
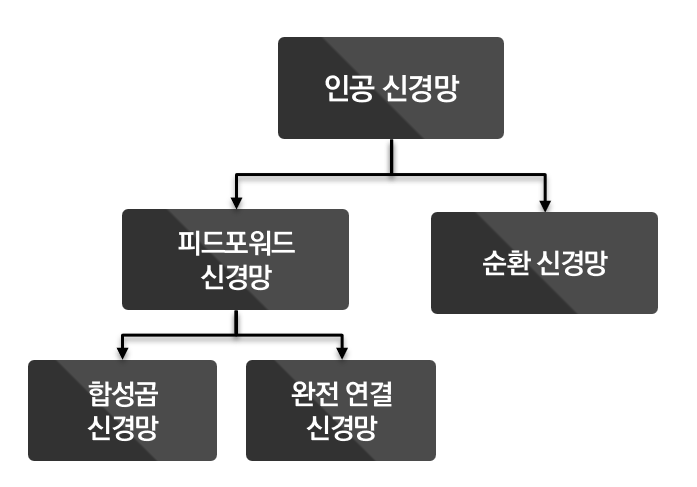
목차
- 순차 데이터
- 순환 신경망(RNN)
- 시계열 데이터와 RNN의 만남
- 시계열 모델링 기법
들어가며
최근 시계열 분석이 필요한 업무를 맡게 되어, 순차 데이터의 개념부터 다시 학습해보려 한다.
1. 순차 데이터
순차 데이터는 데이터의 순서가 중요한 경우를 말하며, 대표적으로 텍스트 데이터와 시계열 데이터가 있다. 예를 들어, 텍스트 데이터는 단어의 순서가 의미 전달에 핵심적인 역할을 하며, 시계열 데이터는 일정한 시간 간격으로 기록된 데이터로 주가, 날씨, 에너지 소비량 등이 포함된다.
순차 데이터는 데이터 간의 관계를 학습하는 데 중점을 둔다. 따라서 시간적 맥락을 반영해야 하기에 보다 복잡한 접근 방식이 필요하다.
2. 순환 신경망(RNN)
순환 신경망(Recurrent Neural Network, RNN)은 순차 데이터를 학습하기 위해 설계된 딥러닝 모델이다. 기존 신경망은 독립적인 입력 간의 관계를 학습하지만, RNN은 과거의 정보를 현재로 전달하며 데이터의 연속적인 흐름을 학습한다.
시간의 순서와 상관없는 데이터는 일반적인 머신러닝 모델이나 딥러닝 모델에서 데이터를 주입하는 순서가 학습에 큰 영향을 미치지 않는다. 반면에 순서에 의미가 있는 순차 데이터의 경우, 순서를 유지하며 신경망에 주입해야 한다. 따라서 순차 데이터를 다룰 때는 이전에 입력한 데이터를 기억하는 기능이 필요하다.
RNN은 숨겨진 상태(hidden state)를 사용해 이전 시점의 정보를 기억하고, 이를 업데이트하는 방식을 통해 데이터를 처리한다.
2.1 버려지는 샘플(?)
완전 연결 신경망이나 합성곱 신경망은 이전에 입력한 데이터를 기억하는 기억 장치가 없다. 하나의 샘플(또는 하나의 배치)을 사용하여 정방향 계산을 수행하고 나면 그 샘플은 버려지고 다음 샘플을 처리할 때 재사용하지 않는다. 이렇게 입력 데이터의 흐름이 앞으로만 (앞만 보는 거지) 전달되는 신경망을 피드포워드 신경망 (feedforward neural network) 라고 한다.
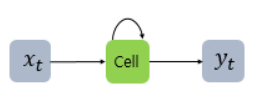
2.2 순환 고리 추가
신경망이 이전에 처리했던 샘플을 다음 샘플을 처리하는데 재사용하기 위해 일반적인 완전 연결 신경망에 이전 데이터의 처리 흐름을 순환하는 고리를 추가한 것이 순환 신경망이다.
그러나 RNN은 긴 시퀀스를 학습할 때 기울기 소실(vanishing gradient) 문제를 겪는다. 이를 해결하기 위해 LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit)와 같은 확장 모델이 개발되었다.
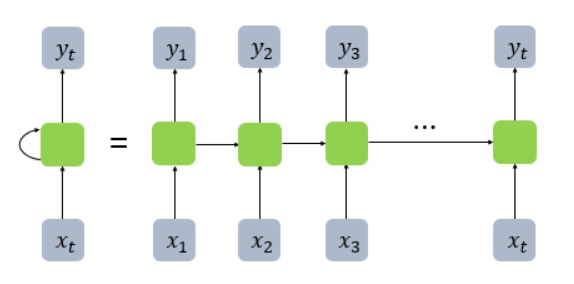
3. 시계열 데이터와 RNN의 만남
RNN은 시계열 데이터의 시간적 연속성을 학습하는 데 적합하지만, 긴 시퀀스를 처리할 때 기울기 소실(vanishing gradient) 문제를 겪는다. 시퀀스가 길어질수록 순환되는 은닉 상태에 저장된 정보가 점차 희석되어, 기본 RNN은 긴 시퀀스를 효과적으로 학습하기 어렵다. 이로 인해 멀리 떨어진 단어나 데이터 간의 관계를 인식하는 데 한계가 생길 수 있다. 이러한 문제를 해결하기 위해 개발된 LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit)은 시계열 데이터 분석에서 매우 유용하게 활용된다.
LSTM은 셀 상태(cell state)라는 구조를 통해 장기적 의존성을 학습한다. 입력 게이트, 삭제 게이트, 출력 게이트로 구성된 메커니즘을 사용하여 중요한 정보를 선택적으로 기억하거나 잊을 수 있다. 이를 통해 긴 시퀀스 데이터에서도 안정적으로 학습이 가능하다.
GRU는 LSTM의 단순화된 버전으로, 유사한 성능을 제공하면서도 계산 비용이 더 낮다는 장점이 있다.
시계열 데이터 분석에서는 이러한 개선된 모델들을 활용하여 데이터의 시간적 패턴을 더 효과적으로 학습할 수 있다. RNN 및 그 확장 모델들은 시간적 흐름을 이해하고 중요한 정보를 포착하여 시계열 데이터를 분석하고 예측하는 데 중요한 역할을 한다.
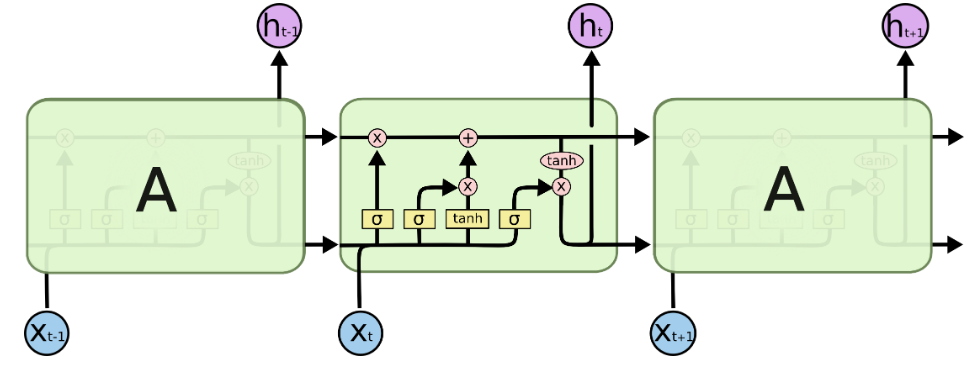
4. 시계열 모델링 기법
시계열 데이터를 다루기 위한 방법은 RNN뿐만 아니라 다양한 기법이 존재한다.
- ARIMA: 과거 데이터를 기반으로 시계열의 선형적 관계를 분석하고 예측하는 통계 모델이다.
- Prophet: 페이스북이 개발한 시계열 예측 도구로, 계절성과 추세를 자동으로 반영한다.
- Transformer 기반 모델: 최근에는 RNN의 한계를 극복하기 위해 Transformer 모델이 시계열 데이터 분석에 적용되고 있다.
시계열 모델링은 데이터의 특성에 따라 다양한 기법을 조합하며, 특정 문제에 최적화된 접근 방식을 설계한다.
다음 장에서는 LSTM 구조에 대해 더 자세히 다뤄보려 한다.
