Introduction
This is the Term Project for HGU Machine Learning course. The purpose of this project is to experience Pytorch, get a glimpse on deep learning and enhance techinical writing skills.
I will try to build a deep neural network of my own and test the accuracy of the output. Furthermore I will try the more conventional machine learning methods I learned throughout this course and compare the results between the neural network ouput accuracy and machine learning methods ouput accuracy.
Dataset Description
- Dota2 Games Results
-
Target - Given the game play infomation, predict whether the team won or not
-
Difficulty - A ✨(MOST DIFFICULT)✨
Attribute Information
1. Team won the game (1 or -1) 2. Cluster ID (related to location) 3. Game mode (eg All Pick) 4. Game type (eg. Ranked) 5 - end: Each element is an indicator for a hero. Value of 1 indicates that a player from team '1' played as that hero and '-1' for the other team. Hero can be selected by only one player each game. This means that each row has five '1' and five '-1' values.
With this dataset the goal is to find which team won the game using the information provided above. The target will be Attribute 1 and the input will be the rest attributes.
The attributes from 5th to the end list all type of heroes(characters) player used in the match. They also provide a json file which links the index of the attribute to the the detail info of the hero such as name and etc, but I did not use this json file.
and yes I chose the most difficult dataset because I like to challenge myself.😁
Preprocessing and Dataloading
The dataset provided contained 2 csv files: 'dota2Train.csv' and 'dota2Test.csv' so i did not split the data to train and test, and just used the data provided as it is.
All the input features are categorical values, so I did not perform any type of normalization on the values.
Also the dataset is huge with size 92650x116 in training dataset alone. So I built a custom dataset class and loaded the dataset with Dataloader provided by pytorch. By using the Dataloader function, data is more stably fed and also batch size can be easily adjusted.
The dataset also included negative values to represent target team and heroes chosen. I replaced the negative values to positive values because it might affect the loss calculation.
self.x_data = np.where(self.x_data==-1,2,self.x_data) #change -1 to 2
self.y_data = from_numpy(xy[:,[0]]).flatten().long()
self.y_data = np.where(self.y_data==-1,0,self.y_data) # change -1 to 0I changed character chosen to 2 and target to 0.
Model
Activation Function : ReLU
Optimizer : Adam
Loss Function : CrossEntropyLoss
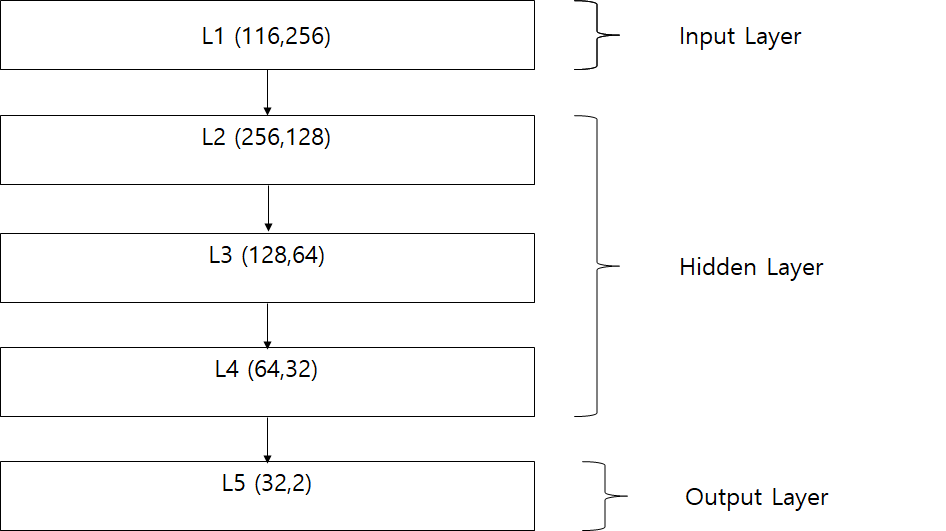
I stacked 5 layers to produce 2 predictions: Team 1 or Team 0.
I used all 116 features given in the csv file.
ReLU was used as the activation function in between layers. It is most commonly used activation function.
I chose Adam as the optimizer because it is definitely faster than SGD and also on par with the goodness of SGD.
For loss function, I firstly used BCEloss function but it did not perform very well in term of accuracy and I thought because this is not a binary type of decision (Eg. You have diabetes or Not) so it might be better to use CrossEntropyLoss which is great for mutidimensional output. (Will elaborate more on the result part)
Here is the code work.
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.l1 = nn.Linear(116,256)
self.l2 = nn.Linear(256,128)
self.l3 = nn.Linear(128,64)
self.l4 = nn.Linear(64,32)
self.l5 = nn.Linear(32,2)
self.hidden = nn.Sequential(
self.l1,
nn.ReLU(),
self.l2,
nn.ReLU(),
self.l3,
nn.ReLU(),
self.l4,
nn.ReLU(),
self.l5
)
def forward(self,x):
x = self.hidden(x)
return xResult
First with BCELoss
Training Configuration
- Epoch : 30
- Learning rate : 0.01
- Batch size : 64
Loss is around 0.7 ~ 0.68 which is not that great. The loss does not go down even if I increase the epoch.
Test Result

Perfomance is very poor as you can see. Changing the learning rate (0.1/0.001) did literally nothing to the accuracy. Increasing the epoch also did nothing.
With CrossEntropyLoss
Training Configuration
- Epoch : 30
- Learning rate : 0.01
- Batch size : 64
Loss is similiar to that of BCELoss function.
Test Result

But the test accuracy has increased from 47% to 53%!!
Changing the learning rate or epoch did no change as well.
Conventional ML methods
KNN
First I tried using K nearest neighbour method since this algorithm does not need any training therefore fast and its suitable for a non linear classification such as this dataset.
I reused all the codes from the previous homeworks.
Turns out KNN is extremely slow when theres alot of observations😭
So I had no other choice but to cut down the size of the training dataset to mere 1000.😥
I left the test dataset as it is.
Result
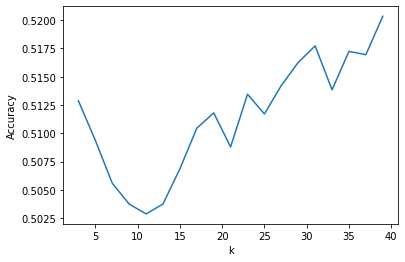
I have tried a range of k from 3 to 40, and as you can see the accuracy constantly increases when k=15 to all the way up to 40. With only 1000 train data, accuracy of 52% was obtained. If I had the resource to use all train data, the accuracy could be much higher.
Random Forest Tree
Second ML method I used was Random Forest Tree. This method is good for a dataset with a lot of observation(features) and also it is very accurate as it uses bootstraping and random inputs to make various trees and aggregate them to produce an output.
This time I used 20000 train data and thankfully my computer produced a result.

Using the grid search, I obtained the best hyperparameter for the model and it produced a whopping 56.5%!!!!🎉
Conclusion
Methods Accuracy MLP(BCEloss) 47% MLP(CrossEntropyLoss) 53% KNN (1000 tr) 52% Random Forest Tree (20000 tr) 56.5%
Surprsingly the conventional machine learning methods performed really well against the neural network I built. Random Forest Tree beat all other methods and came in first with 56.5% accuracy. It is also worthwhile mentioning that both Random Forest Tree and KNN had less train data to train their model and yet they still performed way better then the fully trained neural network.
Why is the accuracy so low? 🤨
- Firstly the features or attributes in the dataset are not that informative. It only provides the types of characters played and game mode/type. So it is not a good dataset for making decisions
- Secondly, because it is a game and all the characters are controlled by players, the quality of the player matters the most in which team wins the game. Therefore, if the players informations were given if would have been a more robust dataset.
Wraping up..
Nonetheless the conventional ML methods produced great result with a limited amount of train data. It is still quite impressive to get above 50% in accuracy. I always thought the neural networks worked way better than any traditional machine learning methods but through this project I learned that sometimes oldies are the goodies!😁
All the codes used for this project can be found here!
Citation
Dota2 Game Result Dataset - https://archive.ics.uci.edu/ml/datasets/Dota2+Games+Results
Pytorch Lecture and codes
https://www.youtube.com/playlist?list=PLlMkM4tgfjnJ3I-dbhO9JTw7gNty6o_2m https://github.com/hunkim/PyTorchZeroToAll
