07. Population
01. 배경
- 목표
- 인구 소멸 위기 지역 파악
- 인구 소멸 위기 지역의 지도 표현
- 지도 표현에 대한 카르토그램 표현
02. 데이터 읽고 인구 소멸 지역 계산하기
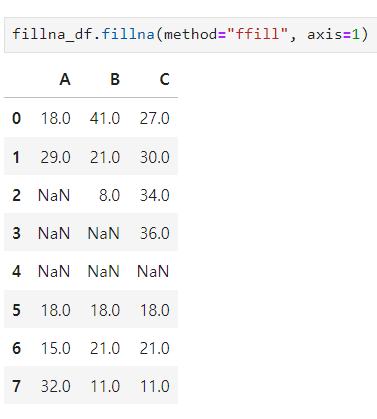
fillna() : NaN 값 채우기
- df
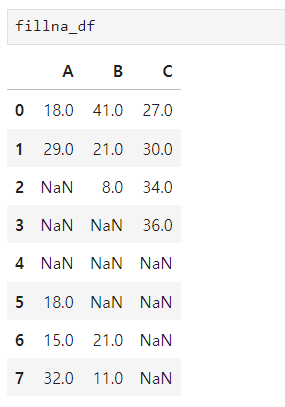
- NaN 값에 0으로 채우기
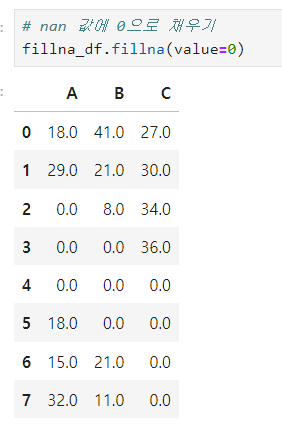
- NaN 값 위에 값으로 채우기
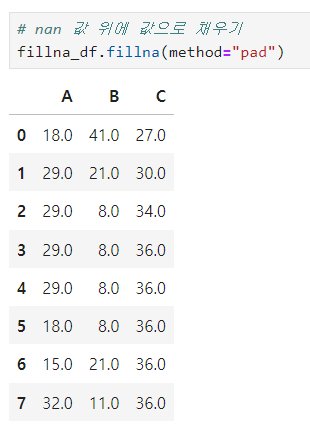
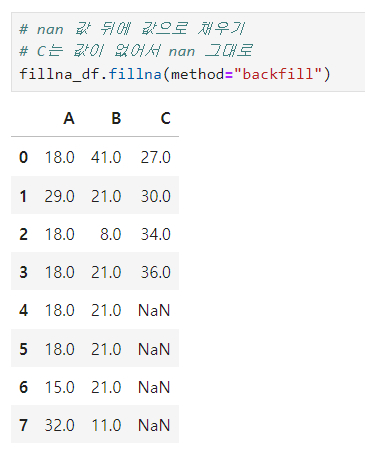
- Nan 값 뒤에 값으로 채우기
- axis 사용 가능
import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import set_matplotlib_hangul
import warnings
# 경고문구 무시
warnings.filterwarnings(action="ignore")
%matplotlib inline데이터 불러오기
사용할 엑셀 파일
population = pd.read_excel("../data/07_population_raw_data.xlsx", header=1)
population.head()
- NaN 값 채우기
population.fillna(method="pad", inplace=True)
population.head()데이터 정리하기
- 컬럼 이름 변경
population.rename(columns={
"행정구역(동읍면)별(1)" : "광역시도",
"행정구역(동읍면)별(2)" : "시도",
"계" : "인구수"}, inplace=True
)- 소계 제거
population = population[population["시도"] != "소계"]- 항목 컬럼 바꾸기
- is_copy = False : 기존 객체의 복사본을 반환할지 여부 결정
population.is_copy = False
population.rename(
columns={"항목" : "구분"}, inplace=True
)- population에 구분 칼럼의 행이 "총인구수 (명)"수를 "합계"로 변경
population.loc[population["구분"] == "총인구수 (명)", "구분"] = "합계" # loc[행,열]
population.loc[population["구분"] == "남자인구수 (명)", "구분"] = "남자"
population.loc[population["구분"] == "여자인구수 (명)", "구분"] = "여자"- 소멸 지역을 조사하기 위한 데이터 정리
population["20-39세"] = (
population["20 - 24세"] + population["25 - 29세"] + population["30 - 34세"] + population["35 - 39세"]
)
population["65세이상"] = (
population["65 - 69세"] + population["70 - 74세"] + population["75 - 79세"] + population["80 - 84세"] +
population["85 - 89세"] + population["90 - 94세"] + population["95 - 99세"] + population["100+"]
)
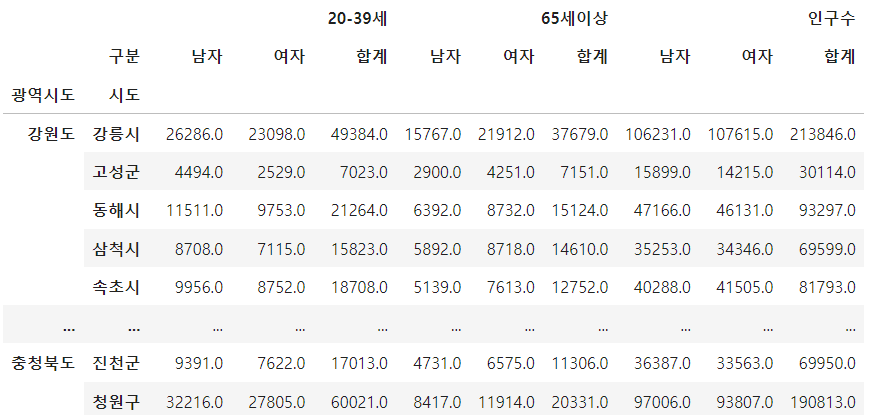
- index "광역시도", "시도"로 pivot_table
pop = pd.pivot_table(
data=population,
index=["광역시도", "시도"],
columns=["구분"],
values=["인구수", "20-39세", "65세이상"]
)
- 소계 비율 계산, 칼럼 추가
pop["소멸비율"] = pop["20-39세", "여자"] / (pop ["65세이상", "합계"] / 2)- 소멸위기 지역 컬럼 생성, 칼럼 추가
pop["소멸위기지역"] = pop["소멸비율"] < 1.0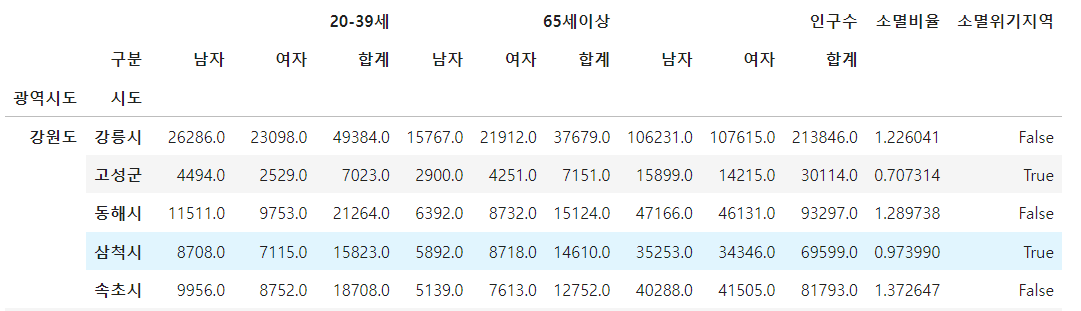
- 소멸위기 지역 조회, 시도 컬럼 기준으로 보기
pop[pop["소멸위기지역"] == True].index.get_level_values(1)
- 멀티 인덱스 정리
pop.reset_index(inplace=True)tmp_col = [
pop.columns.get_level_values(0)[n] + pop.columns.get_level_values(1)[n]
for n in range(0, len(pop.columns.get_level_values(0)))
]
pop.columns = tmp_col
03. 지도 시각화를 위한 지역별 id 만들기
- 빈 리스트 만들기
si_name = [None] * len(pop)- 시에 포함된 구 정렬하기
tmp_gu_dict = {
"수원" : ["장안구", "권선구", "팔달구", "영통구"],
"성남" : ["수정구", "중원구", "분당구"],
"안양" : ["만안구", "동안구"],
"안산" : ["상록구", "단원구"],
"고양" : ["덕양구", "일산동구", "일산서구"],
"용인" : ["처인구", "기흥구", "수지구"],
"청주" : ["상당구", "서원구", "흥덕구", "청원구"],
"천안" : ["동남구", "서북구"],
"전주" : ["완산구", "덕진구"],
"포항" : ["남구", "북구"],
"창원" : ["의창구", "성산구", "진해구", "마산합포구", "마산회원구"],
"부천" : ["오정구", "원미구", "소사구"]
}만들고자 하는 ID의 형태
- 서울 중구, 서울 서초, 통영, 남양주, 포항 북구, 인천 남동, 안양 만안, 안양 동안, 안산 단원 ...

1. 일반 시 이름과 세종시, 광역시도 일반 구 정리
for idx, row in pop.iterrows():
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
si_name[idx] = row["시도"][:-1]
elif row["광역시도"] == "세종특별자치시":
si_name[idx] = "세종"
else:
if len(row["시도"]) == 2:
si_name[idx] = row["광역시도"][:2] + " " + row["시도"]
else:
si_name[idx] = row["광역시도"][:2] + " " + row["시도"][:-1]2. 행정구
for idx, row in pop.iterrows():
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
for keys, values in tmp_gu_dict.items():
if row["시도"] in values:
if len(row["시도"]) == 2:
si_name[idx] = keys + " " + row["시도"]
elif row["시도"] in ["마산합포구", "마산회원구"]:
si_name[idx] = keys + " " + row["시도"][2:-1]
else:
si_name[idx] = keys + " " + row["시도"][:-1]3. 고성군
for idx, row in pop.iterrows():
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
if row["시도"][:-1] == "고성" and row["광역시도"] == "강원도":
si_name[idx] = "고성(강원)"
elif row["시도"][:-1] == "고성" and row["광역시도"] == "경상남도":
si_name[idx] = "고성(경남)"4. 칼럼 추가
pop["ID"] = si_name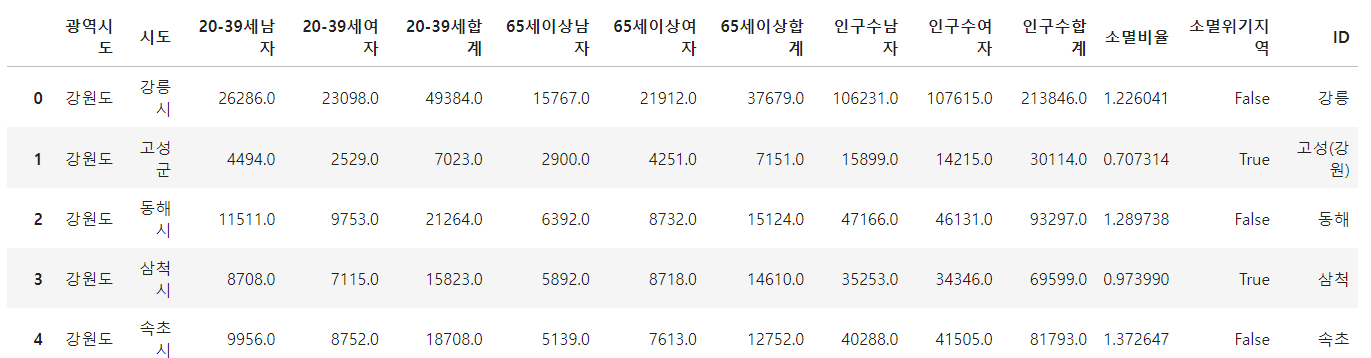
- 인구 소멸 지역에 필요한 데이터 전처리 (최종)
del pop["20-39세남자"]
del pop["65세이상남자"]
del pop["65세이상여자"]
“이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.”

데이터 공부 기록