코호트 분석(Cohort Analysis)이란?
코호트 분석(Cohort Analysis)
코호트 분석은 고객들을 특정 기준에 따라 구분한 후, 이들 그룹의 행동이나 성과를 시간에 따라 추적하는 분석 방법이다.
'코호트'라는 말은 공통된 특성이나 경험을 공유하는 사람들의 그룹을 의미한다.
왜 중요한가?
코호트 분석은 단순히 방문자 수나 판매량 같은 허영 지표들보다 실질적인 통찰력을 제공한다. 이 방법을 통해 기업은 고객의 행동 변화를 좀 더 정확하게 이해할 수 있으며, 이는 제품 개선, 마케팅 전략 조정, 고객 충성도 향상 등 다양한 영역에서 의사 결정을 지원한다. 또한, 특정 기간 동안 고객 행동을 이해함으로써, 시간이 지남에 따른 변화를 파악하고, 예측 가능한 패턴을 식별할 수 있다.
코호트 분석의 종류
1. ⭐시간 코호트(Time Cohorts)⭐
특정 기간 동안 같은 서비스에 가입하거나 같은 제품을 구매한 고객들의 그룹
예시: 연말 쇼핑 시즌에 가입한 고객들이 다른 시기에 가입한 고객들에 비해 더 높은 구매 빈도를 보이는지 분석한다.
2. 행동 코호트(Behavior Cohorts)
과거에 특정 행동을 취한 고객들로 구성된 그룹(제품 구매, 서비스 가입, 또는 특정 활동 참여 등)
예시: 블랙 프라이데이 기간 동안 구매한 고객들이 그 이후에도 할인된 제품을 더 많이 구매하는지 분석한다.
3. 크기 코호트(Size Cohorts)
고객들이 특정 기간 동안 발생시킨 구매액이나 서비스 이용량에 따라 구분된 그룹
예시: 첫 구매 후 6개월 이내에 100만 원 이상을 지출한 고객들과 그렇지 않은 고객들의 재구매율을 비교 분석한다.
코호트 분석(Cohort Analysis)
1. 데이터 테이블 살펴보기
먼저 분석할 데이터를 살펴보자. 데이터는 여러 고객의 거래 내역을 담고 있다. 각 행은 고객의 구매 내역을 나타내며, 구매한 제품, 수량, 구매 날짜, 고객ID등의 정보를 포함한다.
| In [1] | InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country |
|---|---|---|---|---|---|---|---|---|
| 416792 | 572558 | 22745 | POPPY'S PLAYHOUSE BEDROOM | 6 | 2011-10-25 08:26:00 | 2.10 | 14286 | United Kingdom |
| 482904 | 577485 | 23196 | VINTAGE LEAF MAGNETIC NOTEPAD | 1 | 2011-11-20 11:56:00 | 1.45 | 16360 | United Kingdom |
| 263743 | 560034 | 23299 | FOOD COVER WITH BEADS SET 2 | 6 | 2011-07-14 13:35:00 | 3.75 | 13933 | United Kingdom |
| 495549 | 578307 | 72349B | SET/6 PURPLE BUTTERFLY T-LIGHTS | 1 | 2011-11-23 15:53:00 | 2.10 | 17290 | United Kingdom |
| 204384 | 554656 | 21756 | BATH BUILDING BLOCK WORD | 3 | 2011-05-25 13:36:00 | 5.95 | 17663 | United Kingdom |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 448575 | 575063 | 22804 | PINK HANGING HEART T-LIGHT HOLDER | 1 | 2011-11-08 12:32:00 | 2.95 | 16764 | United Kingdom |
| 19970 | 537963 | 21733 | RED HANGING HEART T-LIGHT HOLDER | 12 | 2010-12-09 11:30:00 | 2.95 | 13369 | United Kingdom |
| 264154 | 560089 | 23238 | SET OF 4 KNICK KNACK TINS LONDON | 1 | 2011-07-14 16:45:00 | 4.15 | 12748 | United Kingdom |
| 199822 | 554103 | 85123A | WHITE HANGING HEART T-LIGHT HOLDER | 2 | 2011-05-22 13:51:00 | 2.95 | 15555 | United Kingdom |
| 312243 | 564342 | 22910 | PAPER CHAIN KIT VINTAGE CHRISTMAS | 2 | 2011-08-24 14:53:00 | 2.95 | 16340 | United Kingdom |
총 70864개의 행과 8개의 열이 있다.
2. 날짜 파싱 함수 정의하기
- 날짜 파싱 함수(
get_day)를 정의하여,InoviceDate에서 연, 월, 일 정보만을 추출한다. 이 함수는 구매 날짜에서 시간 정보를 제거하여, 같은 날짜에 이루어진 모든 구매를 동일하게 처리할 수 있도록 한다.
# 날짜 파싱 함수 정의
def get_day(x): return dt.datetime(x.year, x.month, x.day) 3. 코호트 날짜 생성
Invoiceday열을 새로 만들어, 각 구매 건에 대한 정확한 날짜(년, 월, 일)를 저장한다. 이는 고객이 처음 거래한 날짜를 찾기 위한 기준점이다.
고객별로 그룹화하여 각 고객의 최초 구매 날짜를 찾는다. 이렇게 하면, 각 고객에게 고유한 '코호트 날짜'가 할당된다.
# InvoiceDay 열 생성
online['InvoiceDay'] = online['InvoiceDate'].apply(get_day)
# CustomerID로 그룹화하고 InvoiceDay 값을 선택
grouping = online.groupby('CustomerID')['InvoiceDay'] 4. 코호트 할당
CohortDay열을 만들어, 각 고객별로 최초 구매 날짜를 할당한다. 이 날짜는 고객이 처음 구매한 날로, 해당 고객이 속한 코호트를 결정한다.
#최소 InvoiceDay 값을 할당
online['CohortDay'] = grouping.transform('min')5. 결과 확인
최종적으로 고객별로 최초 구매 날짜(CohortDay)와 각 구매 건의 날짜(InvoiceDay)를 확인할 수 있다. 이 정보를 통해, 각 코호트의 구매 행동 분석이 가능하다.
| InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country | InvoiceDay | CohortDay |
|---|---|---|---|---|---|---|---|---|---|
| 416792 | 572558 | POPPY'S PLAYHOUSE BEDROOM | 6 | 2011-10-25 08:26:00 | 2.10 | 14286 | United Kingdom | 2011-10-25 | 2011-04-11 |
| 482904 | 577485 | VINTAGE LEAF MAGNETIC NOTEPAD | 1 | 2011-11-20 11:56:00 | 1.45 | 16360 | United Kingdom | 2011-11-20 | 2011-09-12 |
| 263743 | 560034 | FOOD COVER WITH BEADS SET 2 | 6 | 2011-07-14 13:35:00 | 3.75 | 13933 | United Kingdom | 2011-07-14 | 2011-07-14 |
| 495549 | 578307 | SET/6 PURPLE BUTTERFLY T-LIGHTS | 1 | 2011-11-23 15:53:00 | 2.10 | 17290 | United Kingdom | 2011-11-23 | 2011-11-23 |
| 204384 | 554656 | BATH BUILDING BLOCK WORD | 3 | 2011-05-25 13:36:00 | 5.95 | 17663 | United Kingdom | 2011-05-25 | 2011-02-25 |
6. 시간 오프셋 계산
get_date_int() 함수를 사용하여, 주어진 날짜(InvoiceDay 및 CohortDay)에서 연, 월, 일을 정수 값으로 추출한다.
def get_date_int(df, column):
year = df[column].dt.year
month = df[column].dt.month
day = df[column].dt.day
return year, month, day다음 코드를 실행하여 각 열로부터 연, 월, 일 값을 추출할 수 있다.
# `InvoiceDay` 열에서 연, 월, 일 추출
invoice_year, invoice_month, invoice_day = get_date_int(online, 'InvoiceDay')
# `CohortDay` 열에서 연, 월, 일 추출
cohort_year, cohort_month, cohort_day = get_date_int(online, 'CohortDay')
7. 일수 오프셋 계산
Invoice(청구) 날짜와 Cohort(코호트) 날짜 사이의 차이를 년, 월, 일 단위로 각각 계산한 후, 이 두 날짜 사이의 총 일수 차이를 계산한다.
# 년도 차이 계산
years_diff = invoice_year - cohort_year
# 월 차이 계산
months_diff = invoice_month - cohort_month
# 일 차이 계산
days_diff = invoice_day - cohort_day
# 총 일수 차이 계산 및 데이터프레임에 추가
online['CohortIndex'] = years_diff * 365 + months_diff * 30 + days_diff + 1
print(online.head())| InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country | InvoiceDay | CohortDay | CohortIndex |
|---|---|---|---|---|---|---|---|---|---|---|
| 416792 | 572558 | POPPY'S PLAYHOUSE BEDROOM | 6 | 2011-10-25 08:26:00 | 2.10 | 14286 | United Kingdom | 2011-10-25 | 2011-04-11 | 195 |
| 482904 | 577485 | VINTAGE LEAF MAGNETIC NOTEPAD | 1 | 2011-11-20 11:56:00 | 1.45 | 16360 | United Kingdom | 2011-11-20 | 2011-09-12 | 69 |
| 263743 | 560034 | FOOD COVER WITH BEADS SET 2 | 6 | 2011-07-14 13:35:00 | 3.75 | 13933 | United Kingdom | 2011-07-14 | 2011-07-14 | 1 |
| 495549 | 578307 | SET/6 PURPLE BUTTERFLY T-LIGHTS | 1 | 2011-11-23 15:53:00 | 2.10 | 17290 | United Kingdom | 2011-11-23 | 2011-11-23 | 1 |
| 204384 | 554656 | BATH BUILDING BLOCK WORD | 3 | 2011-05-25 13:36:00 | 5.95 | 17663 | United Kingdom | 2011-05-25 | 2011-02-25 | 91 |
코호트 지표
1. 유지율(retention rate) 계산
고객 유지율은 고객이 얼마나 장기간 서비스나 제품을 이용하는지를 이해하는 데 중요한 지표이다.
# grouping 객체를 사용해 고객 ID별 고유값 수를 계산
cohort_data = grouping['CustomerID'].apply(pd.Series.nunique).reset_index()
# 피벗 테이블 생성
cohort_counts = cohort_data.pivot(index='CohortMonth', columns='CohortIndex', values='CustomerID')
# 첫 번째 열을 선택하여 코호트 크기 계산
cohort_sizes = cohort_counts.iloc[:,0]
# 코호트 크기로 나누어 유지율 계산
retention = cohort_counts.divide(cohort_sizes, axis=0)
| CohortIndex | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CohortMonth | |||||||||||||
| 2010-12-01 | 1.0 | 0.344 | 0.309 | 0.351 | 0.342 | 0.398 | 0.348 | 0.330 | 0.335 | 0.370 | 0.355 | 0.486 | 0.24 |
| 2011-01-01 | 1.0 | 0.208 | 0.247 | 0.244 | 0.331 | 0.271 | 0.247 | 0.259 | 0.313 | 0.307 | 0.373 | 0.136 | NaN |
| 2011-02-01 | 1.0 | 0.184 | 0.180 | 0.263 | 0.269 | 0.234 | 0.253 | 0.263 | 0.272 | 0.301 | 0.089 | NaN | NaN |
| 2011-03-01 | 1.0 | 0.162 | 0.258 | 0.196 | 0.214 | 0.173 | 0.253 | 0.219 | 0.276 | 0.098 | NaN | NaN | NaN |
| 2011-04-01 | 1.0 | 0.192 | 0.204 | 0.192 | 0.184 | 0.204 | 0.220 | 0.231 | 0.067 | NaN | NaN | NaN | NaN |
| ... | |||||||||||||
| 2011-08-01 | 1.0 | 0.216 | 0.201 | 0.252 | 0.101 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2011-09-01 | 1.0 | 0.201 | 0.280 | 0.122 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2011-10-01 | 1.0 | 0.211 | 0.094 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2011-11-01 | 1.0 | 0.110 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2011-12-01 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
- CohortIndex: 코호트 인덱스
- CohortMonth: 코호트 월
- 1-13: 해당 코호트 월에서 지난 특정 기간 동안의 유지율 (첫 번째 열은 100%로 설정됨)
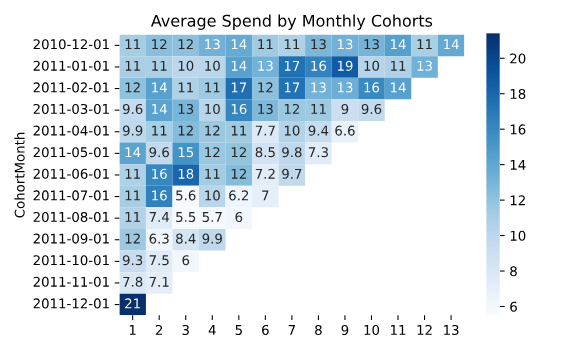
2. 평균 가격 계산
시간이 지남에 따라 평균 구매 가격이 어떻게 변하는지 분석한다.
# 월별 코호트와 코호트 인덱스를 그룹화하여 그룹화 객체 생성
grouping = online.groupby(['CohortMonth', 'CohortIndex'])
# 개당 가격 열의 평균 계산
cohort_data = grouping['UnitPrice'].mean()
# cohort_data의 인덱스 재설정
cohort_data = cohort_data.reset_index()
# 피벗 생성
average_price = cohort_data.pivot(index='CohortMonth', columns='CohortIndex', values='UnitPrice')
print(average_price.round(1))| CohortIndex | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CohortMonth | |||||||||||||
| 2010-12-01 | 3.0 | 3.0 | 3.0 | 2.8 | 2.7 | 6.9 | 2.8 | 3.0 | 2.7 | 2.7 | 3.0 | 2.8 | 2.6 |
| 2011-01-01 | 3.2 | 3.1 | 3.0 | 3.0 | 3.1 | 3.0 | 3.0 | 2.5 | 2.7 | 2.9 | 2.6 | 2.0 | NaN |
| 2011-02-01 | 3.1 | 4.0 | 3.3 | 2.9 | 3.3 | 2.9 | 2.8 | 2.7 | 2.9 | 2.7 | 3.1 | NaN | NaN |
| 2011-03-01 | 3.5 | 3.6 | 3.5 | 2.8 | 2.7 | 2.5 | 2.7 | 2.9 | 2.5 | 2.4 | NaN | NaN | NaN |
| 2011-04-01 | 3.3 | 4.4 | 3.4 | 2.6 | 2.8 | 2.8 | 2.8 | 2.6 | 2.6 | NaN | NaN | NaN | NaN |
| ... | |||||||||||||
| 2011-08-01 | 2.9 | 3.7 | 5.4 | 6.9 | 4.2 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2011-09-01 | 2.9 | 3.1 | 3.0 | 2.6 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2011-10-01 | 2.9 | 2.7 | 2.5 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2011-11-01 | 2.5 | 2.1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2011-12-01 | 1.9 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
2010년 12월 코호트의 경우 첫 번째 달에는 평균 구매 가격이 3.0이었고, 6개월 후에는 6.9로 증가한 것을 볼 수 있다. 이는 특정 시점에 평균 구매 가격이 상당히 증가했음을 의미한다. 반면, 다른 코호트들은 시간이 지남에 따라 평균 구매 가격에 큰 변동이 없거나 점차 감소하는 경향을 보이기도 한다.
코호트 분석 시각화하기(유지율 히트맵)
# seaborn 패키지를 sns로 가져오기
import seaborn as sns
# 8x6 인치의 플롯 피규어 초기화
plt.figure(figsize=(8, 6))
# 제목 추가
plt.title('Average Spend by Monthly Cohorts')
# 히트맵 생성
sns.heatmap(average_quantity, annot=True, cmap='Blues')
plt.show()