
keywords : self-supervised representation learning, colorization
Abstract
Grayscale의 이미지가 입력으로 들어왔을 때, 그럴듯한 착각을 줄 수 있는 Colorization 결과가 나오는데 그러한 결과를 만들어내는 문제를 다루는 논문입니다.
쉽게 말하자면
회색빛이 도는 desaturated하게 나오는 현상(?)을 해결하겠다는 이야기이다.
이전까지의 방법들은 사용자와 상호작용에 크게 의존하거나 회색빛이 도는desaturated colorizations의 결과를 가져옵니다.

이 논문에서는 이런 desaturated하게 colorization 되는 문제를 classification으로 해결할 것이고 학습 할 때 클래스 rebalancing을 통해 결과로 나오는 색의 다양성을 증가시킬 것이라고 합니다.
++ 테스트 시에는 CNN에서 feed forward pass로 구현되며 100만개 이상의 컬러 영상에 대해 학습된다.
Introduction
이 논문의 궁극적인 목표는 GT와 완벽하게 같은 사진을 만드는 것이 아니라 사람을 속일 수 있는 "그럴듯한"사진을 만드는 것입니다.
시각적으로 설득력 있는 결과를 도출하기 위해 grayscale의 semantic, texture와 색상 version 사이의 통계적 의존성을 충분히 model한다.
>우리가 글을 읽을 때 문맥을 파악하고 글을 이해하는 것 처럼 사진도 주어진 상황을 파악하여 사진을 이해한다.
우선 모델은 lightness channel L로 Lab color sapce에서 이미지의 a,b color channel을 예측합니다.
(색을 예측 한다는 것은 어떠한 색의 이미지도 train data로 사용 될 수 있기에 제약이 없다는 nice한 특성을 갖습니다.)
어떤 색의 이미지이던 이미지의 L채널을 입력으로 a,b 채널을 정답으로 가져가면 train data로 사용할 수 있다는 것.
방금 Lab color space라는 말을 했는데 이것에 대해 조금 설명을 해보겠습니다.
Lab color space는 인간의 시각에 대한 연구를 바탕으로 정의된 것으로 L은 밝기, a와 b가 실질적인 색을 나타냅니다.
L값은 0~100사이이며 값이 커질수록 검은색에 가까워 집니다.
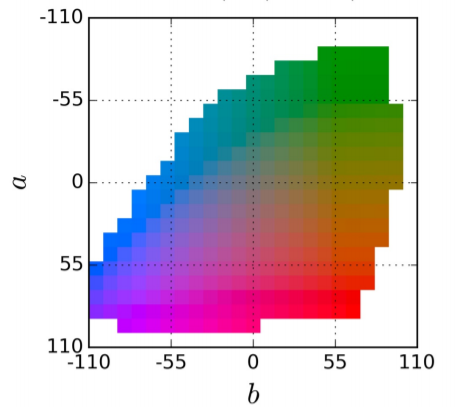
a값은 빨강과 초록 중 어느쪽으로 치우쳤는지를 나타냅니다. 값이 음수이면 초록에 치우친 색깔이며, 양수이면 빨강/보라 쪽으로 치우친 색입니다. b값은 노랑과 파랑을 나타냅니다. 값이 음수이면 파랑이고 양수이면 노랑입니다.
이전의 연구들은 색을 예측하기 위해서 CNN에서 학습되었습니다. 하지만 그로 부터 나온 결과는 desaturated했습니다.
사실 이런 문제는 conservative한 예측의 loss 함수를 사용하기 때문에 발생합니다. (일반적인 regression 문제로 부터 발생함.)
색을 예측 하는 것은 본질적으로 multimodal이라 할 수 있습니다. 예를 들어 바나나는 익기 전에는 초록색, 익은 후에는 노랑색을 갖는데 이렇게 2가지 modal을 갖기 때문에 multimodal하다고 할 수 있습니다.
문제의 multimodal을 적절히 model하기 위해, 각 픽셀의 가능한 색의 분포를 예측합니다.
또한 rare한 색을 보다 더 잘 표현하기 위해 학습할 때, loss를 re-weight한다.
앞서 말한 것과 같이 한 물체나 배경은 여러 종류의 색을 갖을 수 있기 때문에 각 픽셀에서 나타낼 수 있는 색의 분포를 예측하는 것입니다.
이러한 방법은 모델이 학습되는 많은 양의 데이터에서의 완전한 다양성을 이용할 수 있게 합니다. 마지막으로, 분포의 annealed-mean을 이용하여 마지막 colorization을 생성합니다. 그 결과는 이전 방법들 보다 더 생생하고 시각적으로 진짜같아 보인다.
이 논문은 앞서 말한 것 처럼 사람에게 "그럴듯"하게 보이는 이미지를 만드는 것이 목표이기 때문에 평가도 실제로 사람에게 진행했다.
결과로 32%의 참가자를 속이는데 성공했다.
그리고 이 테스트는 본 논문의 알고리즘이 거의 실제와 근접한 결과 즉, "그럴듯한" 이미지를 만들어 낸다는 것을 보여줍니다.
추가로 본 논문에서 제안한 방법으로 나온 결과를 이용해 downstream object classification task에서 사용해도 될 정도로 realistic하다는 것을 보여줍니다.
이전의 work들과 최근 연구인 self-supervision algorithms와 비교를 했을 때 성능 훨씬 잘 나왔다. 또한 다양한 평가방법에서 sota를 기록했습니다.
이전의 colorization 연구
비모수 방법과 모수 방법(None Parametric & Parametric)
비모수 방법 : 입력 grayscale image가 지정된 비모수 방법은 먼저 소스 데이터로 사용할 하나 이상의 색상 참조 이미지(사용자가 제공하거나 자동으로 검색)를 정의합니다.
그런 다음 Image Analogies(영상 아날로그) 프레임워크에 따라 색상이 기준 영상의 유사한 영역에서 입력 영상으로 전송됩니다.
모수 방법 : 파라메트릭 방법은 학습 시 컬러 이미지의 대규모 데이터 셋에서 예측 함수를 학습하여 문제를 연속적인 색 공간에 대한 회귀 또는 정량화된 색 값의 분류로 간주한다.
우리의 방법은 또한 색상을 분류하는 방법을 배우지만, 더 큰 모델로 그렇게 하고, 더 많은 데이터에 대해 훈련되며, 손실 함수와 최종 연속 출력에 매핑하는 몇 가지 혁신으로 그렇게 한다.
현재의 colorization 연구
본 논문이 쓰여질 당시, 대규모 데이터와 CNN을 활용하는 유사한 시스템을 개발하는 연구들이 있었습니다. 본 논문에서는 rare classes를 rebalance하는 classification loss를 사용했지만 다른 연구들에서는 un-rebalance 한 classification loss를 사용하거나, regression loss를 사용하였습니다.본 논문에서는 single-stream 구조를 사용했으며, VGG network에 depth와 dilated convolutions를 추가하여 사용했습니다.
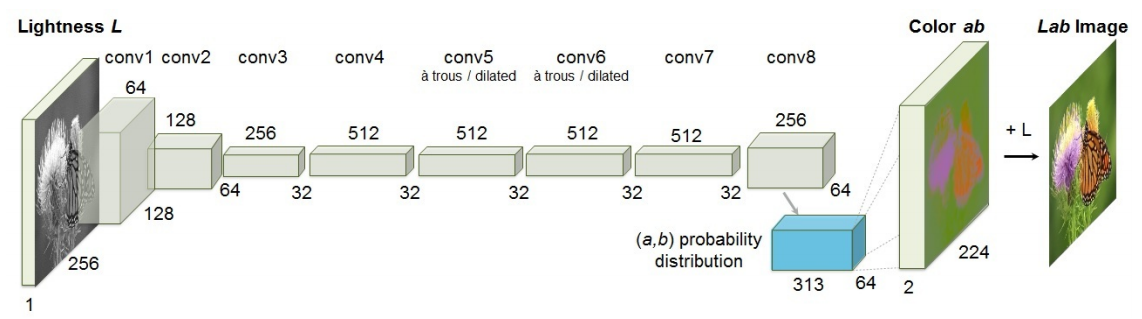
본 논문에서 제안한 네트워크의 구조입니다. 각각의 conv layer는 convolution 과 RELU가 2~3번씩 반복되고, batchnormalization도 있습니다. 이 네트워크의 특징이라면 특징인것이 있는데 그것은 바로 pool layer가 없다는 것입니다. resolution을 downsampling 하거나 upsampling하는 모든 과정은 conv blocks를 통해서 진행됩니다.
(conv layer와 pool의 차이점은 정확하게 뭘까?)
conv layer는 파라미터가 있음 => 학습을 한다는 의미
pool layer는 파라미터가 없음 => 학습을 안한다는 의미.
CNN이 위 그림에 표시된 구조를 사용하여 grayscale 입력에서 정량화된 색상 값 출력에 대한 분포로 mapping하도록 학습합니다.
Objective Function
(H,W,1)의 lightness channel에서, (H,W,2)인 2개의 컬러채널과 관련된 Yhat을 mapping하는 함수를 학습하는 것이 목표입니다.색 분포에서 가능한 색을 찾는다는 의미로 생각하면 됨.
만약 어떤 object가 구별되는 ab값을 취할 수 있다면, 유클리드 loss에 대한 최적의 해결책은 ab의 평균이 될 것입니다.
그렇지만 색상 예측에서 이 평균을 이용한 유클리드 loss는 회색빛이 도는 desaturated한 결과를 야기합니다.
이러한 loss는 Colorization 문제의 고유한 모호성과multimodal 특성에 대해 강인하지 않습니다.
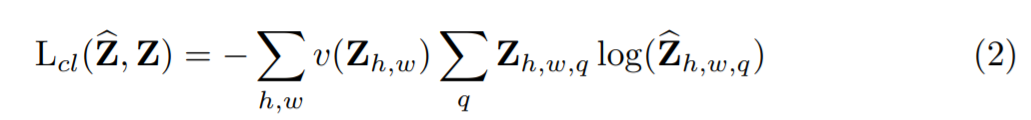
ab값이 나타낼 수 있는 색의 개수를 Q라 하고, Zhat을 그런 가능한 색에 대한 확률적 분포라 할 때,입력 X에 대해 Zhat을 mapping하는 것을 학습합니다.
이렇게 예측한 Zhat과 GT를 비교하려면 같은 형태가 되어야 하기에 GT도 이런 분포를 띄는 벡터로 바꿔줍니다.
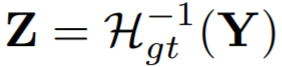
GT인 이미지 Y를 분포벡터 Z로 바꾸는 함수를 위와 같이 정의합니다.
본 논문은 다음과 같은 loss 함수를 사용하여 앞서 말한 두 값의 loss를 구합니다.
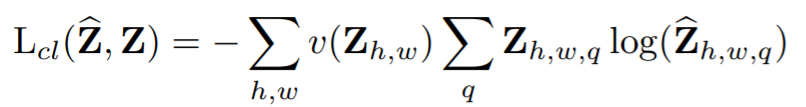
이 식에서 v()는 색의 rare함에 따른 weighting term으로 rare한 색의 class를 rebalance할 수 있습니다.
Class rebalancing
natural한 이미지에 대해서 ab값의 분포는 낮은 값으로 편향되어 있습니다. 이러한 결과는 구름, 포장도로, 흙, 벽과 같은 배경들이 낮은 값을 갖고 있기 때문입니다.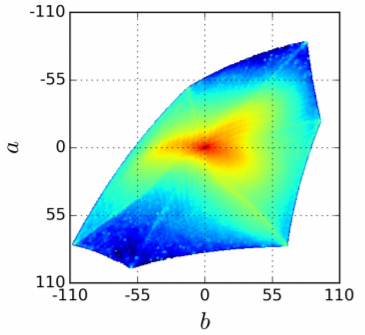
사진에 보이는 것과 같이 가운데에 많은 확률이 분포하고 있습니다. 이것은 결국 desaturated하게 될 확률이 높다는 의미가 됩니다. 이러한 색의 불균형을 해결하기 위해 학습 시 각 픽셀이 가지는 색의 rarity를 기반으로 loss를 reweighting하는 방법을 사용합니다.
각 픽셀은 그 픽셀과 가장 가까운 ab bin(픽셀을 이야기 하는 것 같음)의 weight를 기반으로 reweight됩니다.
Class Probabilities to Point Estimates
예측한 분포벡터 Zhat을 ab space에 있는 한 점인 Yhat 으로 mapping하는 함수인 H를 구해야합니다. 방법은 2가지가 있고 하나는 각 픽셀에 대한 예측된 분포의 mode를 취하는 방법이고 다른 방법은 mean을 취하는 것입니다.mode를 취하는 방법은 선명하게 보일 수 있지만 중간중간에 전혀 관계없는 색이 채워질 수 있습니다.
반면에 mean을 취하는 방법은 전혀 관계없는 색이 나오지는 않지만 desaturated한 결과를 가져옵니다.
그렇다면 두 방법의 중간점을 구하면 중간중간 관계없는 값이 나오는 현상과 desaturated한 현상을 해결할 수 있지 않을까? 라는 생각이 듭니다.
그래서 두 방법에서의 중간점을 찾기 위해 softma 분포의 온도 T를 조정하고 결과의 평균을 구하여 interpolate합니다.
일단 식은 다음과 같습니다.
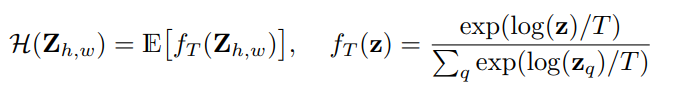
이 개념은 현실에서 물리적인 담금질을 하는 과정으로 부터 나온 개념이며 담글질은 금속을 뜨겁게 달구었다가 천천히 냉각시키면서 강화시키는 것
입니다.
물리적 담금질로 부터 만들어진 개념이기 때문에 온도 T라는 변수가 있는 것이고 이 온도 T를 1로 설정하면 분포가 변하지 않고, T를 낮출수록 더 강한(desaturated하지 않은) 분포가 형성됩니다. 그리고 T가 0이면 앞서 말한 Mode에서의 분포가 됩니다.

본 논문에서는 T값이 0.38일 때 최적의 분포가 나온다고 합니다.
Result

앞서 얘기했던 regression을 포함한 다른 방법들과의 차이를 보여주는 결과입니다.
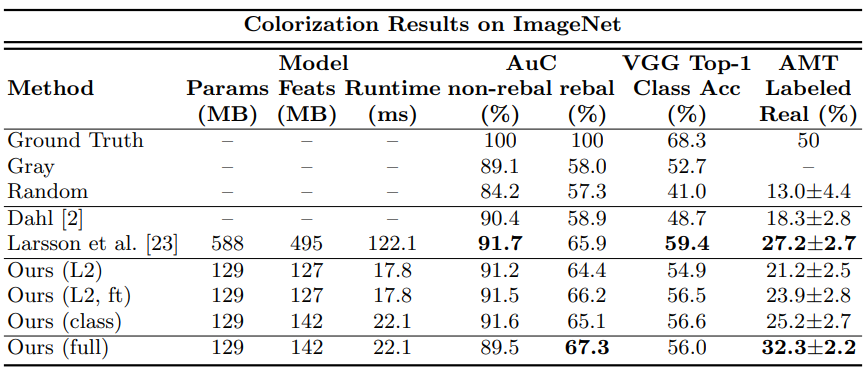
평가 방법은 Perceptual realism(AMT), Semantic interpretability (VGG classification), Raw accuracy(AuC) 3가지로 나뉘어집니다. 하지만 이 논문에서는 진짜같은 '그럴듯한' 이미지를 만드는 것이 목적이기에 AMT가 이 논문에서 만들어낸 결과에 대한 조금 더 정확한 평가라고 할 수 있습니다.
AMT(Amazon Mechanical Turk)는 사람에게 직접 평가를 하게 하는 방법이며 실험에 참가한 사람에게 GT 이미지와 모델이 만들어낸 이미지를 보여주고 둘 중 진짜를 찾게 하는 것이다. 물론 사진은 1초만 보여줬다고 합니다.
이 방법을 사용하였을 때가 다른 평가 방법보다 본 논문에서 제안한 모델에 대한 성능이 제일 좋게 나온다. 당연한 결과라 생각한다.
결론
사람이 보기에 '그럴듯한' 사진을 만들기에 성공했다.
근데 갑자기 생각난 것인데 Colorization과 GAN이 다른 방식이지만 이렇게 사람이 보기에 input으로 들어가는 이미지와 같게 보이게 하는 것이 목적이라면 GAN이 더 나을 수 있겠다는 생각도 들었다. 물론 GAN에 대해 아직은 잘 모른다.
