Instance-aware Image Colorization
Abstract
Colorful Image Colorization에서 garyscale을 통해 그럴듯한 Colorization 결과를 가져왔지만 여러개의 object가 있는 이미지에서는 그럴듯한 Colorizaition 결과를 가져오지 못하고 실패했습니다.
이러한 결과가 나오는 이유는 기존 모델이 전체 이미지에 대해서 colorization하기 때문입니다.
그렇기에 figure와 ground가 명백히 나뉘지 않으면 이 모델은 object-level에서의 의미있는 semantics를 효과적으로 찾거나 학습할 수 없습니다.
그래서 본 논문에서는 Instance-aware colorization(object와 background를 명확히 나누어 colorization)을 성공하기 위한 방법을 제안합니다.
Contribution
Object와 background를 명확히 나누기 위해서는 object가 어디있는지를 알고 있으면 됩니다.
그렇기에 본 논문에서는 미리 학습된 object detector를 사용하여 object를 찾고 찾은 object에 대한 colorization을 합니다.
그럼 object에 대해서는 colorization이 되었고 이를 이미지 전체에 대한 colorization과 합친다면 배경과 object에 대한 완전한 colorization이 완성되는 것입니다.
이 부분에 대해서는 뒤에서 설명하겠습니다.
앞서 말한 것들을 정리해서 말하자면 다음과 같습니다.
1) 사전 학습된 detection모델로 object instance를 검출하고 이를 통해 cropped된 object의 이미지를 만든다.
2) 이미지 전체에 대한 네트워크와 object에 대한 네트워크 각각의 학습을 한다.
3) 2에서 학습한 두 네트워크에서 추출한 feature map을 Fusion한다.이를 머리 속에 두고 조금 더 자세히 알아보겠습니다.
Full-image Colorization & Instance Colorization
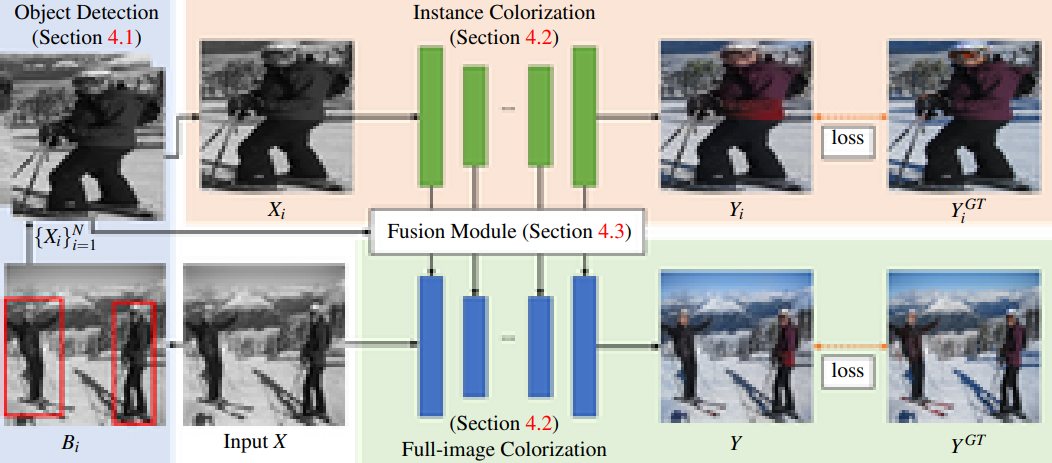
이미지 전체에 대해 Colorization을 하는 네트워크와 Object에 대해 Colorization을 하는 네트워크가 어떻게 동작 되는지에 대한 이미지입니다.
우선 입력으로 주어진 grayscale 이미지 X가 주어졌을 때, 모델은 사전학습 된 detection model을 이용해 X에 대해서 bounding box(Bi)를 찾기 시작합니다.
그 다음 탐지된 모든 object(Xi)를 잘라내고 Instance network에서 Xi를 colorization 하기 위해 사용됩니다.
하지만 Instance의 색상이 예측된 배경의 색과 양립할 수 없을 가능성이 있으므로 본 논문에서는 제안하는 Fusion module을 사용하여 추출된 전체 이미지 feature map과 모든 layer에서의 모든 Instance feature map을 fusion하는 것을 제안합니다.
Fusion module
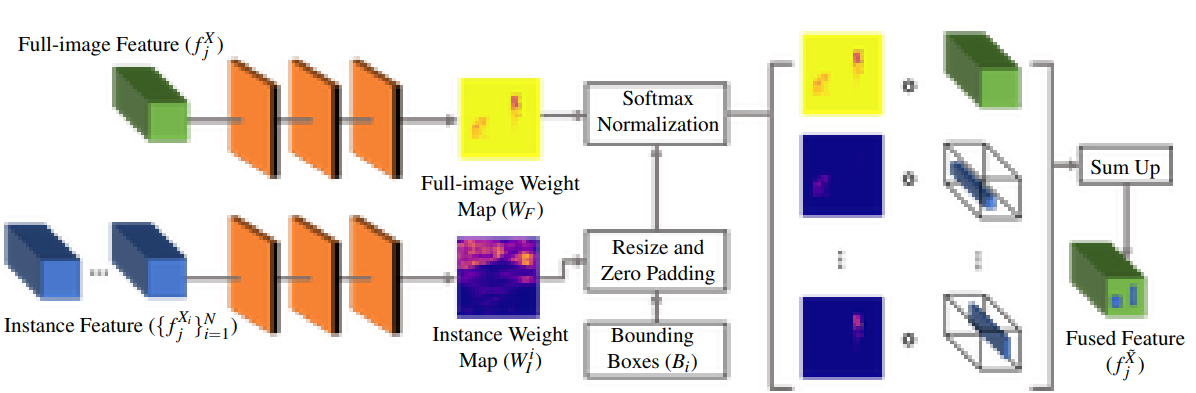
Fusion module의 input은 2가지 입니다.
(1)전체 이미지에 대해 학습하는 네트워크로 부터의 feature(fjX)
(2)object에 대해 학습하는 네트워크로 부터 feature(fjXi)와 그에 대응하는 bounding boxes(Bi)
fjX과 각각의 object에 대한 feature인 jXi를 합치기 위해object의 위치와 크기가 정의된 Bi를 이용합니다.
Fusion module에서 하는 일은 다음과 같습니다.
-
3개의 convolutional layers로 구성된 작은 network를 통해 WF와 WIi를 예측합니다.
-
그 다음 fjXi와 fjXi의 weight map(WIi)를 fjX과 fjX의 weight map(WF)의 사이즈에 맞게 resize합니다.
(이 때, padding은 0을 사용하고, resize된 fjXi와 WIi를 각각 f̄jXi W̄Ii라 합니다.) -
그 후 모든 weight map을 쌓고, 각각의 픽셀에 대해 softmax를 적용한 뒤, 아래에 나오는 식과 같이 weighted sum을 하여 fused feature를 얻을 수 있습니다.
(N : instance의 수)
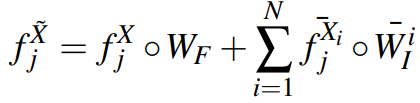
Loss Function and Training
본 논문에서 사용한 Loss Function은 Smooth-L1이고 δ=1이다.
(Real-Time User-Guided Image Colorization with Learned Deep Priors <- 해당 논문에서 사용한 Loss function을 따라서 사용했다고 함.)
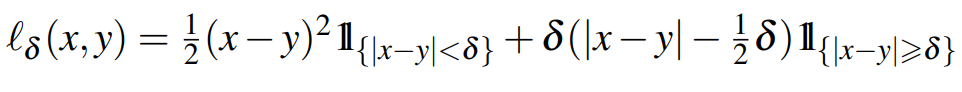
모델을 학습하는 순서는 다음과 같다.
1) full-image colorization을 학습시킨다
2) 1에서 학습된 모델의 weight로 Instance model을 초기화 한 뒤, 학습시킨다.
3) 마지막으로 1,2에서의 모델의 weight를 fusion module로 가져와서 학습시킨다.Result
Evaluation metrics.
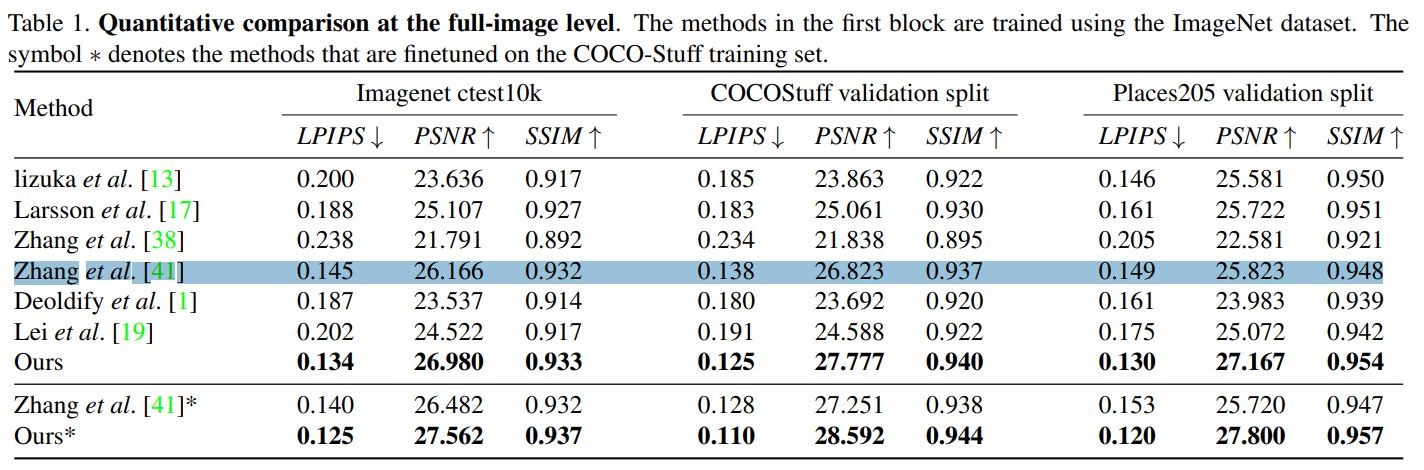
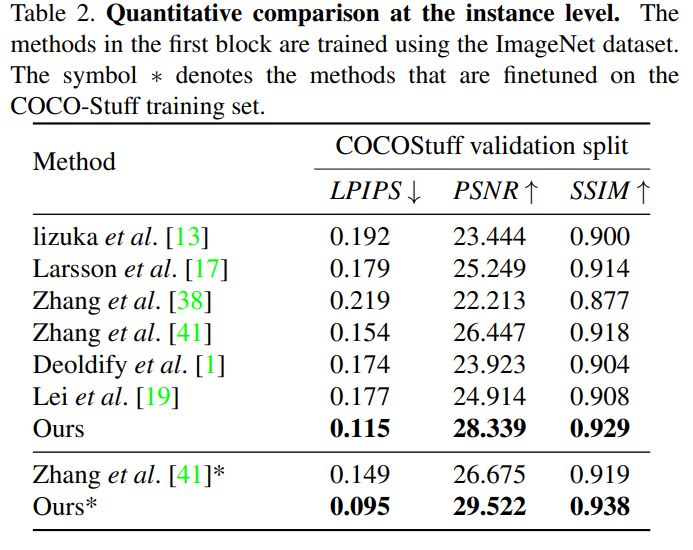
기존 Colorization methods에 의한 실험 평가방법을 따라, Colorization 품질을 정량화하기 위해 PSNR과 SSIM으로 평가를 했습니다.
Color 이미지에서 SSIM을 계산하기 위해 각각의 채널에서 계산된 SSIM 값의 평균을 구합니다.
추가적으로 지각 측정지표 LPIPS를 추가로 사용합니다.
full-image level 에서의 정량적 평가
instance level 에서의 정략적 평가
LPIPS는 신호가 가질 수 있는 최대 신호에 대한 잡음의 비를 나타내며 이미지 또는 영상 분야에서 생성 혹은 압축된 영상의 화질에 대한 손실 정보를 평가하기 위한 목적으로 사용한다. s는 영상에서의 최대 값으로서 해당 채널의 최댓값에서 최솟값을 뺀 값이다. 예를 들면 8-bit Gray 이미지일 경우 255(255-0)가 된다. 단위는 데시벨[db]을 사용하며 , 손실이 적을수록 높은 값을 가진다. 무손실 영상의 경우 MSE가 0 이 되기 때문에 PSNR은 정의되지 않는다.
SSIM은 수치적인 에러가 아닌 인간의 시각적 화질 차이 및 유사도를 평가하기 위해 고안된 방법이다. 사람의 시각 시스템은 이미지의 구조 정보를 도출하는데 특화되어 있기 때문에 구조 정보의 왜곡 정도가 지각에 큰 영향을 미친다는 것이 SSIM의 핵심 가설이다. 원본 이미지 A와 왜곡된 이미지 B 가 있다고 할 때 SSIM은 두 이미지의 휘도, 대비, 및 구조를 비교한다.
이게 detectron으로 object 탐지하고 탐지한 object를 crop해서 그 crop된 이미지에 있는 object에 대해 colorization하는 것 같은데 더 자세하게 세세하게 object를 colorization할거면 detection말고 segmentation이 낫지 않은가?
detectron이 segmentation보다 성능이 좋아서인가 ?
