Python
1. 파이썬 시퀀스 자료형: 기초 개념 소개

파이썬에서는 다양한 자료형을 다룰 수 있는데, 그 중에서도 시퀀스 자료형은 데이터의 순서 있는 나열을 다루는 데에 사용되며, 주로 리스트, 튜플, 레인지, 문자열, 바이트 시퀀스 등이 이에 속합니다.시퀀스 자료형은 데이터를 순서대로 담을 수 있는 자료형입니다. 그래서
2.파이썬 문자열 포맷팅: format 함수와 f 문자열 포맷팅의 활용 방법

파이썬에서 <span style = "color: 문자열 포맷팅(String Formatting)은 문자열 내에 어떤 값을 삽입하거나, 특정 형식에 맞게 문자열을 조정하는 방법입니다. 이는 <span style = "background-color: 파이썬에서
3.args 와 kwargs 정리

함수 인자(Arguments)는 함수로 전달되는 정보입니다. 예를 들어, 레시피에서 재료처럼 생각할 수 있습니다. 안녕하세요, 지수greet_me 함수는 키워드 인자로 전달된 모든 값들을 출력합니다. \*\*kwargs를 사용하여 여러 개의 키워드 인자를 사전 형태로
4.loc과 iloc의 차이점 정리

`loc`과 `iloc`은 파이썬 라이브러리인 Pandas에서 데이터프레임(DataFrame)의 특정 데이터를 선택</span>하기 위해 사용하는 메소드(method)입니다. 먼저 loc과 iloc에 대해 간단히 살펴보겠습니다.
5.DataFrame 데이터 통합하기

예전에는 append()를 사용했으나 pandas 1.4.0버전 이후로는 지원하지 않는다고 합니다.index 라벨을 지정한 DataFrame의 경우에도 index가 같으면 join을 이용해 가로 방향으로 데이터를 추가 할 수 있습니다.두 개의 DataFrame에 공통된
6.DataFrame에서의 명시적 인덱스

Explicit Indexes (명시적 인덱스) 정의 및 개념: 명시적 인덱스(Explicit Indexes): 데이터프레임에서 각 행과 열에 부여된 사용자 정의 인덱스이다. 행 또는 열의 위치를 나타내는 데 사용된다. 예시: 출력: .columns와 .ind
7.데이터 프레임 시각화하기
df.plot(kind='bar)df.plot(x='date', y='weight_kg', kind='line')df.plot(x='', y='', kind='scatter', title='').hist()
8.Missing values(결측치)

데이터에서 누락된 값이다.pandas DataFrame에서 NaN으로 표시된다. (Not a Number)일부 function들은 결측치를 처리할 수 없기 때문에 사용하기 전에 먼저 처리해야 한다.df.isna()모든 값의 존재 여부에 대해 True/False 결과를
9.DataFrame 생성하기 (Dictionary, List)

Dictionaries 중괄호를 이용해 딕셔너리를 만들 수 있고, 대괄호 안에 있는 키를 통해 딕셔너리의 값을 추출할 수 있다. DataFrames 생성하기 딕셔너리의 리스트 데이터는 행별로 구성된다. 리스트의 딕셔너리 데이터는 열별로 구성된다.
10.탐색적 데이터 분석(EDA) - 범주형 데이터

패턴 및 관계 인식: 데이터 내 숨겨진 패턴과 상관관계를 파악하여 인사이트를 얻을 수 있다.질문 및 가설 생성: 데이터를 이해하고 새로운 질문을 생성하거나 가설을 세우는 데 도움이 된다.머신러닝 데이터 준비: 모델 학습에 적합한 데이터 형태로 전처리 및 변환한다.대표성
11.지리 데이터 시각화: Polygon과 Scatterplot

c = 마커(데이터 포인트)의 색상c = darked = 진한 빨간색marker = s = 정사각형 마커marker의 모양'o': 원 (기본값)'s': 정사각형'^': 위쪽을 향하는 삼각형'v': 아래쪽을 향하는 삼각형'>': 오른쪽을 향하는 삼각형'<': 왼쪽을
12.파이썬으로 코호트 분석(cohort analysis)하기
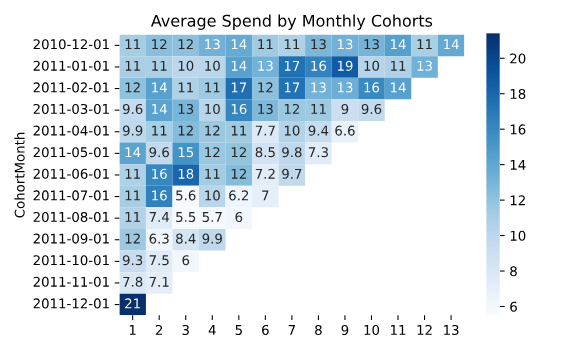
코호트 분석은 고객들을 특정 기준에 따라 구분한 후, 이들 그룹의 행동이나 성과를 시간에 따라 추적하는 분석 방법이다.'코호트'라는 말은 공통된 특성이나 경험을 공유하는 사람들의 그룹을 의미한다. 코호트 분석은 단순히 방문자 수나 판매량 같은 허영 지표들보다 실질적인