서울시 범죄 현황 데이터 분석 프로젝트
데이터 출처
데이터 읽기
- thousands="," : 숫자값을 문자로 인식 할 수 있어서 설정
- 숫자 값들이 콤마(,)를 사용하고 있어서 문자로 인식됨
- 콤마를 제거하고 숫자형으로 읽음
- encoding="euc-kr" : 인코딩시 한글 깨짐 처리
crime_raw_data = pd.read_csv("../data/02. crime_in_Seoul.csv", thousands=",", encoding="euc-kr") crime_raw_data.head()
- info() : 데이터 개요 확인하기
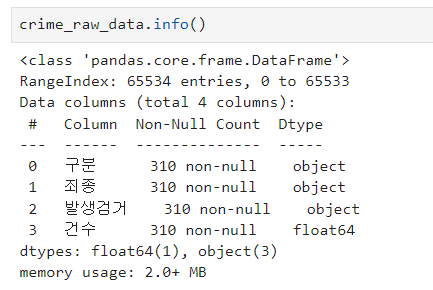
- RangeIndex가 65534인데, 우리가 가진 데이터는 310개이다.
- unique() : 특정 컬럼에서 조사 후 NaN 값 확인하기
- isnull() : null 값을 bool 타입으로 출력
- notnull() : null 값이 아닌 것만 출력
- 출력 후 데이터 전처리 -> 로우데이터에 저장하기
pandas pivot table
아래 데이터 활용하기
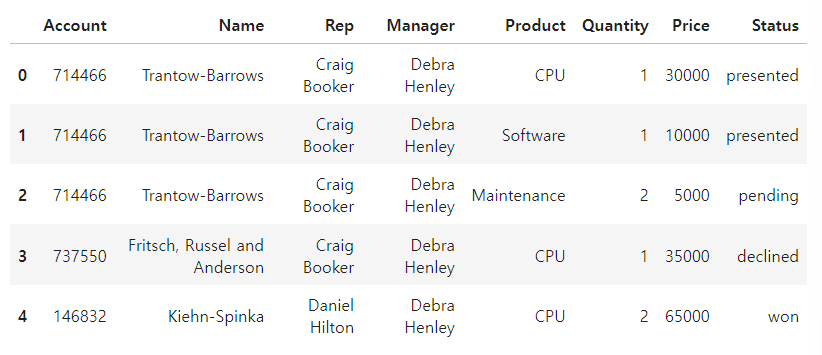
pivot_table 구성
- index : 2개 이상 지정 가능
- column : 분류 지정
- values : 2개 이상 지정 가능, value에 함수를 지정할 수 있음, default = mean
- aggfunc : 2개 이상 지정 가능, 합산 등의 다른 함수를 적용할 때 옵션을 지정
index 설정
- index 설정시 같은 데이터 타입의 values 설정하기
아래 두 코드는 같은 코드 값 pd.pivot_table(df, index="Name", values=["Account", "Quantity", "Price"]) df.pivot_table(index="Name", values=["Account", "Quantity", "Price"])
- 멀티 인덱스 설정
df.pivot_table(index=["Manager", "Rep"], values=["Account", "Quantity", "Price"])

values 설정
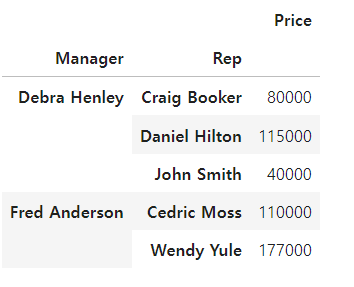
- aggfunc 연산 함수 활용하기
- Price 컬럼 sum 연산 적용
- len : 갯수 구하기
df.pivot_table(index=["Manager", "Rep"], values="Price", aggfunc=[np.sum, len])
columns 설정
- Product를 컬럼으로 지정
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum)
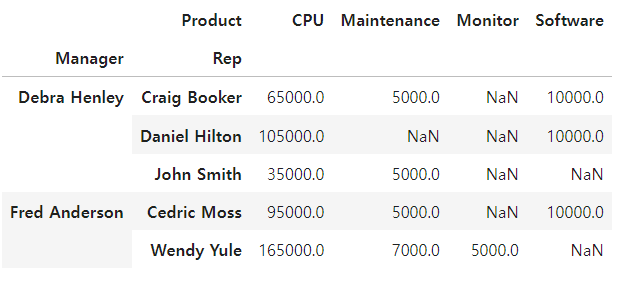
- fill_value : NaN 값 설정
- fill_value=0 : Nan 값을 0으로 채우기
- 2개 이상의 index, values 설정 가능
- aggfunc 2개 이상 설정
- margins : 총계 (All) 추가
df.pivot_table( index=["Manager", "Rep", "Product"], values=["Price", "Quantity"], aggfunc=np.sum, fill_value=0, margins=True)
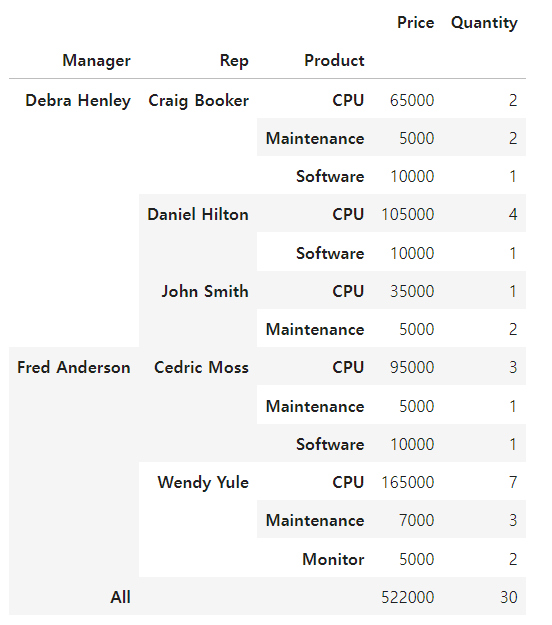
서울시 범죄 현황 데이터 정리
- pivot_table 활용
- index는 경찰서 이름으로 정리
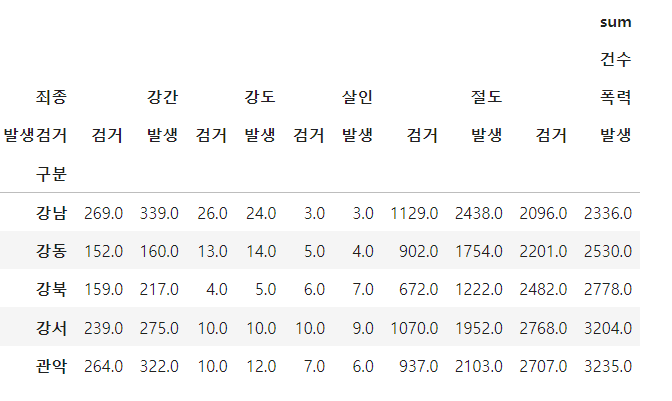
crime_station = crime_raw_data.pivot_table( crime_raw_data, index="구분", columns=["죄종", "발생검거"], aggfunc=[np.sum]) crime_station.head()
- 멀티 인덱스 발생
- multiindex columns 확인하기
- droplevel() : 다중 컬럼에서 특정 컬럼 제거
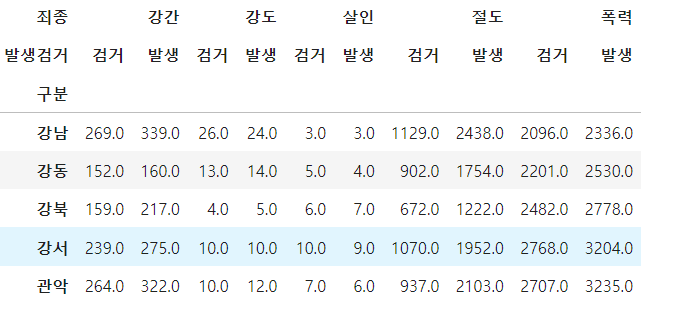
첫 번째, 두 번재 컬럼 제거하기 => sum, 건수 제거 crime_station.columns = crime_station.columns.droplevel([0,1])
“이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.”

데이터 공부 기록