NAVER API
네이버 API 사용 등록하기
- 네이버 api 사용하기 위해 어플리케이션 등록, 클라이언트 id/pw 발급하기
네이버 API 사용하기
-
urllib : http 프로토콜에 따라서 서버의 요청/응답을 처리하기 위한 모듈
-
urllib.request : 클라이언트의 요청을 처리하는 모듈
-
urllib.parse : url 주소에 대한 분석
-
response, response.getcode(), response.code, response.status : HTTP status code 확인
-
네이버 검색 api 예제(블로그 검색)
import os
import sys
import urllib.request
# 발급 받은 클라이언트 id/pw 입력
client_id = "client_id"
client_secret = "client_secret"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)- 글자로 읽을 경우, decode utf-8 설정
print(response_body.decode("utf-8"))- 검색하기
url = "https://openapi.naver.com/v1/search/**blog**?query=" + encText >> bold 문구에 키워드 넣기

크롤링할 상품 "몰스킨" 검색
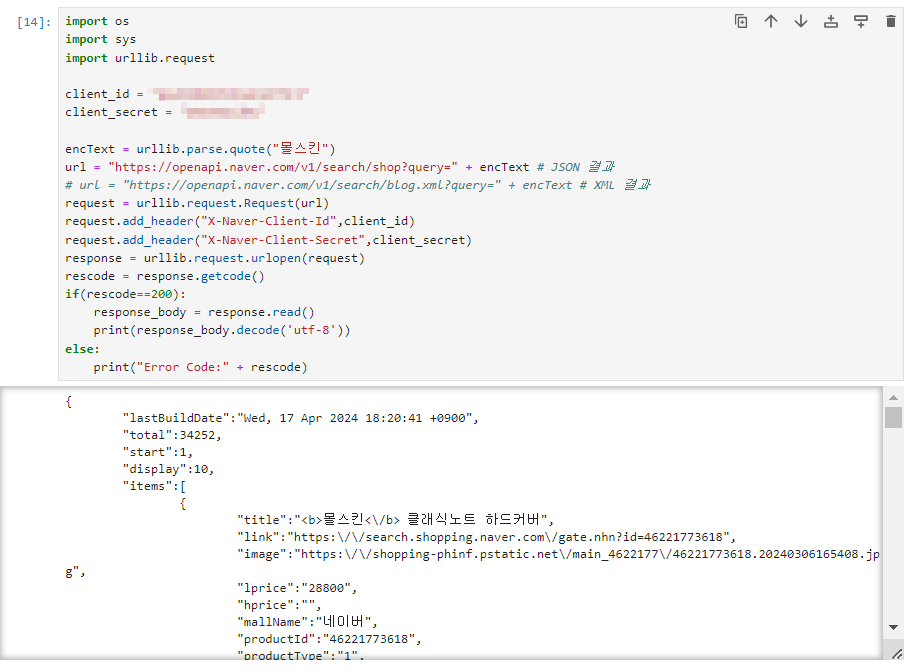
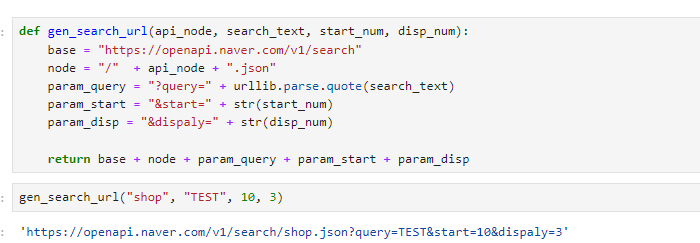
1. gen_search_url()
- url 생성하기
- encText = urllib.parse.quote("몰스킨")
- url = "https://openapi.naver.com/v1/search/shop?query=" + encTex
2. get_result_onepage()
- 몰스킨의 html 코드 긁어오기
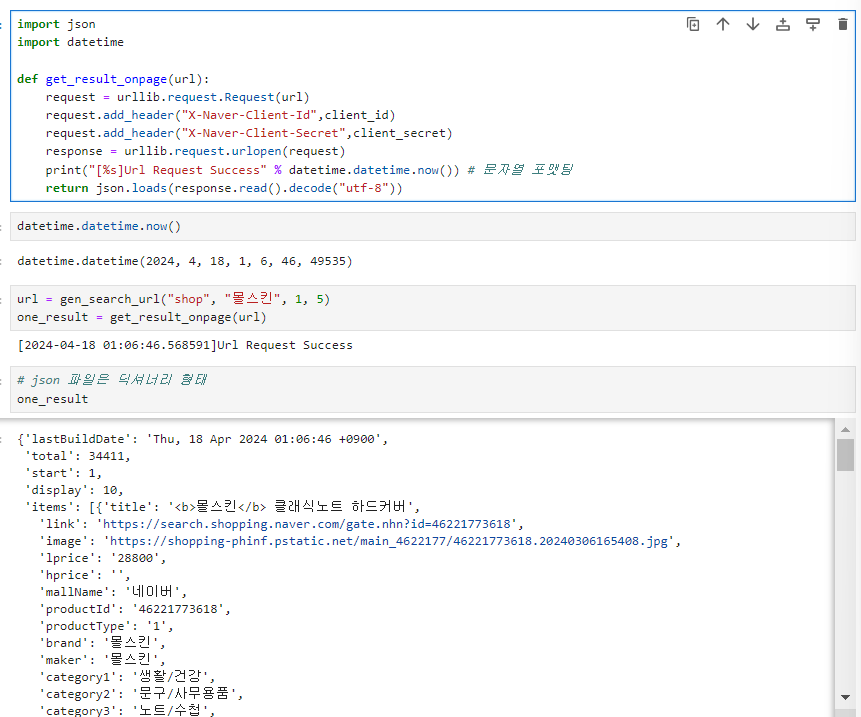
- json 파일은 딕셔너리 형태
# items의 인덱스 0의 타이틀 반환하기
one_result["items"][0]["title"]3. get_fields()
- 데이터 프레임 만들기
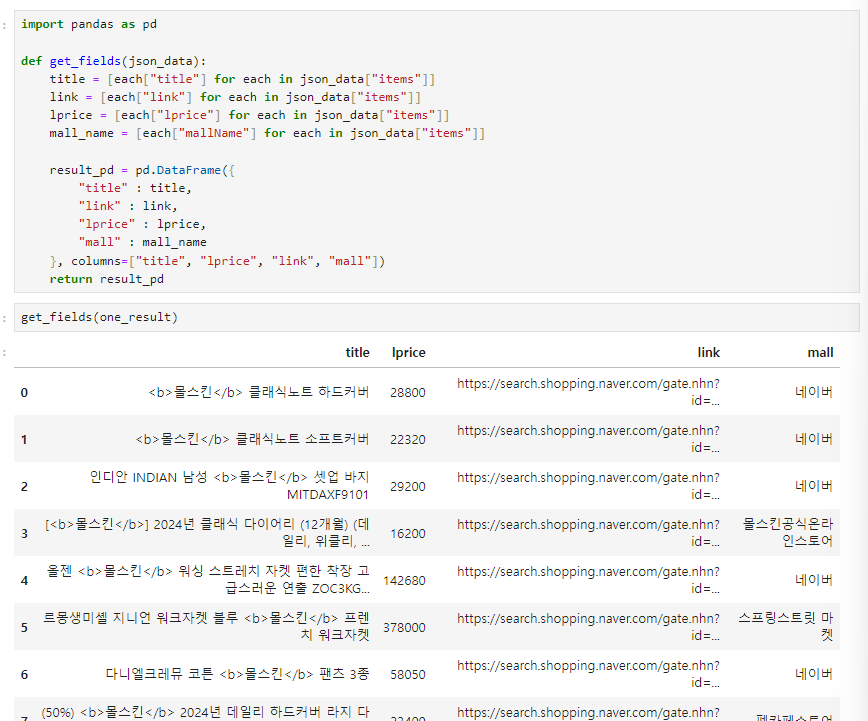
4. delete_tag()
> title <b> </b> 지우기 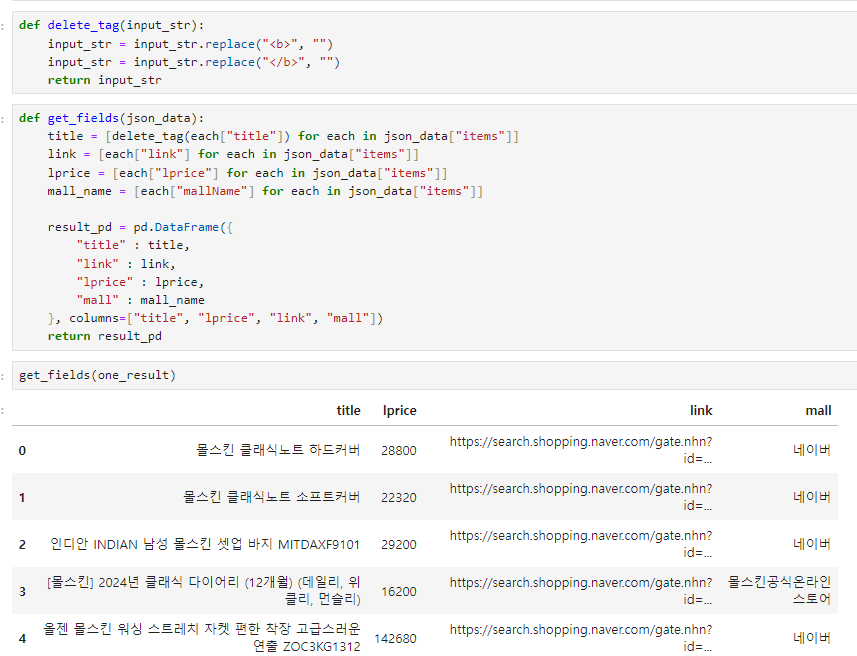
# 변수에 저장하기
url = gen_search_url("shop", "몰스킨", 1, 5)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)5. actMain()
- for문을 활용해서 100개 데이터 저장하기
result_mol = []
for n in range(1, 1000, 100):
url = gen_search_url("shop", "몰스킨", n, 100)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
result_mol = pd.concat(result_mol)-
인덱스 재정렬하기
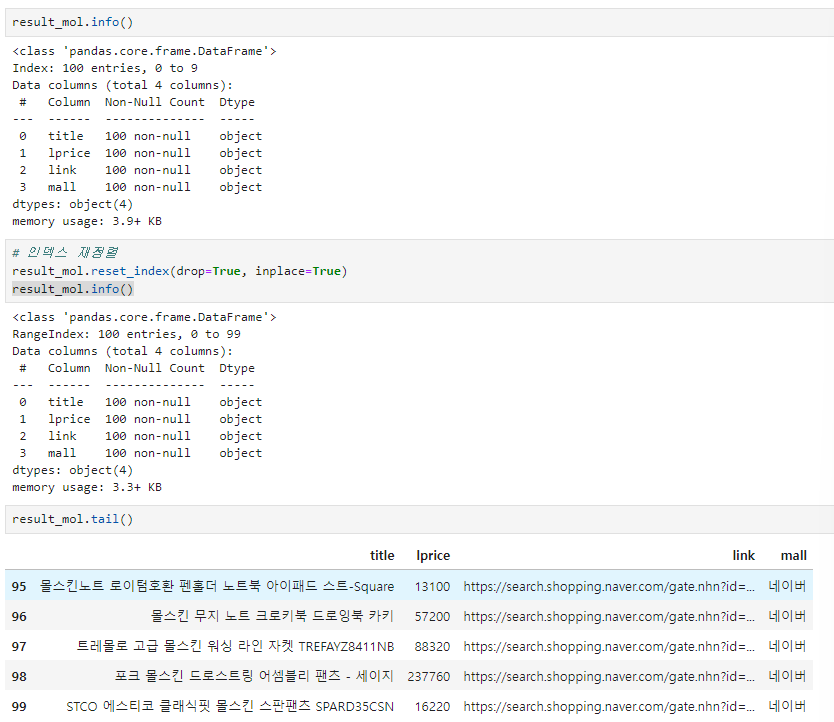
-
lprice type float로 변환하기
result_mol["lprice"] = result_mol["lprice"].astype("float")6. to_excel()
- 엑셀로 저장하기
- 설치 : !pip install xlsxwriter
- 엑셀로 데이터 다룰 때 유용한 코드
writer = pd.ExcelWriter("../data/06_molskin_diary_in_naver_shop.xlsx", engine="xlsxwriter")
result_mol.to_excel(writer, sheet_name="Sheet1")
workbook = writer.book
worksheet = writer.sheets["Sheet1"]
# 각 칼럼에 길이 설정
worksheet.set_column("A:A", 4)
worksheet.set_column("B:B", 60)
worksheet.set_column("C:C", 10)
worksheet.set_column("D:D", 10)
worksheet.set_column("E:E", 50)
worksheet.set_column("F:F", 10)
worksheet.conditional_format("C2:C1001", {"type" : "3_color_scale"})
writer.close()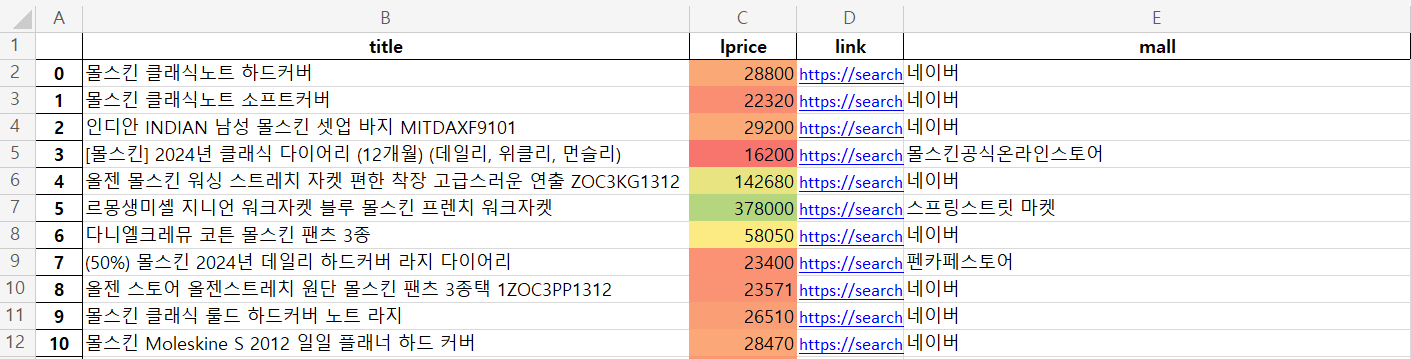
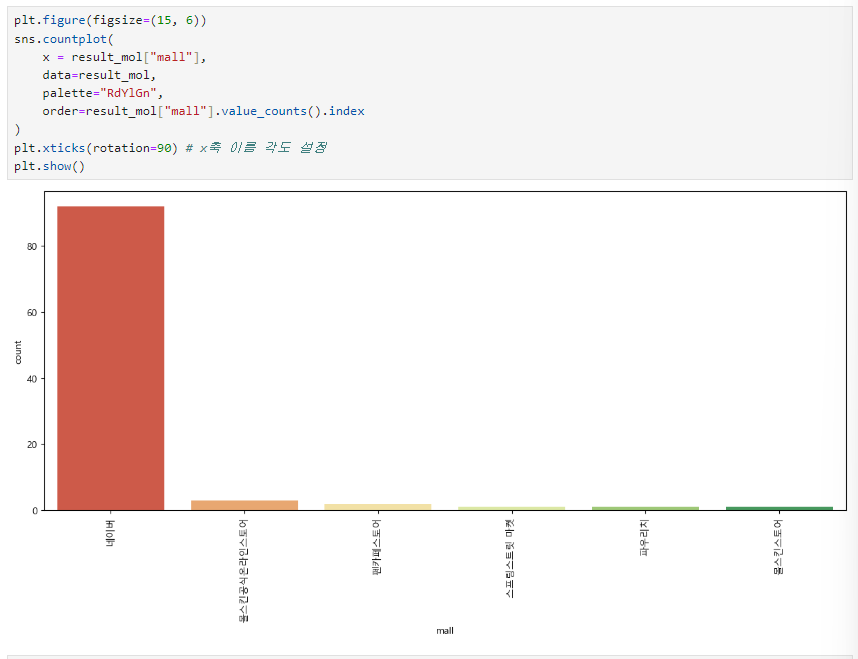
7. 시각화하기
“이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.”

데이터 공부 기록