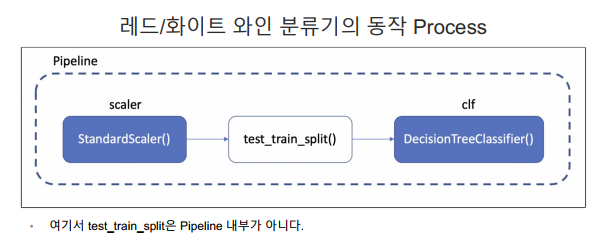
Pipeline
지금까지 불편한 점
- 단순히 Iris, Wine 데이터를 받아서 사용했을 뿐인데 직접 공부하면서 코드를 하나씩 실행해보면 혼돈이 크다는 것을 알 수 있다.
- Jupyter Notebook 상황에서 데이터의 전처리와 여러 알고리즘의 반복 실행, 하이퍼 파라미터의 튜닝 과정을 번갈아 하다 보면 코드의 실행 순서에 혼돈이 있을 수 있다.
- 이런 경우 클래스(class)로 만들어서 진행해도 되지만, sklearn 유저에게는 꼭 그럴 필요없이 준비된 기능이 있다. → Pipeline
와인 데이터 활용하기
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url ='https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
X = wine.drop(['color'], axis=1)
y = wine['color']pipeline 코드로 구현하기
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())]
pipe = Pipeline(estimators)steps 확인하기
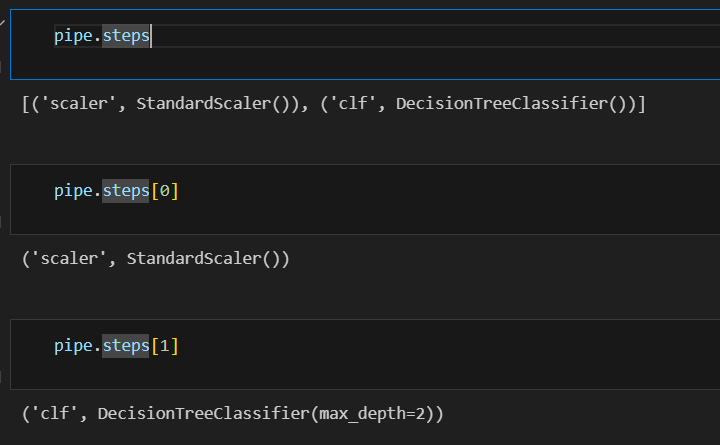
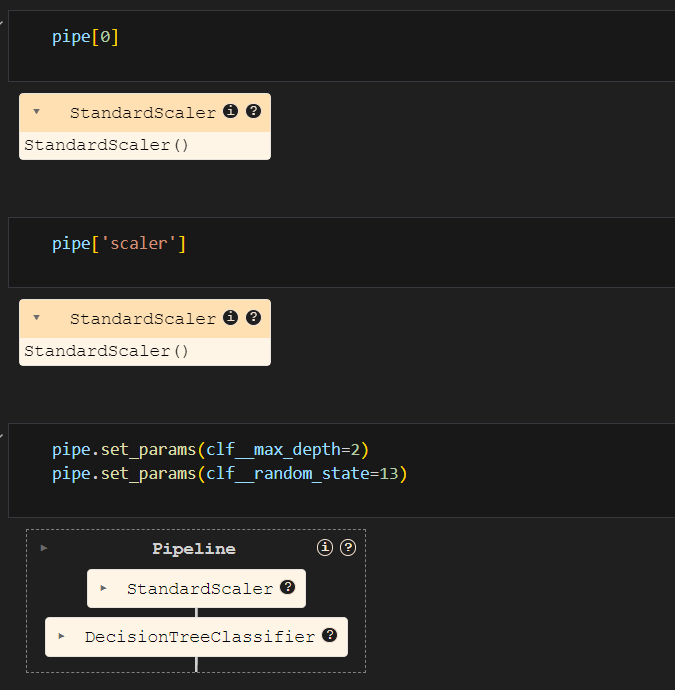
pipeline을 이용한 분류기 구성
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13, stratify=y)
X_train
fit
pipe.fit(X_train, y_train)성과
from sklearn.metrics import accuracy_score
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print('Train ACC : ', accuracy_score(y_train, y_pred_tr))
print('Train ACC : ', accuracy_score(y_test, y_pred_test))Train ACC : 0.9657494708485664
Train ACC : 0.9576923076923077
KFold
교차검증
- 과적합 : 모델이 학습 데이터에만 과도하게 최적화된 현상.
그로 인해 일반화된 데이터에서는 예측 성능이 과하게 떨어지는 현상 - 지난번 와인 맛 평가에서 훈련용 데이터의 Acc는 72.94,
테스트용 데이터는 Acc가 71.61%였는데, 누가 이 결과가 정말 괜찮은 것인지 묻는다면? - 나에게 주어진 데이터에 적용한 모델의 성능을 정확히 표현하기 위해서도 유용하다
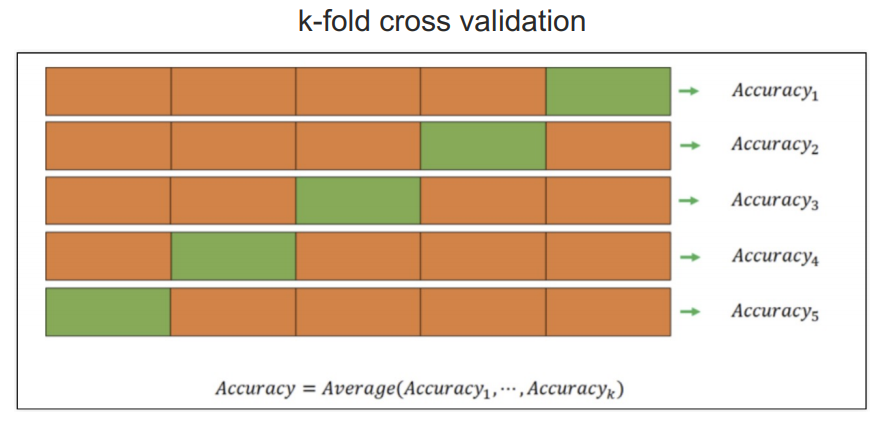
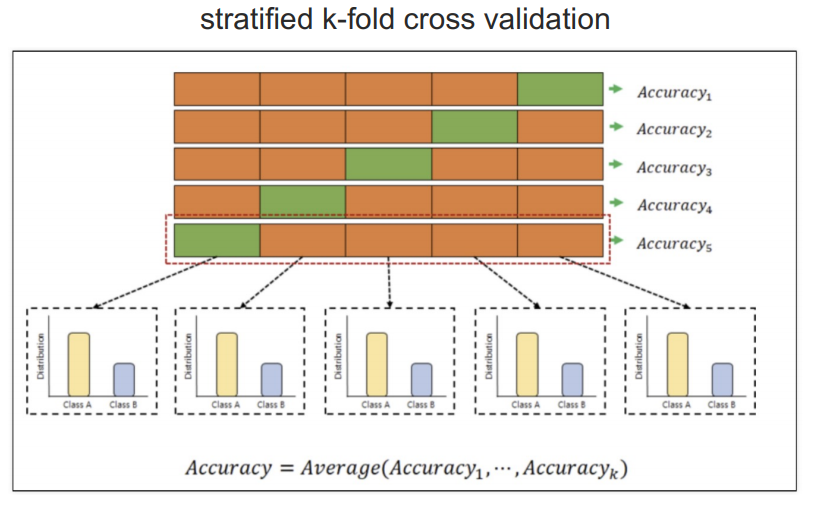
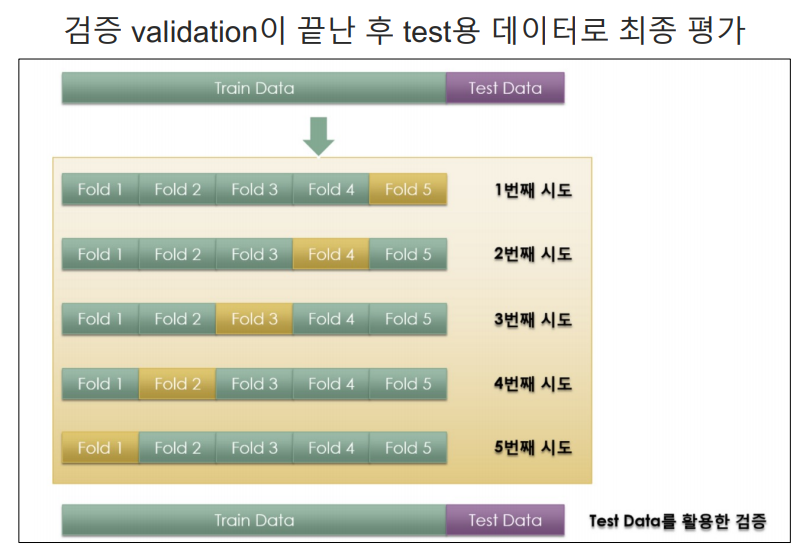
교차검증 구현하기
import numpy as np
from sklearn.model_selection import KFold
x = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
x, y(array([[1, 2],
[3, 4],
[1, 2],
[3, 4]]),
array([1, 2, 3, 4]))
kf = KFold(n_splits=2) # 3, 5등분을 가장 많이 씀
print(kf.get_n_splits(x))
print(kf)2
KFold(n_splits=2, random_state=None, shuffle=False)
for train_idx, test_idx in kf.split(x):
print('--- idx')
print(train_idx, test_idx)
print('--- train data')
print(x[train_idx])
print('--- val data')
print(x[test_idx])--- idx
[2 3][0 1]
--- train data
[[1 2][3 4]]
--- val data
[[1 2][3 4]]
--- idx
[0 1][2 3]
--- train data
[[1 2][3 4]]
--- val data
[[1 2][3 4]]
와인 맛 분류기를 위한 데이터 정리
와인 데이터 활용하기
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url ='https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y= wine['taste']accuracy 확인하기
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print('Train ACC : ', accuracy_score(y_train, y_pred_tr))
print('Test ACC : ', accuracy_score(y_test, y_pred_test))Train ACC : 0.7294593034442948
Test ACC : 0.7161538461538461
데이터 분리가 최선인지? accuracy를 신뢰할 수 있는지?
kFold
from sklearn.model_selection import KFold
Kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)kFold는 index를 반환한다.
for train_idx, test_idx in Kfold.split(X):
print(len(train_idx), len(test_idx))5197 1300
5197 1300
5198 1299
5198 1299
5198 1299
각각의 fold에 대한 학습 후 accuracy
cv_accuracy = []
for train_idx, test_idx in Kfold.split(X):
X_train = X.iloc[train_idx]
X_test = X.iloc[test_idx]
y_train = y.iloc[train_idx]
y_test = y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy[0.6007692307692307,
0.6884615384615385,
0.7090069284064665,
0.7628945342571208,
0.7867590454195535]
평균값
np.mean(cv_accuracy)0.709578255462782
stratifiedKFold
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy = []
for train_idx, test_idx in skfold.split(X, y):
X_train = X.iloc[train_idx]
X_test = X.iloc[test_idx]
y_train = y.iloc[train_idx]
y_test = y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy[0.5523076923076923,
0.6884615384615385,
0.7143956889915319,
0.7321016166281755,
0.7567359507313318]
np.mean(cv_accuracy)0.6888004974240539
accuracy의 평균이 더 나빠짐
cross validation
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)array([0.55230769, 0.68846154, 0.71439569, 0.73210162, 0.75673595])
depth 높이기
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=5, random_state=13)
cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)array([0.50076923, 0.62615385, 0.69745958, 0.7582756 , 0.74903772])
train score
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, cv=skfold, return_train_score=True)
과적합 현상이 나타남
하이퍼파라미터 튜닝
- 모델의 선능을 확보하기 위해 조정하는 설정 값
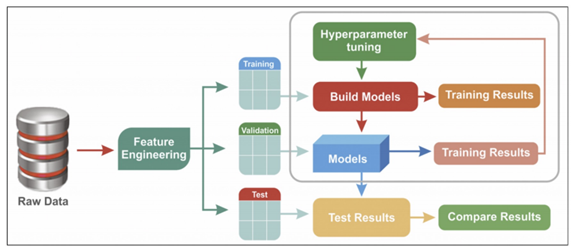
튜닝 대상
- 결정나무에서 아직 우리가 튜닝해 볼만한 것은 max_depth이다.
- 간단하게 반복문으로 max_depth를 바꿔가며 테스트해볼 수 있을 것이다.
- 그런데 앞으로를 생각해서 보다 간편하고 유용한 방법을 생각해보자
와인 데이터 활용하기
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url ='https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y= wine['taste']gridSearchCV
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth' : [2, 4, 7, 10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)fit
# cv = cross validation
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
gridsearch.fit(X, y)gridSearchCV 결과
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(gridsearch.cv_results_)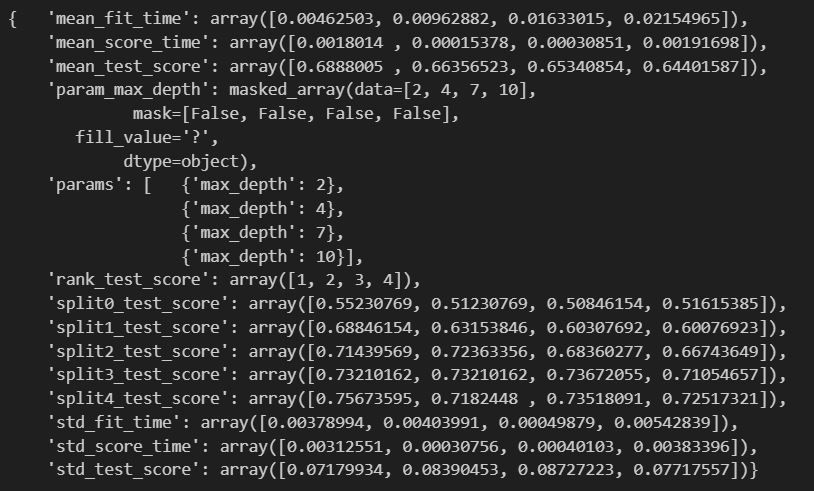
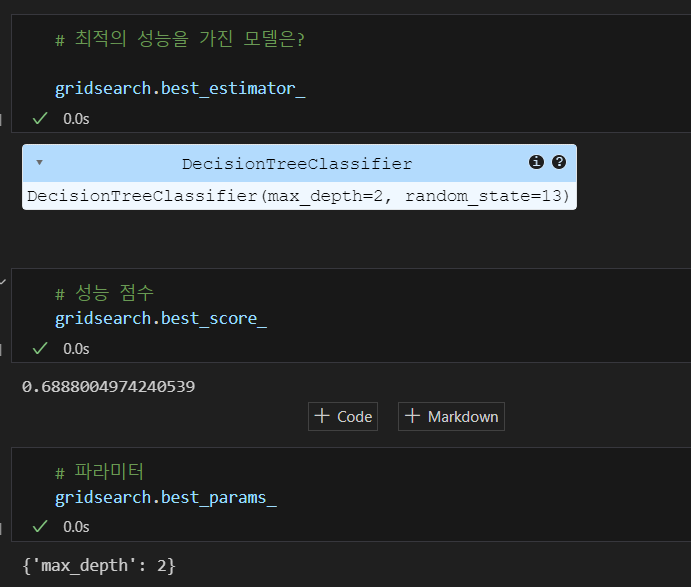
최적의 성능을 가진 모델 확인하기
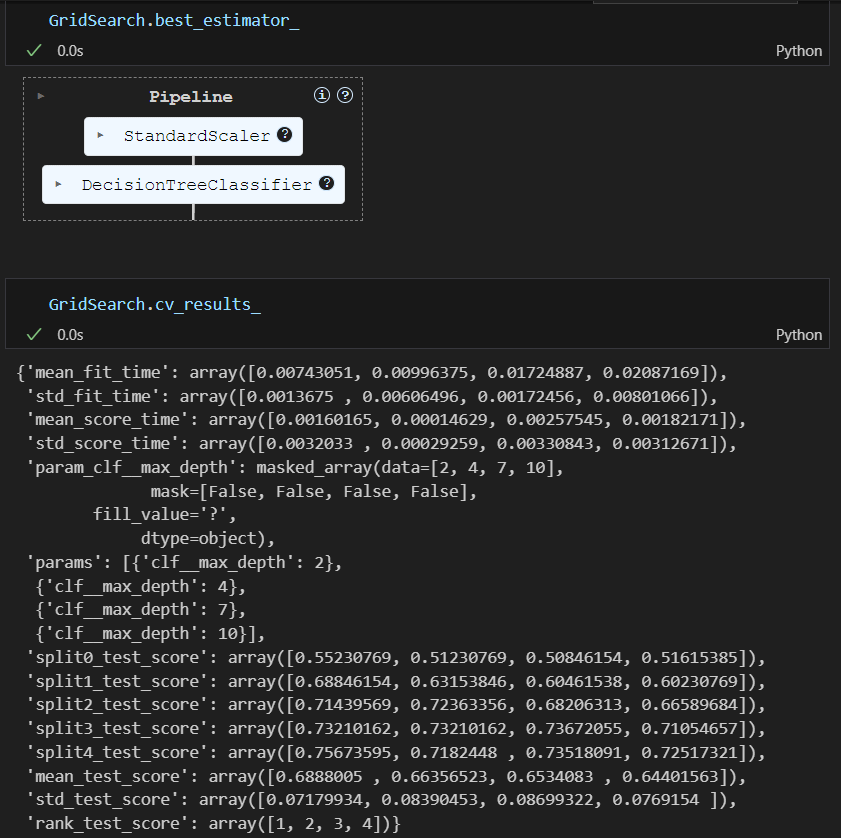
파이프라인에 gridsearch 적용하기
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier(random_state=13))]
pipe = Pipeline(estimators)fit
param_grid = [{'clf__max_depth' : [2, 4, 7, 10]}]
GridSearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
GridSearch.fit(X, y)성능 확인하기
표로 성능 결과 정리하기
import pandas as pd
score_df = pd.DataFrame(GridSearch.cv_results_)
score_df[['params', 'rank_test_score', 'mean_test_score', 'std_test_score']]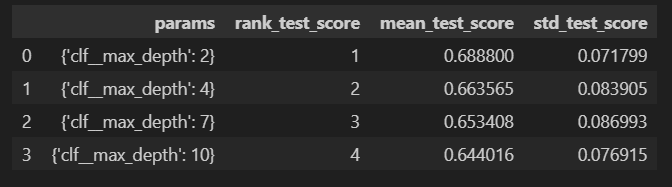
"이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.”
