
📔 개념
데이터를 분류하는 최적(margin을 최대화)의 선을 찾는 것
Support Vector Machine(SVM)은 주어진 데이터를 분류하거나 회귀 분석하는 데 사용되는 강력한 머신러닝 알고리즘 중 하나이다. SVM은 주어진 데이터를 고차원의 공간으로 매핑하고, 두 클래스 사이의 가장 큰 폭을 가진 경계(결정 경계)를 찾는 것으로 알려져 있다. SVM은 다양한 분야에서 효과적으로 사용되며, 이진 분류와 다중 클래스 분류, 회귀 분석에 모두 적용될 수 있다.
데이터를 분리하기 위해서는 직선이 필요하다.
직선이 한쪽 데이터로 치우쳐져 있으면 데이터에 변동이나 노이즈가 있을 때 제대로 구분 못할 수 있다.
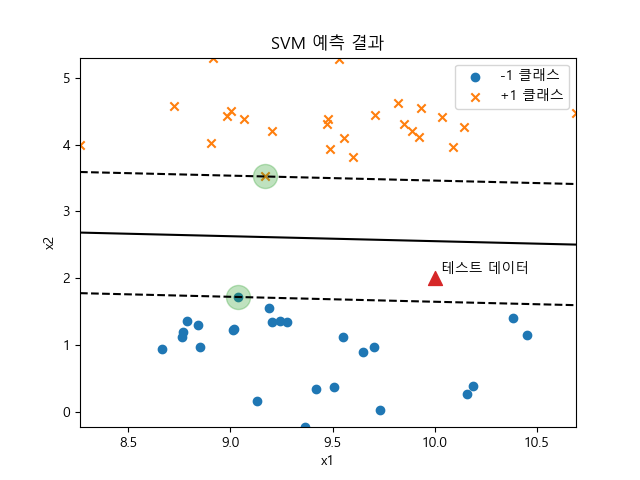
이러한 문제점을 해결하기 위해 margin을 이용하게 된다.
margin을 최대로 만드는 직선을 계산하여 데이터를 분류하는 방법이 바로 서포트 벡터 머신(SVM)이다.
주요 개념 정리
- 서포트 벡터(Support Vectors) : 결정 경계와 가장 가까운 데이터 포인트들로, 결정 경계를 만드는 데 주요하게 사용된다.
- 마진(Margin) : 서포트 벡터와 결정 경계 사이의 거리로, SVM은 이 마진을 최대화하도록 학습한다. 이것이 SVM의 주요 목표 중 하나이다.
- 커널 기법(Kernel Trick): 고차원 공간으로 데이터를 매핑하여 비선형 문제를 해결할 수 있는 기법이다. 주어진 데이터를 고차원 특징 공간으로 변환하지 않고, 커널 함수를 통해 계산 효율성을 높일 수 있다.
📔 실습
🔎 코드 예제
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# Iris 데이터 로드
iris = load_iris()
X = iris.data
y = iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# SVM 모델 학습
model = SVC(kernel='linear') # 선형 커널을 사용한 SVM 모델
model.fit(X_train, y_train)
# 테스트 데이터로 예측
y_pred = model.predict(X_test)
# 정확도 평가
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)🔎 코드 리뷰
위 코드는 Iris 데이터셋을 불러와 SVM을 사용하여 분류하는 예제이다. SVC 클래스를 사용하여 SVM 모델을 생성하고, fit() 함수를 통해 모델을 학습한다. 그리고 테스트 데이터로 예측을 수행하고 정확도를 출력한다. 이 코드를 통해 SVM을 사용한 분류 작업을 실제로 수행해 볼 수 있다.
이 코드에서는 선형 커널을 사용한 SVM 모델을 사용했지만, 경우에 따라 기본값인 모델로 수행하는 것이 더 효율적일 수 있다.
더 자세히 공부하고 싶으면
참고
