이 논문은 NeRF를 보완한 논문 중 하나입니다.
NeRF는 입력 값으로 사진을 넣을 때 카메라 Pose도 필요합니다. 하지만 정확한 Pose를 아는 것은 쉽지 않고 모든 값을 넣어주기도 힘들기 때문에 이 논문은 딥러닝을 통해 Pose를 입력할 필요 없이 NeRF scene 합성을 진행하는걸 보여줍니다.
Introduction
NeRF 학습시 input image의 camera parameter를 넣어줘야합니다.
보통 SFM의 library 중 하나인 colmap을 사용하여 camera parameter를 추정합니다.
이것은 처리시간이 길고 미분가능성이 부족하다는 단점이 존재합니다.
요즘 NeRFmm,BARF,SC-NeRF 등 많은 논문에서 camera pose와 representation을 동시에 Optimization하려는 시도를 하고 있습니다.
하지만 이 경우 Forward Facing scene(앞에서 거리가 비슷한 곳에서 촬영한 scene)에서만 적용가능하고 Camera Motion이 커지면 잘 안될 수 있습니다. 이러한 원인을 이 논문에서는 두가지로 정리합니다.
1. Image 사이의 관계성을 고려하지 않고 Camera Pose를 추정
2. Shape-Radiance Ambiguity문제가 발생
여기서 Shape-Radiance Ambiguity 문제는 Regularization없이 학습 시 image와는 관계없이 기하학적 모양을 학습해버리는 현상을 말합니다.
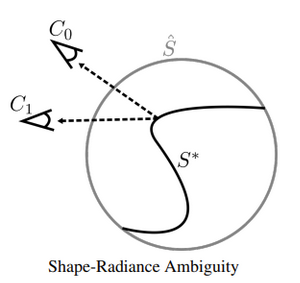
위 그림에서 실제 S* 모양이 아닌 보편적인 원형 S^으로 학습해버리는 것이 Shape-Radiance Ambiguity입니다.
이 문제를 해결하기 위해서 위 논문에서는 Monoclular Depth Estimation을 학습에 결합합니다.
이러한 접근에는 3가지 장점이 있다고 설명합니다.
1.Monocular Depth는 Geometry 단서를 제공
2.Relative Pose는 training에 사용하기 용이
3.Monocular Depth는 학습에 결합하기 가벼움
결론적으로 이 논문은 Monocular Depth Estimation과 Relative Pose를 활용하여 Prior Pose없이도 높은 성능의 NeRF Reconstruction을 제공합니다.
Method
이 논문에서는 학습을 통해 NeRF,Camera-Pose,Mono depth map의 Distortion-parameter를 최적화합니다.
NeRF
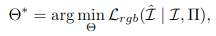
NeRF는 합성된 이미지와 캡쳐된 이미지 사이의 photometric error를 최소화하는 방향으로 학습합니다.
이미지 pixel의 intensity를 구하기 위해서는 input image와 camera Pose가 필요합니다.
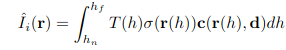
자세한 것은 NeRF 논문을 읽으면 나오지만 위의 Volume rendering 식을 통해 합성된 Scene을 만들어냅니다.
Joint Optimisation of Pose and NeRF
우리는 위 학습 식과는 다르게 camera pose도 최적화를 해야합니다.
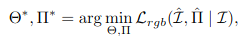
수학적으로 이 논문에서는 camera parameter도 최소화하는 방향으로 학습을 진행합니다.
원래 camera parameter에는 camera intrinsic, Poses, Lens Distortion등이 있지만 이 논문에서는 camera pose만 생각하기로 합니다.
Undistortion of Monocular Depth
DPT라는 monocular depth network를 통해 mono-depth map을 이미지로부터 얻어냅니다.
mono-depth는 multiview에서 일관된 결과를 뽑아내지 않기 때문에 왜곡된 점을 수정해줘야 합니다.
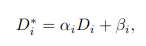
Mono-depth Di에 적절한 parameter를 첨가하여 multiview에서도 일관된 depth map D*를 정의합니다.
D*와 NeRF로 합성된 depth의 차이를 Loss로 정하여 그것을 최소화하면서 저 parameter를 최적화합니다.
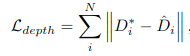
이런 방식을 통해 Monodepth의 왜곡과 NeRF의 shape-radiance ambiguity 문제를 줄일 수 있습니다.
Relative Pose Constraint
앞에서 Pose와 NeRF를 동시에 최적화 하는 논문들과는 다르게 이 논문은 Relative Pose를 사용합니다.
이것을 활용하기 위해 2가지 Loss를 도입하였습니다.
Point Cloud Loss
unditorted depth map에 camera intrinsic을 사용하여 point cloud로 back-project를 진행합니다. 연속적이 frame의 point cloud르 정합하면서 적절한 transformation matrix를 구하여 relative Pose를 구할 수가 있습니다.
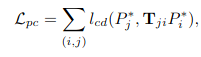
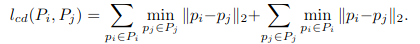
이 loss를 최소화 시키면서 우리는 relative Pose를 최적화 할 수 있습니다.
Surface-based Photometric Loss
Point cloud loss 뿐만 아니라 이것을 image로 projection 시켜 photometric error를 loss로 활용하면 incorrect matching을 많이 줄일 수 있습니다.
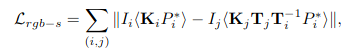
Overall Training Pipe_line
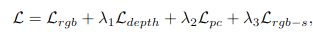
이렇게 정의한 모든 Loss를 weighted sum하여 최종 Loss를 정의합니다.
이 Loss 최소화하는 방향으로 학습하여 NeRF parameter, Camera pose, Distortion Parameter를 구하게됩니다.
3줄 요약
1. Pose를 학습하고 싶은데 지금까지 방법은 여러 단점이 있다.
2. Relative Pose와 Monocular Depth를 활용하여 Pose와 NeRF를 모두 학습한다.
3. Pose 없이도 비교적 정확한 NeRF map을 합성할 수 있다.
