
Redis 에서 지원하는 데이터 타입은 다음과 같다.
1) Strings
2) Lists
3) Sets
4) Hashes
5) Sorted Sets
6) Streams
7) Geospatial
8) Bitmaps
9) HyperLogLog
10) BloomFilter
Strings
- Redis 의 가장 기본적인 데이터 타입이다.
- 문자열이나 숫자, serialized object(JSON string) 등 저장
- 명령어
SET inflearn redis- inflearn 이라는 key 로 redis 라는 string 타입의 value 를 저장하는 명령어이다.
MSET price 100 language ko- MSET 은 Multi Set의 약자로, 다수의 key-value 를 한 번에 저장하는 명령어 이다.
MGET inflearn price language- MGET 은 다수의 key의 값을 한 번에 반환하는 명령어이다.
- 참고)
- ① Redis 는 별도의 숫자를 위한 타입을 제공하지 않는다. string 으로 숫자를 저장한다. 다만 숫자 형태의 string 을 저장할 경우, 연산(+, -)이 가능하다.
- INCR : 숫자형 strings 값을 1 증가한다.
- ex)
INCR price
- ex)
- INCRBY : 숫자형 strings 값에 특정 값을 더할 때 사용한다.
- ex)
INCR price 10
- ex)
- INCR : 숫자형 strings 값을 1 증가한다.
- ② Redis 에는 다음과 같이 JSON string 을 직접 저장할 수도 있다.
- ex)
SET redis '{"price": 100, "language": "ko"}' - JSON Object 형태의 key-value 데이터를 string 으로 저장한 뒤에, 사용할 때 해당 데이터를 직접 JSON 으로 다시 바꿔서 사용해야 한다.
- ex)
- ③ Redis 에서는 key 를 만들 때, 콜론(:)으로 의미 단위를 구분해 줄 수 있다.
- ex)
SET inflearn:study redis
- ex)
- ① Redis 는 별도의 숫자를 위한 타입을 제공하지 않는다. string 으로 숫자를 저장한다. 다만 숫자 형태의 string 을 저장할 경우, 연산(+, -)이 가능하다.
- 활용 방안 예시)
- OTP(One-Time Password)
- 인증을 위해 사용되는 임시 비밀번호(e.g. 6자리 랜덤 숫자)
- Distributed Lock
- 분산 환경의 다수의 프로세스에서 동일한 자원에 접근할 때, 동시성 문제 해결
- Fixed Window Rate Limiter (비율 계산기)
- 시스템의 안정성/보안을 위해 요청의 수를 제한하는 기술이다.
- OTP(One-Time Password)
Lists
- String 을 Linked List로 저장하는 데이터 타입이다.
- push / pop에 최적화 O(1)
- 명령어를 통해 Queue(FIFO) / Stack(FILO) 을 쉽게 구현할 수 있다.
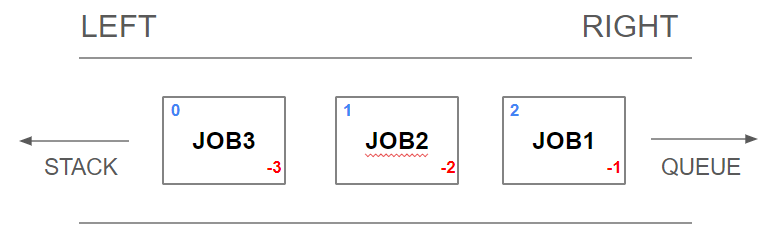
- FIFO 방식의 queue 구현
LPUSH queue job1 job2 job3- 왼쪽부터 차례대로 job1 job2 job3이 저장된다.
RPOP queue- 오른쪽에서 꺼내온다.
- FILO 방식의 stack 구현
LPUSH stack job1 job2 job3- 왼쪽부터 차례대로 job1 job2 job3이 저장된다.
LPOP stack- 왼쪽에서 꺼내온다.
- 결국 LPUSH 를 이용해서 아이템을 추가해주고, 아이템을 어떤 방식으로 꺼내올 것이냐에 따라서
queue와stack을 구현할 수 있기 때문에, 어떻게 아이템을 빼낼것인지에 대한 부분만 고민하면 된다.
- FIFO 방식의 queue 구현
- 참고)
LRANGE명령어를 이용하면 리스트에서 다수의 아이템을 조회할 수 있다. (이때는 인덱스를 이용해서 조회한다.)LPUSH queue job1 job2 job3LRANGE queue -2 -1- 리스트의 인덱스는 왼쪽부터 카운팅 헀을 때는 0부터 시작하여 점차 증가하고, 오른쪽부터 카운팅 했을 때는 -1부터 점차 감소한다.
- 따라서 만약
LRANGE queue -2 -1이라고 한다면, 뒤에서 두번 째 아이템부터 뒤에서 첫 번째 아이템까지. 즉 가장 먼저 추가된 2개의 아이템을 조회하게 된다.- 물론
LRANGE queue 1 2과 같이 양수로 써서 조회해도 되고, 음수로 써서 조회해도 된다. - 지금과 같이
queue용도로 사용한다면 음수 기준으로 작성하는게 더 가독성이 좋다.
- 물론
- 만약 리스트에서 특정 부분만 남기고 싶은 경우
LTRIM명령어를 사용할 수 있다.- ex)
LTRIM queue 0 0 - 0번 인덱스에서 0번 인덱스 까지. 즉 가장 마지막에 추가된 아이템만 남기고 나머지는 모두 삭제하겠다는 의미이다.
- ex)
- 활용 방안 예시)
- SNS Activity Feed (소셜 네트워크 활동 피드)
- Activity Feed(활동 피드)란, 사용자 또는 시스템과 관련된 활동이나 업데이트를 시간순으로 정렬하여 보여주는 기능을 뜻한다. ( 어떤 유저가 나의 게시물을 좋아했는지, 어떤 유저가 새로운 게시물을 올렸는지 등 )
- SNS Activity Feed (소셜 네트워크 활동 피드)
Sets
- 중복 없이 Unique 한 string 을 저장하는 정렬되지 않은 집합 ( 중복 허용 X, 순서 보장 X )
- 명령어)
SADD: Set에 아이템을 추가한다.SADD user:1:fruits apple banana orange orange- 참고)
orange는 중복이므로 1번만 저장된다.
SMEMBERS: Set에 모든 멤버를 출력한다.SMEMBERS user:1:fruits
SCARD: Set의 Cardinality 를 출력한다.SCARD user:1:fruits- 참고) Cardinality 는 고유한 아이템의 갯수를 말한다.
SISMEMBER: Set에 특정 아이템이 포함되어 있는지를 확인할 수 있다.SISMEMBER user:1:fruits banana
- 참고) 집합간 연산: Redis Set 에는 집합에 대한 연산이 구현되어 있다.
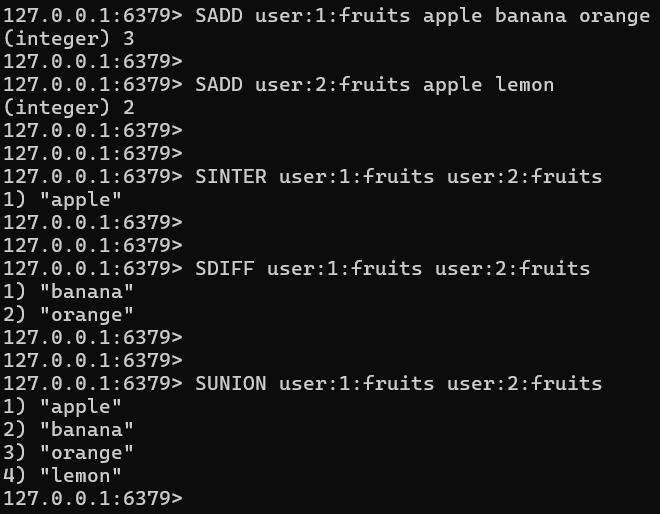
- intersection: 교집합을 구한다.
SINTER user:1:fruits user:2:fruits- 두 집합의 공통 멤버를 출력한다.
- union: 합집합을 구한다.
SUNION user:1:fruits user:2:fruits- user1 과 user2 에 있는 멤버를 출력한다. (중복은 제거된다. )
- difference: 차집합을 구한다.
SDIFF user:1:fruits user:2:fruits- user1 에는 있지만 user2 에는 없는 멤버를 조회한다.
- 참고) user2 를 기준으로 하려면
SDIFF user:2:fruits user:1:fruits과 같이 작성해주면 된다.
- intersection: 교집합을 구한다.
- 활용 방안 예시)
- Shopping Cart(장바구니)
- 만약 유저가 모바일과 데스크톱을 이용해서 수시로 장바구니에 아이템을 추가하고 삭제한다고 해보자. 이때 Redis Set 을 이용하면, 중복 상품에 대한 처리를 쉽게할 수 있고, 임시 데이터를 효율적으로 관리할 수 있다.
- Shopping Cart(장바구니)
Hashes
- field-value 구조를 갖는 데이터 타입
- 프로그래밍 언어에서 Dictionary 나 Map 과 유사한 개념이다.
- 참고)
key field value [field value ...]
- 다양한 속성을 갖는 객체의 데이터를 저장할 때 유용하다.
- 명령어)

HSET: 해시를 생성한다.- ex)
HSET lecture name inflearn-redis price 100 language ko - 참고) 위와 같이 다수의 field 와 value 를 한 번에 저장할 수 있다.
- ex)
HGET: 하나의 field 를 조회한다.- ex)
HGET lecture name - ex)
HGET lecture price - ex)
HGET lecture language
- ex)
HMGET: 다수의 field 를 조회한다.- ex)
HMGET lecture price language invalid - 참고) 존재하지 않는 field 에 대해서는
(nil)이 반환된다.
- ex)
HINCRBY: 숫자형으로 저장되는 field 의 string value 를 특정 값 만큼 더한다.- ex)
HINCRBY lecture price 10 - 참고) 숫자형 string 이 아닌 경우 타입 에러가 발생한다.
(error) ERR hash value is not an integer
- ex)
- 활용 방안 예시)
- Login Session(로그인 세션)

- 예를 들어, 먼저 로그인을 위해 사용자로부터 username / password 와 같은 인증 정보를 넘겨받는다.
- 인증이 완료되면, 서버에서는 임의의 세션아이디를 생성한 뒤, 이를 해시 키로하고, 이후에 필요한 유저의 데이터를 value로 저장한다.
- 서버는 클라이언트에게 응답시 Set-Cookie 헤더에 세션아이디를 담아 반환한다.
- 클라이언트에서는 이후 요청부터 서버에 세션아이디 정보를 전달한다.
- 서버에서는 Redis 에 저장된 캐시를 확인한 뒤 해당 유저에 대한 정보를 체크한다.
- Login Session(로그인 세션)
Sorted Sets
- 중복 없이 Unique 한 string 을 저장하는 Set과 유사하지만, score 라는 추가적인 필드를 가짐으로써, 해당 score 를 통해 데이터를 미리 정렬하는 데이터 타입이다.
- Set 의 기능 + 추가로 score 속성 저장
- Sorted Sets 은 Redis 만의 독특한 데이터 타입 중 하나로, 내부적으로 Skip List 와 Hash Table 을 이용하여 구현되어 있다.
- Sorted Sets 은 내부 구현에 따라 값을 추가하는 순간에 score 에 의해 정렬을 유지한다.
- 만약 score 가 동일한 값이 존재한다면, lexicographically(사전 편찬 순) 으로 정렬된다.
- Sorted Sets 은 줄여서
ZSets라고 불린다. - 명령어)
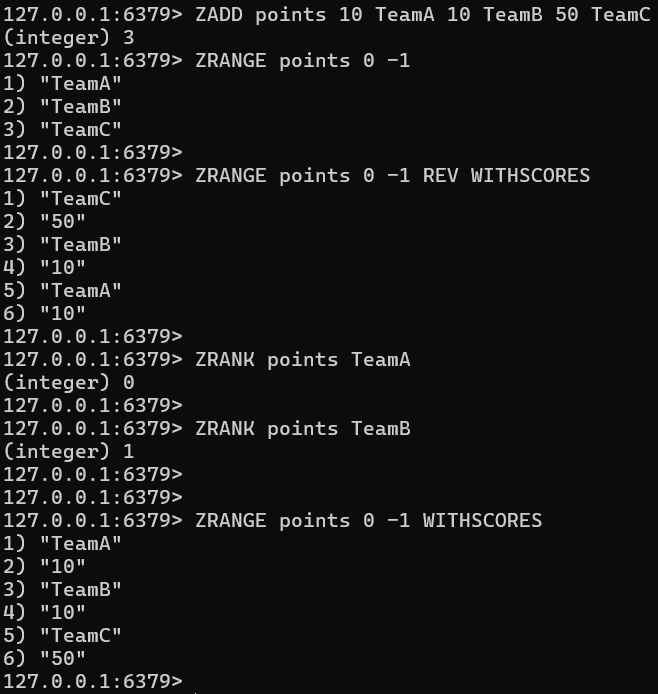
ZADD points 10 TeamA 10 TeamB 50 TeamC- ZADD 명령어를 통해 points 라는 key 로 sorted set 을 생성하고, 각 팀에 점수를 저장한다.
- score 를 먼저 작성하고 member 를 바로 뒤에 써준다.
- 그러면 score 에 의해 (오름차순) 정렬되어 저장된다. ( 저장되는 시점에는 각 member에 인덱스가 정해진다. )
- 그러면 각 팀의 점수는 아래와 같이 정렬된 채로 저장된다. TeamA와 TeamB는 10점으로, 같은 점수를 갖기 때문에, 사전 편찬 순에 의해 TeamA가 우선순위를 갖는다.
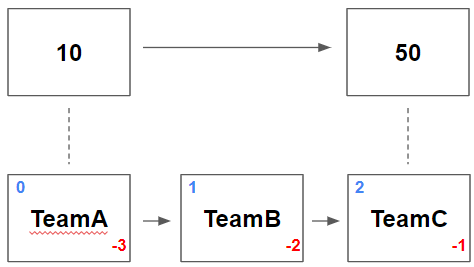
- ZADD 명령어를 통해 points 라는 key 로 sorted set 을 생성하고, 각 팀에 점수를 저장한다.
ZRANGE points 0 -1- ZSets 는 순서를 갖기 때문에 List 와 마찬가지로 RANGE 명령어로 인덱스를 통해 특정 범위를 조회할 수 있다.
- 0부터 -1까지 조회하게 되면 가장 처음부터 가장 마지막 아이템까지 전부 조회하게 된다.
- ZSets 는 순서를 갖기 때문에 List 와 마찬가지로 RANGE 명령어로 인덱스를 통해 특정 범위를 조회할 수 있다.
ZRANGE points 0 -1 REV WITHSROCRESREV(=reserve) WITHSCORES옵션을 주면, 역순(내림차순)으로 score 와 함께 반환된다.- 참고)
REV와WITHSCORES는 각각 따로 적용해줄수도 있다.
ZRANK points TeamA- ZRANK 명령어를 이용하면 멤버의 랭킹을 반환한다. 이 랭킹은 (0부터 시작하는) 인덱스 값과 동일하다.
- 다시 말해 ZRANK 는 Sorted Set 의 인덱스를 반환한다.
- 활용 방안 예시)
- Sliding Window Rate Limiter(비율 계산기)
- Fixed Window Rate Limiter 와 달리 Sliding Window 는 시간에 따라 Window 를 이동시켜 동적으로 요청수를 조절하는 기술이다.
- Fixed Window 는 Window 시간마다 허용량이 초기화 되지만(e.g. '분'이 바뀌었을때 허용량이 초기화), Sliding Window는 시간이 경과함에 따라 Window가 같이 움직인다.
- Sliding Window Rate Limiter(비율 계산기)
강의를 듣고 정리한 글입니다. 코드와 그림 등의 출처는 신동현 강사님께 있습니다.
( https://inf.run/BQH4z )

현실에서 한 발자국