[최종 프로젝트] 2주차: 메타데이터 필터링, 코드 수정, 진행 상황 확인 회의, 멘토링(불참) (250731)
SK 네트웍스 AI 부트캠프 13기 - 최종 프로젝트
목록 보기
8/32
☀️ 오전: 메타데이터 필터링, 코드 수정
1. embedding, rag chain 코드 수정
(1) 문서-카테고리 매핑
문서-카테고리 매핑이 데이터(임베딩 문서)와 사용자 질의(rag chain 문서)가 달랐다. 따라서 임베딩 문서 매핑을 rag chain 문서 매핑에 맞게 수정했다.
category_map = {
"복리후생 규정.docx": "복리후생 규정",
"보안 규정.docx": "보안 규정",
"복무 규정.docx": "복무 규정",
"안전보건관리 규정.docx": "안전보건관리 규정",
"여비 규정.docx": "여비 규정",
"인사 규정.docx": "인사 규정",
"인사팀 업무 가이드.docx": "인사팀 업무 가이드",
"전산팀 업무 가이드.docx": "전산팀 업무 가이드",
"회계 규정.docx": "회계 규정",
"회계팀 업무 가이드.docx": "회계팀 업무 가이드"
}(2) 문서 분할 방식 개선
- 기존: 조항 단위로 분리하기 위해
제숫자조기준으로만 분리 - 개선:
제숫자조기준으로 분리 후chunk_size와chunk_overlap을 각각 1000과 100으로 지정했다. 또한chunk_index는 없앴다.
2. 메타데이터 구상
(1) 내가 구상한 메타데이터
# Qdrant에 저장할 하나의 포인트 생성
point = PointStruct(
id=str(uuid.uuid4()), # 고유 ID 생성
vector=embedding, # 임베딩 벡터
payload={ # 메타데이터
"text": chunk, # 청크별 텍스트
"category": category, # 문서 카테고리
"article_title": article_title.strip(), # 전체 조문 제목 문자열
"article_number": article_number, # 조문 번호 분리 저장
"article_subject": article_subject, # 조문 제목 분리 저장
"article_content": article_content.strip(), # 조문 전체 본문
"chunk_index": i, # 조문 내 청크 순서
}
)payload 딕셔너리 안에 있는 게 메타데이터이다.
위와 같이 메타데이터를 설정하면 다음과 같은 결과가 나온다.
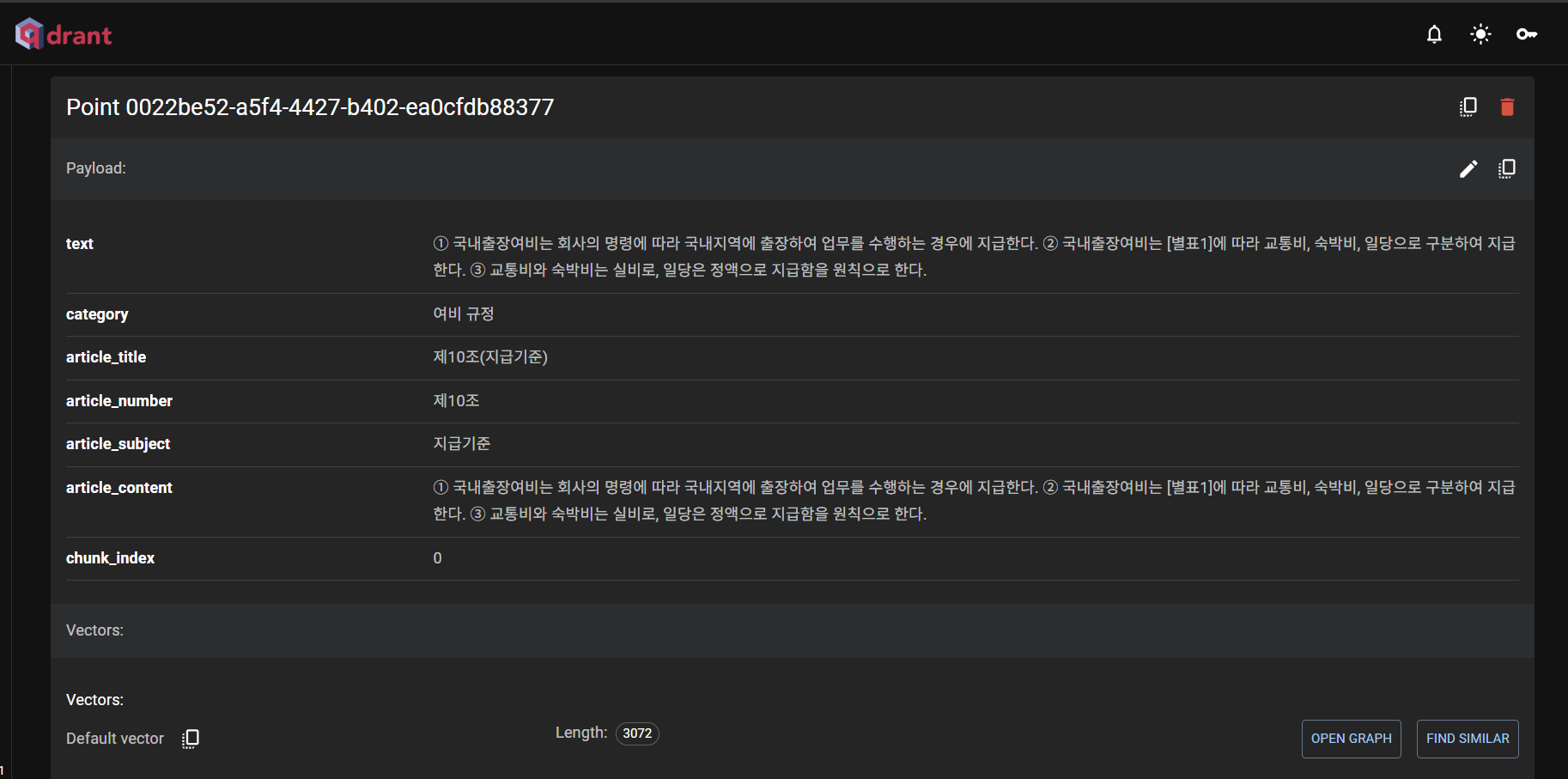
(2) 문서 분할 기준 수정
기존
"제3조(기존 규정의 폐지)"라는 조항이 있으면 "제3조"와 "기존 규정의 폐지"로 분리되기를 기대했다.
한계
문서에 "제35조에 따라"라는 문구가 있었는데, 이 문구에서 "제35조", 즉 제숫자조가 인식되어서 문서 분할이 되었다.
개선
조항 시작의 경우 "제3조(기존 규정의 폐지)"와 같이 제숫자조 뒤에 괄호가 들어오므로, 제숫자조 뒤에 괄호가 있는 경우에만 조항으로 인식하고 문서를 분할한다.
⭐ 확인 사항
- 문서에
제 숫자 조와 같이 숫자 양옆에 공백이 있는 경우가 있었다.제숫자조와 같이 공백이 있는 경우만 인식하지 않게 수정 필요! 별표라는 이름의 첨부 파일이 있다는 걸 몰랐다. 이것도 적절히 분할 필요!
3. 문제: 메타데이터 필터링이 안 됨
SelfQueryRetriever에서 질의를 받으면 LLM을 통해 질의 카테고리 분류를 하고, 이를 이용해 메타데이터 필터링을 해야 하는데, LangSmith에서 확인해보니 메타데이터가 필터링이 안 되어 있는 것을 확인했다.
"filter": "NO_FILTER"수정 필요!
🦥 오후: 진행 사항 확인 회의
리서치: 이 모델을 왜 쓰는가?
Qdrant 선정 이유? (FAISS -> Qdrant)
- Docker 사용 편리
- 메타데이터 필터링 용dl. RAG 기반 검색을 용이하게 하려고
Docker
- 보편적이고, Qdrant와 함께 쓰기 좋음.
기능 구현: 어려운데? 성능이 잘 안 나오는데?
- 사용자 질의 응답 기록 저장 - 불가능할까?
- 회의록 기능 뺘고, 업무 가이드랑 영수증 처리에 집중할까?
모델 선정
OCR: Qwen 중간 모델 써보고 성능 비교 필요
- 원래 Qwen 2B, 에이닷 7B 모델 중 Qwen 2B 모델이 속도가 빨라서 택함.
- 속도가 좀 느리더라도 정확도가 중요하다는 피드백을 받고, 가벼운 Qwen 2B 모델 말고, 중간 모델 써보고 성능 비교해보기로.
텍스트 요약: kobert
- 성능 지표는 모델별 ROUGE 평균 점수를 사용함.
FAQ: 구조를 어떻게 설계하지?
- 뚜렷한 방안을 생각하기 어려웠음 -> 저녁 멘토링 때 멘토님께 여쭤보기로.
🌜 저녁: 멘토링
나는 일정이 있어 멘토링에 불참해 아쉬웠다. 정리된 회의록을 보니 정말 알찬 멘토링이었구나 싶어서 다음에는 나도 꼭 참여해야겠다고 한 번 더 다짐했다!
멘토링 내용 정리
정리된 회의록 내용을 한 번 더 숙지할 겸, 멘토링 내용을 정리해보겠다.
1. 전반적인 방향 및 기획 관련
프로젝트 목표 구체화가 필요하며, 이에 맞게 기획서, 요구사항 정의서, 화면 설계서를 수정하도록 한다.
2. 기능 구현 및 API 설계
- STT 모델은 속도 확보가 필요하다.
- 기능 범위는 가능한 한 생각한 기능을 최대한 확장하되, 우선순위와 집중 영역을 명확히 하도록 한다.
- API 도출이 선행되어야 한다. API 여부에 따라 프로젝트 구조 계획이 달라지기 때문이다.
3. OCR 및 영수증 처리
- 다른 기능도 고려: 텍스트가 필요한 이미지를 입력하면 텍스트를 추출해주는 컨셉은 어떤지?
- 텍스트 추출 시 결과를 어떻게 저장할지 형태를 고려해야 한다.
4. 관리자 페이지 및 기능
- 구현 방식: 게시판 형태로 간단하게 구성
- 포함 기능 예시: 대시보드, 피드백 관리 등
5. 검색 기능 고도화 (RAG, FAQ 포함)
검색 설계
- 의도 파악 기반 검색 설계가 필요하다.
- 필터링
- LLM을 통한 질의 의도 분석
- 질의를 LLM에 넣어 카테고리를 도출한다.
- 검색
- 해당 카테고리 문서에서 유사도 기반으로 문서를 검색한다.
- LLM 답변 생성
- 질의를 검색된 문서와 함께 LLM에 넣어 답변을 추출한다.
- 필터링
메타데이터 구성: 필터링용 + 출처 제공용
- 사용자 질의에서 필터링 및 출처 제공용 메타데이터를 추출할 방안이 필요하다.
FAQ 및 대화 이력
- 자주 묻는 질문에 대한 답변은 LLM을 거치지 않고도 응답 가능하게 구현 고려
- 대화 이력은 벡터 DB 저장 권장 -> 유사도 기반 FAQ 대응 가능
- 캐시 DB 별도 운영 권장 (비정형 데이터용 인덱스 구현)
6. STT 입력 최적화
- 음성 데이터는 모델이 처리 가능한 토큰 단위로 적절하게 잘라서 입력해야 속도 향상이 가능하다.
