✅ 오늘의 업무: 벡터 DB에 문서 저장하기
오늘 할 일은 벡터 DB에 데이터를 임베딩해서 저장하고, Langchain 구조로 RAG를 구현하는 것이었다. 나는 벡터 DB에 데이터를 저장하는 일을, 같이 일한 다른 팀원은 langchain을 설계하고 프롬프트를 짜는 일을 했다.
Qdrant를 로컬에서 돌리면 내 컴퓨터에서 벡터 DB를 구축해도 다른 팀원과 공유할 수 없기에, 내가 DB를 구축하는 코드를 써서 다른 팀원에게 전달해 RAG를 구현했다.
- Qdrant 벡터 DB에 데이터 임베딩해서 저장하기
- 메타데이터도 임베딩 벡터와 함께 저장
RAG 구현 결과
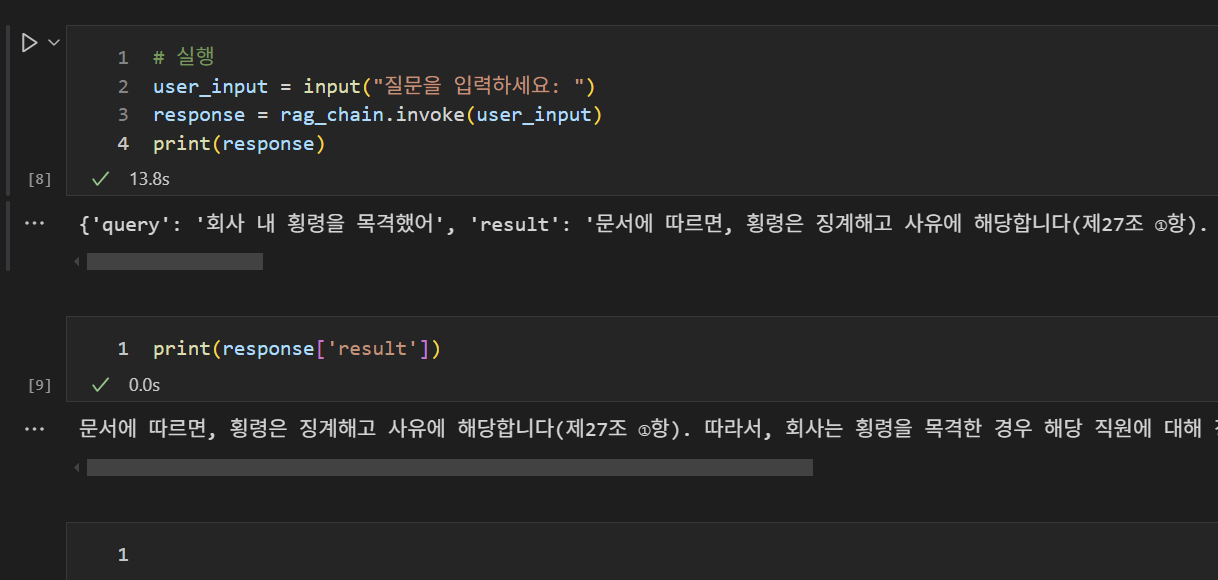
질문을 입력하면 문서를 찾아 LLM에 전달하고, 답변을 생성해준다~!
🔎 벡터 DB 구축 과정
Qdrant 환경 설정: Docker, WSL
먼저 Qdrant DB를 사용하기 위해 Docker와 WSL을 준비해야 했다. Docker 사용자 이름 입력창에 자꾸 한글이 깨진듯한 오류가 떠서 강사님께 여쭤봤는데, 강사님이 오류 뜨면 재설치하면 되니까요~ 하시면서 깨진 문자 옆에 그대로 사용자 이름 적었더니 됐다 😮
코드 리뷰: 벡터 DB 구축
여러 개의 DOCX 워드 문서를 읽어, 조문(조항) 단위로 텍스트를 분할하고, 각 조문을 다시 여러 개의 작은 청크(chunk)로 나눈 뒤, OpenAI 임베딩 모델 "text-embedding-3-large"를 사용해 텍스트 임베딩을 생성하고, Qdrant 벡터 데이터베이스에 임베딩과 함께 메타데이터(본문, 카테고리)를 저장하는 전체 파이프라인이다.
아래는 코드 각 부분별 상세 설명이다.
1. load_docx_text(filepath)
def load_docx_text(filepath):
doc = Document(filepath)
return '\n'.join([p.text.strip() for p in doc.paragraphs if p.text.strip()])- 기능: 주어진
filepath의 DOCX 파일을 열어서 모든 문단(paragraph)에서 텍스트를 추출한다. - 빈 줄(내용 없는 단락)은 제외하고, 각 문단 텍스트에 대해 앞뒤 공백을 제거한 후 한 줄씩 합쳐 하나의 큰 문자열로 반환한다.
- 결과: 텍스트 전체가 하나의 큰 스트링으로 구성됨.
2. split_by_articles(text)
def split_by_articles(text):
pattern = r'(제\d+조.*?)(?=제\d+조|$)'
return re.findall(pattern, text, re.DOTALL)- 기능: 전체 본문 텍스트에서 “제1조”, “제2조” 등 ‘제숫자조’ 로 시작하는 조문 단위로 텍스트를 분리해서 리스트로 반환한다.
re.DOTALL옵션을 통해 줄바꿈 문자를 포함해 전체를 매칭하도록 한다.- 패턴 설명:
(제\d+조.*?): ‘제숫자조’부터 가능한 가장 적게(최소 매칭) 텍스트 추출(?=제\d+조|$): 다음 조문 혹은 텍스트 끝까지
결과적으로 조문 리스트 형태가 된다.
3. get_openai_embedding(text: str)
def get_openai_embedding(text: str):
response = openai.embeddings.create(
model="text-embedding-3-large",
input=text
)
return response.data[0].embedding- OpenAI API를 사용해
text에 대한 임베딩 벡터를 생성한다. - 사용 모델은
"text-embedding-3-large"로 3072차원의 고차원 벡터를 반환합니다. - API 호출 결과(JSON)에서 임베딩 벡터만 추출해 반환.
- 참고: OpenAI API 키가 환경변수나 코드에서 설정되어 있어야 정상 작동한다.
4. 문서 - 카테고리 매핑 (category_map)
category_map = {
"복리후생 규정.docx": "복지",
...
}- 각 DOCX 파일명에 대응하는 카테고리(주제 분류)를 미리 지정해둔 딕셔너리이다.
- 문서별로 적절한 카테고리 값을 메타데이터 저장 시 함께 부여하기 위해 사용한다.
- 만약 맵에 없으면
"기타"로 기본 처리하게 되어 있다.
5. Qdrant 클라이언트 초기화 및 컬렉션 생성
folder = r"C:\SKN13SM\SKN13_FINAL_6Team\생성 문서"
collection_name = "regulations"
client = QdrantClient(host="localhost", port=6333)
if client.collection_exists(collection_name):
client.delete_collection(collection_name)
client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=3072, distance=Distance.COSINE),
)- 변수
folder: DOCX 문서들이 저장된 폴더 경로collection_name: Qdrant 내에 새로 생성할 컬렉션 이름
- Qdrant 클라이언트(로컬호스트 6333 포트) 연결
- 컬렉션이 이미 있으면 삭제 후 재생성 (
delete_collection→create_collection) - 임베딩 벡터 차원(3072), 거리 메트릭(COSINE 유사도) 설정
6. RecursiveCharacterTextSplitter 초기화
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100
)- 자주 쓰는 텍스트 분할 도구인 LangChain 내
RecursiveCharacterTextSplitter클래스. - 각 조문 내 긴 텍스트를 최대 1000자 크기(문자 단위)로 분할하면서, 각 청크별로 100자씩 겹쳐서 분할하여 의미 단절 최소화.
- 토큰 단위가 아닌 문자 수 기준임을 유의
7. 전체 문서 대상 임베딩용 포인트 리스트 생성
points = []
for file in os.listdir(folder):
if not file.endswith(".docx"):
continue
path = os.path.join(folder, file)
category = category_map.get(file, "기타")
text = load_docx_text(path)
articles = split_by_articles(text)
for article in articles:
chunks = text_splitter.split_text(article) # 조문별 텍스트를 다시 청크로 분할
for chunk in chunks:
if not chunk.strip():
continue
embedding = get_openai_embedding(chunk) # OpenAI 임베딩 API 호출
point = PointStruct(
id=str(uuid.uuid4()), # 임의 UUID로 고유 ID 생성
vector=embedding, # 3072차원 임베딩 벡터
payload={
"text": chunk, # 원문 청크 텍스트
"category": category # 해당 문서 카테고리 메타데이터
}
)
points.append(point)- 폴더 내 모든
.docx파일을 순회 - 각 문서로부터 텍스트 추출 → 조문 단위 분할
- 각 조문은 1000자 크기 청크들로 다시 분할
- 각 청크에 대하여 OpenAI 임베딩 생성
- 생성된 벡터와 청크 텍스트, 카테고리 메타데이터를 담은 Qdrant 포인트(
PointStruct) 생성 points리스트에 모두 쌓음
8. Qdrant에 임베딩 및 메타데이터 업로드
client.upsert(collection_name=collection_name, points=points)
print("✅ Qdrant 업로드 완료!")- 모든 생성한 벡터 포인트를 Qdrant 컬렉션에 일괄 업로드
- 업로드 완료 시 메시지 출력
요약
| 단계 | 설명 |
|---|---|
| 1. DOCX 텍스트 읽기 | 각 문서 내 모든 텍스트 불러오기 |
| 2. 조문별 분할 | “제숫자조” 패턴을 이용해 조항 단위로 분리 |
| 3. 긴 조문 청크별 분할 | 각 조문을 1000자 미만 청크 단위로 나눔 |
| 4. OpenAI 임베딩 생성 | 각 청크 텍스트를 "text-embedding-3-large" 모델로 벡터화 |
| 5. Qdrant 포인트 생성 | UUID, 벡터, 원문 텍스트, 카테고리 포함 |
| 6. Qdrant에 벡터 및 메타데이터 저장 | 모두 모아서 한꺼번에 업로드 |
추가 참고사항
- 임베딩 생성 API는 호출량이 많으면 비용/속도에 영향 있으니, 대용량 처리 시 배치(batch) 처리나 캐싱 고려.
- 임베딩 벡터의 차원이 code 내
VectorParams와 맞아야 하며, 모델 변경 시 차원도 맞춰야 한다. category외에 다른 메타데이터를 더 추가하려면payload에 추가 키-값 쌍을 포함시키면 된다.- Qdrant 검색 시 메타데이터(예:
category)로 필터링하거나 상세 표시가 가능하다.
Qdrant Docker 서버 연결
[WinError 10061] 대상 컴퓨터에서 연결을 거부했으므로 연결하지 못했습니다는 Qdrant 서버(즉, Docker 컨테이너)가 실행 중이 아니어서 발생하는 대표적인 오류이다.
→ Docker의 Qdrant 서버를 반드시 실행시켜야 합니다!
1. 여러 DOCX 파일 한 번에 처리하기 코드 예시
여러 워드 파일을 한 번에 처리하려면 os.listdir 또는 glob 라이브러리를 활용해 폴더 내 모든 .docx 파일을 순회하면 됩니다.
아래는 이 기능이 반영된 전체 코드 예시입니다:
import os
import re
from docx import Document
from sentence_transformers import SentenceTransformer
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance, PointStruct
import numpy as np
import uuid
# 📄 DOCX 파일에서 텍스트 추출
def load_docx_text(filepath):
doc = Document(filepath)
full_text = []
for para in doc.paragraphs:
if para.text.strip(): # 빈 줄 제거
full_text.append(para.text.strip())
return '\n'.join(full_text)
# ✂️ "제1조", "제2조" 등의 조문 단위로 분할
def split_by_articles(text):
pattern = r'(제\d+조.*?)(?=제\d+조|$)'
articles = re.findall(pattern, text, re.DOTALL)
return articles
if __name__ == "__main__":
folder = "C:/SKN13SM/clean_repo_SM/13_Langchain/documents" # 워드 파일 폴더 경로
docx_files = [os.path.join(folder, file) for file in os.listdir(folder) if file.endswith(".docx")]
all_articles = []
file_infos = []
for filepath in docx_files:
text = load_docx_text(filepath)
articles = split_by_articles(text)
all_articles.extend(articles)
file_infos.extend([{"filename": os.path.basename(filepath)}] * len(articles))
print(f"✅ 전체 조문 개수: {len(all_articles)}")
# 임베딩
model = SentenceTransformer("jhgan/ko-sbert-nli")
embeddings = model.encode(all_articles, convert_to_numpy=True, show_progress_bar=True)
# Qdrant 연결 및 컬렉션 생성
client = QdrantClient(host="localhost", port=6333)
collection_name = "regulations"
if client.collection_exists(collection_name):
client.delete_collection(collection_name)
client.recreate_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=embeddings.shape[1], distance=Distance.COSINE),
)
print("✅ Qdrant 컬렉션 생성 완료!")
# Qdrant에 업로드 (파일명 정보까지)
points = [
PointStruct(
id=str(uuid.uuid4()),
vector=embedding.tolist(),
payload={"text": article, **info} # 파일명 등 정보 추가
)
for article, embedding, info in zip(all_articles, embeddings, file_infos)
]
client.upsert(collection_name=collection_name, points=points)
print("✅ Qdrant에 업로드 완료!")2. "연결을 거부했습니다" 오류 원인과 Qdrant Docker 서버 실행법
오류 원인:
[WinError 10061] 대상 컴퓨터에서 연결을 거부했으므로 연결하지 못했습니다는 Qdrant 서버(즉, Docker 컨테이너)가 실행 중이 아니어서 발생하는 대표적인 오류입니다.
→ Docker의 Qdrant 서버를 반드시 실행시켜야 합니다!
Qdrant Docker 서버 실행법
- Docker Desktop을 반드시 실행시킨다.
- 터미널(또는 명령 프롬프트/WSL)에서 아래 명령을 순서대로 입력한다.
docker pull qdrant/qdrant(이미 pull 했다면 생략 가능)
docker run -p 6333:6333 -p 6334:6334 -v Qdrant_데이터_저장_폴더의_경로:/qdrant/storage qdrant/qdrant-
위 명령은 6333(REST/web) 및 6334(gRPC) 포트를 연다.
-
윈도우 CMD/PowerShell에서 경로 표기만 주의:
-
/qdrant/storage← 컨테이너 내부의 데이터 저장 경로 (이건 바꾸지 마세요) -
:(콜론)으로 구분
- 정상적으로 실행된 경우, 브라우저에서
http://localhost:6333접속 시 Qdrant 환영 메시지가 떠야 한다.
요약
- Qdrant 서버(Docker) 실행 → Python 코드 실행 순서로 하기
- Docker 컨테이너가 종료되어 있거나 포트가 막혀있으면 연결 오류가 발생한다.
- Qdrant는 기본적으로 6333 포트로 HTTP API를 제공하니, client 인스턴스도 그에 맞게 설정해야 한다.
