이 반복 구조가 DROID-SLAM의 본질이다.
1. 왜 DROID-SLAM이 중요한가?
기존 visual SLAM은 크게 두 계열로 설명할 수 있다.
첫째는 feature-based indirect SLAM이다. ORB-SLAM 계열처럼 corner/keypoint를 뽑고 descriptor를 매칭한 뒤, reprojection error를 최소화한다. 장점은 기하학적으로 명확하고 최적화가 비교적 안정적이라는 점이다. 단점은 texture가 부족하거나 motion blur, 반복 패턴, dynamic object가 있는 경우 feature tracking이 깨질 수 있다는 점이다.
둘째는 direct SLAM이다. LSD-SLAM, DSO처럼 image intensity 또는 photometric error를 직접 최소화한다. 장점은 keypoint에만 의존하지 않고 더 많은 픽셀 정보를 쓸 수 있다는 점이다. 단점은 photometric consistency가 깨지는 상황, 노출 변화, rolling shutter, blur 등에 취약할 수 있고 optimization landscape가 어려워질 수 있다는 점이다.
DROID-SLAM은 이 둘 중 하나로 깔끔하게 들어가지 않는다. 전체 이미지를 dense하게 사용한다는 점에서는 direct 계열과 닮았지만, 최적화하는 것은 photometric error가 아니라 learned dense correspondence에 대한 geometric reprojection error다. 즉, “모든 픽셀을 쓰는 indirect SLAM”에 가깝다.
이 관점이 중요하다. DROID-SLAM은 딥러닝이 기하학을 대체한 논문이 아니라, 딥러닝이 correspondence와 confidence를 만들고, 기하학적 BA가 상태를 푸는 구조다.
2. DROID-SLAM이 들고 있는 상태 변수
DROID-SLAM은 입력 비디오를 다음과 같이 둔다.
각 이미지 에 대해 두 가지 상태를 유지한다.
여기서 는 camera pose이고, 는 depth가 아니라 inverse depth다. 논문에서는 depth라고 부르지만 실제 parameterization은 inverse depth다.
inverse depth를 쓰는 이유는 visual SLAM/SfM에서 흔하다. 멀리 있는 점은 depth 가 커질수록 변화가 둔감해지고 수치적으로 다루기 어렵다. inverse depth 를 쓰면 먼 점은 0에 가까워지고, monocular setup에서 scale과 depth uncertainty를 다루기 더 편해진다.
DROID-SLAM은 또한 frame graph를 사용한다.
node는 frame이고, edge 는 frame 와 frame 가 서로 볼 수 있는 영역, 즉 co-visibility가 있다고 보는 연결이다. 이 edge 위에서 correspondence residual을 만들고, 그 residual들이 pose/depth를 업데이트하는 constraint가 된다.
중요한 점은 frame graph가 고정되어 있지 않다는 것이다. pose와 depth가 업데이트되면 co-visibility도 다시 평가할 수 있고, camera가 이전에 방문한 영역으로 돌아오면 long-range edge가 추가되어 loop closure 역할을 한다.
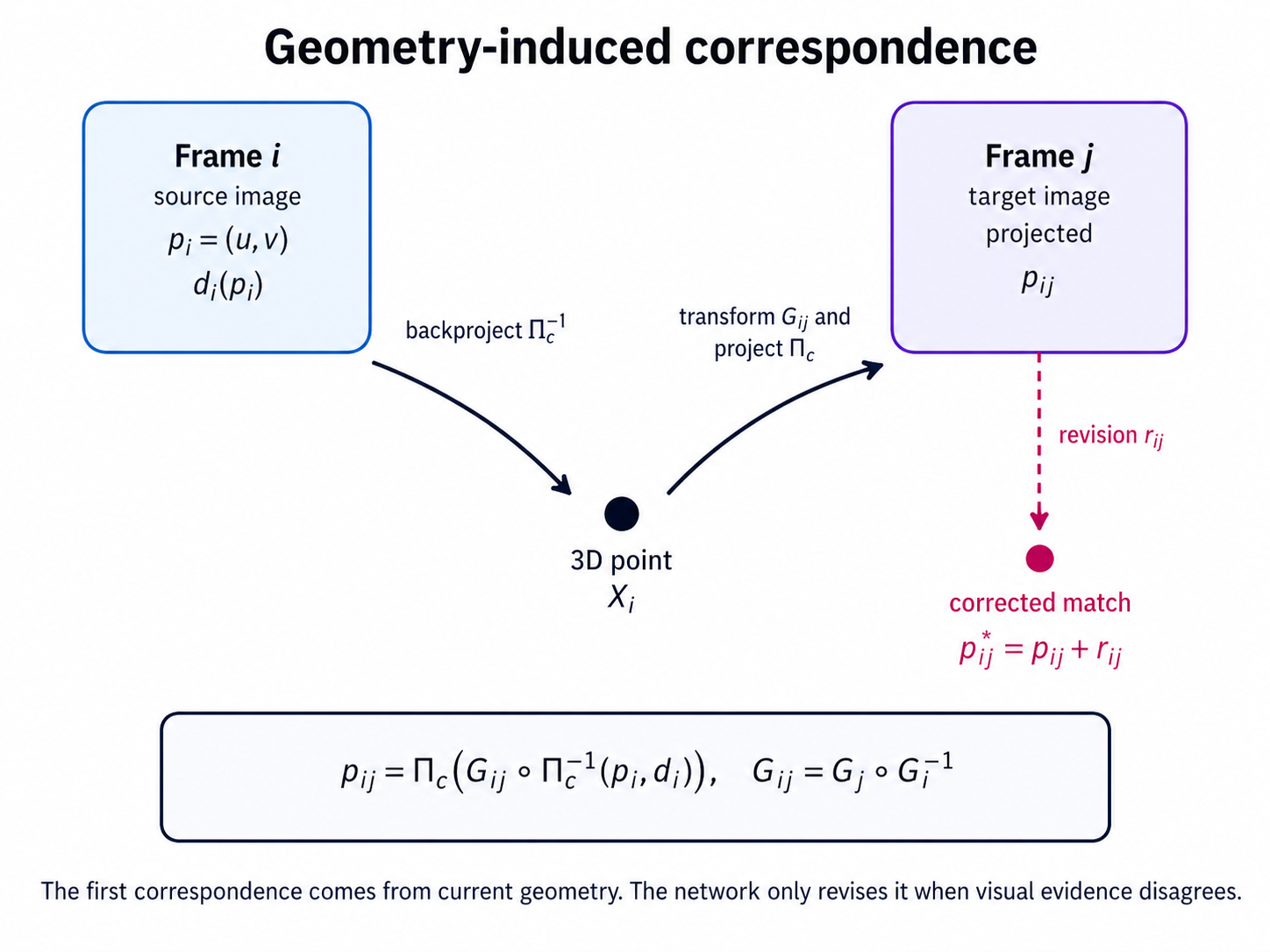
3. 핵심 수식 1: 현재 pose/depth가 만드는 dense correspondence
DROID-SLAM의 가장 중요한 수식은 사실 이 projection 식이다.
여기서 는 frame 의 pixel coordinate grid다. 즉, 하나의 점이 아니라 이미지 전체 픽셀 좌표 집합이다.
의미는 다음과 같다.
- frame 의 픽셀 를 inverse depth 로 3D point로 back-projection한다.
- relative pose 로 frame 기준으로 보낸다.
- camera projection 로 다시 image plane에 투영한다.
- 그렇게 얻은 좌표가 다.
즉, 는 “현재 추정한 pose와 depth가 맞다면, frame 의 픽셀은 frame 의 어디에 보여야 하는가?”에 대한 답이다.
pinhole camera를 예로 들면, homogeneous pixel 에 대해 back-projection은 다음처럼 쓸 수 있다.
그 뒤 상대 변환을 적용하고 다시 projection한다.
이때 는 network가 예측한 optical flow가 아니다. 현재 geometry가 유도한 correspondence다. 이것이 틀려 있으면 pose가 틀렸거나 depth가 틀렸거나 둘 다 틀린 것이다.
4. 핵심 수식 2: correlation volume은 무엇인가?
DROID-SLAM은 RAFT의 아이디어를 가져와 dense feature correlation을 사용한다.
각 이미지에서 feature map을 뽑는다.
그리고 frame graph의 edge 마다 all-pairs correlation volume을 만든다.
이 식을 말로 풀면 다음과 같다.
frame 의 위치 feature와 frame 의 위치 feature가 얼마나 비슷한가?
따라서 는 단순히 “두 픽셀이 같다/아니다”를 나타내는 binary 값이 아니다. feature vector 간 dot product로 만든 visual similarity score field다.
여기서 초보자가 자주 헷갈리는 부분이 있다.
DROID-SLAM이 매 iteration마다 모든 후보 픽셀을 새로 직접 고르는 것은 아니다. 현재 pose/depth가 만든 correspondence 주변에서 correlation lookup을 한다. 즉, geometry가 “여기쯤일 것”이라고 말하면, network가 그 주변의 correlation pattern을 보고 “조금 오른쪽으로 가야 한다”, “이 residual은 믿을 만하다/아니다”를 판단한다.
논문은 correlation volume의 마지막 두 차원에 pooling을 적용해 4-level correlation pyramid를 만든다. 이렇게 하면 작은 displacement뿐 아니라 더 큰 displacement에 대해서도 lookup할 수 있다.
5. Update operator: 네트워크가 직접 pose를 예측하지 않는다
DROID-SLAM의 update operator는 3x3 convolutional GRU다. 이 ConvGRU는 edge 마다 recurrent하게 작동한다.
입력으로 들어가는 핵심 정보는 다음과 같다.
- 현재 correspondence 주변의 correlation feature
- 현재 pose/depth가 유도한 motion flow
- 이전 BA residual
- context network feature
그리고 출력은 크게 두 가지다.
는 revision flow다. 현재 geometry가 만든 correspondence 를 얼마나 수정할지 나타낸다.
는 confidence map이다. 이후 BA objective에서 residual의 weight 역할을 한다.
여기서 굉장히 중요한 해석이 나온다.
DROID-SLAM의 network는 최종 pose를 직접 출력하지 않는다. 직접 출력하는 것은 corrected correspondence 와 그 confidence 다. pose와 depth는 그 다음 Dense Bundle Adjustment가 기하학적으로 계산한다.
이 구조가 DROID-SLAM을 단순 pose regression network와 완전히 다르게 만든다.
6. 핵심 수식 3: Dense Bundle Adjustment(DBA)
DROID-SLAM의 Dense Bundle Adjustment는 corrected correspondence 를 가장 잘 만족하는 pose와 inverse depth를 찾는다.
objective는 다음과 같다.
이 식은 DROID-SLAM 전체를 이해하는 데 가장 중요하다.
왼쪽 항 는 network가 수정한 correspondence다. 오른쪽 항은 현재 업데이트하려는 pose/depth 가 만들어내는 projection이다. DBA는 이 둘의 차이를 줄인다.
즉, DROID-SLAM은 raw RGB photometric error를 직접 줄이는 것이 아니다.
같은 brightness residual을 직접 최소화하지 않는다. 대신 network가 만든 correspondence target에 대해 geometric reprojection error를 최소화한다.
이 차이가 매우 중요하다.
photometric error는 조명, 노출, blur, rolling shutter, non-Lambertian surface에 취약하다. 반면 learned feature correlation과 recurrent update는 appearance 변화에 대해 더 유연할 수 있다. 하지만 최종 상태 업데이트는 여전히 geometry-constrained BA로 수행된다.
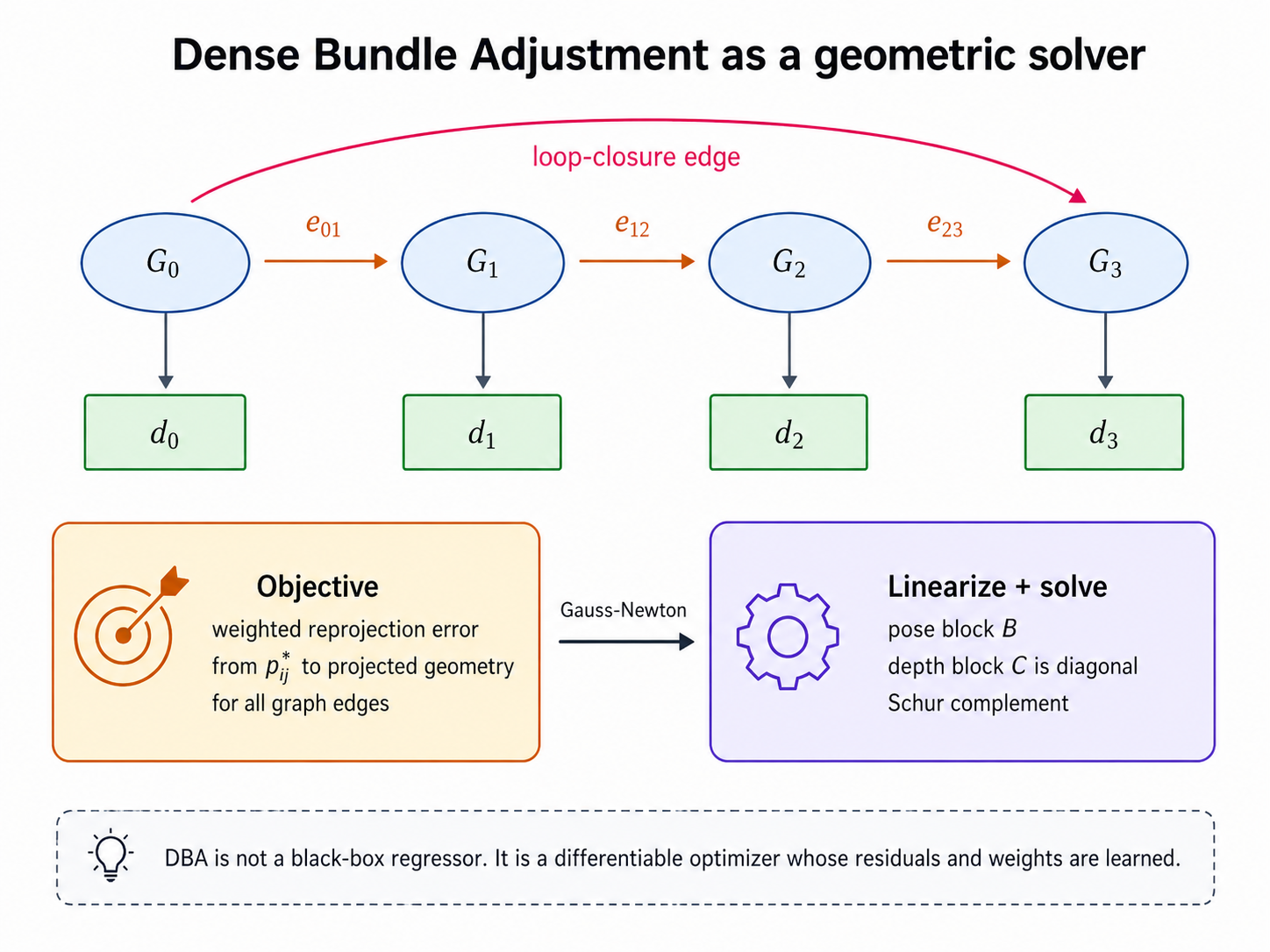
7. DBA를 Gauss-Newton으로 푸는 구조
DBA objective는 nonlinear least squares 문제다. DROID-SLAM은 이를 local parameterization으로 linearize하고 Gauss-Newton update를 구한다.
pose update는 Lie algebra에서 표현된다.
inverse depth는 일반 vector addition으로 업데이트된다.
linearization 후 normal equation은 pose variable과 depth variable로 나눠 다음처럼 쓸 수 있다.
여기서 중요한 구조적 사실이 있다.
각 residual term은 하나의 source pixel depth variable에만 직접 의존한다. 그래서 depth block 가 diagonal structure를 갖는다. 이 구조 덕분에 을 싸게 계산할 수 있고, Schur complement로 pose update를 효율적으로 구할 수 있다.
이 부분이 전문가 입장에서 DROID-SLAM을 봐야 하는 핵심이다.
DROID-SLAM은 dense pixel-wise depth를 상태 변수로 들고 있지만, naive하게 모든 pixel depth와 모든 pose를 거대한 dense system으로 푸는 것이 아니다. residual 구조를 이용해 block-sparse/diagonal property를 활용한다. 그래서 “dense”하지만 완전히 무식하게 dense하지 않다.
8. DROID-SLAM의 반복 구조를 다시 정리하면
한 iteration을 아주 단순화하면 다음 순서다.
Step 1. 현재 상태로 correspondence 계산
Step 2. correlation lookup
현재 correspondence 주변의 feature correlation을 가져온다.
Step 3. ConvGRU가 correction과 confidence 예측
Step 4. DBA가 pose/depth update 계산
Step 5. 상태 갱신
이 과정을 반복하면 pose와 depth가 fixed point로 수렴하기를 기대한다.
9. Monocular, Stereo, RGB-D를 어떻게 같은 시스템으로 처리하는가?
DROID-SLAM의 흥미로운 점은 monocular로 학습했지만, test time에 stereo나 RGB-D도 활용할 수 있다는 점이다. 이게 가능한 이유는 최종 구조가 pose regression이 아니라 optimization objective이기 때문이다.
9.1 Monocular
monocular에서는 절대 scale을 직접 알 수 없다. 따라서 trajectory는 similarity transform까지의 ambiguity를 가진다. 논문은 training 안정성을 위해 첫 두 pose를 ground truth pose로 고정한다. 첫 pose를 고정하면 6-DoF gauge freedom이 제거되고, 두 번째 pose까지 고정하면 scale freedom이 해결된다.
inference에서도 monocular SLAM은 본질적으로 scale ambiguity를 갖는다. 따라서 monocular 결과를 해석할 때는 절대 metric scale을 바로 믿기보다, evaluation protocol에서 alignment가 어떻게 수행되는지 확인해야 한다.
9.2 Stereo
stereo에서는 left/right camera 사이의 relative pose가 calibration으로 주어진다. DROID-SLAM은 system 자체를 크게 바꾸지 않고, left/right frame을 추가 frame처럼 다룬다. DBA layer에서는 left-right relative pose를 고정하고, cross-camera edge를 추가해 stereo constraint를 활용한다.
즉, stereo 정보를 “별도 depth network”로 처리하는 것이 아니라 frame graph와 DBA objective에 더 강한 geometric constraint로 넣는 방식이다.
9.3 RGB-D
RGB-D에서는 sensor depth가 주어진다. 하지만 DROID-SLAM은 sensor depth를 절대적인 정답으로 고정하지 않는다. depth sensor는 noise가 있고 missing observation도 있기 때문이다. 따라서 inverse depth는 여전히 variable로 두고, measured depth와 predicted depth 사이의 차이를 penalize하는 term을 objective에 추가한다.
개념적으로 쓰면 다음과 같다.
위 식은 개념 설명용이다. 핵심은 RGB-D depth를 hard assignment로 박아 넣는 것이 아니라, optimization에 추가 constraint로 넣는다는 점이다.
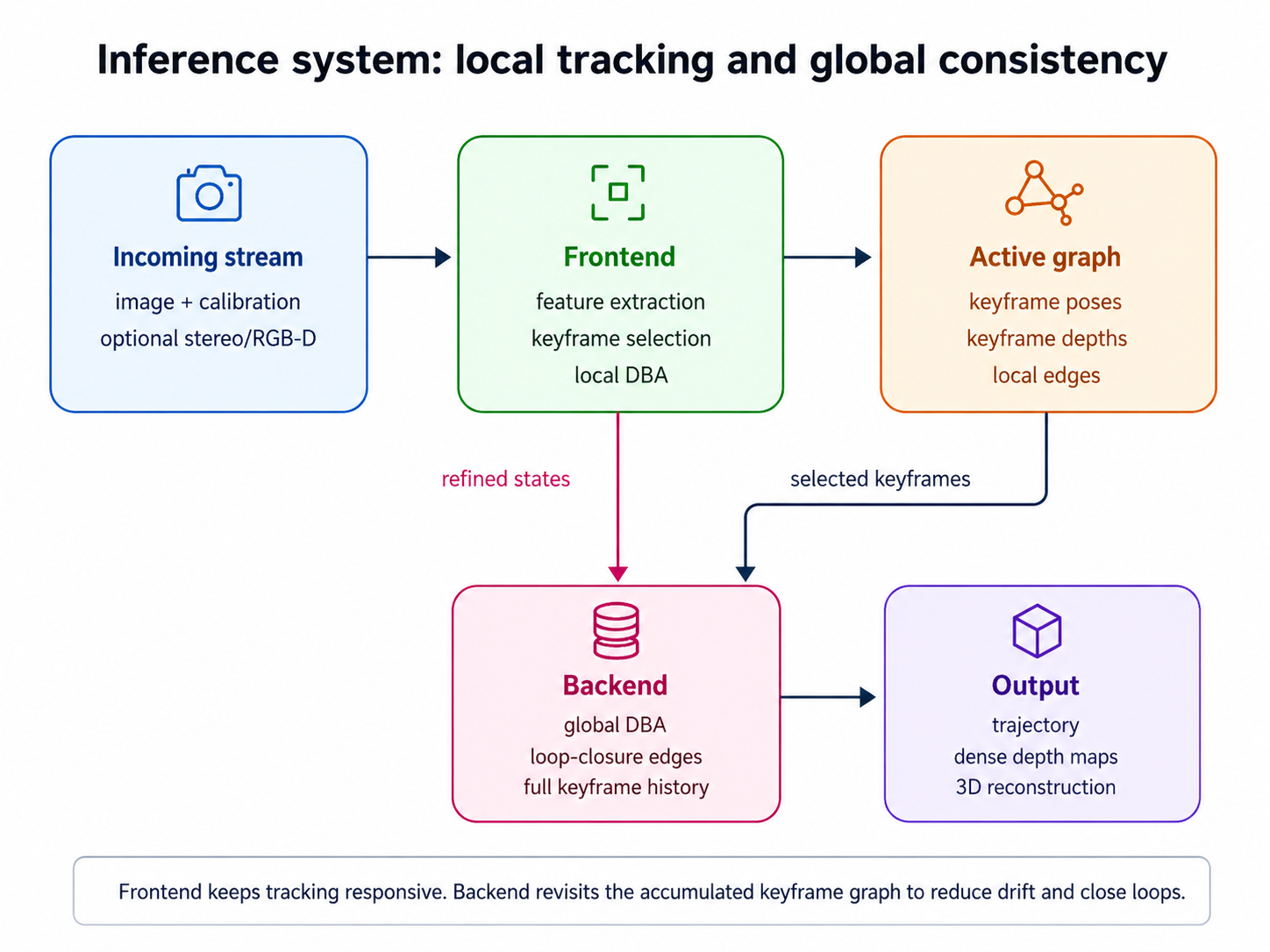
10. 실제 SLAM 시스템: frontend와 backend
논문 속 DROID-SLAM은 network module 하나만 말하는 것이 아니라, 실제 SLAM system으로 구성되어 있다.
10.1 Initialization
DROID-SLAM은 초기화를 위해 frame을 모은다. 논문 기준으로는 12개 frame을 모으고, 그 사이 optical flow가 충분히 큰 frame만 유지한다. 이후 시간적으로 가까운 keyframe 사이에 edge를 만들고 update operator를 여러 번 적용한다.
이 설계는 feature-based SLAM의 복잡한 map initialization과 비교하면 단순한 편이다. 하지만 단순하다는 것이 “아무렇게나 시작해도 된다”는 뜻은 아니다. 충분한 parallax와 motion이 없으면 monocular geometry는 여전히 불안정하다.
10.2 Frontend
frontend는 incoming video stream을 직접 처리한다.
주요 역할은 다음과 같다.
- 새 frame의 feature 추출
- keyframe 관리
- co-visible keyframe과 edge 추가
- local bundle adjustment 수행
- redundant keyframe 제거
새 frame이 들어오면 평균 optical flow 기준으로 가까운 이웃 frame들과 edge를 만든다. pose는 linear motion model로 초기화하고, update operator와 DBA를 통해 keyframe pose와 depth를 갱신한다.
10.3 Backend
backend는 전체 keyframe history를 대상으로 global bundle adjustment를 수행한다. 이때 frame graph를 다시 만들고, temporal edge뿐 아니라 distance matrix 기반으로 long-range edge를 추가한다. long-range edge는 loop closure에 해당한다.
DROID-SLAM이 visual odometry에 머물지 않고 SLAM이라고 불릴 수 있는 이유가 여기에 있다. 단순히 최신 frame만 tracking하는 것이 아니라, keyframe graph 전체를 다시 최적화해 drift를 줄인다.
11. Training objective
DROID-SLAM은 학습 시 pose loss와 flow loss를 사용한다.
pose loss는 ground truth pose 와 predicted pose 사이의 SE(3) distance로 표현된다.
flow loss는 predicted pose/depth가 유도한 optical flow와 ground truth pose/depth가 유도한 optical flow 사이의 L2 distance다.
여기서 중요한 점은 DROID-SLAM이 “flow network를 학습한다”로 끝나지 않는다는 것이다. network의 output은 DBA layer를 통과하고, 최종 pose/depth trajectory에 대한 supervision을 받는다. DBA layer가 computation graph 안에 들어가 있으므로 backpropagation이 가능하다.
논문은 training sequence로 7-frame clip을 사용하고, update operator를 unroll하여 각 iteration output에 loss를 적용한다. 뒤쪽 iteration일수록 더 큰 weight를 주기 위해 exponential weighting을 사용한다.
12. 결과를 볼 때 중요한 포인트
DROID-SLAM은 논문에서 TartanAir, EuRoC, TUM-RGBD, ETH3D-SLAM 등 여러 benchmark에서 평가된다.
핵심적으로 봐야 할 결과는 세 가지다.
첫째, monocular로 학습했는데 stereo/RGB-D test에서도 동작한다. 이것은 network가 특정 sensor output을 직접 regression한 것이 아니라, DBA objective에 sensor constraint를 추가할 수 있는 구조이기 때문이다.
둘째, catastrophic failure가 적다. 논문은 ETH3D RGB-D benchmark에서 32개 중 image data가 있는 30개 sequence를 성공적으로 tracking했다고 보고한다.
셋째, dense optimization을 하면서도 real-time system으로 구성된다. 다만 memory와 GPU resource는 여전히 큰 제한이다. 논문은 frontend와 backend를 나누고, backend는 full keyframe feature map을 저장해야 하므로 memory-intensive하다고 설명한다.
13. DROID-SLAM을 잘못 이해하기 쉬운 지점들
오해 1. “DROID-SLAM은 pose를 network가 바로 예측한다.”
아니다. DROID-SLAM의 update operator는 pose/depth update를 직접 regression하지 않는다. network는 dense correspondence correction 와 confidence 를 예측하고, pose/depth update는 DBA가 계산한다.
오해 2. “는 최종 matching score다.”
정확히는 feature map 사이의 all-pairs dot product correlation volume이다. 이 correlation 자체가 최종 correspondence는 아니다. 현재 geometry가 만든 주변에서 lookup하고, ConvGRU가 그 local correlation pattern을 해석해 revision flow를 만든다.
오해 3. “는 여러 후보 중 하나를 고른 것이다.”
수식상 는 각 edge와 각 source pixel에 대해 하나의 corrected coordinate field다.
여러 후보라는 표현은 correlation lookup 과정에서 주변 후보들의 similarity를 본다는 의미로는 맞지만, 최종 DBA objective에 들어가는 target correspondence는 하나다.
오해 4. “DROID-SLAM은 direct photometric SLAM이다.”
아니다. 이미지를 dense하게 쓰지만 objective는 photometric residual이 아니라 learned correspondence에 대한 weighted reprojection residual이다.
오해 5. “DBA는 그냥 일반 BA와 같다.”
일반 BA와 철학은 같지만, 여기서는 sparse keypoint가 아니라 dense pixel-wise inverse depth를 상태 변수로 둔다. 또한 correspondence target과 residual weight가 neural update operator에서 나온다. 따라서 classical BA와 deep recurrent correspondence estimation이 결합된 형태로 보는 것이 정확하다.
14. 전문가 관점에서 봐야 할 contribution
DROID-SLAM의 contribution은 “딥러닝으로 SLAM을 했다”가 아니다. 그렇게 말하면 논문을 너무 얕게 본 것이다.
더 정확히는 다음 네 가지다.
14.1 Recurrent optimization-inspired design
DROID-SLAM은 RAFT처럼 iterative refinement를 사용하지만, RAFT가 optical flow field를 반복 업데이트하는 것과 달리 DROID-SLAM은 pose와 depth를 반복 업데이트한다. 즉, dense correspondence estimation을 SLAM state estimation 안으로 끌어들인다.
14.2 Learned measurement model + geometric optimizer
classical SLAM에서 어려운 부분 중 하나는 correspondence와 outlier rejection이다. DROID-SLAM은 이 부분을 learned update operator가 담당하게 한다. 대신 state update는 geometric optimizer가 담당한다.
이 분업이 중요하다.
- network: 어떤 correspondence를 믿을지 판단
- DBA: 그 correspondence를 만족하는 pose/depth를 기하학적으로 계산
14.3 Dense depth variable without learned depth basis
BA-Net이나 DeepFactors 계열은 depth basis나 learned latent representation에 의존하는 경우가 있었다. DROID-SLAM은 pixel-wise inverse depth를 직접 variable로 최적화한다. 이 때문에 더 flexible하지만, 동시에 메모리와 계산량 문제가 커진다.
14.4 Same model, multiple modalities
monocular training만으로 stereo/RGB-D까지 활용할 수 있는 것은 network가 modality-specific output을 직접 예측하는 방식이 아니라, DBA objective에 constraint를 추가할 수 있는 구조이기 때문이다.
15. 한계도 명확하다
DROID-SLAM이 강력한 시스템인 것은 맞지만, 만능은 아니다.
15.1 메모리와 연산량
논문과 공식 repository 모두 DROID-SLAM의 GPU memory 요구량이 작지 않다는 점을 보여준다. 특히 backend는 전체 keyframe history의 feature map을 저장해야 하므로 메모리 부담이 크다. dense method의 본질적 비용이다.
15.2 Dynamic object에 대한 명시적 모델은 아니다
DROID-SLAM은 confidence map 를 통해 잘못된 correspondence를 약하게 만들 수 있다. 하지만 dynamic object를 semantic하게 분리하거나, map에서 장기적으로 제거하는 lifelong mapping system은 아니다. dynamic scene에서 robust할 수는 있지만, dynamic object reasoning 자체가 논문의 중심 contribution은 아니다.
15.3 Map quality와 SLAM accuracy는 다르다
DROID-SLAM은 dense depth map과 trajectory를 만든다. 하지만 이것이 곧바로 high-fidelity 3D reconstruction이나 surface-level mapping을 의미하지는 않는다. 논문도 high-quality dense reconstruction은 multi-view stereo 영역에 가깝고 본 논문의 범위 밖이라고 둔다.
15.4 Learned system의 generalization 문제
논문은 TartanAir synthetic data만으로 학습하고 여러 dataset에서 좋은 generalization을 보인다. 하지만 learned feature/correspondence 기반 시스템인 이상, training distribution과 크게 다른 카메라, 조명, motion pattern, scene statistics에서는 성능 검증이 필요하다.
16. DROID-SLAM을 공부한 뒤 남는 핵심 직관
DROID-SLAM을 한 문장으로 외우면 이렇게 정리할 수 있다.
DROID-SLAM은 “flow를 예측하는 SLAM”이 아니라, flow-like dense correspondence correction을 measurement로 사용해 pose와 depth를 BA로 반복 최적화하는 SLAM이다.
초보자는 다음 세 가지만 기억하면 된다.
- 각 frame은 pose 와 inverse depth map 를 가진다.
- 현재 pose/depth로 pixel correspondence 를 만들고, network가 이를 로 수정한다.
- 수정된 correspondence를 만족하도록 DBA가 pose/depth를 업데이트한다.
전문가는 다음 세 가지를 다시 생각해볼 만하다.
- DROID-SLAM은 learned frontend와 geometric backend의 경계가 매우 정교하다.
- confidence 는 단순 score가 아니라 BA residual weighting으로 들어간다.
- dense pixel-wise inverse depth를 쓰면서도 Schur complement 구조로 계산 가능하게 만든 점이 핵심이다.
17. 직접 논문을 다시 읽을 때 체크할 질문
논문을 다시 읽을 때는 아래 질문을 들고 보면 훨씬 잘 보인다.
- 는 optical flow인가, geometry-induced correspondence인가?
- 는 어디서 나오며, DBA objective에서 어떤 역할을 하는가?
- 는 matching score인가, residual confidence인가?
- DBA objective는 photometric error인가, geometric reprojection error인가?
- 왜 depth block 가 diagonal이 되는가?
- 왜 monocular로 학습했는데 stereo/RGB-D test가 가능한가?
- frontend local BA와 backend global BA는 어떤 역할 분담을 하는가?
- DROID-SLAM은 robust correspondence estimation을 학습한 것인가, SLAM 전체를 black-box로 학습한 것인가?
이 질문들에 답할 수 있으면 DROID-SLAM을 단순히 “읽었다”가 아니라 “구조를 이해했다”고 말할 수 있다.
18. 마무리
DROID-SLAM의 가치는 딥러닝과 기하학 중 하나를 선택하지 않았다는 데 있다. 고전 SLAM의 bundle adjustment는 여전히 강력하다. 하지만 correspondence, confidence, outlier handling은 hand-crafted rule만으로는 어렵다.
DROID-SLAM은 이 둘을 분리해서 잘 결합한다.
- correspondence correction과 confidence는 network가 학습한다.
- pose와 depth는 Dense Bundle Adjustment가 기하학적으로 푼다.
- 이 전체 과정을 recurrent하게 반복하고, 학습 시에는 DBA layer를 통과해 gradient가 흐른다.
그래서 DROID-SLAM은 단순한 deep visual odometry가 아니다. classical SLAM의 핵심인 graph optimization과 bundle adjustment를 유지하면서, dense learned correspondence를 결합한 system-level visual SLAM이다.
결국 DROID-SLAM이 보여준 가장 중요한 메시지는 이것이다.
좋은 SLAM 시스템은 geometry를 버리지 않는다.
대신 learning이 geometry가 어려워하는 부분을 도와주게 만든다.
References
- Zachary Teed, Jia Deng, DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras, NeurIPS 2021.
- Official implementation:
princeton-vl/DROID-SLAM.
