이 논문은 2024년 CVPR에서 나온 semantic slam논문이고요
상하이 자오퉁 대학교의 Siting Zhu씨가 1저자네요.
Introduction
NeRF-based SLAM의 경우 두가지 어려운 점이 있다고 합니다.
- Appearance, Geometry, Semantic 정보들이 모두 연관되어 있다는 것
모두 연관되어 있기 때문에 그 정보들을 독립적으로 처리하게 되면 상호 연관관계를 잃어버려
이미지 또는 장면의 불완전한 이해를 야기할 수 있습니다.
- 정보들을 얼마나 고려해야할지
장면의 appearance 같은 경우 viewing direction이나 조명에 따라 변하기가 쉽다.
그래서 변하지 않는 semantic 정보로 최적화하게 되면 appearance로 최적화한 것보다 장면을
덜 디테일하게 나타내기 때문에 이 균형을 잘 맞춰야 합니다.
첫번째 문제를 해결하기 위해 이 논문에서는 appearance, semantic, geometry의 각각의 특성을 사용하여 mutual collaboration과 강화된 접근법을 cross attention 기반으로 디자인합니다.
두번째 문제를 해결하기 위해서 one-way correlation 접근법을 제안합니다.
decoder desing과 rendering process를 향상 시켰기 때문에 가치있는 정보가 다른 정보들을 강화시키면서 기존 표현에는 영향을 끼치지 않을 수 있게 합니다.
전반적으로 이 논문의 contribution은 다음과 같습니다.
-
SNI-SLAM을 통해 dense RGB-D semantic SLAM이 정확한 3d semantic segmentation을 실시간으로 할 수 있게 했습니다.
-
진화된 feature collaboration approach를 통해 cross attention 기반 feature 통합을 이루어 냈습니다.
-
Replica, ScanNet 같은 어려운 dataset에서도 잘 구동되는 알고리즘을 제안
Method
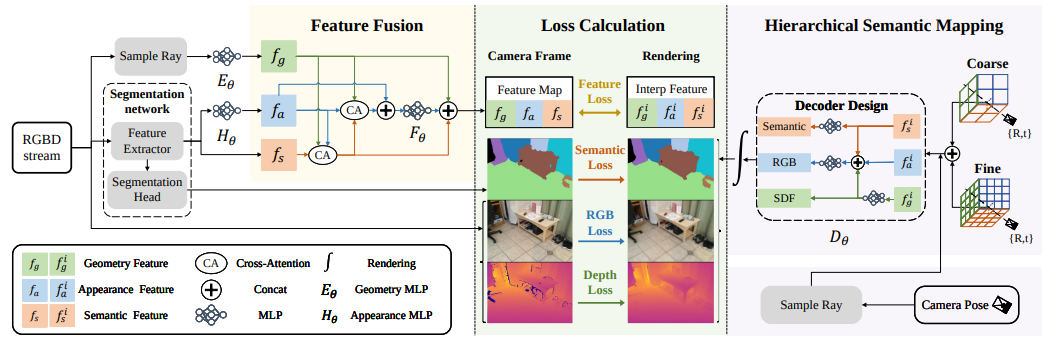
Overview는 다음과 같습니다.
RGB-D stream이 들어오게 되면 RGB 이미지를 semantic feature extractor(DINOv2)에 넣어 semantic feature를 뽑습니다. 이 feature를 MLP 에 넣어 appearance feature를 얻습니다. Geometry feature는 ray sampling을 통해 얻어지고 MLP 를 통해 처리됩니다. 이 feature map은 supervision signal로 사용될 것입니다. mapping을 위해선 hierarchical semantic representation을 하고 camera tracking을 위해선 camera pose를 최적화하는 loss function을 사용합니다.
tracking과 mapping의 경우 ESLAM:Efficient dense slam system based on hybrid representation of signed distance fields를 참고했다고 합니다.
Cross-Attention based Feature Fusion
이 알고리즘이 사용하는 세가지 feature appearance, geometry, semantic은 서로 연관된 정보입니다.
appearance feature 같은 경우 조명 조건 또는 viewing direction에 따라 달라질 수 있는데 semantic 정보는 그것들에 영향을 받지 않습니다. semantic feature의 안정성은 물체의 정보를 인지할 때 중요한 도구가 될 수 있습니다. 그렇다고 appearance feature를 고려하는게 단점만 있는 것이 아니라 색깔, 밝기, 질감등을 관측한다면 물체의 의미를 쉽게 생각할 수 있게 됩니다. geometry feature의 경우 물체의 모양이나 위치를 알게 되면 semantic 정보에 영향을 끼칠 수 있기 때문에 모든 feature는 연관되어 있다고 생각하시면 됩니다.
이러한 correlation을 고려하기 위해 Cross-attention을 사용하여 feature들을 결합하게 됩니다.
: semantic feature
: geometry feature
: appearance feature
fused semantic feature 는 다음과 같이 나타납니다.
와 가 연관이 있을 수록 를 더욱 고려하도록 만든 feature라서 각 feature에 영향을 받도록 fusion된 것을 볼 수 있습니다.
fused appearance feature 는 다음과 같이 나타낼 수 있습니다.
fused semantic feature도 사용하기 때문에 더 확실히 appearance를 나타내는 feature를 만든 것으로 보입니다.
이 feature들을 활용하여 feature map을 형성합니다.
FM = {}
Hierarchical Semantic Mapping
현존하는 NeRF 기반 semantic modeling 기법은 single-level neural implicit 표현을 채용합니다. 그러나 이러한 표현방식은 복잡한 scene을 표현할 때 한계에 부딪힙니다. 그래서 이 논문에서는 Hierarchical approach방식을 활용해서 더 효율적으로 semantic representation을 하려고 합니다. hierarchical approach방식에 대해 설명하자면 처음에는 전체 layout에 대해 main object들을 인지합니다. 그리고 나서 더 자세하게 보는 방식을 말하는 것입니다.
- Coarse-to-fine Semantic Representation

그림과 같이 먼저 흐릿하게 물체들을 인지하고 fine-level에서 더 자세한 표현을 하게합니다.
- Decoder Design
두 일반적인 decoder model이 있습니다.
1. 다른 feature에 대해 각각의 network를 사용
- geometric, color information을 single feature로부터 얻는 네트워크를 사용한다.
이러한 방식은 decoder가 feature간의 interaction을 잘 고려하지 못한다고 말합니다.
geometry feature와 appearance와 semantic feature를 쌓아서 network에 넣어 color decoding information을 얻을 수 있도록 합니다.
이러한 design은 one-way correlation은 feature들이 한방향으로 적용될 수 있도록하여 서로 추론에 도움을 줄 수 있는 decoder를 만들었습니다.
- Rendering
Volume density를 계산할 때 SDF값을 사용할 수 있도록 하는 styleSDF방식을 차용하여 rendering을 합니다.
의 경우 학습가능한 parameter이고 이를 활용하여 rendering을 하게 됩니다.

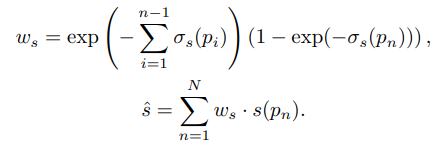
Loss Functions

sdf loss이고 surface와 근처에 있을 경우
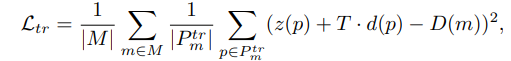
이러한 loss를 사용합니다.
- Semantic Loss
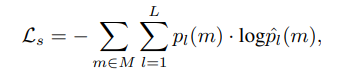
- Feature Loss

- Color and Depth Loss
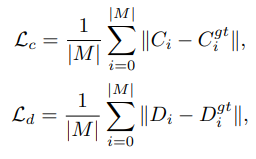
- 최종 loss
이러한 loss를 통해 학습을 합니다.
