
의사 결정 트리(Decision Tree)는 트리 구조를 사용하여 분류 및 회귀 작업을 수행하는 지도 학습 알고리즘이다. 이는 데이터를 특정 규칙에 따라 재귀적으로 분할하여 예측을 수행하는 모델이다.
🌳 구조 및 작동 방식
🍎 구조
- 노드(Node): 결정 트리의 각 단계를 나타낸다. 특정 특성(feature)의 값을 기준으로 데이터를 분할한다.
- 가지(branch): 각 노드에서 특성의 조건을 나타내며, 이 조건에 따라 다음 노드로 분기한다.
- 리프(Leaf): 더 이상 분할할 수 없는 노드로, 최종적인 예측값을 제공한다.
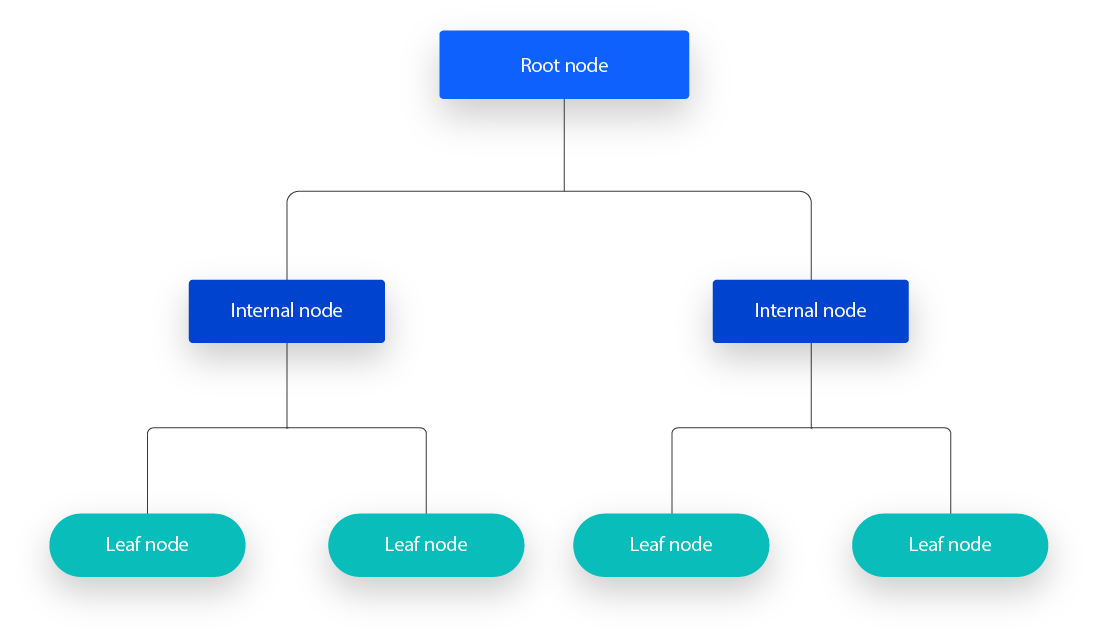
위 사진에서 각각의 사각형 및 타원형이 노드이고, 노드에서 노드로 이어지는 선들이 가지이며, 마지막 타원형 노드가 리프라고 한다.
🍏 작동 방식
1. 분할 기준 선택 : 가장 좋은 특성을 찾아서 해당 특성을 기준으로 데이터를 분할한다. 분할 기준으로는 엔트로피, 지니 불순도 등이 사용된다.
2. 재귀적 분할 : 처음 분할 이후에도 다시 분할될 때까지 데이터를 부분 집합으로 분할한다. 이 과정은 가장 중요한 특성을 기반으로 계속해서 진행된다.
3. 최종 예측 : 리프 노드에 도달하면 해당 리프 노드의 클래스 레이블이 예측값으로 사용된다.
🌳 장점 및 한계
🍎 장점
- 이해하기 쉽고 해석하기 간편하다.
- 범주형 및 수치형 데이터 모두에 대해 사용할 수 있다.
- 특성의 스케일링이나 정규화가 필요하지 않다.
- 이상치나 누락된 값에도 강건하다.
🍏 한계
- 과적합(Overfitting)될 수 있으며, 이를 방지하기 위한 가지치기(Pruning)나 규제(Regularization) 방법을 사용해야 할 수 있다.
- 데이터의 작은 변화에도 모델이 크게 변할 수 있다.
- 선형 결정 경계를 만들 수 없고, XOR 문제와 같은 복잡한 문제를 해결하기 어려울 수 있다.
의사 결정 트리는 직관적이고 해석하기 쉬운 특성 때문에 많은 분야에서 사용되며, 앙상블 기법인 랜덤 포레스트(Random Forest)나 그래디언트 부스팅(Gradient Boosting)과 같은 기법에서도 중요한 구성 요소로 사용된다.
앙상블 기법에 대해서는 다음 포스팅에서 작성하겠다 -> 앙상블 기법
🌳 코드 예제
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 아이리스 데이터셋 불러오기
iris = load_iris()
X = iris.data
y = iris.target
class_names = iris.target_names.tolist() # 타겟 이름을 리스트로 변환
# 데이터를 훈련 세트와 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 의사 결정 트리 모델 초기화 및 학습
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
# 테스트 세트로 예측 수행
y_pred = clf.predict(X_test)
# 정확도 계산
accuracy = accuracy_score(y_test, y_pred)
print(f'정확도: {accuracy:.4f}')
# 의사 결정 트리 시각화
plt.figure(figsize=(12, 8))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=class_names)
plt.show()
이 코드는 Scikit-learn을 사용하여 붓꽃 데이터셋을 의사 결정 트리로 분류하는 과정을 담고 있다.
🍎 코드 리뷰
load_iris()를 사용하여 붓꽃 데이터를 불러온다.train_test_split()함수를 사용하여 데이터를 훈련 세트와 테스트 세트로 분할한다. 이는 모델의 일반화 성능을 평가하기 위함이다.DecisionTreeClassifier()를 사용하여 의사 결정 트리 모델을 초기화하고,fit()메서드를 통해 훈련 데이터에 모델을 학습시킨다.predict()메서드를 사용하여 테스트 데이터에 대한 예측을 수행하고,accuracy_score()함수를 사용하여 예측값의 정확도를 계산했한다.plot_tree메서드를 사용하여 의사 결정 트리를 시각화한다.
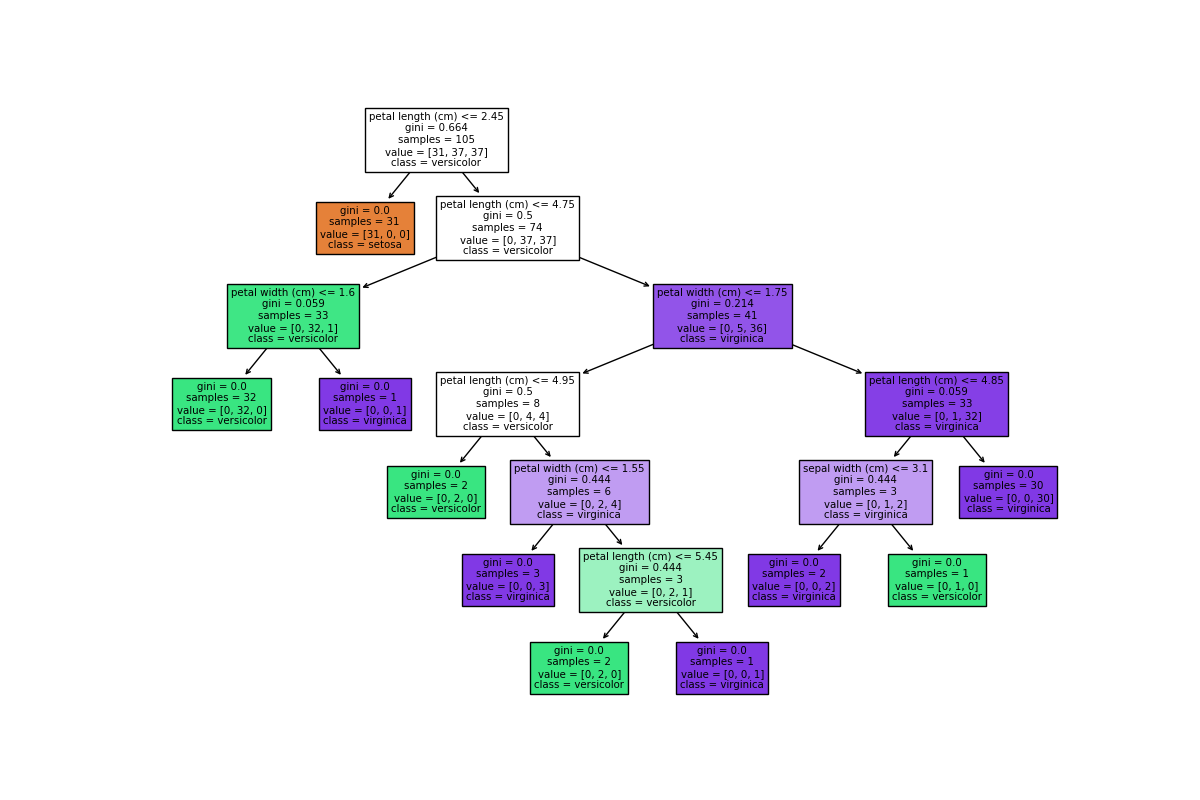
이 코드는 간단하게 기본적인 분류 모델을 구축하고 성능을 평가하는 방법을 보여주는데, 실제 프로젝트에서는 데이터 전처리, 모델 튜닝 등 다양한 추가 단계가 필요할 수 있다.
