
OCR
光學文字認識(광학문자인식)/Optical Character Recognition(OCR)
OCR은 이미지(사진) 속 글자 위치를 찾고 어떤 글자인지 자동으로 알아내는 기술입니다. OCR은 다양한 형태의 글자를 이해하기 위해 독자적인 글자 영역 검출 및 인식 기술을 보유하고 있습니다.
구글의 tesseract를 이용해서 간단하게 OCR기술을 테스트해보겠습니다.
아래는 테스트를 위해 작성한 코드이며 순차적으로 설명하겠습니다.
app.py import pytesseract from PIL import Image pytesseract.pytesseract.tesseract_cmd = r'/usr/local/bin/tesseract' a = Image.open('영수증.jpg') result = pytesseract.image_to_string(a,lang='kor') print(result)
우선 Conda를 이용해 가상환경 생성 및 적용을 해줍니다.
그런 뒤 tesseract 및 기타 필요 라이브러리를 설치해줍니다.
python 에서 tesseract를 사용하기 위해서는 pytesseract도 깔아줘야 합니다.
mac OS 기준 Brew install tesseract pip install pytesseract pip install pillow
설치가 완료되면 app.py라는 파일을 만든 뒤 아래 모듈을 불러와줍니다.
import pytesseract from PIL import Image
그런 후 tesseract의 설치 경로를 적어줘야 합니다.
pytesseract.pytesseract.tesseract_cmd = r'tesseract경로'
tesseract의 경로를 찾지 못할 때는 터미널 상에서 brew list tesseract 또는 Which tesseract 라고 입력해주면 경로가 확인됩니다.

이제 Image.open() 이라는 메소드안에 이미지 파일 이름을 넣어주고 a라는 변수에 담아줍니다. Pytesseract가 가지고 있는 메소드 중 image_to_string( =사진속 글자를 텍스트로 변환해줌)를 사용하여 a를 넣어줍니다. 이미지 속 해독할 언어가 한국어라면 lang=’kor’도 넣어줍니다. 영어일 경우 넣지 않아도 괜찮습니다.
a = Image.open('영수증.jpg') result = pytesseract.image_to_string(a,lang='kor') print(result)
이렇게 로직을 끝낸 후 파일을 실행 시켜 보겠습니다.
python app.pytest (한글/표)
OCR로 검출 된 모습
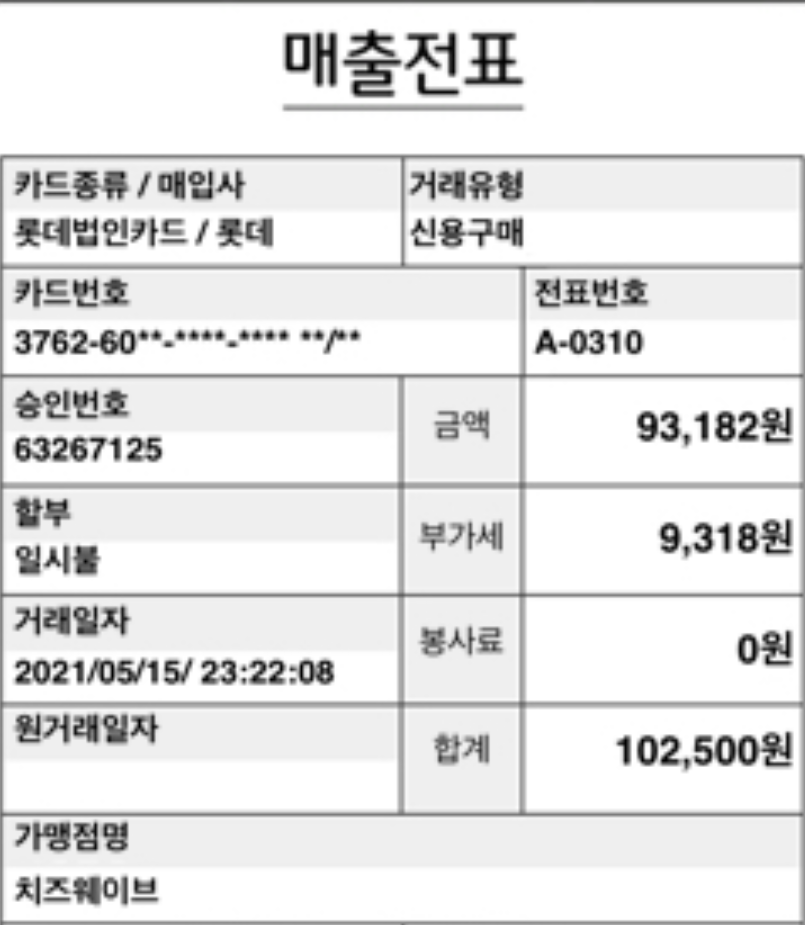
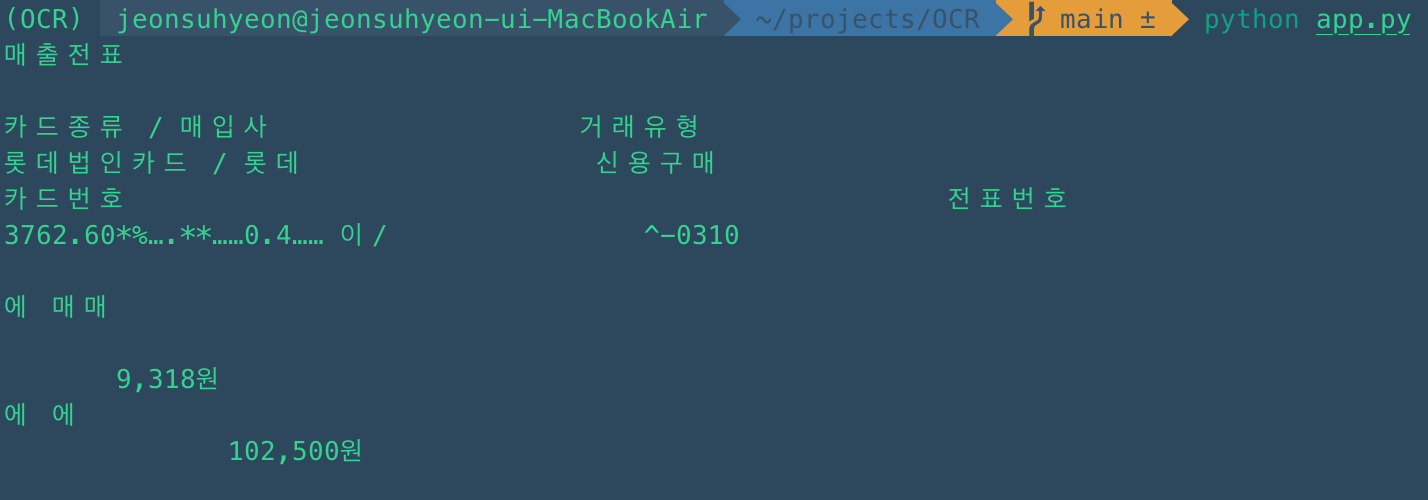
아무래도 test 이미지의 화질 및 한글 인식, 표 인식 등이 잘 되지 않는 것 같습니다. 좀 더 이미지가 깨끗하고 표형식이 아닌 이미지를 test 해보겠습니다.
python app.pytest (한글/문장)
OCR로 검출 된 모습

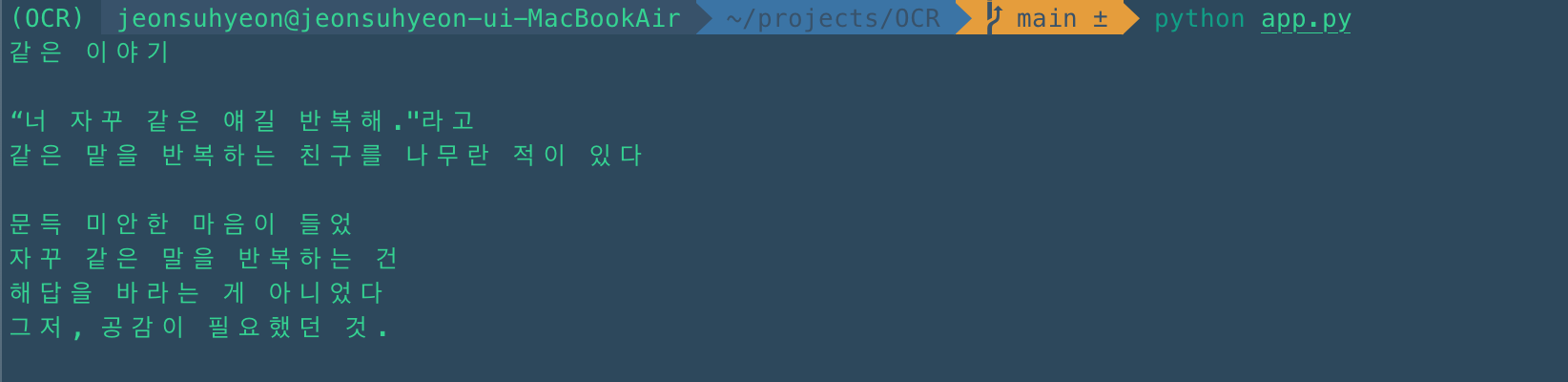
확실히 아까의 test보다는 깔끔하게 검출 된 모습을 볼 수 있습니다.
추가로 영어로 된 이미지도 test 해보고 마치겠습니다.
python app.pytest 이미지(영어)
OCR로 검출 된 모습

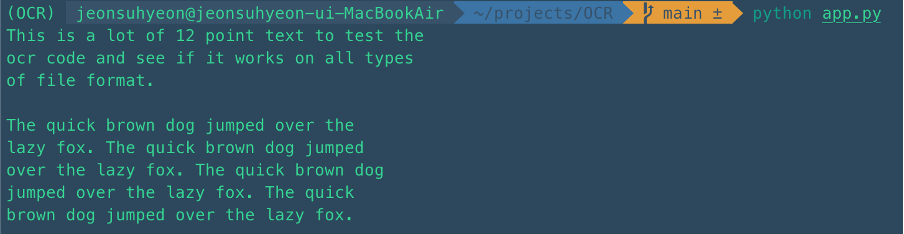
허접하지만 간단 OCR 체험해보기 끝!
