서울시 CCTV 현황 분석 프로젝트
데이터 출처
데이터 읽기
- pandas로 cvs, 엑셀 파일 읽기
- 파이썬에서 r 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가는 스테로이드를 맞은 엑셀로 표현함
- pandas에서 엑셀 및 텍스트 파일 읽기
- 통상 cvs는 띄어쓰기로 구분되니 그냥 read_csv 명령으로 읽기만 해도된다.
- 긴 파일명을 끝까지 입력하지 말고 적당한 곳에서 tab 키 누르기
- 한글은 encoding 설정이 필수

데이터 이름 바꾸기
- inplace=Ture : 바꾼 속성 파일에 바로 저장하기

- rename() : 인덱스 속성 바꾸기 (이름 바꾸기)
- rename() 사용해서 해당 인덱스에 위치한 칼럼 이름 바꾸기 가능
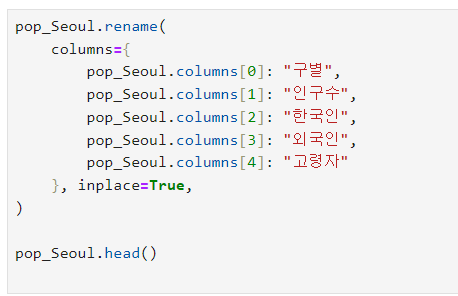
- header=n : 가지고 오고 싶은 n행부터 가져오기
- usecols="" : 가지고 오고 싶은 ""열만 가져오기

Pandas 기초
- pandas는 통상 pd
- numpy는 통상 np
Series
- pandas의 데이터형을 구성하는 기본
- index와 value로 이루어져 있습니다.
- 한 가지 데이터 타입만 가질수 있습니다.
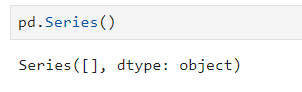
[다른 데이터 타입과 있을 시 object로 출력 ]
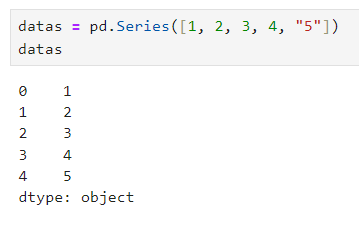
날짜 데이터
- data_range : 날짜와 시간 이용 가능
- "20240402"를 시작으로 6개 출력
DataFrame
-
pd.Series()
- index, value -
pd.DataFrame()
- index, value, column -
pandas DataFrame의 구조
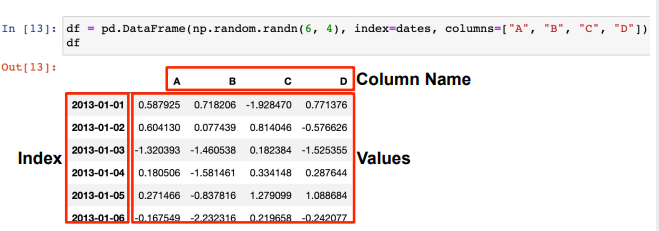
-
random.randn(a, b) : 표준정규분포도에서 샘플링한 난수 생성(행, 열)
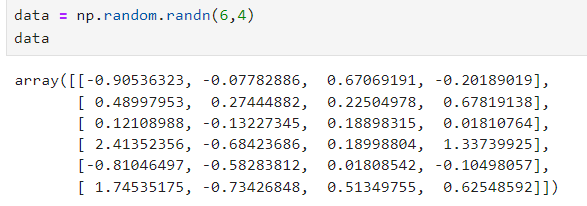
-
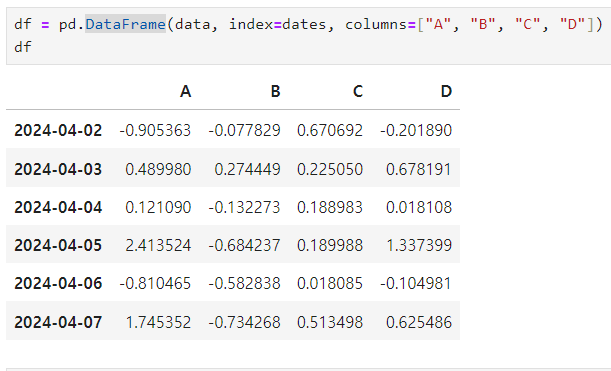
DataFrame 만들기
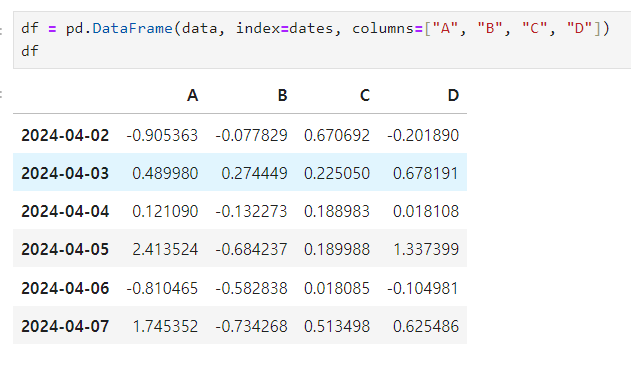
데이터 프레임 정보 탐색
- head() : 상단 5개 출력, ()안에 숫자 입력시 숫자만큼 출력
- tail() : 하단 5개 출력, ()안에 숫자 입력시 숫자만큼 출력
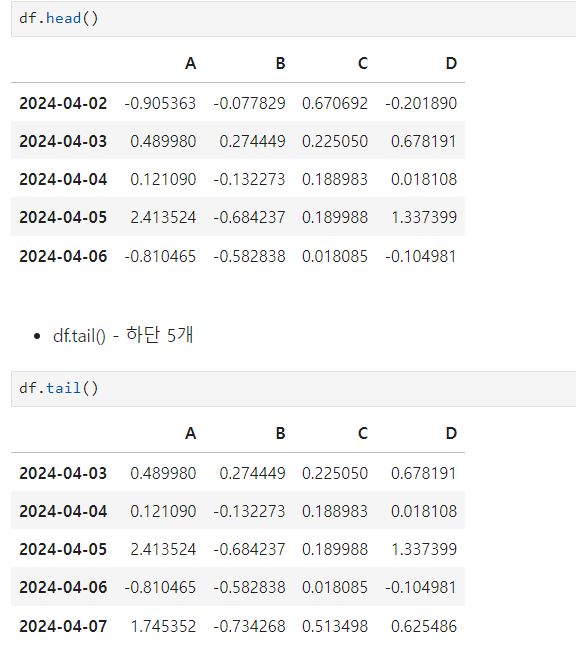
- index() : 행 출력
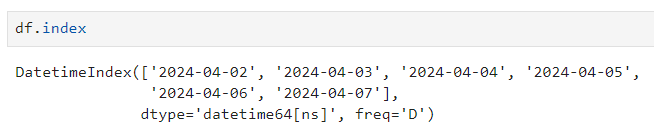
- columns / columns[n] :인덱스 출력 / [n]번째 인덱스만 출력
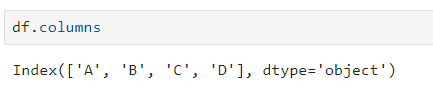
- values : 행과 열 안의 값 출력
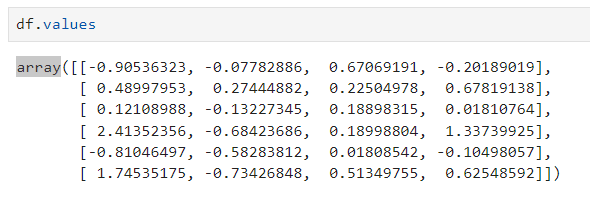
- info() : 데이터 프레임의 기본 정보 확인
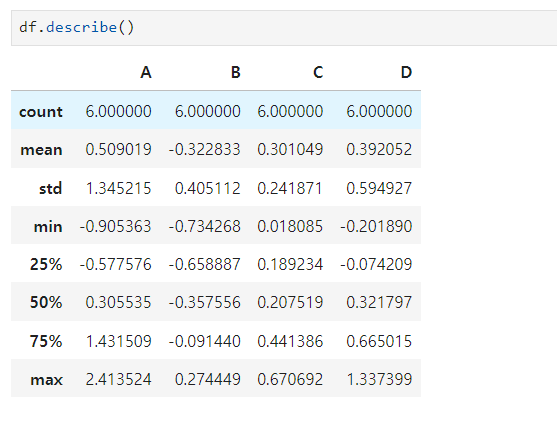
- describe() : 데이터 프레임의 기술 통계 정보 확인
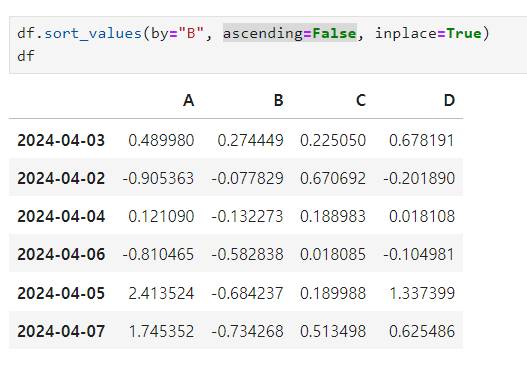
데이터 정렬
- sort_values() : 특정 컬럼(열)을 기준으로 데이터를 정렬함
- 기본값(오름차순) : ascending=Ture
- 내림차순 : ascending=False
[B를 기준으로 내림차순 출력하기⬇️]
데이터 선택
- df.["A"] : 한 개 컴럼 선택
- df.[["A", "B"]] : 두 개 이상의 컬럼 선택시 리스트 안에 담아주기
- 데이터를 선택해서 DataFrame 만들기
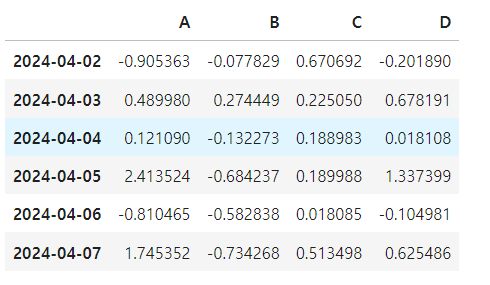
offsest index
[기존 dataframe]
-
[n:m] : n부터 m-1 까지
-
인덱스나 컬럼 이름으로 slice 하는 경우 끝을 포함한다.
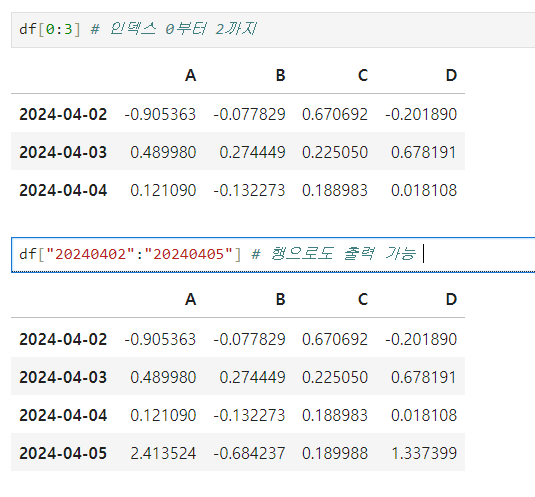
-
loc (location) : pandas의 보편적인 slice 옵션
-
df.loc[ : , [”A”, “B”]] : 모든 행의 열 A,B 칼럼만 선택
-
index 이름으로 특정 행, 열 선택
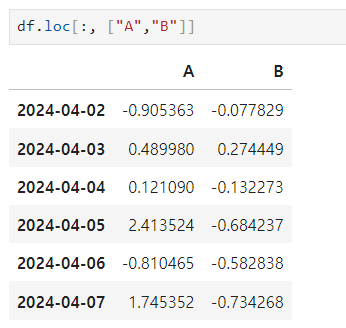
-
iloc (inter locatio) : 컴퓨터가 인식하는 인덱스 값으로 선택
-
df.iloc[] : iloc 옵션을 이용해서 번호로만 접근 ⇒ 해당 행에 접근
-
df.iloc[3:5, 0:2] : 3,4 행과 1,2열만 보여주기
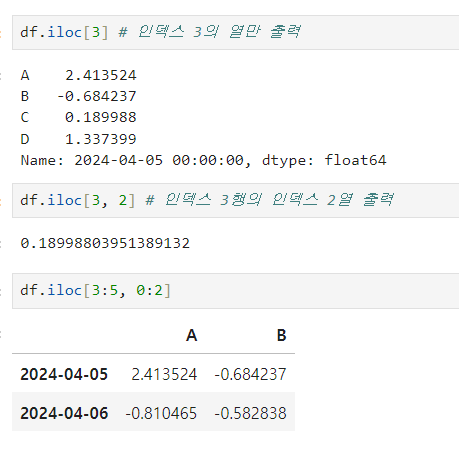
condition
- 조건문
- df[df[”A”] > 0] : A열의 0보다 큰 경우만 출력
- df[df > 0] : 모든 행과 열의 0보다 큰 경우만 출력
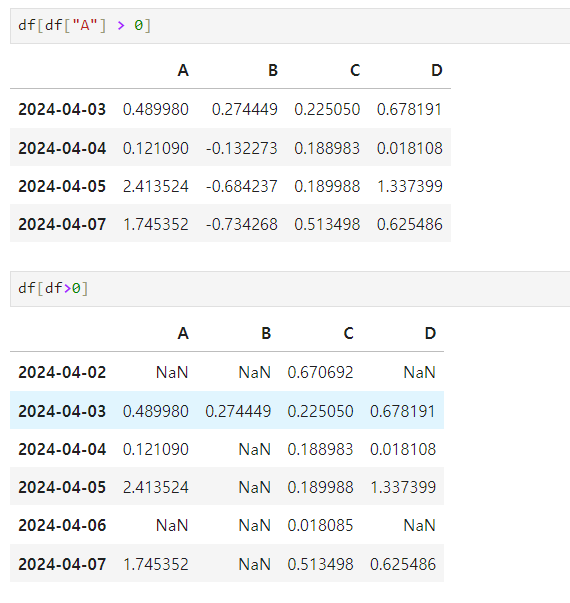
- NaN : 데이터가 없다는 뜻 not a number
칼럼 추가
-
기존 컬럼이 없으면 추가
-
기존 컬럼이 있으면 수정
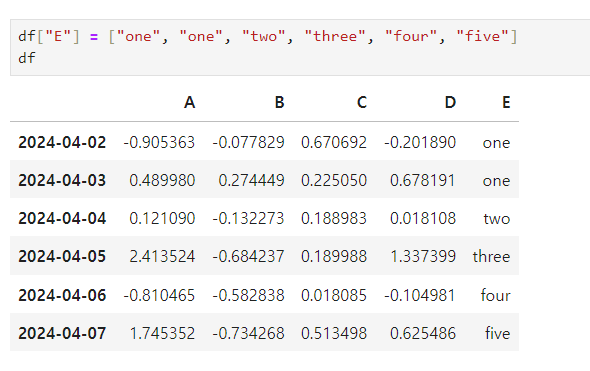
-
isin() : 특정 요소가 있는지 확인 후 출력
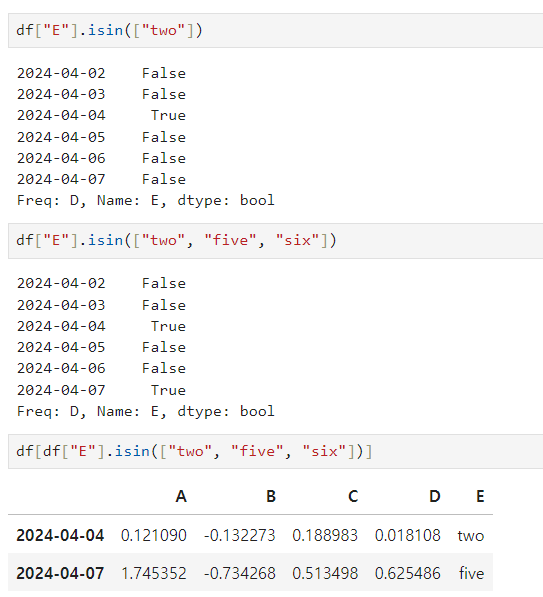
특정 컬럼 제거
-
del
-
drop
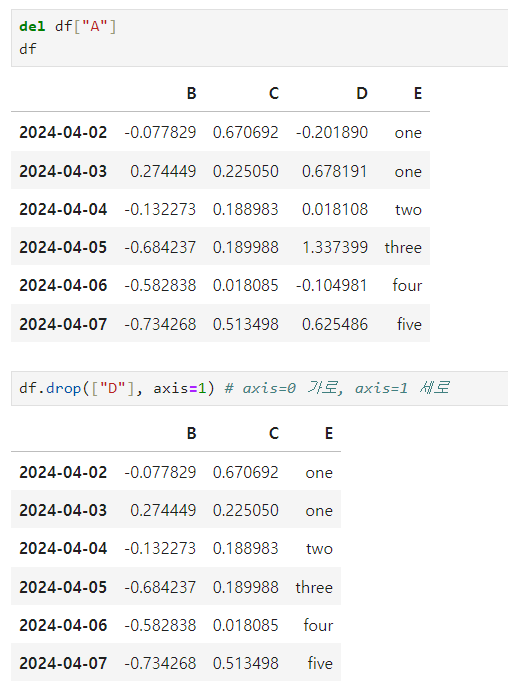
-
apply() : 각 칼럼 누적합 ⇒ 함수를 적용
-
numpy 함수도 사용 가능
- df["B"].apply("sum") : B열 값의 합
- df["B"].apply("mean") : B열 값의 평균
- df["B"].apply("min"), df["B"].apply("max") : B열 값 중 작은 수, B열 값 중 큰 수
- df[["C","D"]].apply("sum") : C와 D 각각의 합
-
각 숫자의 양수와 음수 구별하기

두 데이터 합치기
pandas에서 데이터 프레임을 병합하는 방법
- pd.concat()
- pd.join()
- pd.merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 함
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어야 함
-
left, right dataframe 만들기
left = 딕셔너리 안에 리스트 형태
right = 리스트 안에 딕셔너리 형태
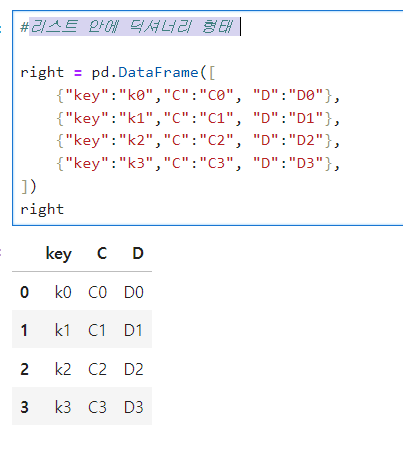
-
pd.merge를 사용해서 데이터 합치기
- on : 기준 key 값 (on은 공통된 key 값을 가진 dataframe끼리 합칠 수 있음)
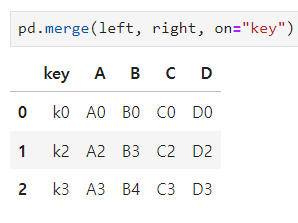
- how 옵션 사용하기
-
how="inner" 기본값
-
how=”left” : left에 키를 기준으로 right 병합 (공통 칼럼만 병합)
-
how=”right” : right에 키를 기준으로 left 병합 (공통 칼럼만 병합)
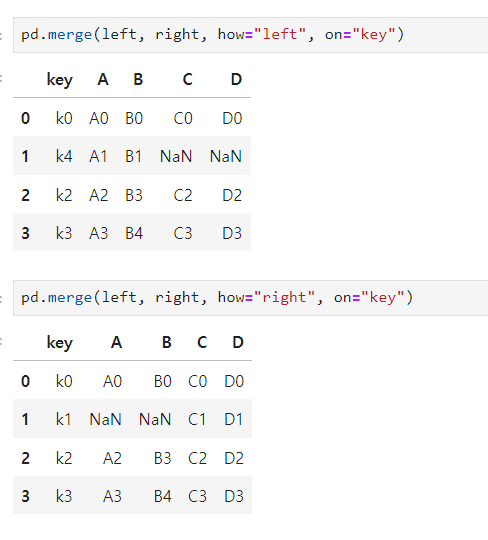
-
how=”outer” : 둘 다 손상되지 않도록 key를 기준으로 병합
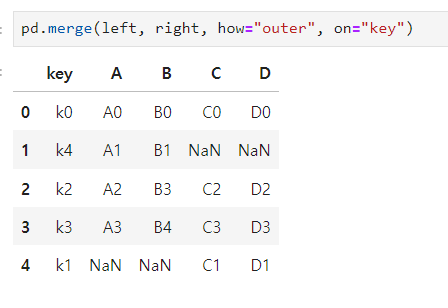
데이터를 병합하고 정리하기
- pandas index 지정
- 데이터를 정리하는 과정에서 index를 재지정할 때가 있다.
- 여기서는 unique한 데이터인 구별로 index를 잡자
- index를 재지정하는 명령어는 set_index이다
- set_index : 선택한 컬럼을 데이터 프레임의 인덱스로 지정 (인덱스 변경)
“이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.”
