
작성자 : 성균관대학교 사회학과 박지은
1. Self-Supervised Learning (자기지도학습)
1-1. 필요성
레이블링의 단점
- Supervised learning(지도학습)은 강력하지만 많은 양의 레이블링된 데이터 필요
- 많은 양의 양질의 데이터만 있다면 좋은 성능을 낼 수 있음
- 하지만 이는 레이블링된 데이터가 없으면 사용 불가능하다는 문제가 있음
- 레이블링 작업자의 편향된 사전 지식 포함될 수 있음
- 레이블링에 매우 많은 시간 소요 (목적 태스크 복잡할수록)
GAN의 불안정성
- GAN은 높은 차원의 파라미터 공간의 non-convex한 문제에서 내쉬 균형을 찾기 때문에 학습이 어려움
- 자기지도학습을 사용하면 학습이 더 쉬워서 과거의 정보를 더 기억할 수 있음
- 학습이 진행될수록 생성자는 점점 더 실제 데이터에 가까운 데이터 분포를 만들어내는 non-stationary한 환경
- 뉴럴 네트워크는 학습 데이터의 도메인이 바뀌는 동적인 상황에서 과거의 데이터 잊음
- ex) conditional model: real/fake를 구분하는 것뿐만 아니라 cat/dog도 구분하며 계속 학습하여, 새 데이터에 대하여 판별자가 구분해서 condition 습득 후 real/fake 구분을 진행하면 학습이 더 쉽고 안정적
- supervision signal이 학습에 불필요한 편향을 줄 수 있음
{kind=link}
1-2. 정의
{kind=link}
- 레이블링 된 데이터셋으로 모델을 학습하는 지도학습과 달리, 다량의 레이블이 없는 원데이터로부터 데이터 부분들의 관계를 통해 레이블을 자동으로 생성하여 지도학습에 이용 (비지도학습 기법 중 하나)
- 데이터의 일부분을 은닉하여 모델이 그 부분을 예측하도록 학습
- 프리텍스트 태스크(pretext task): 딥러닝 네트워크가 어떤 문제를 해결하는 과정에서 데이터 내의 semantic한 정보를 이해할 수 있도록 학습하게 하는 임의의 태스크 (사용자 임의대로 정의)
- 레이블이 없는 데이터를 이해하도록 프리텍스트 태스크를 위한 레이블을 직접 생성하여 모델을 학습하거나 데이터 간의 관계를 이용하여 학습
- 이렇게 사전학습된 모델을 데이터셋을 representation learning하여 다른 태스크로 전이시켜 사용
⇒ 새로운 태스크에서 소량의 데이터만으로 semantic representation을 찾게 하여 좋은 성능을 내는 전이학습(transfer learning)
Pipelines
- 레이블링 없는 데이터를 프리텍스트 태스크로 학습
{kind=link}
2-1. 학습된 특징들로 분류기를 학습하여 더 적은 레이블을 가진 새로운 데이터에도 적용 가능하게 학습
{kind=link}
2-2. 더 적은 레이블의 새로운 데이터에도 적용 가능하도록 파인튜닝
{kind=link}
- 원래 처음 모델을 고정하고, 그로부터 추출된 특징인 z를 사용하는 방식이나 실제로는 전체 네트워크를 파인 튜닝하고, 더 다양한 방식을 포함하여 다운스트림 태스크를 처리
1-3. 장점
- 각 태스크에 따른 새로운 데이터셋을 구축하는 비용과 시간을 줄일 수 있음
ex) 웹, 클라우드 상에 존재하는 다량의 비디오, 이미지, 텍스트 데이터들 별도 레이블링 없이 사전학습 가능 - 사람으로 인한 데이터셋 편향 현상 최소화
- 특정 태스크에서만 동작하는 모델이 아닌 범용성을 가지는 모델을 학습할 수 있음
(기존의 지도학습은 원데이터 목적에 따른 태스크에 알맞은 레이블을 할당하여 학습에 이용)
1-4. 연구의 분류
- 데이터의 부분 데이터나 손상된 부분으로부터 생성 및 재건
- 시각적 상식이나 문맥을 이용
- 대조 학습
2. 초창기의 GAN 기반 자기지도학습
- 재건 및 생성 기반 모델들은 픽셀 단위로 복원하거나 예측하기 때문에 계산 복잡도가 높다는 단점이 있음
2-1. 오토인코더
- 데이터에 대한 표현 학습을 위한 자기지도학습 기법
- 신경망을 통해 재건한 출력 데이터의 정답 레이블로 입력 데이터를 사용하여 입력과 출력의 결과가 같도록 학습
- 학습한 네트워크의 히든 레이어는 입력데이터보다 낮은 차원의 벡터로 압축되어 표현되는 이 벡터가 원본 데이터를 가장 잘 표현할 수 있는 특성 정보를 인코딩
example
- 디노이징 모델: 원본 이미지에 노이즈를 삽입하여 신경망의 입력으로 사용한 다음, 원본 이미지으로 다시 복원
- 색상화(Colorization): 이미지의 색상 정보 분리하여 흑백 채널을 네트워크에 입력 → 색상정보 예측
{kind=link}
2-2. SSGAN (Self-Supervised GAN)
rotation-based 자기지도학습
{kind=link}
rotation 기반 self-supervision의 판별자는 이미지의 real/fake 여부와 rotation degree 총 2가지를 구분합니다. real 이미지와 fake 이미지 모두 0, 90, 180, 270도로 회전되고, 화살표를 보면 회전되지 않은 이미지만 real/fake의 classification loss task에 쓰인다고 합니다! 또한 rotation loss에 대해서는 회전된 이미지를 회전된 각도에 따라 구분한다고 하네요.
- 생성자가 만든 이미지에 대해 rotation하고, rotation 얼마나 했는지 cross entropy loss로 만들어서 GAN loss에 더함
- identity한 이미지에 대해서 real/fake 구분, 나머지 이미지에 대해서는 rotation angle 학습
판별자 forgetting 방지
{kind=link}
- ImageNet의 선형 분류 모델
- 500k번 넘어가면 Uncond-GAN의 정보 손실 일어남
{kind=link}
- 1k번 반복할 때마다 클래스의 분포가 바뀔 경우 이미지 분류 문제의 정확성
- 동적인 환경에서는 분류기가 일반화 가능한 특징을 학습하기 어려울 수도 있음
rotation-based loss function
- 기존의 GAN loss function에 cross entropy loss와 hyper-parameter 곱해줌
{kind=link}
- GAN value function
{kind=link}
experiments
-
Details
-
dataset
-
GAN: spectral normalization GAN with self-modulated batch normalization
-
하이퍼파라미터: Ir 0.0002, alpha 0.2, beta 1, Adam optimizer, Batch size 16 x 4 augmentation
-
-
Result
- gradient penalty
- unconditional GAN: 같은 hyper-parameter이어도 결과의 질이 낮고 결과의 variation이 높음
- self-supervision GAN: hyper-parameter가 같으면 같은 결과
- spectral normalization: 성능이 더 좋아짐
- FID: 이미지 생성 결과는 conditional GAN이 더 좋지만 그 다음으로 SSGAN이 좋음 (성능 비슷함)
→ conditional GAN은 각 이미지에 대한 label이 필요하지만 SSGAN은 데이터에 대한 label이 필요 없음 - classification task → 좋은 representation 도출
- Image → Trained Discriminator + classifier (training from zero to converge)
- Rot-only: rotation만 사용하여 학습 (GAN 사용 안 함) → 협력하여 학습하므로 SSGAN이 더 성능 좋음
- 학습을 하면 할수록 좋은 representation 도출
- gradient penalty
{kind=link}
{kind=link}
example
-
Image Completion: 이미지에서 일부분만 제거한 뒤 신경망의 입력으로 사용하고 제거한 영역을 복원
→ 오토인코더로 이미지 복원하며 복원된 데이터인지 실제 데이터인지를 판별하는 판별 네트워크를 두어 적대적으로 학습
-
초해상도 복원 (Super-resolution): 원본 이미지를 해상도가 낮은 영상으로 변형한 뒤 다시 해상도를 높임
ex) BigGAN(고해상도 이미지 생성 가능) + BiGAN(이미지로부터 유사도 추출) = BigBiGAN
3. 프리텍스트 태스크를 이용한 자기지도학습 방법
3-1. 구조 유추 (Inferring Structure)
1) 맥락 예측 (Context Prediction)
- 모델이 object의 부분을 인지하고 공간적 관계를 파악하는 것을 학습
{kind=link}
-
과정
- 이미지 패치로 분할
- 중심 패치와 이웃에서 다른 패치 가져옴
- 각 패치를 같은 네트워크에 입력
- 특징을 concate하여 분류기에 넣음
- cross-entropy loss → 이웃 패치 파악
-
장점
- 최초의 자기지도학습 방법
- object의 부분에 대하여 학습하게 하는 직관적인 태스크
-
단점
-
학습 이미지의 표준성 전제
ex) 인공위성 사진
-
이미지의 representation이 목적이지만 패치를 학습
-
다른 이미지의 negative가 없기 때문에 충분히 fine-grained 하지 않음
-
output space가 작음: 8가지 선택지 밖에 없어서 출력에 대한 경우의 수가 너무 작음
-
2) Jigsaw puzzles
- 이미지를 패치로 분할하고 순서를 바꿈
- 네트워크가 순서를 예측하는 것이 목표
- 맥락 예측과 비슷하지만 더 어려움
{kind=link}
3-2. 변환 예측 (Transformation Prediction)
1) 회전 예측 (Rotation prediction)
- 원래 이미지의 canonical한 orientation 잘 이해해야 함 → 이미지의 전반적 특징 잘 학습 가능
{kind=link}
{kind=link}
-
장점
- 적용이 용이함
-
단점
-
학습 이미지의 표준성 전제
-
train-eval gap: eval에는 회전된 이미지가 없음
-
다른 이미지의 negative가 없기 때문에 충분히 fine-grained 하지 않음
-
output space가 작음
-
domain이 사소한 경우
ex) 거리 사진에서 하늘만 인식
-
2) 상대적 변환 예측 (Relative transformation prediction)
{kind=link}
⇒ 잘 매칭되기 위해서 좋은 feature 필요
{kind=link}
-
장점
- 고전파 컴퓨터 비전의 SIFT 등과 일치 (특징점 추출, 주 방향 결정, descriptor 생성)
-
단점
-
train-eval gap: eval에는 변환된 이미지가 없음
-
다른 이미지의 negative가 없기 때문에 충분히 fine-grained 하지 않음
-
semantic의 중요성 vs. 낮은 수준의 특징
→ how much semantics do you need to solve this task? features are potentially not invariant to transformations
-
3-3. 재건 (Reconstruction)
- 재건을 통해 annotation 없이 이미지의 특징을 학습할 수 있음
- 이미지 복원 과정 → 네트워크가 영상 전반의 representation을 학습 할 수 있게 된다는 가정
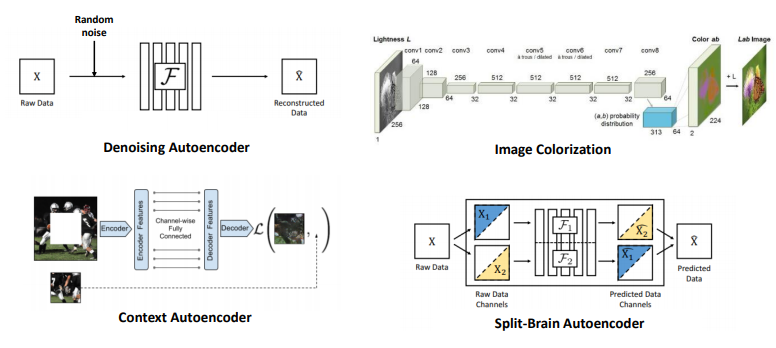
1) 디노이징 오토인코더 (Denoising Autoencoders)
- 랜덤 노이즈가 섞인 원본 raw data에서 네트워크를 거쳐 원본 raw data를 복원하는 방법
{kind=link}
- 장점
- 간단하고 정통적인 방식: denoising 간편
- 단점
- train-eval gap: 노이즈가 있는 데이터를 학습
- 너무 간단해서 semantics가 필요 없음
2) 맥락 인코더 (Context Encoders)
- 영상 내 중간에 뚫린 부분을 추측/복원하는 방법
{kind=link}
⇒ object를 인식하면 더 쉬움 (perceptual loss - 판별자)
-
자연어처리(NLP)
-
ex) BERT: 레이블이 없는 데이터셋을 먼저 훈련시킨 다음 작은 레이블이 있는 데이터셋에서 파인 튜닝하여 몇 가지 클래스 레이블로 좋은 결과 얻음
All [MASK] have tusks. ⇒ All elephants have tusks.
-
-
장점
- fine-grained 정보 보존하게 함
-
단점
-
train-eval gap: masking된 부분이 eval에는 없음
-
재건 자체가 너무 어렵고 모호함
-
불필요한 세부 사항에 소모적
ex) 색, 경계
-
3) 색상화 (Colorization)
- 흑백 영상을 색을 입혀 컬러 영상으로 바꿔주는 방법
{kind=link}
⇒ object가 무엇인지 인지하지 못하면 어려움
- 장점
- fine-grained 정보 보존하게 함
- 단점
- 재건 자체가 너무 어렵고 모호함
- 불필요한 세부 사항에 소모적
- 그레이스케일 이미지를 평가해야 하므로 정보 손실이 야기됨
4) Split-brain encoders
- 맥락 인코더 ⇒ Split-brain encoders
- 이미지의 절반을 잘랐을 때, 네트워크가 나머지 잘린 이미지 절반을 맞추도록 하는 방법
{kind=link}
- 2개의 가지: 그레이스케일 이미지 → 컬러 이미지, 컬러 이미지 → 그레이스케일 이미지
- 장점
- fine-grained 정보 보존하게 함
- 단점
- 재건 자체가 너무 어렵고 모호함
- 불필요한 세부 사항에 소모적
- 입력을 독립적으로 처리
5) bag-of-words 예측 (Predicting bag-of-words)
- NLP에서 영감: 이산적 타겟인 단어들의 출현 빈도에 집중하는 텍스트 데이터의 수치화 표현 방법
- BoW (Bag-of-Words)
- 각 단어에 고유한 정수 인덱스 부여
- 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터 만듦
{kind=link}
{kind=link}
Visualization of Clusters
- 과정
- 특징 추출
- 이미지를 BoW로 represent: visual words에 특징 부여
- 클러스터 → 중간 수준과 높은 수준의 개념을 인코딩
- 이미지 왜곡하여 BoWNet에 넣어 학습
- BoW representation 예측
{kind=link}
-
장점
- 왜곡된 이미지로부터 BoW 재건 → representation이 원하는 변환에 강건함
- 맥락적 추론 학습 가능
-
단점
-
pre-trained 네트워크에서 부트스트래핑(bootstrapping) 필요
→ 더 fine-grained한 특징은 학습, 재발견 어려움
-
BoW로 집화(aggregate) → 공간 정보 손실
-
3-4. 인스턴스 분류 (Instance Classification)
1) Exemplar ConvNets
{kind=link}
{kind=link}
-
이미지에서 분할 추출하여 변형 → 같은 원본 이미지 고르기를 가진 분할 사진 고르기
-
수행된 기하학적이나 색상 관련 변환에 강건하면 쉬움
-
과정
-
96x96 크기의 영상 내에서 considerable한 gradient가 있는(객체가 존재할 만한 영역) 부분을 32x32 크기로 crop
-
하나의 이미지 당 이렇게 crop된 32x32 크기의 패치를 seed patch로 하고, 이 seed patch가 하나의 class를 의미하도록 함
-
seed patch를 data augmentation에 사용하는 transformation들을 적용시켜 추가 영상을 만듦
-
하나의 seed image 여러 장 만들어 같은 class 가지도록 학습

-
{kind=link}
-
장점
- representations이 원하는 변환에 강건함
- fine-grained 정보 보존하게 함
-
단점
-
exemplar 기반으로, 같은 클래스에서 생성된 이미지나 인스턴스가 negative로 쓰임
(nothing prevents it from focusing on the background)
-
N개의 영상에 N개의 클래스 존재 → 학습 난이도가 올라가며 파라미터수도 매우 많아지게 됨
⇒ 큰 데이터셋에는 적합하지 않음 (number of classes = data size)
-
2) CPC (Contrastive Predictive Coding)
잘 구성된 representation은 data efficiency를 향상시킵니다. 하지만 실제 visual task에서는 그러한 representation을 찾는 것이 어렵다고 합니다. 대신 시공간 변동성을 인식하는 효율성 개선에 능력이 효과적이라고 밝혀졌는데, 이를 위해 representation의 predictability가 data efficiency의 중요한 역할이라 가정하고 contrastive predictive coding(CPC)이 제안되었습니다.
- 관찰이 시간적 또는 공간적 차원과 같이 순서에 따라 이루어지도록 요구하는 기술
- 고차원 데이터를 더 작은 임베딩 공간으로 압축하여 회귀 모델을 이용하여 예측 수행
- 작업 자체와 관련이 적은 세부 사항은 한 걸음 물러나 노이즈로 간주하여 의미있는 맥락 학습
- 압축된 representation & 현재 패치와 미래의 타겟 패치와의 공통 정보를 참조
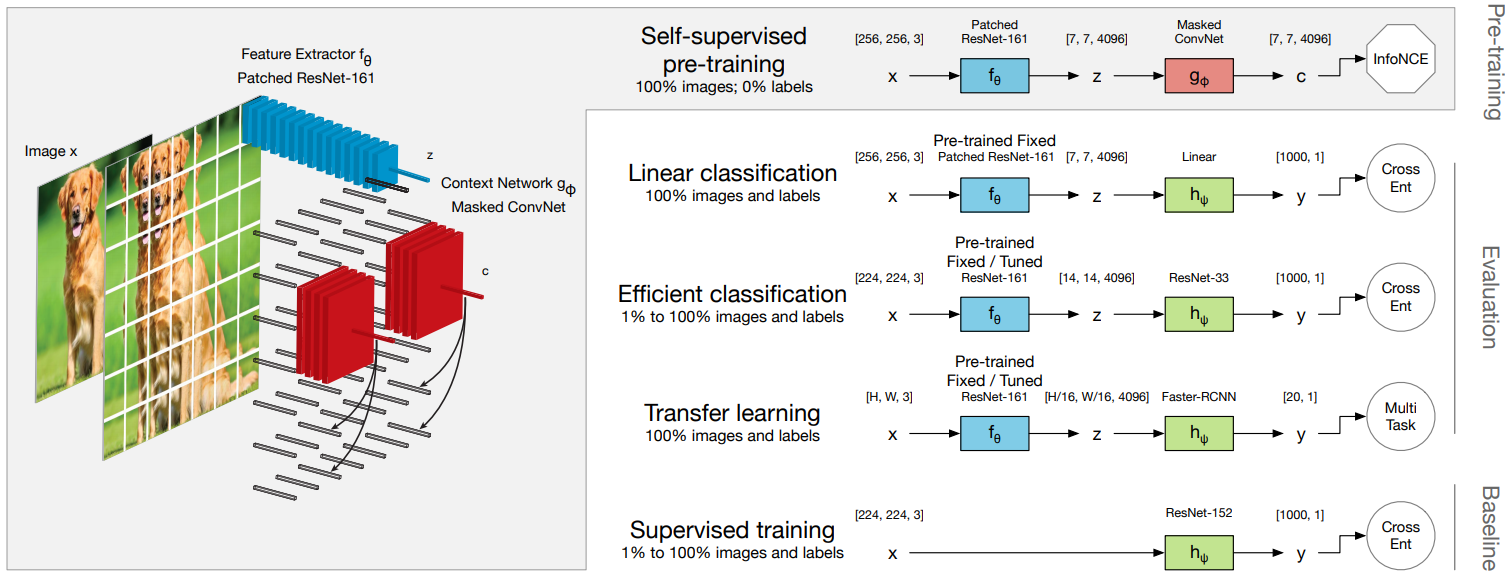
- 입력 이미지를 중복 패치 x_i,j로 나눔
- 각 패치를 encoder network fθ에 넣어 single vector z_i,j = fθ(x_i,j)를 만듦
- z 뭉치를 context network g_ϕ에 넣어 context vector c_i,j를 만듦
- mask는 c_i,j의 receptive field가 {z_u,v}_u≤i,v가 되도록 함
- prediction matrix W_k(prediction length k>0)를 이용하여 z^_i+k,j=W_kci,j 예측
-
c_i,j와 z_i+k,j의 상호 정보량이 최대가 되도록 L_CPC를 이용하여 학습
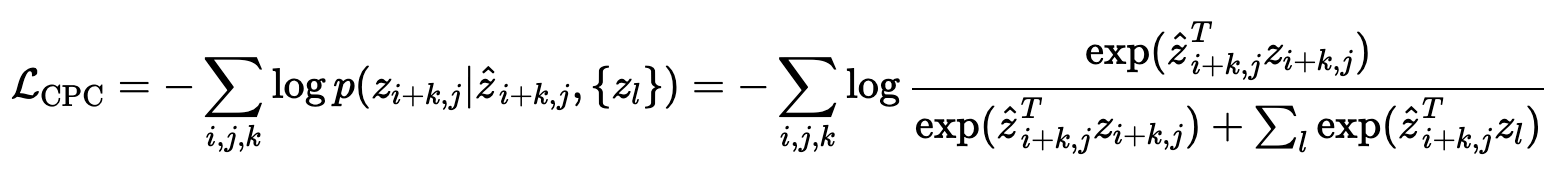
(z_l: negative samples, 이미지의 다른 위치나 배치 안의 다른 이미지에서 무작위로 뽑은 feature vectors)
- InfoNCE loss 사용
- NCE(Noise Contrastive Estimation)를 통해 상호 정보량을 최대화 → {predict, correct, negatives} 비교
- 단순 cross-entropy를 이용하기에는 클래스 수가 너무 많아서 비효율적 → good/bad 판별하는 이진 분류 사용
- 각각의 c_t마다 x_1, x_2, ..., x_n 중 실제 x를 예측해야 함
- negatives: 이미지의 다른 위치나 배치 안의 다른 이미지에서 무작위로 뽑은 특징 벡터
{kind=link}
-
overview
-
비선형 인코더 g_enc가 입력 시퀀스 x_t를 latent representation의 시퀀스 z_t = g_enc(x_t)에 매핑
-
자동회귀모델 g_ar가 t 이전의 z로 맥락 c_t = g_ar 생성
-
이 때, 바로 x_t+3을 예측하는 것이 아니라 density ratio를 모델링함
-
인코더와 NCE, 중요도 샘플링을 통해 density ratio에서 무작위로 샘플링 된 negative와 target 비교
-
-
장점
- 이미지, 영상, 음성, NLP 등에 쉽게 적용이 가능한 포괄적인 프레임워크
- exemplar: fine-grained 정보를 보존하게 함
- 맥락 예측: object의 부분에 대해 학습이 가능하게 함
-
단점
- exemplar 기반: 같은 클래스 내의 이미지나 인스턴스가 negatives
- train-eval gap: 학습은 패치로, 평가는 이미지로 함
- 학습 이미지의 표준화 전제
- 패치를 분할하기 때문에 학습 시간이 오래 걸림
{kind=link}
3) Count
-
한 patch의 object의 특징들을 가상의 vector로 표현함
ex) 각 패치 안에 코 2개, 눈 4개, 머리 1개 등
→ 이런 특징들은 각 패치나 전체 영상이 up/down sampling 되어도 유지가 되어야 함
-
각 패치의 특징 벡터들의 합은 원래 이미지의 특징 벡터의 합과 같다는 가설에서 제안
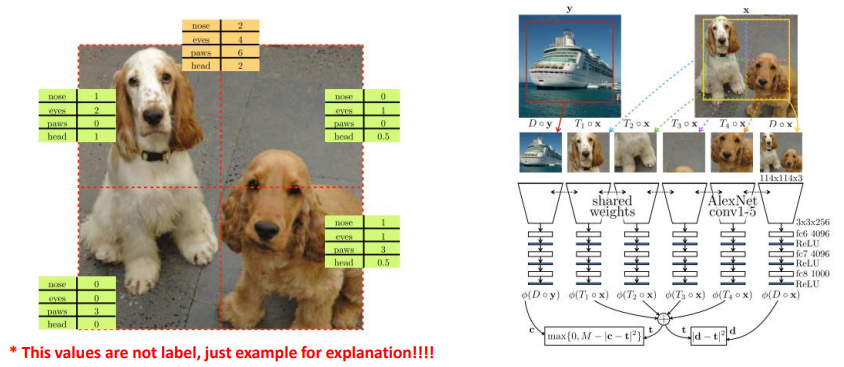
-
과정
- 이미지를 네트워크에 넣고, feature extractor를 통해서 최종 출력으로 위와 같은 패치별 특징 벡터를 구하도록 모델 구현
- 원본 이미지를 down scaling 했을 때 추론되는 특징 벡터 D의 합 = 패치별 네트워크를 지나서 얻은 T들의 합
-
L2 loss 사용, 모든 특징 벡터를 0으로 출력하는 trivial loss 될 수도 있음
→ sample supervision 학습: 패치로 잘리는 영상 x와 완전히 다른 영상 y를 넣었을 때 다른 feature 벡터가 나오도록 하는 contrastive loss를 추가
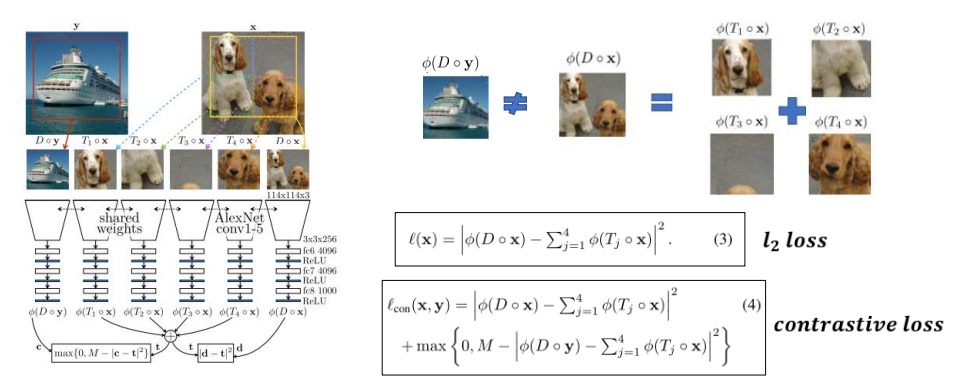
3-5. 시간적 관계
- 영상에서 시간에 따른 일관성을 고려한 프레임의 재건 또는 생성을 이용하여 자기지도학습 수행
1) Optical Flow & SURF 특징점 기반의 추적 기법
- Optical Flow (광학 흐름): 2개의 연속된 영상 프레임 사이에 이미지 객체의 가시적 동작 패턴
- SURF 특징점: SIFT보다 빠르게 semantic한 특징 추출 가능한 특징점 기반 알고리즘
(Speed-Up Robust Feature) - 영상 내 특정 패치를 단시간 추적하여 추적된 패치들과의 관계를 이용하여 학습에 이용
- 같은 패치로부터 추적된 패치들은 서로 positive 쌍, 다른 패치나 다른 영상으로부터 추출된 패치는 negative 쌍
- 양성 쌍 패치의 임베딩된 특징점 사이의 거리는 음성 쌍 패치의 거리보다 항상 작도록 triplet loss를 이용하여 학습 (대조 학습(Contrastive Learning))
- baseline인 anchor를 positive, negative input과 비교
- anchor input과 positive input 사이의 거리 최소화, negative input과의 거리 최대화 (유클리디안 거리)
- 임베딩 학습의 목적으로 유사성을 학습하는 데 사용
{kind=link}
2) 영상 내 프레임들의 시간적 순서 맞추기
- 영상 프레임들은 일반적으로 시간에 따른 순서를 따라 위치
- 프레임 사이의 움직임에 집중하도록 학습
- 과정
- 움직임이 많이 발생하는 구간에서 3개의 프레임을 고름
- 이들의 시간적 순서가 항상 증가하도록 나열된 튜플을 positive 튜플로, 시간 순서가 뒤섞인 튜플을 negative 튜플로 둠
- positive 튜플은 1, negative 튜플은 0으로 예측하도록 학습
3) 영상의 색상화
- 회색조로 변환한 영상 내의 두 프레임 사이의 자연스러운 시간적 연관성을 고려하여 이전 프레임에서 색상을 복사하여 다음 프레임의 색 예측
- 임베딩된 feature map의 유사도 비교 → 두 프레임 사이의 매칭을 구하여 이 관계를 통해 이전 프레임의 색상 정보를 다음 프레임으로 복사
- 복사를 통해 복원된 다음 프레임의 색상 정보를 그 프레임의 원래 색상값과 비교하여 손실 함수 계산
→ 레이블링이 매우 오래 걸리는 영상 분할과 사람 자세 예측 태스크에서 레이블링된 데이터 없이 자기지도학습만으로 잘 동작
{kind=link}
3-6. 대조 학습 (Contrastive Learning)
- 2개의 샘플이 하나의 쌍을 이루어 네트워크의 입력으로 사용되며 그 데이터들이 서로 비슷한지 학습
(2006년 Yann Lecun) - 두 샘플이 서로 다른 negative 쌍: 모든 negative 쌍을 고려하는 것은 불가능한 일이므로 학습에 도움이 되는 음성 쌍을 잘 골라내는 것이 대조 학습의 목표
{kind=link}
1) MoCo (Momentum contrast for unsupervised visual representation learning)
-
contrastive loss를 이용한 비지도학습
-
데이터를 인코더에 통과시켜 key와 query를 만듦
-
query와 매칭되는 key와 유사하게, 매칭되지 않는 key와는 차별화되도록 학습
-
인코딩된 key들을 queue에 삽입하여 dictionary 구성
⇒ dictionary는 클수록, key는 consistent할수록 좋음
-
-
Momentum Contrast
{kind=link}
- 비교에 사용 되는 key dictionary를 queue로 사용
- 미니배치 크기와 무관하게 커질 수 있음 → 더 많은 negative 쌍 고려 가능
- 직전에 계산된 미니배치의 encoded representation이 queue에 들어오면 가장 오래된 representation 삭제하여 dictionary를 consistent하게 유지
- momentum update
- queue로 dictionary를 크게 만들면 queue 안의 모든 샘플에 대해 gradient를 역전파해야 하므로 key를 학습시키기 어려움
- key 인코더를 query 인코더와 분리 → query 인코더의 파라미터에 momentum 가중치를 주어 아주 천천히 업데이트 → 키 인코더의 표현이 천천히 일관되게 변화하도록 함
2) SimCLR (A simple framework for contrastive learning of visual representations)
{kind=link}
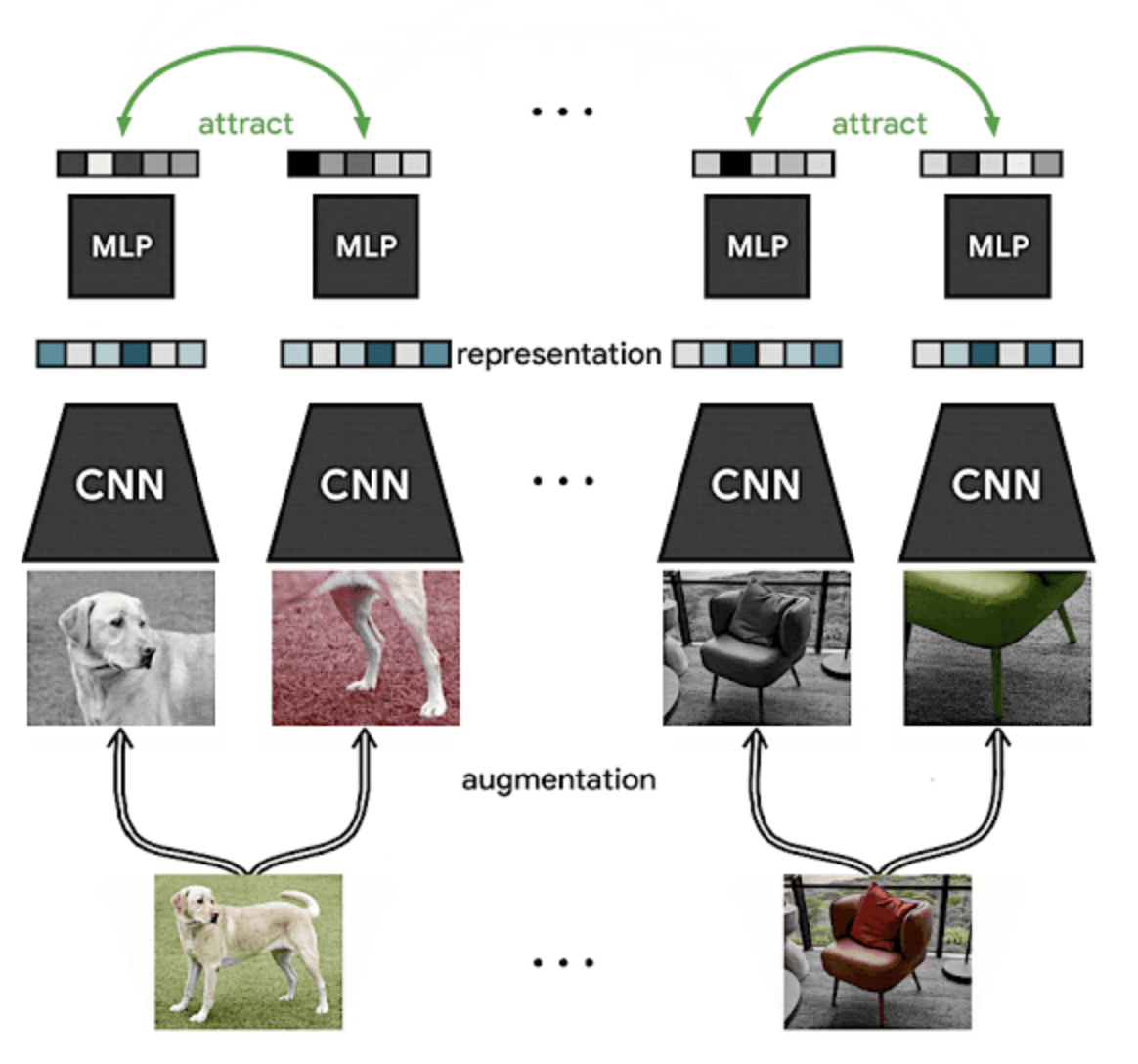
- 과정
- 원본 데이터셋에서 예제를 무작위로 추출하여 두 번 변환 (random cropping & random color distortion)
- representation 계산
- representation의 비선형 투영 계산
- 동일한 이미지의 다른 변형을 식별하는 데 도움이 되고, 유사한 개념(ex. chairs vs dogs)의 표현 학습
- 비선형 투영 계산 → representation 자체에서 대조 손실을 구하는 것보다 성능 좋음
- 큰 배치 사이즈 & 오래 학습 → negative 쌍을 더 많이 고려하게 되어 지속적으로 성능 향상
3) BYOL (Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning)
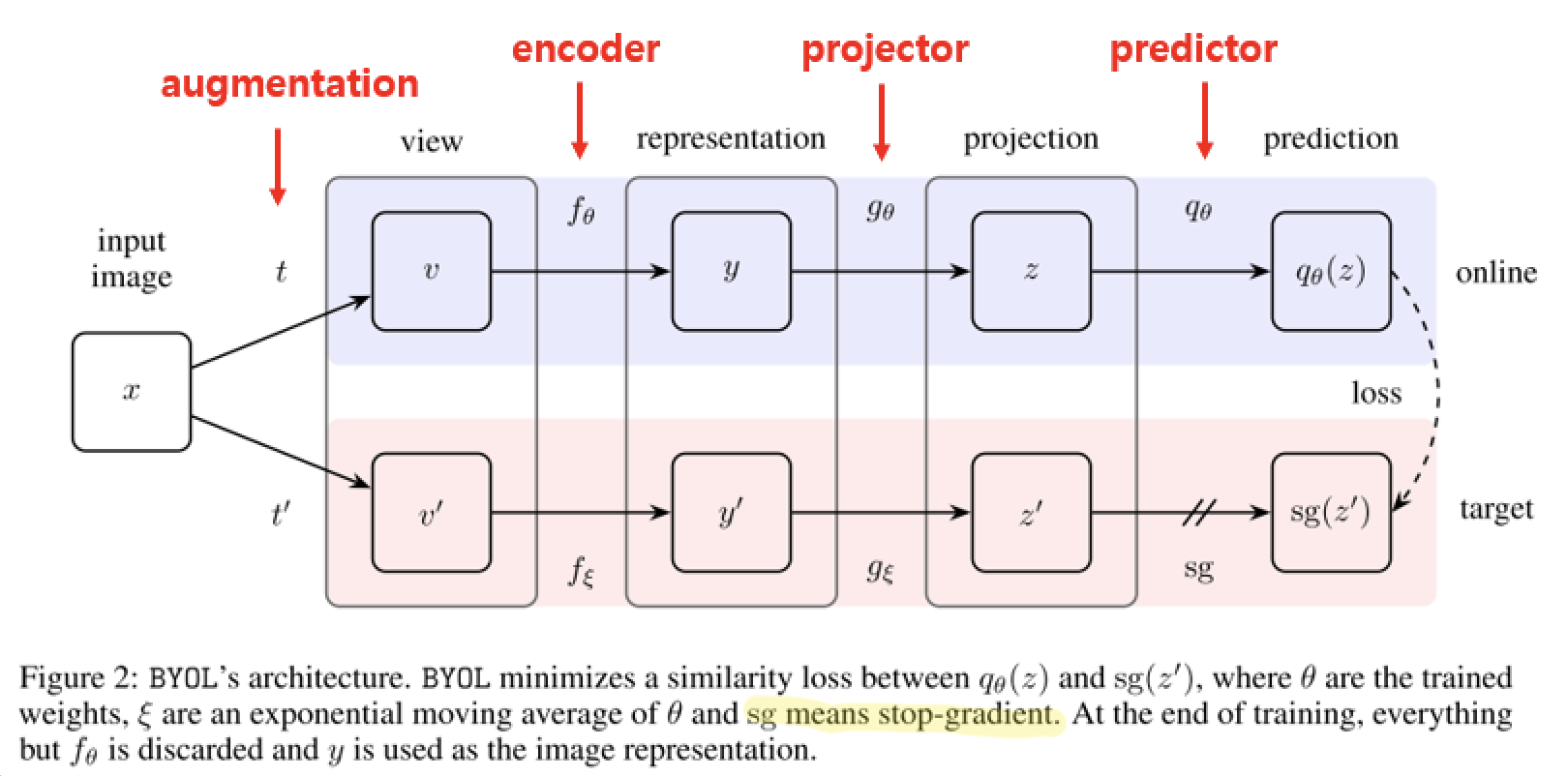
구조
- input: 같은 샘플로부터 다른 데이터 증강을 이용해 변형된 샘플
- 2개의 network (online network, target network)를 사용
- loss function: mean sqaured error function
- 각각의 network는 encoder + projector + predictor로 구성
- target network의 weight: online network의 weight의 exponential moving average(지수이동평균)에 의해 업데이트
→ online network가 배울 regression target 생성
(expotential moving average의 coefficient 값은 0.996부터 1에 가깝게 감)- loss는 online network의 학습에만 사용
- 과정
- 2개의 network에 서로 다른 augmentation을 적용하여 feature vector(prediction)을 뽑기
- online network와 target network의 projection output에 l2 normalization (MSE)
- mean squared error를 최소화시키는 방향으로 online network를 학습
(online network와 target network의 output이 같아지도록 학습) - loss의 대칭화를 위해 사용한 augmentation을 바꿔서 loss 한번 더 계산하여 두 loss의 합으로 학습
- 장점
- negative 쌍을 사용하지 않고 positive 쌍만 이용하여 SimCLR보다 2% 성능 향상
- 기존의 negative 쌍을 사용할 때 배치 크기가 매우 커야 학습이 잘 된다는 문제와 데이터 증강에 따른 성능 편차가 크다는 문제 해결
- representation을 잘 배우는 것이므로 학습이 끝나면 onlline network의 encoder 제외 나머지는 사용 안함
⇒ 과거의 online netwrok들이 target network 속으로 스며드는 느낌
{kind=link}
ImageNet에서 pre-training한 다양한 자기지도학습으로 학습된 representation에 대해 훈련된 linear classifierdml ImageNet 최고 정확도)
3-7. 멀티태스킹
- 맥락 예측 태스크인 Relative Patch Location + Colorization + Exemplar + Motion Segmentation을 1개의 네트워크에 학습
- 4개를 모두 적용했을 때의 결과가 가장 좋았음
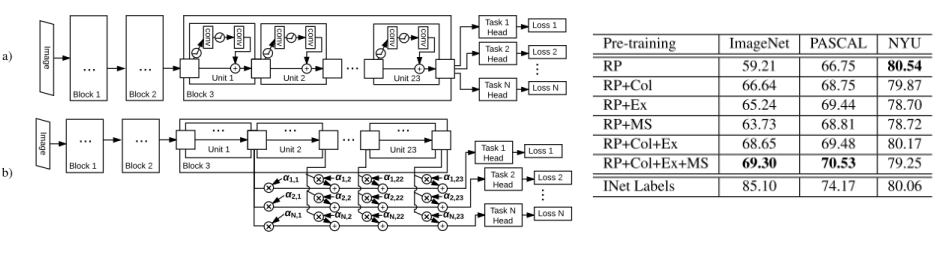
4. 성능 측정
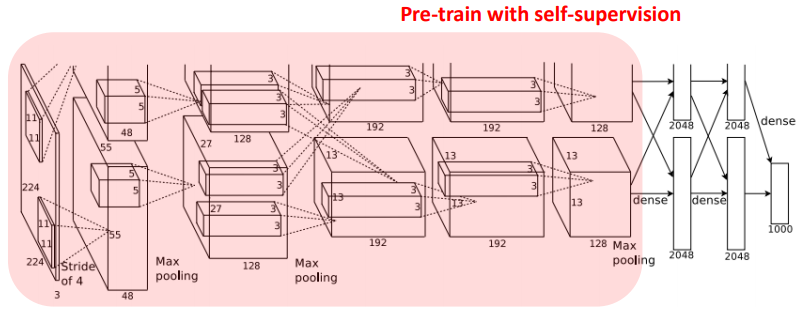
빨간 상자: pre-training을 self-supervise로 얻은 feature extractor
- 프리텍스트 태스크로 네트워크를 학습시키는 이유는 다음에 이어질 다운스트림 태스크를 잘 수행하기 위함
4-1. 태스크 일반화 (Task Generalization)
-
성능 측정을 위해 자기지도학습으로 네트워크를 pre-training 한 뒤 모든 가중치를 고정하고, 마지막 레이어에 linear classifier를 붙여 지도학습 방식으로 다운스트림 학습 진행
⇒ 가중치가 얼마나 특징을 잘 추출하고 representation을 잘 배웠는가?
(단순한 선형 레이어 하나만 붙여 학습 했을 때 좋은 성능을 내기 위해서는 feautre extractor가 얼마나 성능이 좋은 간접적으로 확인할 수 있는 방법)
ImageNet : Classification
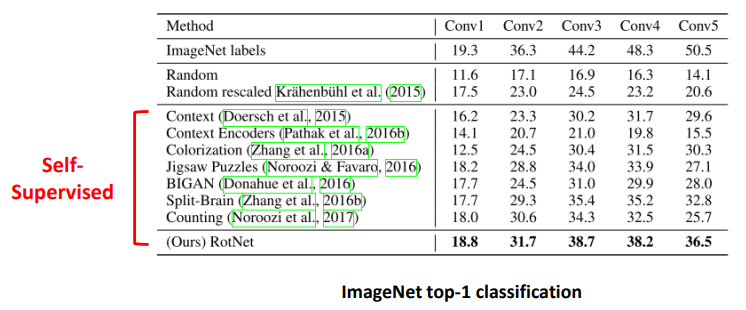
- Conv1, Conv2, ..: 는 AlexNet의 해당 레이어까지 파라미터를 고정하고 뒷부분을 학습
- ImageNet labels: 일반적인 지도학습으로 모델을 학습 후 Conv 레이어를 고정시킨 뒤 각 Conv 레이어 뒤에 linear 레이어를 붙여 학습한 결과
- Random & Random rescaled: Conv 레이어들을 random initialization 한 뒤 linear 레이어 붙여서 학습한 결과 ⇒ feature extractor 아무런 정보도 담고 있지 않기 때문에 오직 linear 레이어에 의존하여 학습하므로 linear layer를 사용할 때의 lower bound 성능임
- Self-supervised: Conv 레이어들을 pre-training 한 뒤 고정하고 linear 레이어를 붙여서 학습한 결과
4-2. 데이터셋 일반화 (Dataset Generalization)
-
자기지도학습으로 ImageNet 데이터셋으로 pre-training 후, 다운스트림 태스크로 PASCAL VOC의 classification, object detection, segmentation task 이용
⇒ feature extractor의 품질이 아니라 pre-training 후 파인 튜닝을 했을 때 얼마나 성능이 좋은가?
PASCAL VOC : Classification, Object Detection, Segmentation Task
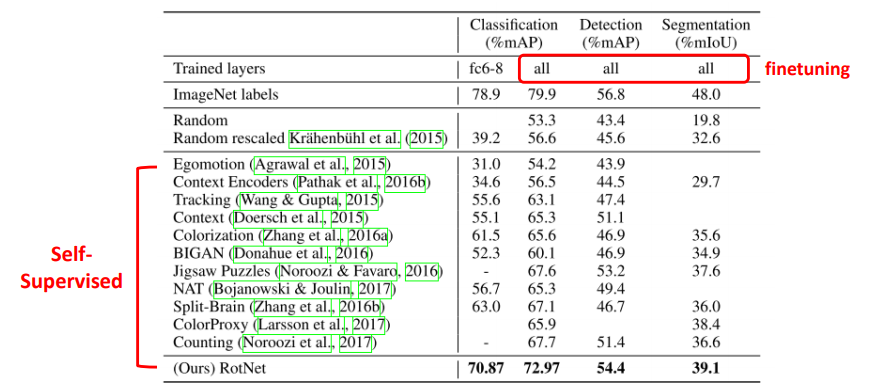
-
ImageNet labels: ImageNet pre-trained 가중치를 사용하여 다른 데이터셋에 학습한 결과
-
Random & Random rescaled: random 가중치로부터 학습한 결과 (= scratch로부터 학습)
→ 적은 epoch 진행: pre-training 가중치의 이점인 빠른 학습의 빠른 수렴 강조 (30 epoch)
5. 결론
- 레이블링이 없는 데이터로 프리텍스트 태스크를 정의하여 높은 수준의 semantic 이해를 위해 학습
- feature extractor를 사전 학습하고, 다운스트림 태스크로 전이
- ImageNet으로 학습할 수 없는 다른 도메인의 경우 pre-training 시킬 데이터셋의 대안이 될 수 있음
Reference
https://arxiv.org/abs/1811.11212
http://www.kisdi.re.kr/kisdi/common/download?type=DR&file=1|14840
https://www.youtube.com/watch?v=MaGudzppu3I&t=11567s
https://abursuc.github.io/slides/2020_tutorial_cvpr//self_supervised_learning.html#1
https://annotation-efficient-learning.github.io/slides/relja_cvpr2020_self_supervised.pdf
https://hoya012.github.io/blog/Self-Supervised-Learning-Overview/
https://www.youtube.com/watch?v=eDDHsbMgOJQ&list=PLk4Qf8NdfVem3BKLdI_oWb0kHuRFYqxVy&index=8&t=3s
https://creamnuts.github.io/paper/CPCv2/
https://brunch.co.kr/@synabreu/76

8개의 댓글

투빅스 14기 김상현
이번 강의는 self-supervised learning에 관한 survey로 투빅스 14기 박지은님이 진행해주셨습니다.
- Self-supervised learning의 필요성: 레이블링 비용을 줄일 수 있다. GAN의 불안정성 해결에 도움을 준다.
- Pretext task: 딥러닝 네트워크가 어떤 문제를 해결하는 과정에서 데이터 내의 semantic한 정보를 이해할 수 있도록 하는 임의의 작업. 예시로 데이터에 대한 표현 학습을 하는 Autoencoder
- SSGAN: rotation-based 자기지도학습을 하는 생성모델로 판별자는 real/fake와 rotation degree를 판별해야 한다. 따라서 판별자의 forgetting을 방지해서 vanilla GAN 보다 좋은 성능을 보여준다.
- 자기지도학습 방법은 구조 예측, 변환 예측, 재건, 인스턴스 분류, 시간적 관계, 대조 학습 등이 있다,
- Self-supervised learning은 pretext task를 통해 높은 수준의 semantic이해를 할 수 있고, downstream task로 전이한다.
self-supervised learning의 개념과 전반적인 내용을 이해할 수 있었습니다. 특히 여러가지 pretext task들 자세히 설명해주셔서 유익했습니다.
유익한 강의 감사합니다!

투빅스 14기 김민경
- Self-Supervised Learning은 레이블링에 대한 많은 cost, GAN의 불안정성 등의 이유로 요구되는 분야이다.
- Self-Supervised Learning은 Unsupervised Learning의 방법 중 하나로, 새로운 태스크에서 소량의 데이터만으로 semantic representation을 찾게 하여 좋은 성능을 내는 transfer learning이 가능하다.
- 초창기의 GAN이 Self-Supervised Learning을 적용한 기법인 오토인코더, SSGAN 등은 ‘픽셀 단위’로 복원하거나 예측하기 때문에 계산 복잡도가 높다는 단점이 있다.
- pretext tasks는 사용자 임의로 정의한 문제를 의미하는데, 이것을 적용해 Self-Supervised Learning을 하는 방법으로는 Inferring Structure, Transformation Prediction, Reconstruction 등등이 있다.
- Self-Supervised Learning에 대한 전반적인 흐름과 적용된 다양한 분야들을 소개해 주셔서 정말 유익한 강의였습니다:)

투빅스 14기 정재윤
이번 강의는 self-supervised learning에 관한 강의로 투빅스 14기 박지은님이 진행해주셨습니다.
-
Supervised learning은 매우 강력하게 사용되지만 레이블링된 데이터셋이 존재하지 않은 경우가 많고, 작업자의 편향성이 들어갈 위험이 있다는 단점이 있습니다. 또한 GAN은 높은 차원의 파라미터 공간일 때 학습이 어렵습니다. 이런 점을 개선하기 위해 나온 것이 바로 self supervised learning입니다. 레이블링이 되지 않은 데이터셋을 바탕으로 하며 모델이 스스로 레이블을 생성하여 지도학습에 이용합니다.
-
Pretext task는 네트워크가 데이터 내의 semantic한 정보를 이해할 수 있도록 학습하게 하는 임의의 테스크로, 이를 이용한 자기지도 학습 방법들이 많이 제시됐습니다. 대표적으로 맥락 예측, jigsaw puzzle, 회전 예측, 상대적 변환 예측, 디노이징 오토인코더, 맥락 인코더, 색상화, split-brain encoders, bag-of-words예측 등이 있습니다.
-
실제 pre-training을 self supervised로 얻은 feature extractor로 성능을 평가해본 결과 classification의 경우 기존의 모델보다 더 높은 성능을 얻을 수 있었고, 일반화된 데이터셋의 경우, 성능은 약간 떨어졌지만 학습 속도가 월등히 좋았다라는 결과를 얻었습니다.
최근 연구 중인 self – supervised learning에 대해서 잘 설명해주셨고, 그 종류에 대해서 굉장히 상세하게 알려주셨습니다. 덕분에 여러 종류를 알 수 있었고, 자기지도학습의 결과가 유의미하다는 것을 알 수 있었습니다. 감사합니다. 😊

투빅스 13기 이예지:
이번 강의는 ‘Self-Supervised Learning’으로, 박지은님이 진행하였습니다.
Self-supervised Learning
- Supervised learning은 많은 양의 labeled data가 요구됨
- SSL은 레이블이 없는 데이터를 이해하도록 pretext task를 위한 레이블을 직접 생성하여(self supervised) 모델을 학습하여 다른 태스크로 전이하여 사용함
Rotation Prediction
- rotation기반으로 SSL을 시도함
Context Prediction
- 모델이 object의 공간적 관계를 파악하도록 학습함
Jigsaw puzzles
- 이미지를 패치로 분할하고 순서를 바꿈
- Context prediction보다 더 어려운 태스크임
Reconstruction
- 정답 레이블을 입력 데이터로 사용하여 입력과 출력의 결과가 같도록 학습함
- Denoising auto encoders, context encoders, colorization, split-brain encoders
- Bag-of-words
Instance classification
- 입력이미지를 분할하고 변형하여, 같은 원본 이미지를 고르는 것이 목적
시간적 관계
- 영상에서 시간에 따른 일관성을 고려한 프레임을 재건함
Contrastive Learning
- Postive pair와 negative pair를 입력으로 사용하여 서로 비슷한지를 학습함
Multi-tasking
- 동시에 여러 태스크를 진행함
다양한 SSL 태스크를 이해하고, pretext task의 중요성을 알 수 있었습니다.
좋은 강의 감사합니다 :)
[투빅스 12기 김태한]
이번 세미나는 Self-Supervised Learning을 14기 박지은님께서 진행하였습니다.
Supervised learning에는 많은 양의 label data set이 필요합니다.
이를 매번 labeling하여 학습시키는데 많은 번거로움과 어려움이 존재하는데 이를 pretext task라는 label이 없는 데이터에 대해 스스로 label을 생성하여 학습하는 방법을 Self-Supervised Learning이라고 합니다.
이러한 SSL에는 다양한 방법이 존재합니다.
-
먼저 Rotation Prediction으로 기존에 가지고 있던 이미지들을 회전함으로써 라벨되어 있는 데이터를 생성하는 방법입니다.
-
다음의 Context Prediction은 pretext 모델이 어떠한 공간적인 관계를 학습하도록 하는 방법으로 jigsaw puzzle방법과 이미지를 패치로 분할하여 순서를 바꾸는 등의 다양한 학습방법이 있습니다.
-
다음으로는 reconstruction task로써 denoising autoencoder, context encoder등이 존재합니다.
-
이외에도 instance classification, 시간적 관계, contrastive learning, 멀티태스킹 등의 방법들이 존재합니다.
이번 세미나를 통해 SSL에 대해 보다 깊게 알 수 있었습니다.
좋은 강의 너무 감사합니다 :)

투빅스 14기 박준영
이번수업은 self-supervised learning으로 투빅스 14기 박지은님이 진행해주셨습니다.
-
레이블링 된 데이터셋으로 모델을 학습하는 지도학습과 달리, 자기지도 학습이란 다량의 레이블이 없는 데이터의 관계를 통해 레이블을 자동으로 생성하여 지도학습을 한다
-
진행과정은 레이블링 없는 데이터를 pretext task로 학습한 뒤 학습된 특징들로 분류기를 학습하여 더 적은 레이블을 가진 데이터를 적용가능하도록 파인튜닝한다.
-
비지도학습을 통해 데이터 셋을 만드는 사람으로 인한 데이터셋의 편향을 최소화하고 다량의 데이터들을 별도의 레이블링 없이 사전학습이 가능하다.
-
자기지도학습의 pretext task를 이용한 학습방법에는 구조유추, 변환예측, 재건, 인스턴스 분류, 시간적 관계, 대조학습, 멀티테스킹 방법이 있다.
-
구조유추 자기지도학습 방법은 이미지 패치로 분할해서 중심패치와 이웃패치를 같은 네트워크에 넣고 합쳐서 분류를 하는 방식으로 진행된다. 그러나 fine-grained 하지않고 8개의 선택지 밖에 없어 출력에 대한 경우의 수가 너무 작다는 단점이 있다.
-
변환예측은 이미지를 회전시켜서 학습하는 방법으로 다른 이미지의 negative가 없기때문에 충분히 fine-grained하지 않고 eval에는 변환된 이미지가 없어어 train-eval 사이의 gap이 발생한다.
-
재건은 복원을 통해 annotaion 없이 이미지의 특징을 학습할 수 있는데 랜덤 노이즈가 섞인 raw data에서 네트워크를 거쳐 원본 raw data를 학습하는 디노이징 오토인코더, 영상의 중간에 뚫린 부분을 추측하여 복원하는 맥락인코더 방법, 흑백 영상에 색을 입혀 컬러 영상으로 바꾸어주는 색상화 방법, 이미지의 절반을 잘라 네트워크가 남은 절반의 이미지를 맞추도록 하는 split-branin encoders 방법 등이 있다.
-
인스턴스 분류는 이미지를 분할 추출하여 변형 시킨 사진들 중에서 원본 이미지를 가진 분할 사진 고르기를 통해 같은 class를 가지도록 학습한다.
-
시간적 관계는 영상에서 시간에 따른 일관성을 고려한 프레임 재건 또는 생성을 이용하여 자기지도학습을 한다.
-
대조학습은 2개의 샘플이 하나의 쌍을 이루어 네트워크의 입력으로 사용한다. 이 데이터들이 서로 비슷한지 학습을 한다.
-
멀티태스킹은 Relative Patch Location + Colorization + Exemplar + Motion Segmentation 합쳐서 네트워크에 학습하는 방법이다.
-
위의의 pretext task를 이용한 방법으로 pre-traning 후 다운스트림 테스크로 전이한다.
self-supervised learning의 개념과 다양한 pretext task의 방법들에 대해서 잘 알 수 있었던 강의였습니다. 감사합니다

투빅스 11기 이도연
Self-Supervised Learning에 대해 그 개념부터 다양한 Self-Supervised 방법까지 공부할 수 있어 좋았습니다. 좋은 강의 감사합니다!
- Unsupervised Learning 연구 분야 중 하나인 Self-Supervised Learning
- 지도학습의 경우 무수히 많은 양의 데이터가 필요하고, 데이터를 사용하기 위해 라벨링에 많은 시간이 소요된다. 이를 해결하기 위한 여러 연구 중에는 유사한 task의 학습된 weight를 가져와 적용하는 Transfer Learning, 데이터 셋 중 일부만 라벨링하는 Semi-Supervised Learning 등이 있고 아예 label을 이용하지 않는 Unsupervised Learning이 있다.
- Pretext Task는 데이터 자체에 대한 이해를 높이기 위해 사용자가 정의해 학습하게 하는 임의의 task다. 이렇게 pretrain 된 모델을 downstream task로 전이시켜 사용한다.(transfer learning)
- Pretext Task를 이용한 자기지도학습 방법은 아주 다양하다. 공간적 관계를 파악해 그 맥락과 구조를 예측하고, 회전 등의 변환을 예측하고, Denoising, Colorization, 이미지 왜곡에 대해 재건하고, 대조 학습 하는 등의 방법이 있다.
- 이러한 pretext task에 대한 학습은 다음에 이어질 downstream task에서 잘 이용하기 위한 목적이 있다. pretraining을 통해 얻은 weight들이 얼마나 데이터를 잘 이해했느냐가 중요하다.
- label 이 없을 경우 뿐만 아니라 ImageNet과 같은 pre-training 데이터 셋이 없는 다른 도메인의 경우 대안이 될 수 있다.
투빅스 14기 한유진
Self-Supervised Learning의 개념적인 부분을 배울 수 있었던 좋은 강의였습니다. Self-Supervised Learning가 왜 등장했고, 어떤 방법으로 사용되는지까지 차근차근 알수있어서 좋았습니다! 감사합니다