
selenium을 통해 간단하게 구현할 수 있는 크롤링 연습을 진행해봤습니다.
구글 이미지 페이지에서 원하는 검색어를 통해 나오는 이미지들을 전부 클릭하여 다운로드 받는 과정을 진행하려고 합니다.
아래 코드는 최종적으로 위 과정을 진행하기 위해 만든 코드이며, 코드를 순서대로 실행해보며 설명할 예정입니다.
google.py from selenium import webdriver from selenium.webdriver.common.keys import Keys import time import urllib.request chrome_path = r'/usr/local/bin/chromedriver' driver = webdriver.Chrome(executable_path=chrome_path) driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl") elem = driver.find_element_by_name("q") elem.send_keys('치즈웨이브') elem.send_keys(Keys.RETURN) SCROLL_PAUSE_TIME = 1 last_height = driver.execute_script("return document.body.scrollHeight") while True: driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(SCROLL_PAUSE_TIME) new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: try: driver.find_element_by_css_selector('.mye4qd').click() except: break last_height = new_height images = driver.find_elements_by_css_selector('.rg_i.Q4LuWd') count = 1 for image in images: try: image.click() time.sleep(2) imgUrl = driver.find_element_by_css_selector('.n3VNCb').get_attribute('src') urllib.request.urlretrieve(imgUrl, str(count)+'.jpg') count = count + 1 except: pass driver.close()
초기세팅
테스트를 진행 할 폴더를 하나 만들어 주고 conda로 가상환경 생성을 해줍니다.
이 후 pip install selenium을 통해 selenium을 깔아줍니다.
폴더 안에 google.py라는 명령어가 들어가게 될 파일을 만들어 주었고 python selenium example라고 검색하여 간단 크롤링에 기본 베이스가 되는 코드를 가져왔습니다.
from selenium import webdriver from selenium.webdriver.common.keys import Keys driver = webdriver.Firefox() driver.get("http://www.python.org") assert "Python" in driver.title elem = driver.find_element_by_name("q") elem.clear() elem.send_keys("pycon") elem.send_keys(Keys.RETURN) driver.close()
그런 후 Chrome을 통한 크롤링을 진행 할 것이니 본인의 os와 깔려있는 Chrome 버전을 확인하여 맞는 chromedriver를 다운받고 파일을 해당 폴더에 넣어줍니다.
chrome을 통한 크롤링을 진행 할 예정이니 chromedriver로 바꿔주고 driver.get에는 크롤링을 진행 할 구글 이미지 페이지의 url을 넣어줍니다.
chrome_path가 생긴 이유는 파일 실행시 chromedriver 경로 오류가 계속 발생하여 입력해주었습니다.
from selenium import webdriver from selenium.webdriver.common.keys import Keys chrome_path = r'/usr/local/bin/chromedriver' driver = webdriver.Chrome(executable_path=chrome_path) driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&ogbl") elem = driver.find_element_by_name("q") elem.clear() elem.send_keys("pycon") elem.send_keys(Keys.RETURN) driver.close()
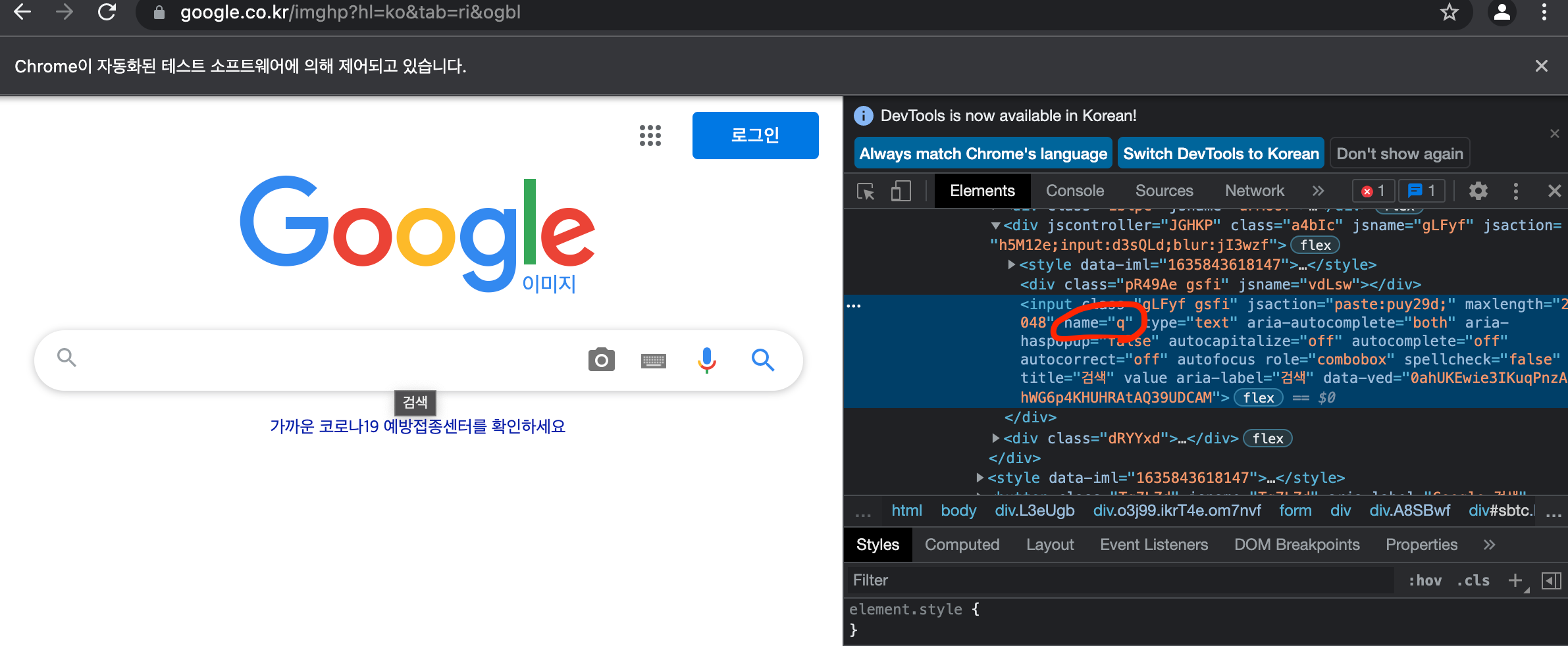
terminal을 통해 python googlep.py 명령어를 입력해주면 자동적으로 google 이미지 페이지가 뜨는 것을 볼 수 있고, 검색창을 찾아 검색어를 입력하는 과정도 넣어야해서 개발자도구에서 검색창에 대한 name을 찾아보았고"q"라고 지정되있는 걸 확인 할 수 있었습니다.
하여 elem = driver.find_element_by_name("q")명령어를 그대로 사용해줍니다.
검색창을 찾고 검색어를 입력하는 명령어인 elem.send_keys('검색어') 와 검색어를 입력 한 뒤 엔터를 쳐주는 elem.send_keys(Keys.RETURN) 명령어를 차례로 입력해줍니다.
from selenium import webdriver from selenium.webdriver.common.keys import Keys chrome_path = r'/usr/local/bin/chromedriver' driver = webdriver.Chrome(executable_path=chrome_path) driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&ogbl") elem = driver.find_element_by_name("q") elem.send_keys("치즈웨이브") elem.send_keys(Keys.RETURN) driver.close()
세상에서 가장 맛있는 피자집이라는 치즈웨이브를 검색해보도록 하겠습니다..
python google.py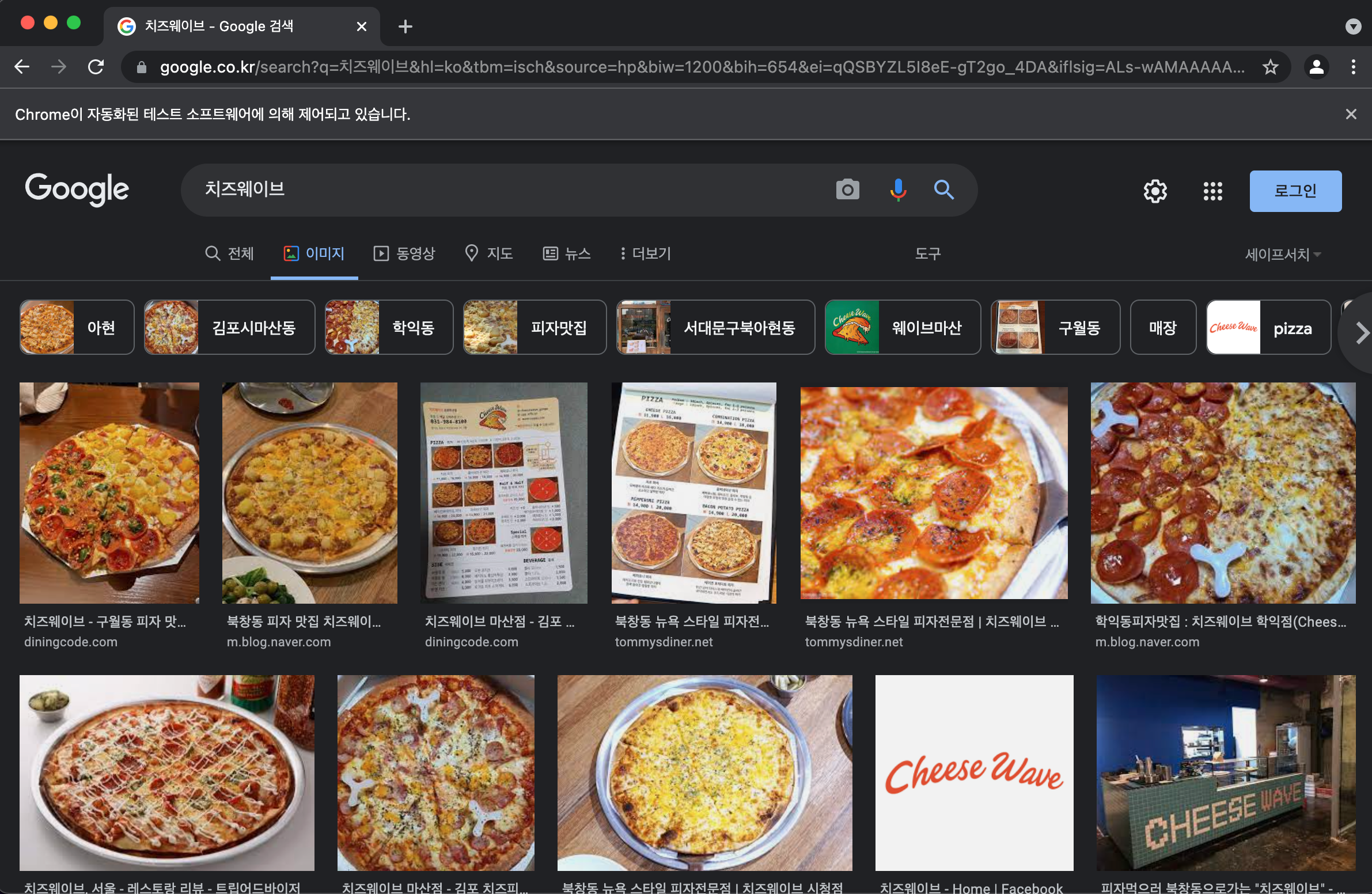
구글 이미지 페이지에서 치즈웨이브가 검색되어 검색 결과가 나오는 모습입니다.
소문대로 맛있어보이네요🤤..
이제 스크롤을 내려 끝까지 내려 검색어에 대한 전체 사진이 나올 수 있도록 로드해주는 작업을 진행합니다. python selenium scroll down 을 검색하여 나오는 코드를 가져왔습니다. (SCROLL_PAUSE_TIME부터..)
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time chrome_path = r'/usr/local/bin/chromedriver' driver = webdriver.Chrome(executable_path=chrome_path) driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&ogbl") elem = driver.find_element_by_name("q") elem.send_keys("치즈웨이브") elem.send_keys(Keys.RETURN) ---------------------------------------------------------------- SCROLL_PAUSE_TIME = 1 last_height = driver.execute_script("return document.body.scrollHeight") while True: driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(SCROLL_PAUSE_TIME) new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: try: driver.find_element_by_css_selector('.mye4qd').click() #더보기 항목을 클릭하기 위한 명령어 except: break #더보기 항목이 없게되면 멈추기 last_height = new_height driver.close()
driver.execute_script("return document.body.scrollHeight")을 통해 스크롤 전체 높이를last_height변수에 담아줍니다.
While 반복문을 통해 스크롤을 계속 내려주며 사진들을 로드시켜줄 수 있게 만들 예정입니다. 로드되는 시간이 있으니 time.sleep을 통해 중간마다 break를 걸어줍니다.
검색어 '치즈웨이브'는 사진이 많지않아 해당되지 않았지만 '구글'처럼 이미지가 많이 나오는 검색어로 검색하였을때는 한번에 최대로 로딩되는 이미지 개수가 정해져 있고 '결과 더보기'라는 버튼을 눌러 추가 이미지들을 불러오게 됩니다.
하여 전체 이미지를 다 확인하기 위해서는 '결과 더보기'버튼이 나오지 않을때까지 클릭 및 스크롤 다운을 해줘야 합니다.
이 명령어를 수행하기 위해 '결과더보기' 버튼의 class 가 mye4qd 인 것을 확인하였고
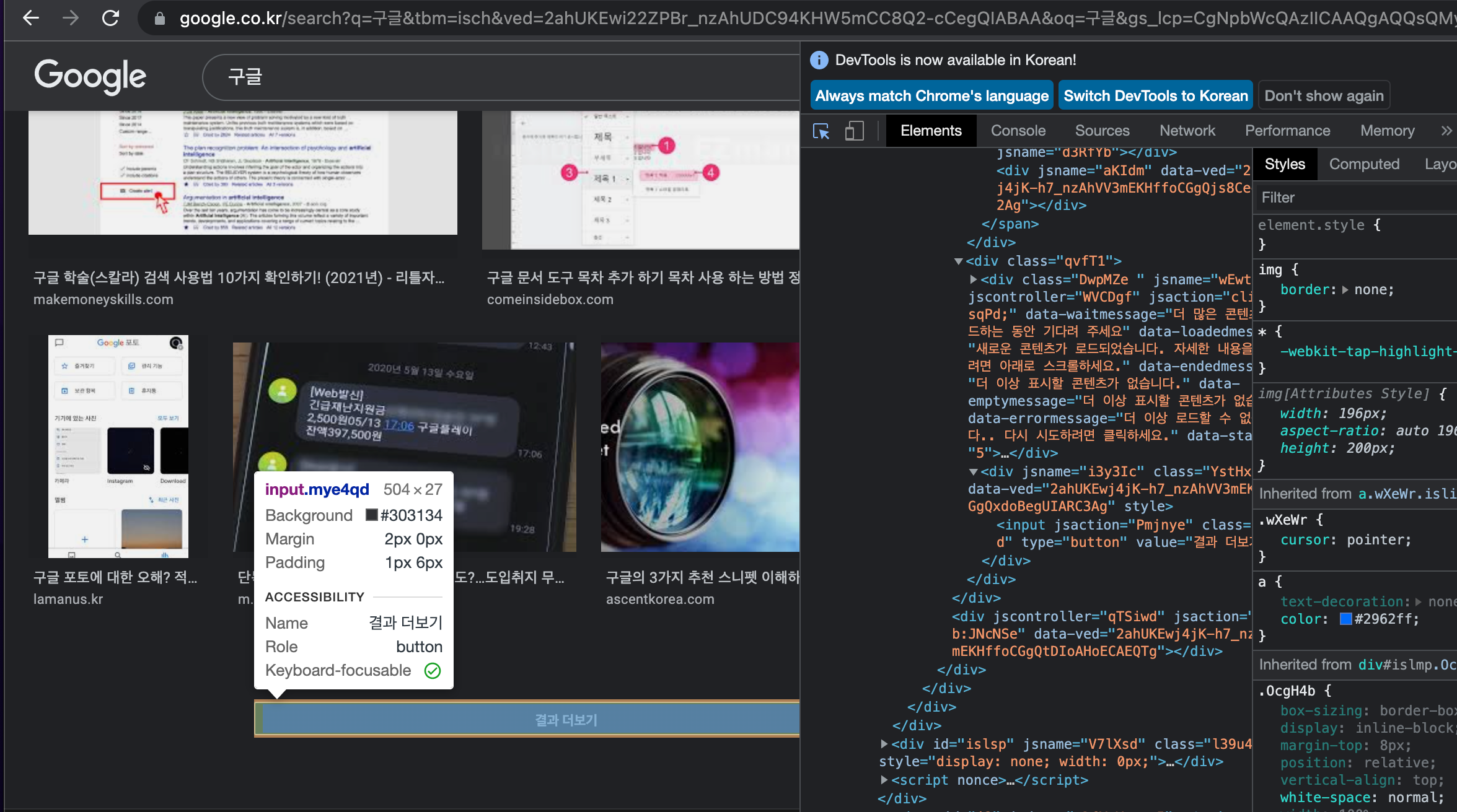
driver.find_element_by_css_selector('.mye4qd').click()
를 통해 해당 class를 확인하게 되면 클릭하도록 설정했습니다.
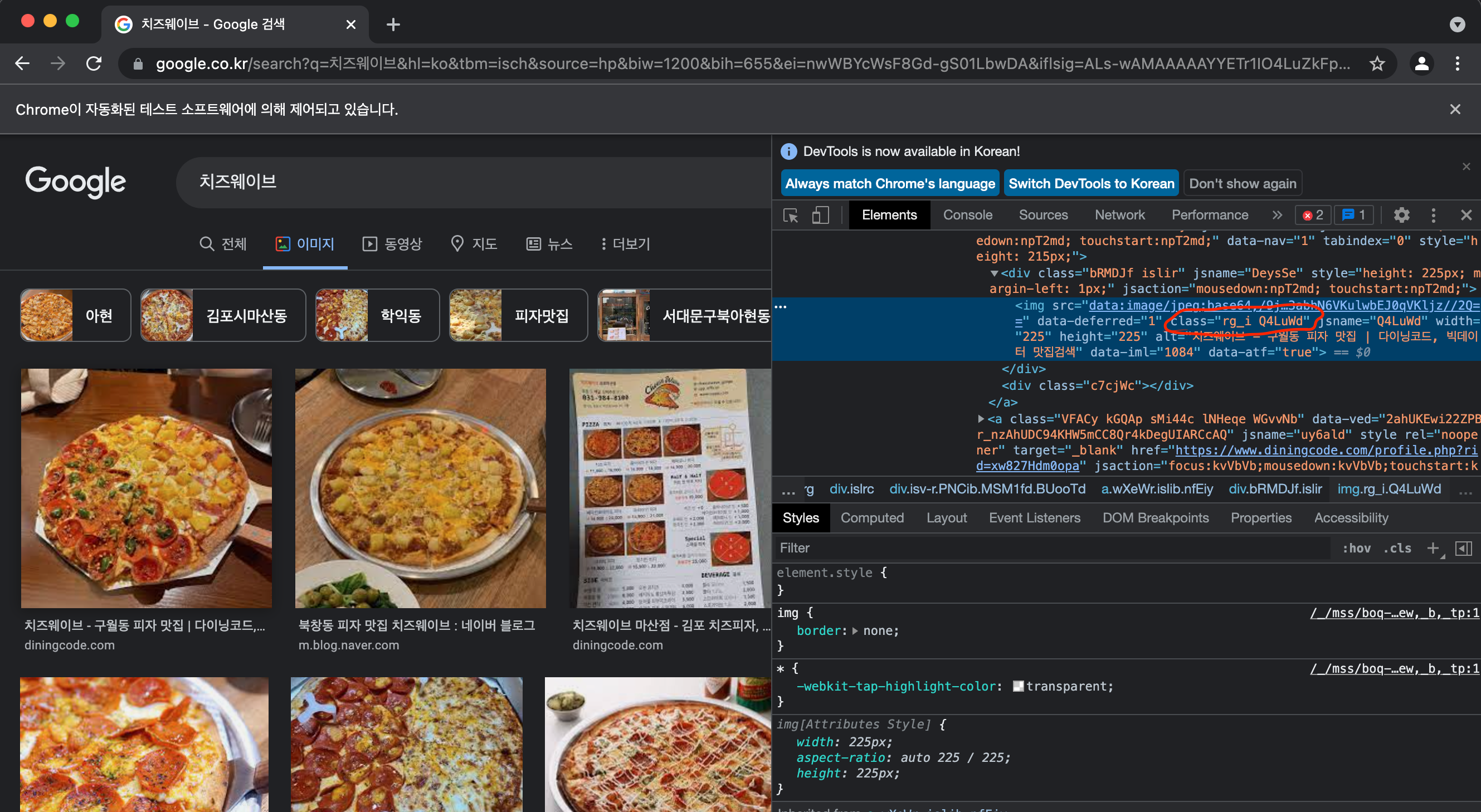
이제 전체 로딩된 이미지를 처음부터 클릭해 나가는 과정을 만들기 위해 class부터 확인해줍니다.class = rg_i Q4LuWd임을 확인 할 수 있었고 반복문을 통해 해당 이미지를 클릭해주는 과정을 만들어줍니다.
images = driver.find_elements_by_css_selector('.rg_i.Q4LuWd') for image in images: image.click()
이제 반복문을 통해 이미지들을 눌러주는 작업을 만들었으니 이미지를 눌렀을때 나오는 상세이미지에서 src를 빼내 다운로드 받는 작업을 만들어 줍니다.
그 전에 상세이미지의 class를 확인해줍니다.
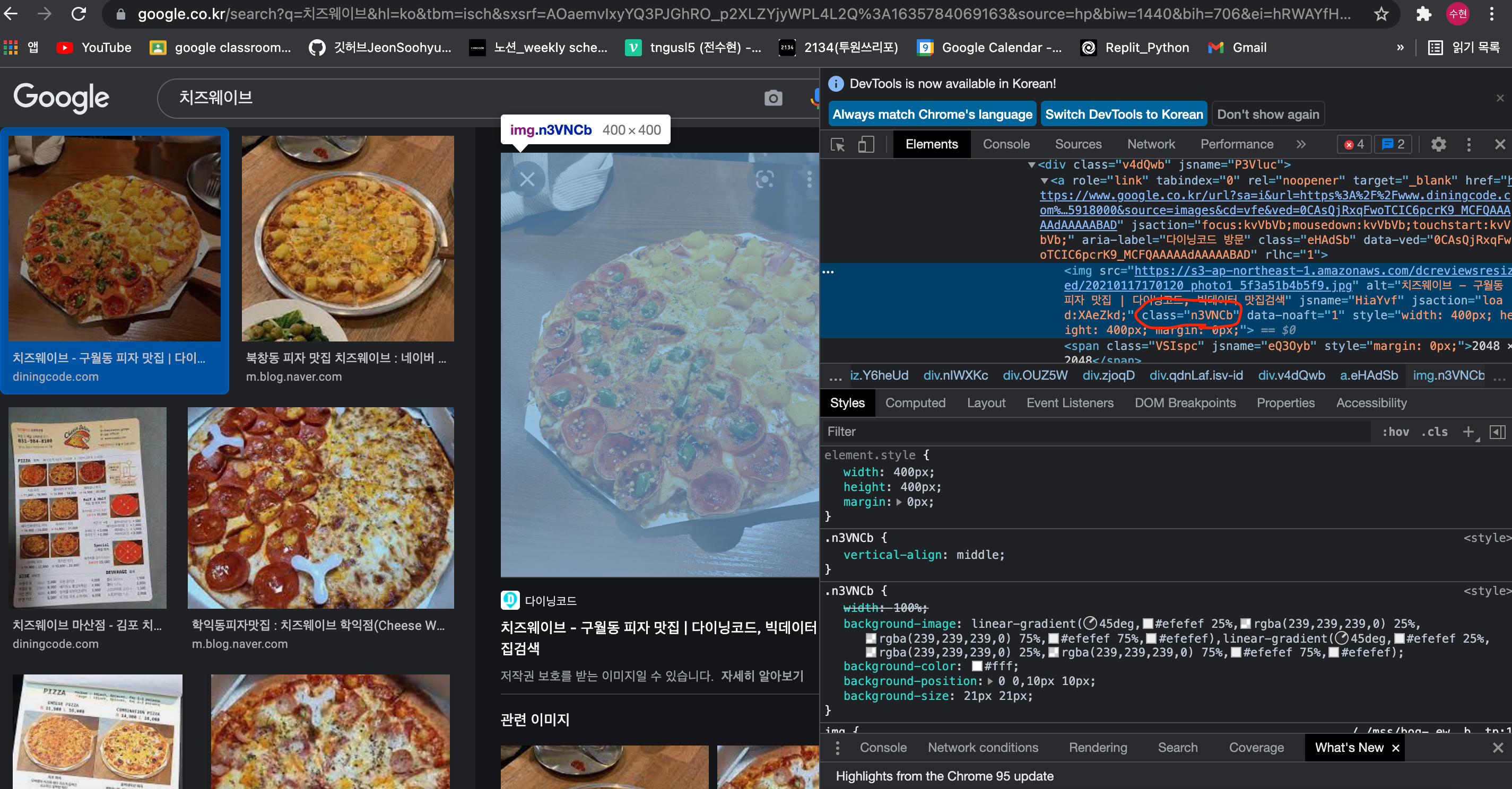
상세이미지의 class가 n3VNCb임을 확인 하였고, 이제 반복문을 통해 클릭을 하고 상세이미지 클래스를 찾아 src를 빼내어 다운로드해주는 작업을 진행하도록 하겠습니다.
images = driver.find_elements_by_css_selector('.rg_i.Q4LuWd') count = 1 for image in images: try: image.click() time.sleep(2) imgUrl = driver.find_element_by_css_selector('.n3VNCb').get_attribute('src') urllib.request.urlretrieve(imgUrl, str(count)+'.jpg') count = count + 1 except: pass
우선 image.click()을 한 뒤 상세이미지가 로딩 되기까지 time.sleep(2)로 잠시 break를 걸어줍니다.
이 후 상세이미지 클래스를 찾은 뒤 .get_attribute('src')를 통해 src를 빼내어 imgUrl이라는 변수에 담아줍니다.
urllib이라는 다운로드를 받는데 도움을 주는 모듈을 불러와 urllib.request.urlretrieve(imgUrl, str(count)+'.jpg') 을 통해 다운로드를 진행해줍니다. 이때 파라미터에는 아까 src를 담아준 imgUrl과 다운로드 된 파일의 이름을 지정해주는 항목을 넣어줍니다.
count는 반복문을 통해 1씩 늘어나게 해주어 파일의 이름으로 지정하기 위해 써주었습니다. ex) 1.jpg, 2.jpg, 3.jpg
이제 파일을 실행해줍니다.
python google.py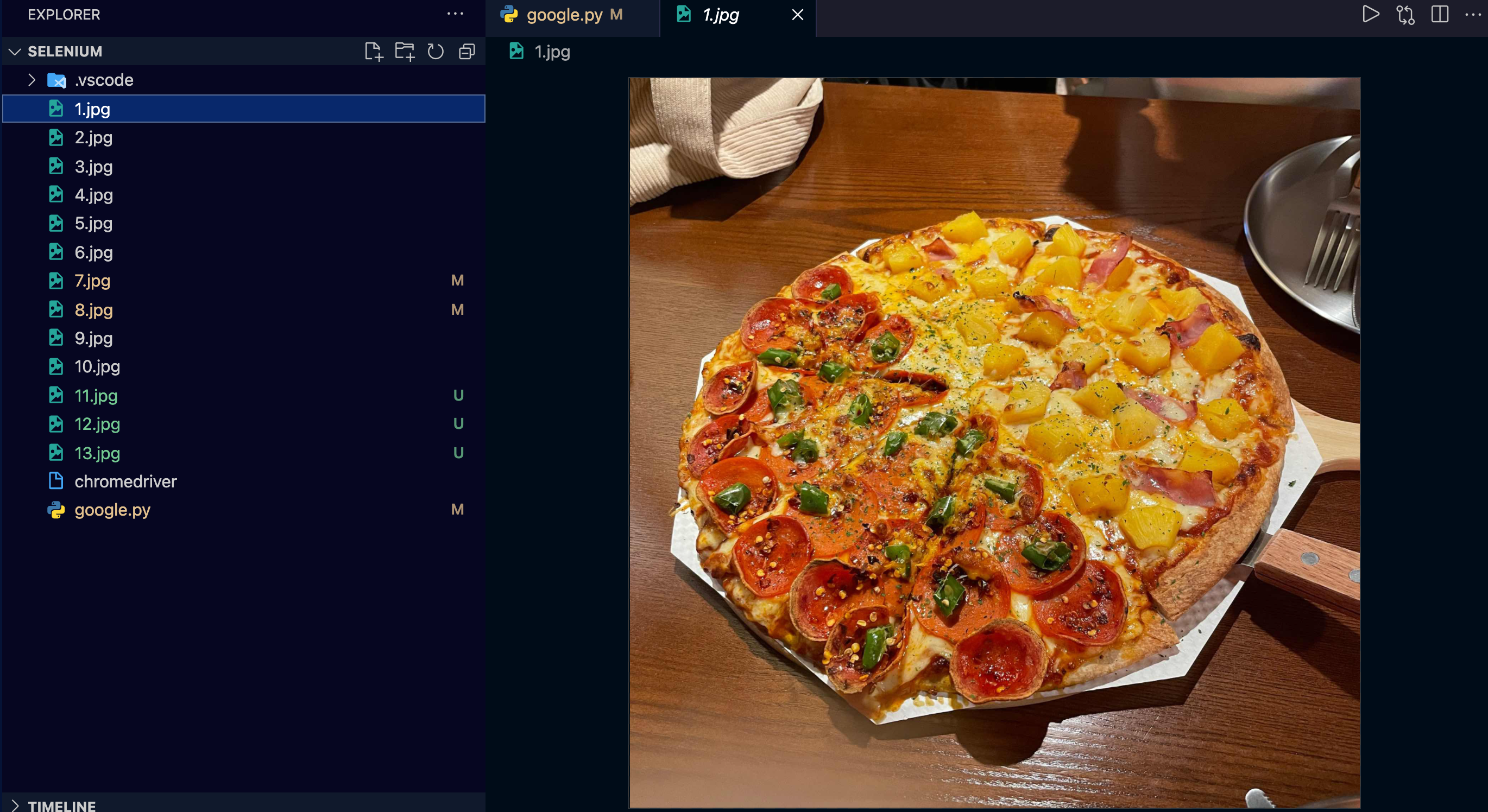
시간 상 전부 받지는 않았지만 위처럼 하나씩 증가하며 다운로드 되는 모습을 볼 수 있습니다.
전체 과정!
.gif)
굉장히 허접하지만 나름 재밌었던 크롤링 이였습니다~~끝!
