
앙상블(Ensemble) 기법은 여러 개의 개별 모델을 결합하여 하나의 강력한 모델을 구성하는 기법이다. 이는 개별 모델들의 예측을 결합하여 보다 정확하고 안정적인 예측을 할 수 있도록 도와준다.
가장 일반적인 두 가지 종류의 앙상블 기법은 배깅과 부스팅이 있다. 배깅과 부스팅에 대해 알기 전에 보팅에 대해서 알아보자.
0. 보팅(Voting)
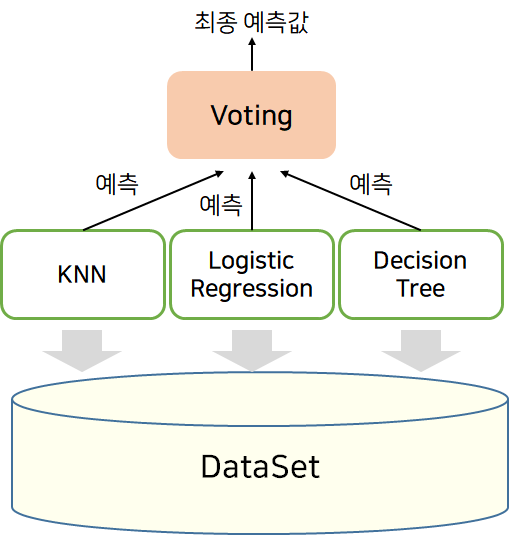
보팅(Voting)은 앙상블 학습의 한 형태로, 다양한 머신 러닝 알고리즘들이 투표를 통해 결합하여 예측을 수행하는 방법이다. 보팅은 주로 분류(Classification) 문제에서 사용된다.
보팅은 크게 하드 보팅(Hard Voting)과 소프트 보팅(Soft Voting)으로 나뉜다.
1. 하드 보팅(Hard Voting)
- 여러 모델이 각각의 예측 결과를 투표하여 가장 많이 선택된 클래스를 최종 예측으로 선택한다.
- 이진 분류의 경우, 0 또는 1로 결정하는 경우가 대표적이다.
2. 소프트 보팅(Soft Voting)
- 모든 모델의 예측 확률의 평균을 계산하고, 평균적으로 가장 높은 확률을 갖는 클래스를 선택한다.
- 예측 결과에 대한 확률을 고려하여 최종 예측을 수행하므로, 일반적으로 소프트 보팅이 더 선호된다.
보팅은 서로 다른 알고리즘 혹은 동일한 알고리즘의 다른 설정을 사용한 모델들을 결합하여 모델의 성능을 향상시키는데 사용된다. 이를 통해 각 모델의 약점을 상쇄하고 종합적으로 높은 예측 성능을 얻을 수 있다. 예를 들어, 로지스틱 회귀, 결정 트리, 랜덤 포레스트 등 서로 다른 알고리즘을 사용하여 보팅을 적용할 수 있다.
1. 배깅(Bagging)
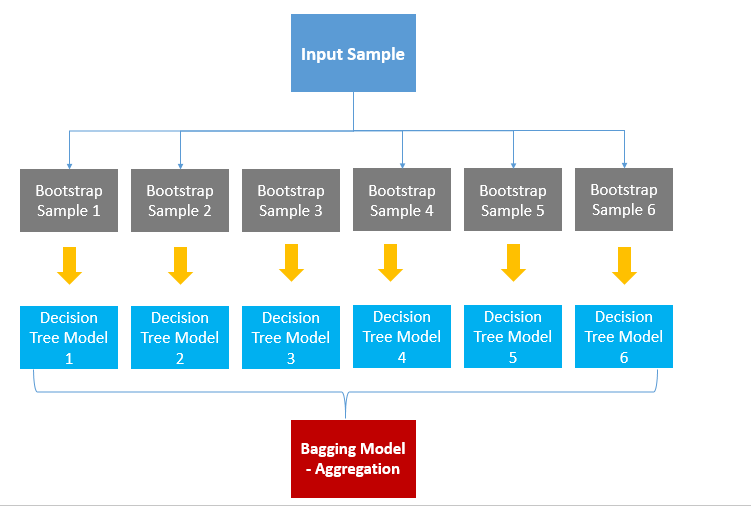
배깅(Bagging)은 Bootstrap Aggregating의 줄임말로, 여러 개의 동일한 모델을 독립적으로 학습시켜 각각의 예측을 결합하여 최종 예측을 수행하는 앙상블 기법이다.
여기서 Bootstrap은 중복을 허용한 리샘플링을 의미한다. 즉, 주어진 데이터셋에서 중복을 허용하여 샘플을 여러 번 랜덤하게 추출하는 방법이다. 이렇게 생성된 서브셋을 기반으로 각각의 모델을 학습시키는 것이 배깅의 기본 개념이다.
1-1) 주요 과정
1. 부트스트랩 샘플링 (Bootstrap Sampling)
주어진 데이터셋으로부터 중복을 허용한 랜덤 샘플링을 수행하여 복수의 훈련 데이터 셋을 생성한다.
2. 독립적인 모델 학습
각 부트스트랩 샘플로부터 독립적인 모델을 학습힌다. 이 모델들은 동일한 알고리즘을 사용하지만 서로 다른 데이터로 학습된다.
3. 예측 결합
각 모델은 테스트 데이터에 대한 예측을 수행하고, 이 예측 결과들을 결합하여 최종 예측을 만든다. 회귀 문제에서는 평균을 내거나 분류 문제에서는 투표(Voting)를 통해 최종 예측을 수행한다.
1-2) 장점
- 과적합을 줄여 모델의 일반화 성능을 향상시킨다.
- 다양한 모델을 결합해 예측력을 높일 수 있다.
1-3) 예시
🔎 랜덤 포레스트
랜덤 포레스트(Random Forest)는 앙상블 학습 기법 중 하나로, 여러 결정 트리(Decision Tree)들을 생성하고 그들의 예측을 결합함으로써 보다 정확한 예측을 하는 데 사용된다. 이 모델은 분류와 회귀 문제 모두에 적용할 수 있다.
주요 특징
-
부트스트랩 샘플링 (Bootstrap Sampling)
- 주어진 데이터에서 복원 추출을 통해 샘플을 랜덤하게 선택하여 서브셋을 생성한다.
- 이를 통해 서로 다른 트리들이 서로 다른 데이터셋을 기반으로 만들어지게 된다.
-
랜덤 특성 선택 (Random Feature Selection)
- 각 노드에서 트리를 구성할 때, 전체 특성 중 일부만을 랜덤하게 선택하여 트리를 만든다.
- 이렇게 함으로써 각 트리가 데이터의 다양한 측면을 고려할 수 있다.
-
다수결 투표 (Majority Voting)
- 분류 문제의 경우, 각 트리가 예측한 결과를 종합하여 가장 많이 선택된 클래스를 최종 예측으로 선택한다.
랜덤 포레스트는 여러 개의 결정 트리를 사용하므로, 과적합을 피하고 예측력을 향상시킬 수 있다.
코드 예제
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 데이터 불러오기
iris = load_iris()
X = iris.data
y = iris.target
# 데이터를 훈련 세트와 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 랜덤 포레스트 모델 초기화 및 학습
clf = RandomForestClassifier(n_estimators=100, random_state=42) # 트리 개수는 100개로 설정
clf.fit(X_train, y_train)
# 테스트 세트로 예측 수행
y_pred = clf.predict(X_test)
# 정확도 계산
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.4f}')코드 리뷰
RandomForestClassifier를from sklearn.ensemble import RandomForestClassifier를 통해 불러온다.n_estimators매개변수를 사용하여 결정 트리의 개수를 설정했습니다. 이 예제에서는 100개의 트리를 사용한다.fit을 통해 모델을 학습시키고,predict를 사용하여 테스트 데이터에 대한 예측을 수행한다.accuracy_score함수를 사용하여 정확도를 계산하고 출력한다.
🔎 XGBoost
XGBoost는 배깅과 부스팅으로 나누기 애매한 부분이 있다. 한 자료에서는 배깅이라고 하기도 하고 다른 자료에서는 부스팅이라고 한다. 나는 일단 배깅으로 나눴다.
XGBoost는 트리 기반의 강력한 머신 러닝 알고리즘 중 하나이다. "eXtreme Gradient Boosting"의 약자로, GBM(Gradient Boosting Machine)의 변형으로, 속도와 성능 면에서 최적화되어 있다. XGBoost는 회귀, 분류, 랭킹 등 다양한 문제에 적용할 수 있으며, 대용량 데이터셋에서도 뛰어난 성능을 보인다.
주요 특징
- Regularization(정규화) : Overfitting을 방지하기 위한 정규화 기능을 제공한다.
- Cross-validation(교차 검증) : 내장된 교차 검증 기능을 통해 모델의 성능을 평가할 수 있다.
- Missing Values 처리 : 결측값 처리 기능을 제공하여 누락된 데이터에 대응할 수 있다.
- Parallelization(병렬화) : 병렬 처리를 통해 학습 속도를 빠르게 할 수 있다.
- Customization(사용자 정의) : 다양한 매개변수를 조정하여 모델을 최적화할 수 있다.
코드 예제
# 필요한 라이브러리 불러오기
import xgboost as xgb
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 데이터셋 불러오기
boston = load_boston()
X, y = boston.data, boston.target
# 데이터셋을 학습용과 테스트용으로 나누기
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# XGBoost 모델 생성 및 학습
xg_reg = xgb.XGBRegressor(objective ='reg:squarederror', colsample_bytree = 0.3, learning_rate = 0.1,
max_depth = 5, alpha = 10, n_estimators = 10)
xg_reg.fit(X_train, y_train)
# 예측 수행
preds = xg_reg.predict(X_test)
# RMSE(평균 제곱근 오차) 계산
rmse = np.sqrt(mean_squared_error(y_test, preds))
print("RMSE: %f" % (rmse))코드 리뷰
xgboost라이브러리를 import하고 필요한 라이브러리들을 함께 import한다.- 보스턴 주택가격 데이터셋을 불러온 후 학습용과 테스트용으로 나눈다.
- XGBoost 모델을 생성하고 학습한다.
XGBRegressor는 회귀 모델용 XGBoost 클래스이다. - 학습된 모델을 사용하여 테스트 데이터에 대한 예측을 수행하고 RMSE를 계산하여 모델의 성능을 평가한다.
이 코드를 실행하면 XGBoost를 사용하여 보스턴 주택가격 데이터셋에 회귀 모델을 학습하고 그 성능을 평가할 수 있다. XGBoost의 다양한 매개변수를 조정하여 모델의 성능을 향상시킬 수 있다.
2. 부스팅(Boosting)
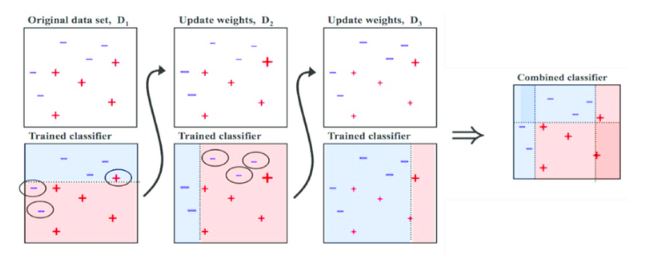
부스팅은 약한 모델들을 순차적으로 학습시켜 잘못 예측한 샘플에 가중치를 부여하여 학습하는 방법이다. 부스팅은 이전 모델의 예측 오류를 보완하는 새로운 모델을 만들어나가는 방식으로 동작한다.
부스팅(Boosting)은 약한 학습기(weak learner)를 결합하여 강력한 앙상블 모델을 구축하는 머신 러닝 알고리즘 기법이다. 이는 단순한 모델들을 연속적으로 학습시켜 나가면서, 이전 모델이 놓친 부분에 초점을 맞춰 새로운 모델을 조정하는 방식으로 작동한다. 부스팅의 기본 아이디어는 이전 모델들이 실패한 데이터에 집중하여 새로운 모델이 그 부분을 보완하는 것이다.
2-1) 주요 과정
1. 약한 학습기(Weak Learner) 학습 : 기본적으로 각각의 학습 단계에서는 약한 학습기가 학습된다. 이는 전체 데이터셋에 대해 예측 성능이 조금 떨어지더라도, 랜덤 추측보다는 조금 더 나은 성능을 보이는 모델이다. 대표적으로 결정 트리의 깊이가 제한된 경우가 있다.
2. 가중치 업데이트 : 초기에는 모든 데이터 포인트에 동일한 가중치가 부여된다. 이후 각 모델은 이전 모델이 잘못 예측한 데이터에 대해 높은 가중치를 부여받게 된다.
3. 연속적인 학습 : 이전 모델들의 오차를 보완하도록 새로운 약한 학습기들을 추가적으로 학습시킨다. 이때, 오차에 집중하여 새로운 모델을 학습시키기 위해 가중치가 조정된다.
4. 최종 결합 : 모든 약한 학습기의 예측을 결합하여 최종 예측을 수행한다. 대부분의 경우, 각 모델의 예측에 가중치를 부여하여 최종 예측을 수행하게 된다.
부스팅은 여러 알고리즘에서 사용되는데, 그 중 대표적으로는 AdaBoost(Adaptive Boosting), Gradient Boosting, LightGBM, CatBoost 등이 있다. 이러한 알고리즘들은 부스팅의 기본 원리를 기반으로 하되, 각자의 개선된 방법을 적용하여 더 나은 성능을 내고 있다.
부스팅은 과적합(Overfitting)을 방지하고 높은 성능을 내는 데에 효과적이지만, 학습 시간이 길 수 있고 매개변수 튜닝이 필요할 수 있다.
3. 배깅 vs 부스팅
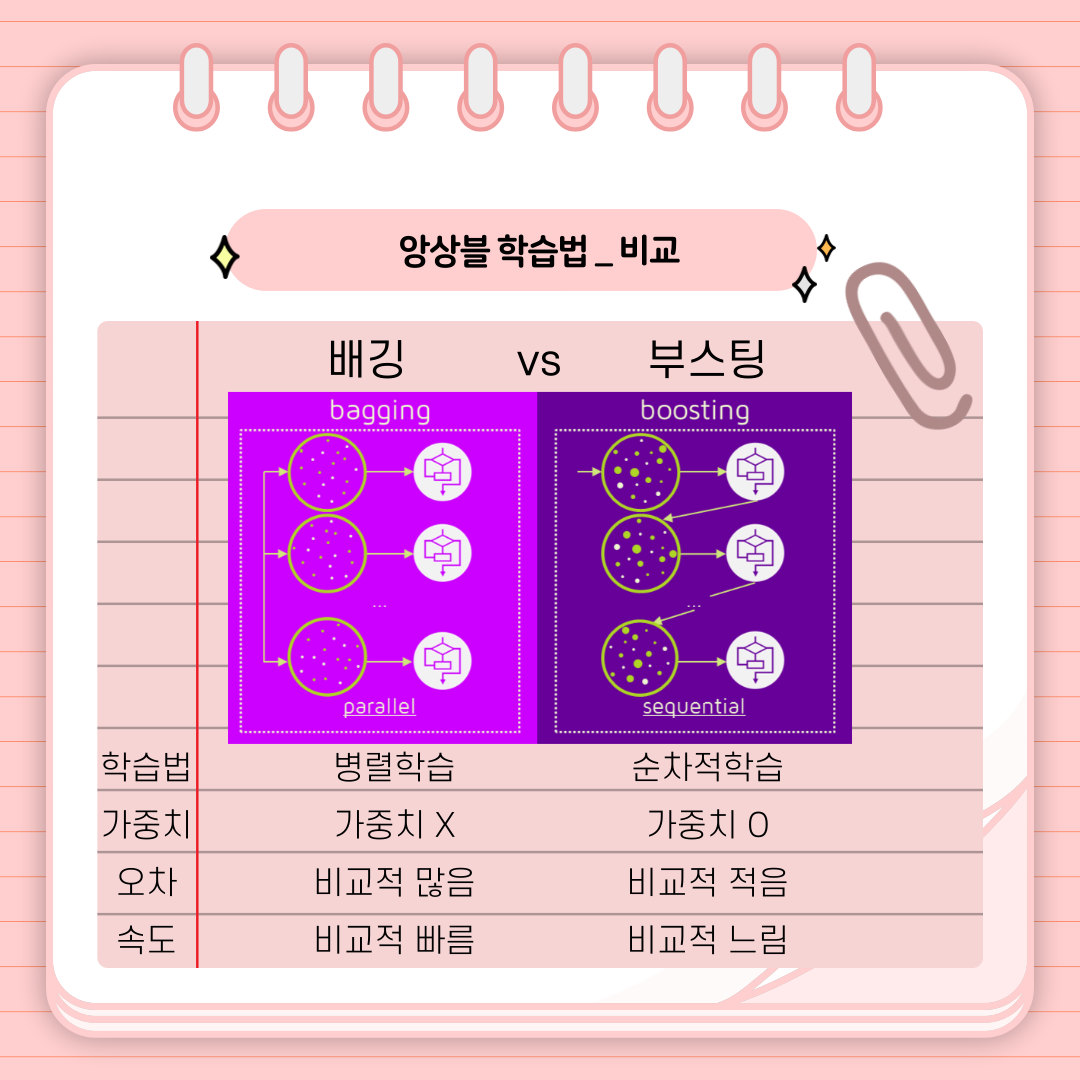
배깅 (Bagging):
- 병렬적 학습: 병렬적으로 여러 개의 모델을 학습시키는 방식이다. 각 모델은 원본 데이터에서 복원 추출(Bootstrap Sampling)을 통해 만들어진 부분 데이터셋에 대해 학습된다.
- 모델 간 독립성: 각 모델은 독립적으로 학습하고 예측한다. 이들의 결과를 평균 또는 다수결 등을 통해 결합한다.
부스팅 (Boosting):
- 순차적 학습: 이전 모델이 실패한 부분에 집중하여 새로운 모델을 학습시키는 방식이다. 각 모델은 이전 모델의 예측 오차를 보완하도록 학습된다.
- 가중치 부여: 각 모델은 이전 모델이 잘못 예측한 데이터에 높은 가중치를 부여받는다.
- 예측 오류에 집중: 이전 모델들이 놓친 데이터의 부분을 학습하는 방식으로 작동한다.
차이점 요약:
- 병렬 vs. 순차: 배깅은 병렬적으로 모델을 학습시키고, 부스팅은 순차적으로 이전 모델을 보완하는 방식이다.
- 모델 독립성 vs. 가중치 부여: 배깅에서는 각 모델이 독립적으로 학습하고 결과를 결합한다. 부스팅에서는 모델들 간에 오류에 따라 가중치를 부여하면서 순차적으로 학습한다.
- 가중치 부여: 배깅은 모든 데이터 포인트에 대해 동일한 가중치를 가진다. 부스팅은 오분류된 데이터에 높은 가중치를 부여하여 새로운 모델이 이를 보완한다.
배깅과 부스팅은 앙상블 방법의 두 가지 주요 접근 방식으로, 각각의 장단점과 상황에 맞는 적용이 필요하다.
앙상블 기법은 단일 모델보다 예측 성능이 우수하며, 다양한 종류의 데이터에 적용할 수 있는 강력한 기법 중 하나이다. 여러 개의 약한 모델을 결합하여 강력한 모델을 만들어내는 이러한 방식은 일반적으로 일반화 성능을 향상시키고 과적합을 줄일 수 있어 많은 분야에서 널리 사용된다.
참고하면 좋을 사이트
배깅부스팅 차이점 이미지
배깅 이미지
부스팅 이미지
보팅 이미지
