서울시 범죄 현황 데이터 분석 프로젝트
python 반복문
for n in range(0,10):
print(n**2)
=> 위 코드를 한 줄로 : list comprehension
[n ** 2 for n in range(0,10)]iterrows()
- pandas에 잠 맞춰진 반복문 용 명령
- pandas 데이터 프레임은 대부분 2차원
- 이럴땐 for문을 사용하면 n번째라는 지정을 반복해서 가독률이 떨어짐
- pandas 데이터 프레임으로 반복문을 만들때 iterrows() 옵션을 사용하면 편함
- 받을때, 인덱스와 내용으로 나누어 받는 것만 주의
현재 index는 경찰서 이름으로 되어 있고 추후 경찰서 이름으로 구 이름을 알아내야 한다.
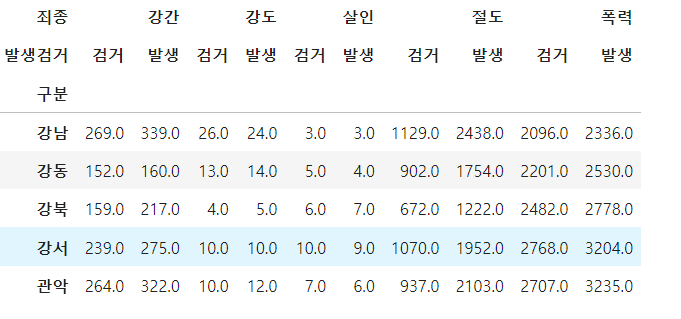
- google map API 설치
- import google
- geocode()로 알고 싶은 위치의 정보 알아내기
구글 맵을 이용한 데이터 정리
구글 맵 api 불러오기
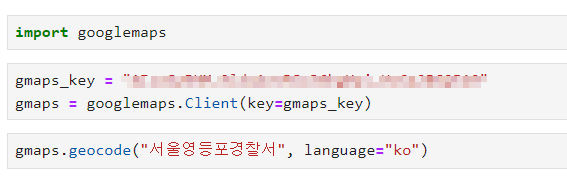
- 변수 tmp 지정
- get()으로 컬럼의 형태 알기
- split() : 문자열 쪼개기
구별, lat, lng 컬럼 NaN 값으로 추가
- 경찰서 이름에서 소속된 구이름 얻기 -> 인덱스로 먼저 확인하기
- 구이름과 위도 경도 정보를 저장할 준비
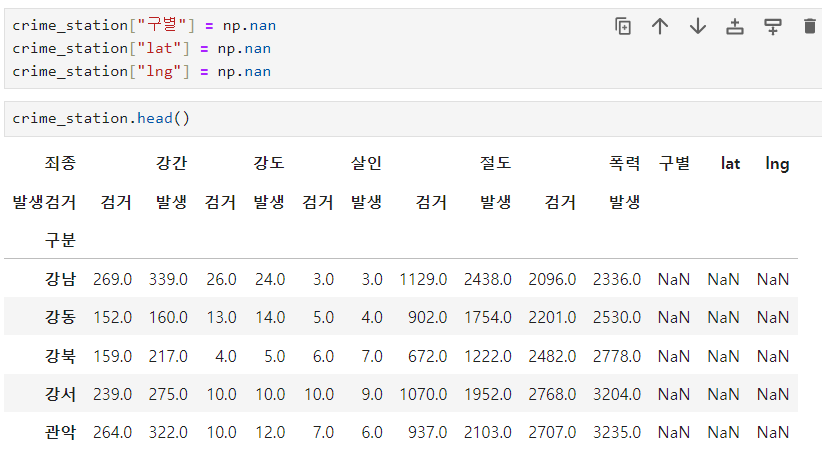
반복문을 이용해서 위 표의 Nan을 모두 채워주기 => iterrows()
for idx, rows in crime_station.iterrows(): station_name = "서울" + str(idx) + "경찰서" tmp = gmaps.geocode(station_name, language="ko") tmpgu = tmp[0].get("formatted_address") lat = tmp[0].get("geometry")["location"]["lat"] lng = tmp[0].get("geometry")["location"]["lng"] crime_station.loc[idx, "lat"] = lat crime_station.loc[idx, "lng"] = lng crime_station.loc[idx, "구별"] = tmpgu.split()[2]
- get_level_values() : 컬럼 이름 합치기
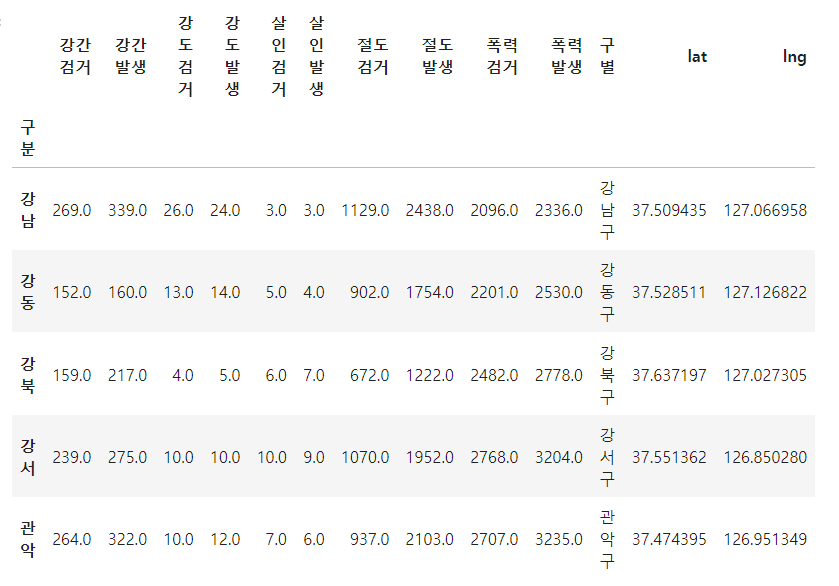
구별 데이터 정리
- index_col=0 : 인덱스 0 컬럼으로 설정
=> 원하는 인덱스로 데이터 불러오기- 검거율 생성
- 하나의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu["강도검거"] / crime_anal_gu["강도발생"]
- 다수의 컬럼을 다른 컬럼으로 나누기
- div() 활용
crime_anal_gu[["강도검거", "살인검거"]].div(crime_anal_gu["강도발생"], axis=0)
- 다수의 컬럼을 다수의 컬럼으로 각각 나누기
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"] den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"] crime_anal_gu[num].div(crime_anal_gu[den].values).
- 다수의 컬럼을 다수의 컬럼으로 각각 나눈 값을 colunms에 추가
target = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"] num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"] den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"] crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100 crime_anal_gu.head()
- 필요 없는 컬럼 제거
- del, drop 사용하기- rename(dict) 사용해서 칼럼 이름 바꾸기
crime_anal_gu.rename(columns={"강간발생":"강간", "강도발생":"강도", "살인발생":"살인", "절도발생":"절도", "폭력발생":"폭력"}, inplace=True) crime_anal_gu.head()
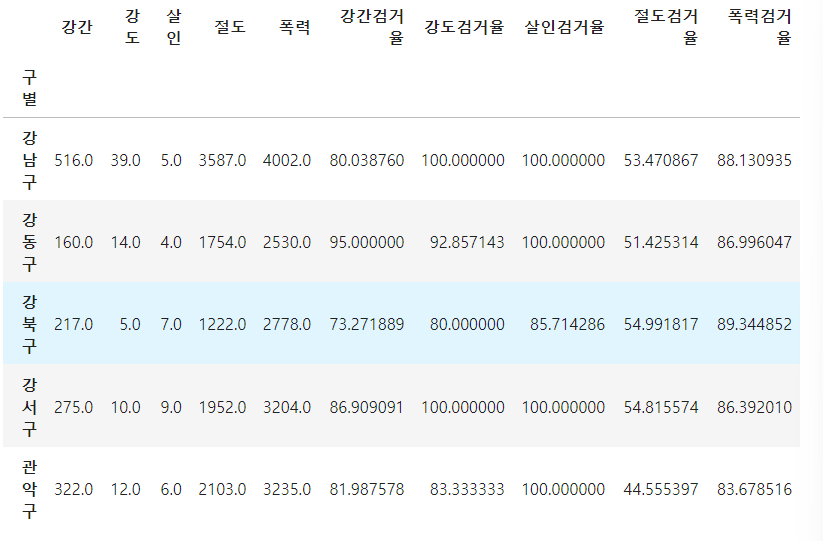
범죄 데이터 정렬을 위한 데이터 정리
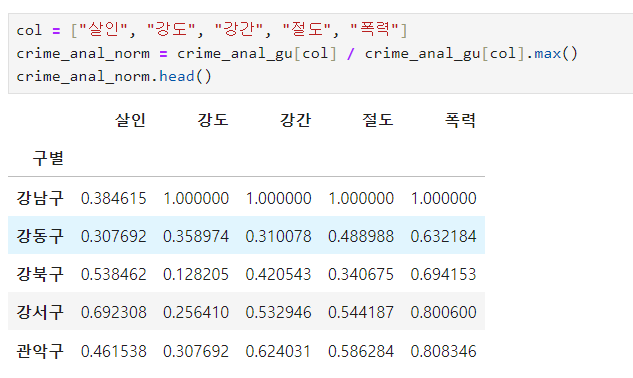
정규화하기
- 정규화 : 최고값은 1, 최소값은 0
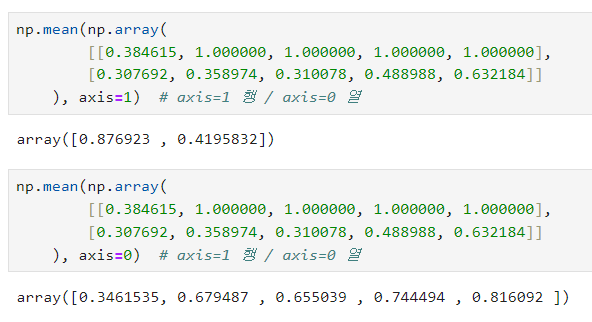
- axis=1 행을 따라서 연산하는 옵션
np.mean()
- axis=1 행 / axis=0 열
“이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.”

데이터 공부 기록