
Redis 에서 지원하는 데이터 타입은 다음과 같다.
1) Strings
2) Lists
3) Sets
4) Hashes
5) Sorted Sets
6) Streams
7) Geospatial
8) Bitmaps
9) HyperLogLog
10) BloomFilter
Streams
- 스트림은
append-only log에consumer groups과 같은 기능을 더한 자료구조이다.- kafka 와 같은 이벤트 스트리밍 플랫폼과 어느정도 유사한 부분이 있다.
append-only log란 데이터베이스나 분산시스템에 주로 사용되는 데이터 저장 알고리즘으로, 데이터가 수정되거나 삭제되지 않고 항상 추가만 되는 구조를 갖는다.
- Redis Steam 에는 몇가지 추가적인 기능이 구현되어 있다.
- 1)
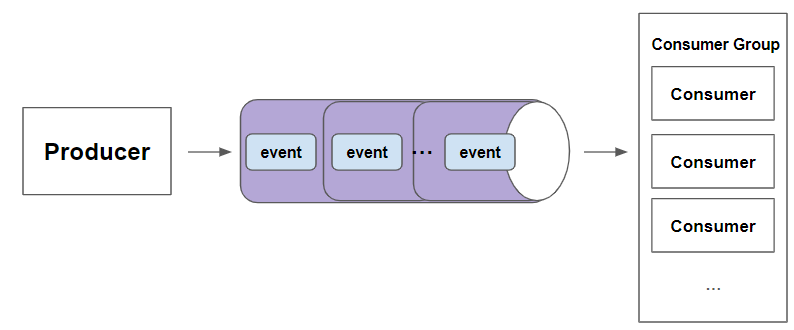
stream에 추가되는 이벤트 또는 메시지는unique id를 갖는다.unique id는 스트림에 추가되는 시간과 순서를 기준으로 Redis 에 의해 자동으로 할당된다. 이러한unique id를 통해 하나의 entry 를 읽을 때, O(1)의 시간 복잡도를 갖게된다. - 2) 분산 시스템의 다수의
consumer에서 안전하게 메시지를consuming할 수 있도록Consumer Group이라는 기능이 포함되어 있다. ( Consumer Group 을 통해 분산 시스템에서 다수의 consumer 가 event 처리 )- List 를 통해 구현하는 Message Broker 의 경우, 다수의 컨슈머에서 메시지를 컨슈밍 할 때, 동일한 메시지를 여러번 처리하는 경우가 발생할 수 있다.
- Redis Stream 의 Consumer Group 을 이용하면, 다수의 Consumer 가 메시지를 처리하면서도, 동일한 메시지를 중복처리하는 문제를 쉽게 해결할 수 있다.
- 1)
- 명령어)
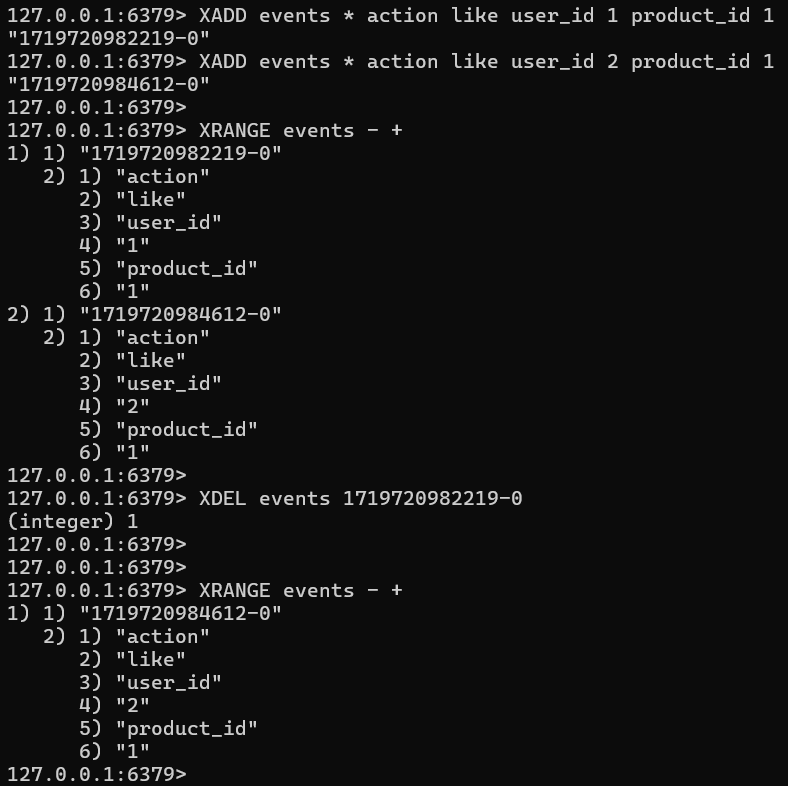
XADD명령어를 통해Stream에entry를 추가할 수 있다. 이후*옵션을 주면 Redis에 의해 자동으로unique id가 할당된다. 이후에 hash 와 같은 field value 형태로 메시지를 구성할 수 있다.- ex)
XADD events * action like user_id 1 product_id 1events라는stream를 생성했다. (하나의 이벤트를 스트림에 추가)*옵션을 줘서,unique id를 자동으로 할당한다.- ex) 1719720982219-0
- 1719720982219 는 엔트리가 추가된 시간을 의미한다.
- 0 은 0번째 아이템이다라는 것을 의미한다.
- ex)
XADD events * action like user_id 2 product_id 1- user2가 1번상품에 좋아요를 눌렀다는 이벤트를 스트림에 추가
- ex)
XRANGE명령어를 이용하면 List 와 유사하게 다수의 메시지를 조회할 수 있다.- ex)
XRANGE events - + - 가장 처음에 들어갔던 이벤트부터 가장 마지막에 들어간 이벤트까지 출력할 수 있다.
- ex)
XDEL명령어를 이용하면 Stream 에서 제거할 수 있다.- ex)
XDEL events UniqueID
- ex)
Geospatial
- Geospatial Indexes : 좌표를 저장하고, 검색할 수 있는 데이터 타입이다.
- 거리 계산, 범위 탐색 등의 기능을 지원한다.
- 명령어)

GEOADD seoul:station 126.923917 37.556944 hong-dae 127.027583 37.497928 gang-nam- 서울에 있는 지하철 역들의 (경도/위도) 좌표를 알고 있을 때,
GEOADD를 이용하여 좌표를 저장할 수 있다. - 참고) 경도를 앞에 추가해줘야 한다.
- 서울에 있는 지하철 역들의 (경도/위도) 좌표를 알고 있을 때,
GEODIST seoul:station hong-dae gang-nam KMGEODIST명령어를 이용하여 역 간의 거리를 구할 수 있다. ( 이때, 옵션을 통해 출력하는 단위를 지정할 수 있다. )
- 활용 방안 예시)
- Geofencing(반경 탐색)
- 위치 정보를 활용하여 지도 상의 가상의 경계 또는 지리적 영역을 정의하는 기술
- Geofencing(반경 탐색)
Bitmaps
- Bitmaps 는 실제 데이터 타입은 아니고,
String에binary operation을 쉽게 사용할 수 있도록 만들어 놓은 인터페이스라고 생각하면 된다. (String에binary operation을 적용한 것 )- 최대 2의 32승(42억개)의 binary 데이터를 표현할 수 있다.
- Bitmaps 은 적은 메모리를 사용하여 바이너리 상태값을 저장하는데 많이 활용된다.
- 명령어)

SETBIT user:login-in:23-01-01 123 1SETBIT user:login-in:23-01-02 456 1SETBIT user:login-in:23-01-02 123 1- 참고)
SETBIT명령어를 이용해서user:login-in:23-01-01라는key로,123이라는offset에value를1로 설정했다. (SETBIT key offset value)- 참고로
value에는 기본적으로0이 들어간다. ( 여기서value는 로그인 여부로 사용한다고 가정 )
- 참고로
- 참고)
BITCOUNT user:login-in:23-01-01BITCOUNT를 이용하면 2023년 1월 1일에 로그인한 유저를 출력할 수 있다.
BITOP AND result user:login-in:23-01-01 user:login-in:23-01-02BITOP명령어에AND를 이용하면 1일과 2일에 모두 로그인한 유저를 확인할 수 있다.- 참고로 결과는 바로 출력되는 것이 아니라, 결과를 담은 다른 bitmap 이 생성된다. (여기서는 result 라는 bitmap이 생성)
- 1일과 2일에 로그인한 유저들의 비트맵 각각을
AND연산을 통해서result에 저장
- 1일과 2일에 로그인한 유저들의 비트맵 각각을
GETBIT result 123- 결과를 확인하고 싶으면 위와 같이
GETBIT를 이용해서,result에서 123번 오프셋 데이터를 출력한다. - 123번 유저는 1일에도, 2일에도 모두 로그인했으므로 1이 출력된다.
- 결과를 확인하고 싶으면 위와 같이
GETBIT result 456- result 에서 456번 오프셋 데이터를 출력한다.
- 456번 유저는 1일, 2일 모두 로그인하지는 않았으므로 0이 출력된다.
BITCOUNT result- 공통으로 로그인 한 유저가 1명임을 확인할 수 있다.
- 활용 방안 예시)
- User Online Status(온라인 상태 표시)
- 사용자의 현재 상태를 표시하는 기능
- 소셜서비스나 게임을 보면 사용자의 현재 상태가 표시되는 서비스들이 있다. 해당 사용자가 현재 온라인 상태인지 오프라인 상태인지를 표시하는 기능이다.
- User Online Status(온라인 상태 표시)
HyperLogLog
- 집합의
cardinality 를 추정할 수 있는확률형 자료구조이다.- 확률형 자료구조 라는 말은, 결과값이 실제와 일정 부분 오차가 발생할 수 있다는 의미이다.
- 따라서 HyperLogLog 에서는 cardinality 를 계산할 때, 추정이라는 표현을 사용하고 있다.
- HyperLogLog 는 정확성을 일부 포기하는 대신에 저장공간을 매우 효율적으로 사용한다.
- 참고) HyperLogLog 의 평균 오차율은 0.81% 이다.
- 따라서 매우 정확한 값을 알 필요가 없고, 근사치만 알아도 되는 경우에 HyperLogLog 를 사용할 수 있다.
- HyperLogLog 원리)
- HyperLogLog 는 멤버의 값을 해싱하여 bucket 이라는 단위로 분류해서 해시 값에 맞게 표시한다.
- 동일한 아이템이 추가된 경우 동일한 해시를 갖기 때문에, cardinality 를 일정하게 계산할 수 있다.
- 다만 HyperLogLog 는 확률적인 계산식이므로, 최종 결과 값은 실제와 다를 수 있다.
- 만약 해시 충돌이 발생하는 경우, HyperLogLog 는 정확하지 않은 cardinality 를 반환한다.
- 물론 Set 을 이용해서도 cardinality 를 계산할 수 있지만, Set 은 중복검사를 위해 실제 값을 메모리에 모두 저장한다. 만약 1만개의 아이템이 존재한다면 아이템 갯수에 비례해서 저장공간이 증가하는데, HyperLogLog 를 이용하면 상대적으로 매우 적은 메모리로 cardinality 를 계산할 수 있다.
- 다만, HyperLogLog 는 실제 값을 저장하지 않기 때문에 모든 아이템을 다시 출력해야 하는 경우에는 활용할 수 없다.
- 명령어)

PFADD fruits apple orange graph kiwiPFADD명령어를 이용하면HyperLogLog에 멤버를 추가할 수 있다.fruits라는key로apple orange graph kiwi를 추가한다.
PFCOUNT fruitsPFCOUNT명령어를 통해서 fruits HyperLogLog 의 cardinality 를 출력할 수 있다.
- 참고) 지금은 4개의 멤버로, 갯수가 적기에 오차가 없지만, 멤버의 수가 1000개, 10000개 등 그 이상 많아질수록 그 결과는 약 1% 미만의 오차가 발생할 수 있다. ( 10000 개를 넣었는데 9999 개로 출력을 한다거나, 10001 개라고 출력할 수 있다. )
- 따라서, 정확한 값이 아닌 근사치만 알아도 되는 경우에 HyperLogLog 를 이용하면, 메모리를 매우 적게 사용하면서 cardinality 를 계산할 수 있다.
- 참고) Set 과 HyperLogLog 메모리 사용량 비교
- Set

for (( i = 1; i <= 1000; i++ )); do redis-cli SADD k1 $i; done- k1 이라는 set에 값들을 1000번 추가
k1 의 메모리 사용: 40296 바이트 사용cardinality: 1000
- HyperLogLog

for (( i = 1; i <= 1000; i++ )); do redis-cli PFADD k2 $i; done- k2 이라는 key로 요소들을 1000번 추가
k2 의 메모리 사용: 2608 바이트 사용- Set 은 40296 바이트를 사용했지만, HyperLogLog 는 2608 바이트만 사용한다. (거의 20배 가까이 메모리 사용량을 절약할 수 있다.)
cardinality: 1001- 1000개를 넣었지만 1001이 반환된 것을 확인할 수 있다. (오차 발생)
- 따라서, 정확도를 일부 포기하더라도 데이터를 효율적으로 적게 사용하고 싶은 경우, Set 보다는 HyperLogLog 를 이용할 수 있다.
- Set
- 활용 방안 예시)
- Visitors Count(방문자 수 계산)
- 방문자 수(또는 특정 액션의 횟수)를 대략적으로 추정하는 경우
- 정확한 횟수를 셀 필요 없이 대략적인 어림치만 알고자 하는 경우에는 HyperLogLog 를 이용하면 해당 기능을 쉽게 구현할 수 있다.
- Visitors Count(방문자 수 계산)
BloomFilter
BloomFilter는HyperLogLog와 마찬가지로 확률형 자료구조의 일종이다.BloomFilter는element가 특정한 집합 안에 포함되었는지 여부를 확인할 수 있는 확률형 자료 구조이다. ( 흔히membership test라고 불리는 기능을 구현할 때 자주 사용된다. )BloomFilter는HyperLogLog와 마찬가지로 정확성을 일부 포기하는 대신 저장공간을 효율적으로 사용한다.BloomFilter는element가 집합에 포함되지 않는다는 사실은 정확하게 확인할 수 있지만, 집합에 포함되지 않는 값이 존재한다고 잘못 말하는,false positive를 반환하는 경우가 있다.- 참고로 존재하는 요소에 대해서, 존재하지 않는다고 반환하는 경우는 없다.
BloomFilter는 실제 값을 저장하지 않기 때문에 (Set에 비해) 매우 적은 메모리를 사용한다.BloomFilter데이터 저장 원리)
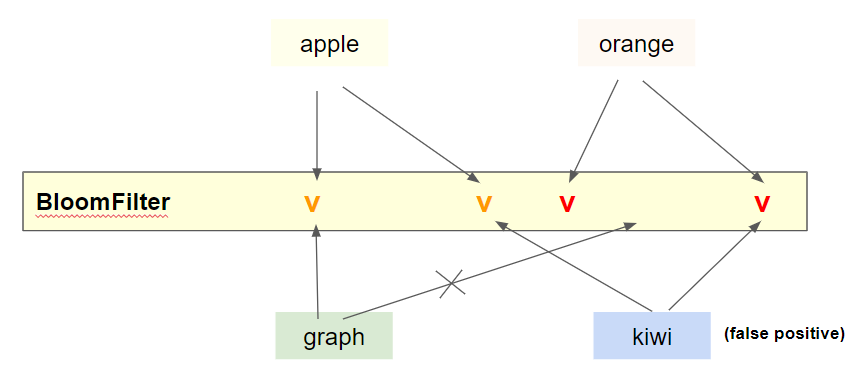
BloomFilter는 값을 해싱하여 여러개의 해시 키를 만들어낸다. 그리고 여러개의 키에 해당하는 위치를BloomFilter에 표시한다.- 이후, 어떤 아이템이 존재하는지 여부를 확인할 때는, 해당 아이템의 해시 키를 생성하여 위치를 확인한다.
- 참고) 위
wiki에서false positive가 발생한다.
- 명령어)
BF.MADD명령어를 통해서 집합에 아이템을 추가할 수 있다.- ex)
BF.MADD fruits apple orange
- ex)
BF.EXISTS명령어를 통해서 특정 아이템이 집합에 이미 포함되어 있는지 여부를 확인할 수 있다.- ex)
BF.EXISTS fruits apple
- ex)
- 활용 방안 예시)
- Unique Events(중복 이벤트 제거)
- 동일 요청이 중복으로 처리되지 않기 위해 빠르게 해당 item이 중복인지 확인하는 방법
- 클라이언트에서 발생하는 이벤트를 수집하는 서버가 있다고 할 때, 클라이언트의 실수로 중복되는 이벤트를 여러번 요청할 수 있다. 이벤트 수집 서버는 이런 경우를 대비해서 중복 데이터를 제거하는 기능을 가지고 있어야 한다. 이럴때 BloomFilter 를 이용할 수 있다.
- Unique Events(중복 이벤트 제거)
강의를 듣고 정리한 글입니다. 코드와 그림 등의 출처는 신동현 강사님께 있습니다.
( https://inf.run/BQH4z )

현실에서 한 발자국