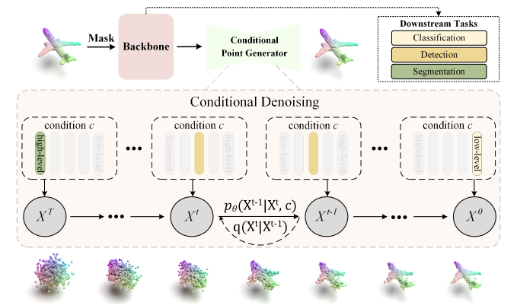
Point Cloud를 생성 모델을 활용하여 Pre-processing을 하는 논문입니다.
지금까지 Point Cloud의 unordered, non-uniform density 특징 때문에 학습이 쉽지 않았습니다.
이것을 point-to-point generation task로 학습하여 이 문제를 해결해보려고 합니다.
이 논문에서는 sampling기법이나 conditional point generator를 도입하는 등 다양한 시도를 통해 학습을 진행합니다.
Introduction
SAM, VisualGhatGPT, BLIP-2같은 많은 연구들이 pre-trained model이 2d 이미지나 자연어 처리 방면에서 좋은 성능을 내고 있는 것으로 보입니다. large-scale dataset에서 Pre-training은 모델에게 많은 사전지식을 부여하고 성능 상승은 물론 generalization 성능까지 증가합니다.
2D 이미지와 자연어처리 분야와 비슷하게, point cloud processing도 성능 향상에 큰 도움을 주는 것이 알려지고 있습니다.
현재 point Cloud Pre-Processing에는 두가지 방법이 주로 사용됩니다.
1. 대조 기반 pre-training: Sample의 유사성을 model이 찾아내도록 학습
2. 생성 기반 pre-training: masked point cloud 또는 2D projection을 생성하도록 학습
이 논문은 diffusion을 기반으로한 생성 기반 pre-training을 사용할 것입니다.
Duffusion은 noise를 일부러 넣어서 학습을 하기 때문에 noise가 많고 unordered한 point cloud학습에 적합한 것으로 판단하였습니다.
이 논문의 주요한 contribution은 다음과 같습니다:
1.PointDif라는 diffusion model기반의 point cloud pre-training을 제안합니다.(point의 noise를 줄일 수 있습니다.)
2.Conditional Point generator를 사용하여 noisy point cloud로부터 point-to-point generation을 수행합니다.
3.Recurrent uniform sampling strategy를 도입하여 noise가 많이 있는 point cloud를 일정하게 재저장하는 것을 도와줍니다.
4.다양한 point cloud backbone에 적용가능하고 높은 성능을 보여줍니다.
Methodology
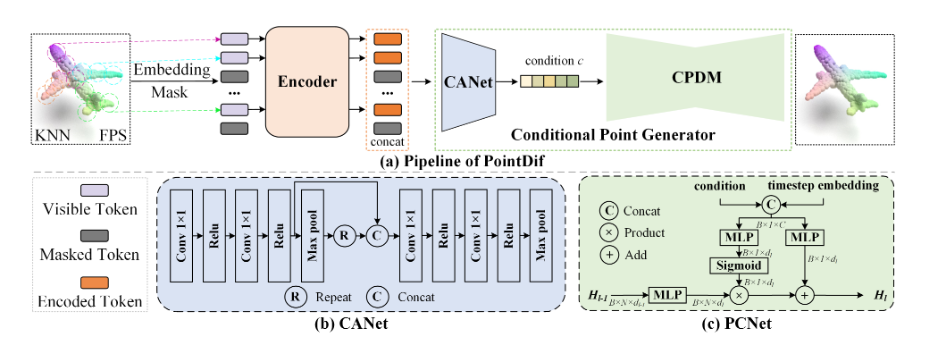
Point cloud set을 쪼개서 patch로 묶고 embedding과 random masking을 적용합니다.
그걸 Transformer encoder에 넣고 visible token을 처리합니다. 그것을 CANet에 넣어 feature를 추출하고 feature를 CPDM에 넣어 point cloud를 generate합니다.
3.1 Preliminary: Conditional Point Diffusion
Diffusion 과정동안 random noise를 Markov chain을 통해 도입합니다.
인접한 time stamp에서 noisy point cloud간의 point-to-point mapping 관계가 있다.
형식적으로는 실제 data distribution p로부터 추출한 noise 없는 n개의 pointpoint cloud X0에 점차적으로 gaussian noise를 time stamp에 따라 더합니다.
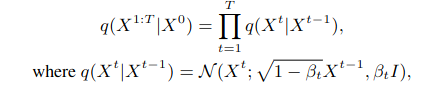
Bt는 hyper parameter로 작은 상수이고 시간에 따라 조금씩 커집니다.
Xt는 Gaussian distribution으로부터 샘플링됩니다. 이 Xt를 X0에 대한 함수로 나타낼 수 있습니다.
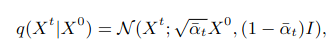
time stamp가 커지면 커질수록 a는 0에 가까워지고 이것은 Gaussian distribution에 가까워 질 것입니다.
역과정은 condition c에 따라 gaussian noise를 제거합니다.
Diffusion 모델은 밑의 식을 optimization합니다.
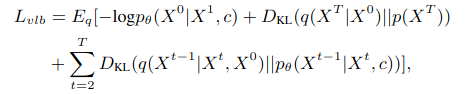
하지만 이 시식은 안정성에 약점이 있기 때문에 이 식의 간단화 버전을 이 논문에서 사용합니다.
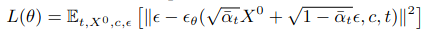
3.2 Point Cloud Processing
이 과정에서 Point Cloud를 Token으로 만듭니다.
Point Patch Embedding
Point-BERT나 Point MAE처럼, 이 논문은 point cloud를 grouping strategy를 사용하여 point patch로 나눕니다. input point X는 Farthest point sampling 알고리즘을 사용하여 샘플링을 진행합니다.
Center point에 knn을 사용하여 Patch를 생성합니다.
patch에 centering process를 적용하여 convergence에 도움을 줍니다.
Patch Masking
Patch의 geometry 정보를 보전하기 위해서, 우리는 전체 포인트를 마스킹하여 마스킹된 patch와 visible patch를 얻습니다. 다양한 ratio에 따라 실험을 진행하여 결과를 도출하였습니다.
3.3 Encoder
Transformer Encoder를 활용하여 latent feature vector를 추출합니다.
이 Encoder에는 3D geometric information을 더 잘 추출하기 위해 visible patch만 사용하여 encoding합니다. 또 positional embedding을 사용합니다.
visible patch를 Postion embedding한 output은 Token과 연결되어 encoder에 들어갑니다.
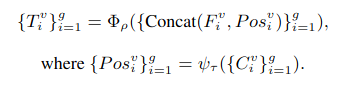
3.4 Conditional Point Generator
Condition Aggregation Network(CANet)
CAN을 통해 feature를 encoding하여 CPDM에 필요한 condition을 계산합니다.
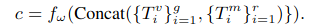
Conditional Point Diffusion Model(CPDM)
original point cloud를 복원하기 위해서 point diffusion model을 활용합니다.
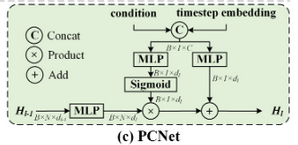
위 식은 point condition network를 도식화한 그림입니다.
이것을 식으로 나타내면,
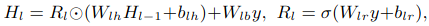
Hl-1은 input이고 Hl은 output입니다. Wl과 bl은 학습하는 parameter입니다.
y는 feature를 나타냅니다.
3.5 Training Objective
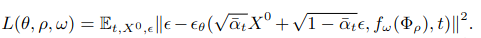
encoder, CANet 그리고 CPDM 을 동시에 최적화를 진행합니다.
Recurrent Uniform Sampling Strategy
time stamp에 따라 sampling을 진행합니다.
샘플들을 사용하여 학습하면 downstream task에 대해 다양한 성능이 나타납니다.
early interval로 샘플링하면 clssification task에 대해 성능이 높고
later interval로 샘플링하면 segmentation task에 대해 성능이 높습니다.
이것을 활용하여 recurrent uniform sampling strategy를 만듭니다.
[1,T] 범위를 h개의 interval로 쪼갭니다.이 h interval로부터 무작위로 샘플링하고 loss h time을 계산합니다. 이것을 적용하여 final loss를 도출합니다.
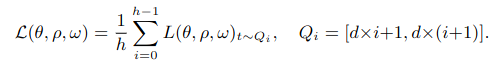
Conclusion
이 논문에서는 diffusion model에 기반한 point cloud pre-training을 위한 새로운 framework를 제안합니다. conditional point generator로 network가 point density distribution을 학습하는 것을 도와줍니다. 또 recurrent uniform sampling도 활용하여 interval 조절을 통해 성능을 높였습니다.
이러한 frame work는 point cloud processing에 대한 발전 방향을 제공합니다.
