BERTScore: Evaluating Text Generation with BERT

2020 ICLR에서 발표된 논문으로, BERT의 Contexutal Embedding을 활용해 두 문장 사이의 유사성을 측정하는 지표를 제시하였다. BERT Score는 Cosine-Similarity와 BERT에 대한 사전지식이 있는 사람이라면 누구든지 직관적으로 이해할 수 있는 지표이며, ICLR에 출간되었을 만큼 수학적으로도 탄탄하게 설계되었다. 실제로 최근 top-conforence의 summarization 논문에 ROUGE와 함께 굉장히 많이 사용되는 지표 중 하나이기도 하다.
본 게시글에서 참고하는 code는 lovit님이 한국어로 구현하신 KoBERTScore를 참고했습니다!
1. Introduction
Machine Translation과 Caption Imagination과 같은 '자연어 생성'문제에서 모델의 성능을 평가하기 위해서는 모델이 생성한 'candidate sentence'와 기존 정답 문장인 'annotated references'을 비교하는 지표가 필요하다. (앞으로 편의를 위해 모델이 생성한 문장을 'candidate sentence', 정답 문장을 'reference sentence'로 통일하여 명명하겠다.) 하지만 기존의 방법론들(BLEU,ROUGE)은 'candidate sentence'와 'reference sentence'의 표면적인 비교밖에 하지 못한다. 즉 두 문장 사이에 동시에 등장하는 단어/토큰의 exact match만으로만 평가한다는 한계가 존재한다. 이러한 방법론들은 단어/토큰이 내재하고 있는 의미(meaning-preserving lexical) 와 통사구조의 다양성(compositional diversity) 을 제대로 평가하지 못한다.
1. Meaning-preserving lexical
cross-entropy loss와 마찬가지로 exact match계열의 비교는 paraphrase를 완전히 다른 token으로 취급한다. 즉 자연어=token에 내재되어 있는 의미를 제대로 반영하지 못한다.
ex. '사랑해'와 '좋아해'를 의미가 다른 단어로 취급함
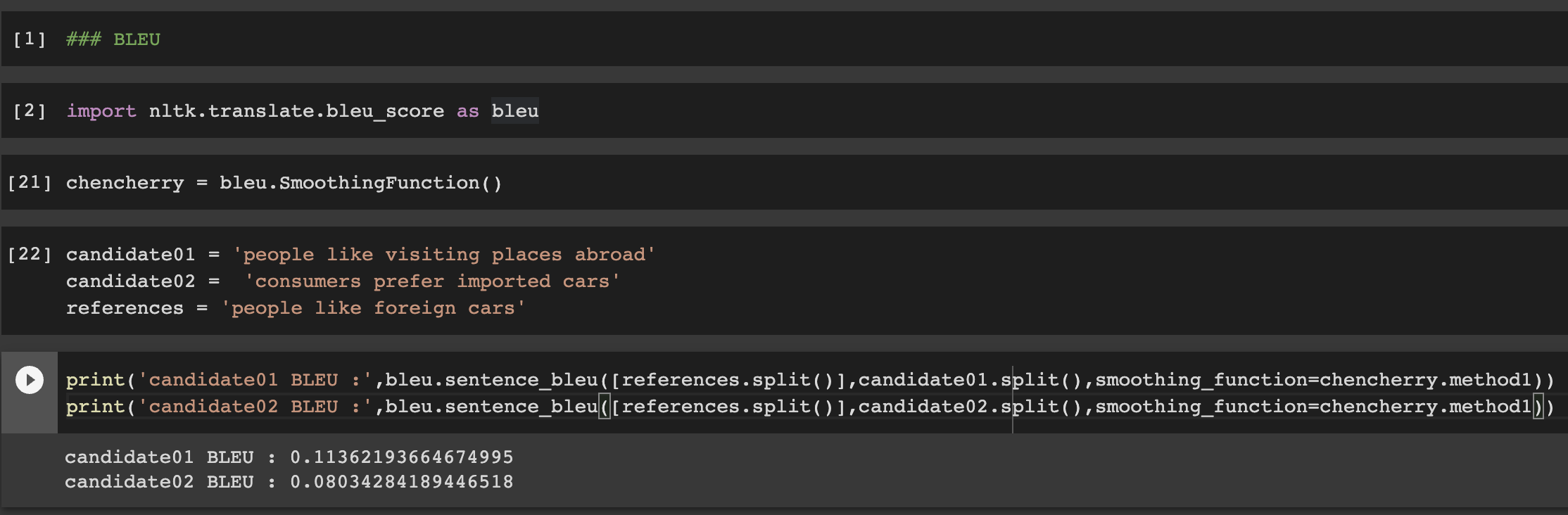
논문에 나와있는 예시를 살펴보자.
BLEU Score는 candidate01를 candidate02보다 reference와 유사한 문장으로 평가한다.
2. Comopositional Diversity
N-gram exact match는 문장내 통사구조가 주는 의미를 반영하지 못한다. (fail to capture distant dependencies and penalize semantically-critical ordering changes)
ex. A because B 와 B because A는 다른 문장이지만 점수가 높게 나옴
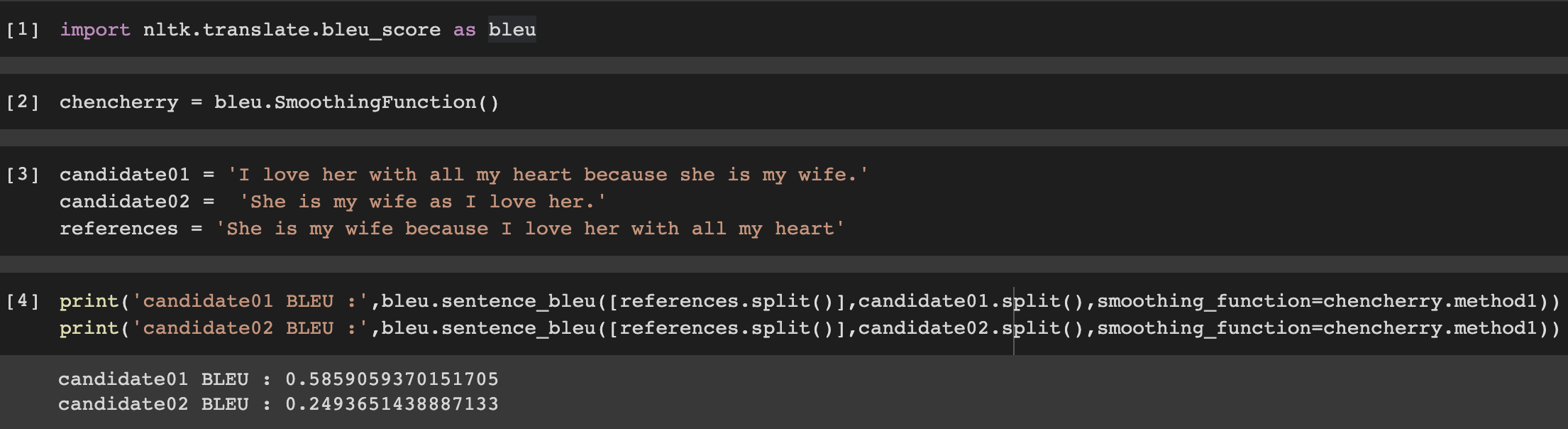
논문에 나와있는 예시를 살펴보자.
because 전후가 바뀌면 문장의 의미가 완전히 바뀜에도 BLEU Score는 높은 점수를 주고 있다.
2. Problem Statement and Prior Metrics
2.1 n-GRAM MATCHING APPROACHES

METEOR가 궁금하면 아래 링크 참고!
METEOR
2.2 EDIT-DISTANCE-BASED METRICS

2.3 EMBEDDING-BASED METRICS & LEARNED METRIC
3. BERTScore
BERTScore 구하는 방법을 한줄로 요약하면 'Candidate Sentence'와 'Reference Sentence'에 BERT를 태워 Contextual Embedding 값을 얻어내고, token-pair마다 Cosine Similarity로 유사성을 평가한 후, IDF로 각 Token에 가중치를 부여하자!'이다.
말만 들어도 직관적으로 이해가 되는만큼, 실제 구현도 간단한 편이니 하나씩 살펴보자.
- k개의 token으로 이루어진 reference sentence와 l개의 token으로 이루어진 candidate sentence에 BERT를 태워 Contextual Embedding을 얻고, layer normalization을 진행한다. (layer normalization 진행하는 이유는 나중에 내적만해서 Cosine Similarity를 구하기 위함이다)
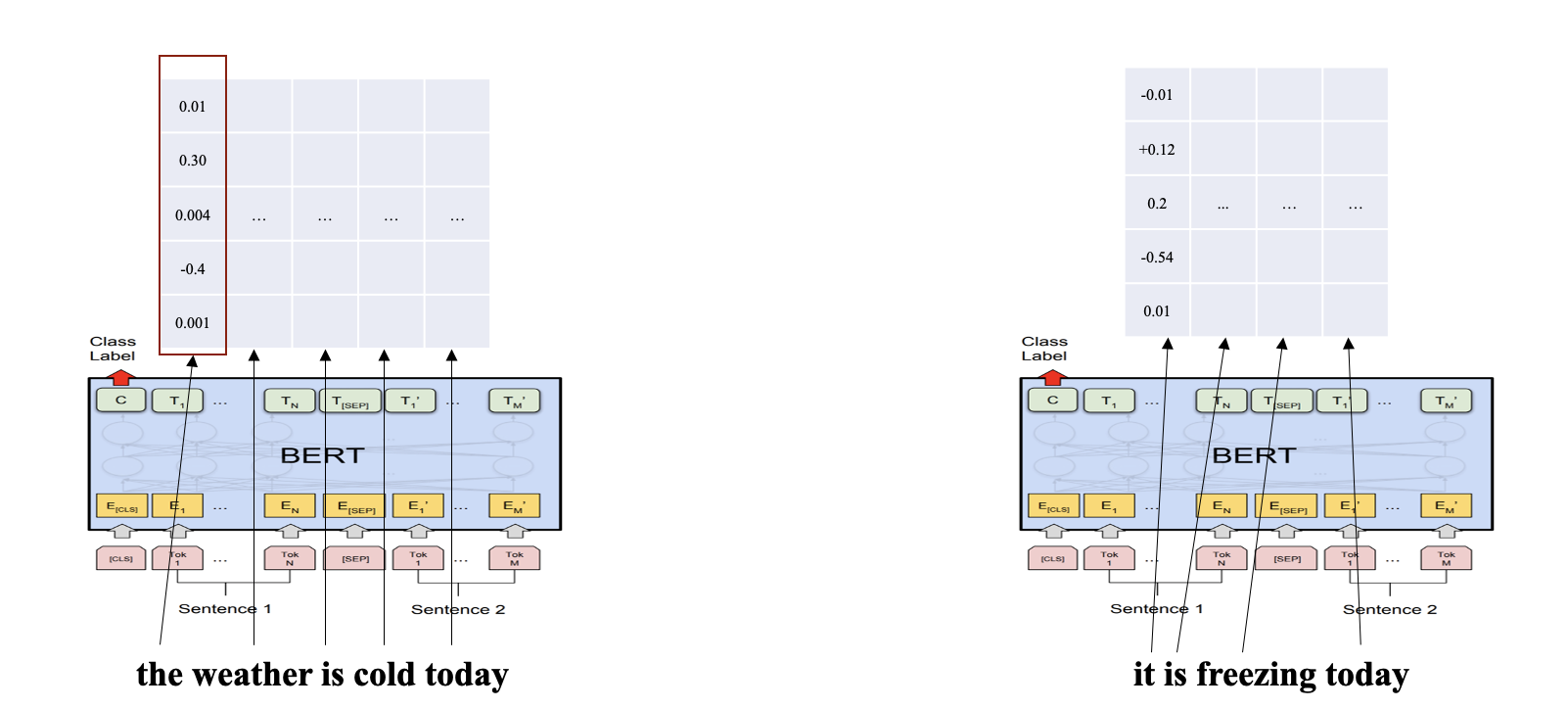
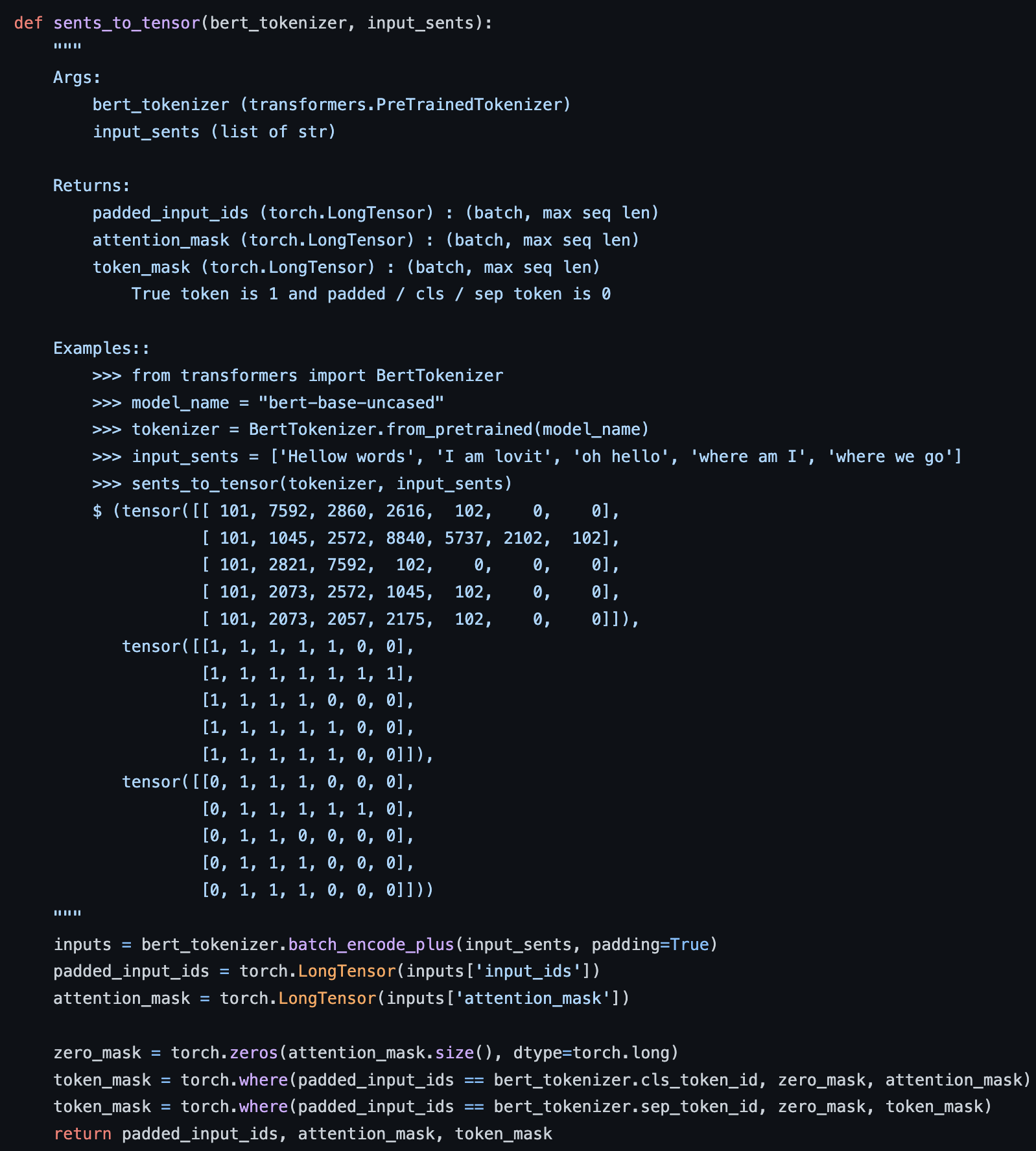
- Candidate & Reference Embedding Pair에 대해서 Cosine Similarity를 계산 (이미 Normalization 해서 사실상 내적만 해도 됨)
torch.bmm은 행렬곱 연산시에 자주 사용되는 method이다. 실제로 대부분의 transformer 계열들이 attention weighted sum 계산시에 torch.bmm을 활용한다.
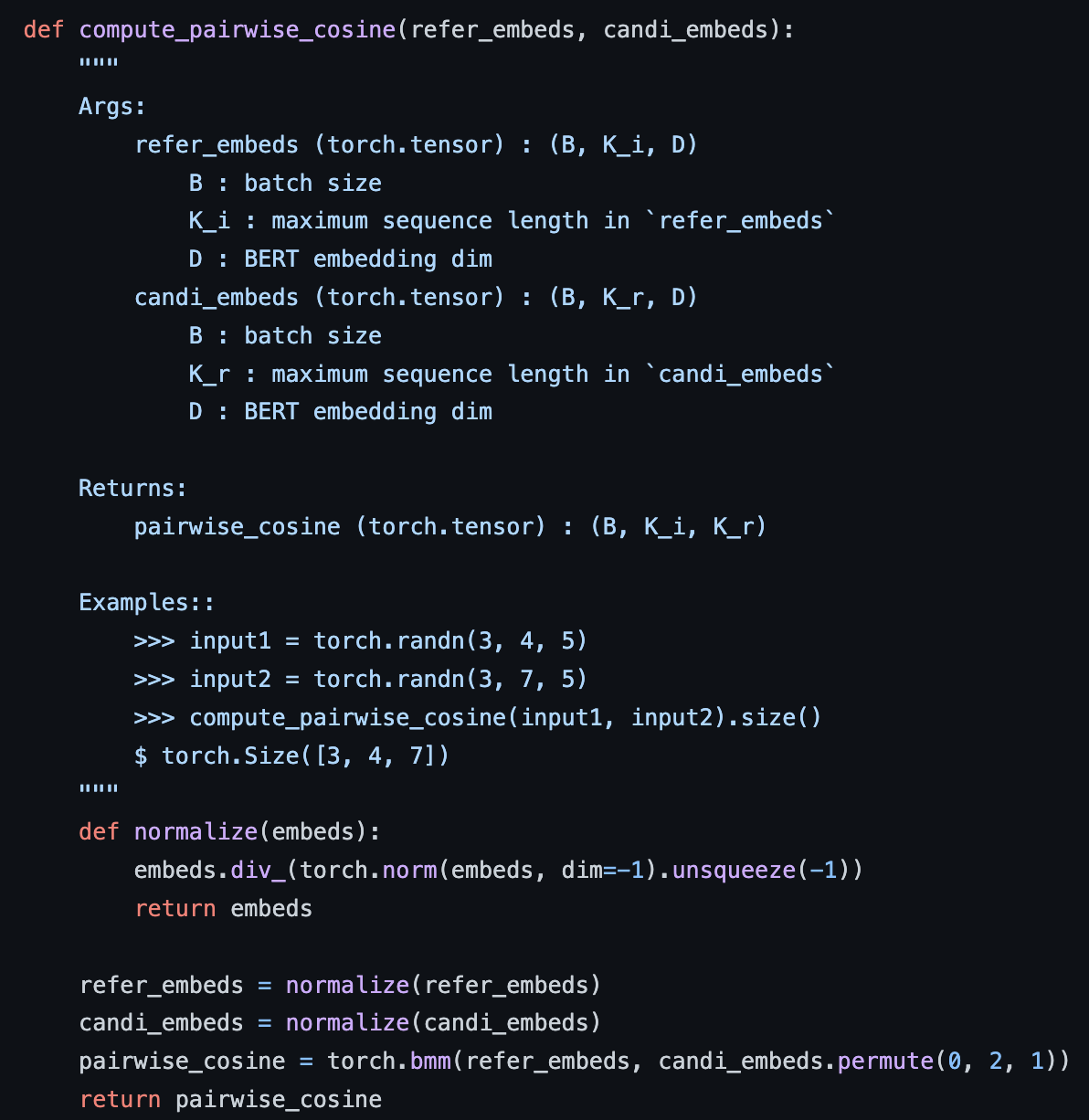

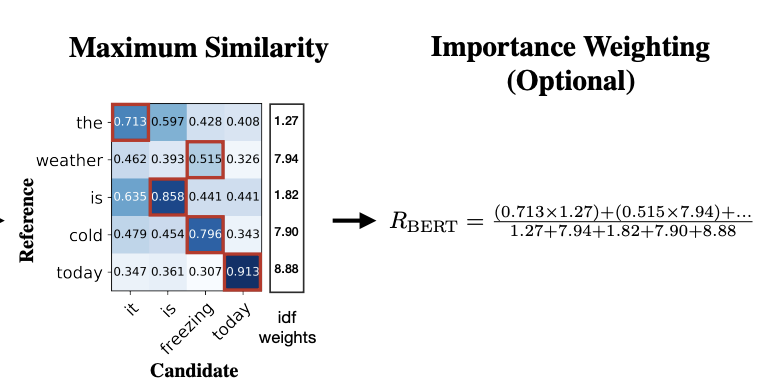
- 계산된 Similarity Matrix 에서 Recall 계산 시에는 Row-Wise Max Pooling 통해 각 Reference의 Token의 최대 내적값, Precision 계산 시에는 Column-Wise Max Pooling 통해 각 Candidate Token의 최대 내적값을 추출해 Summation 후 평균 계산. F1은 게산된 Recall과 Precision으로 계산
Recall 계산 예시


- Importance Weighting
rare word가 common word보다 문장 간 유사성을 평가하는데 더 중요한 요소라는 것을 보여준 선행연구를 논거로 idf score를 추가했다. (TF-IDF처럼 모든 문장에 등장하는 token의 중요도는 낮춰주었다고 이해하시면 되겠습니다.) M개의 reference 문장들을 돌면서 (보통 MT의 경우에는 1개의 'candidate sentence'와 여러개(=M)의 'reference sentences'를 비교하면서 'candidate sentence'의 퀄리티를 평가하기 때문에) 토큰별로 idf score를 구합니다.
log function
토큰별로 idf score구했으면, Recall/Precision 계산시에 normalize term으로 사용해줍니다.
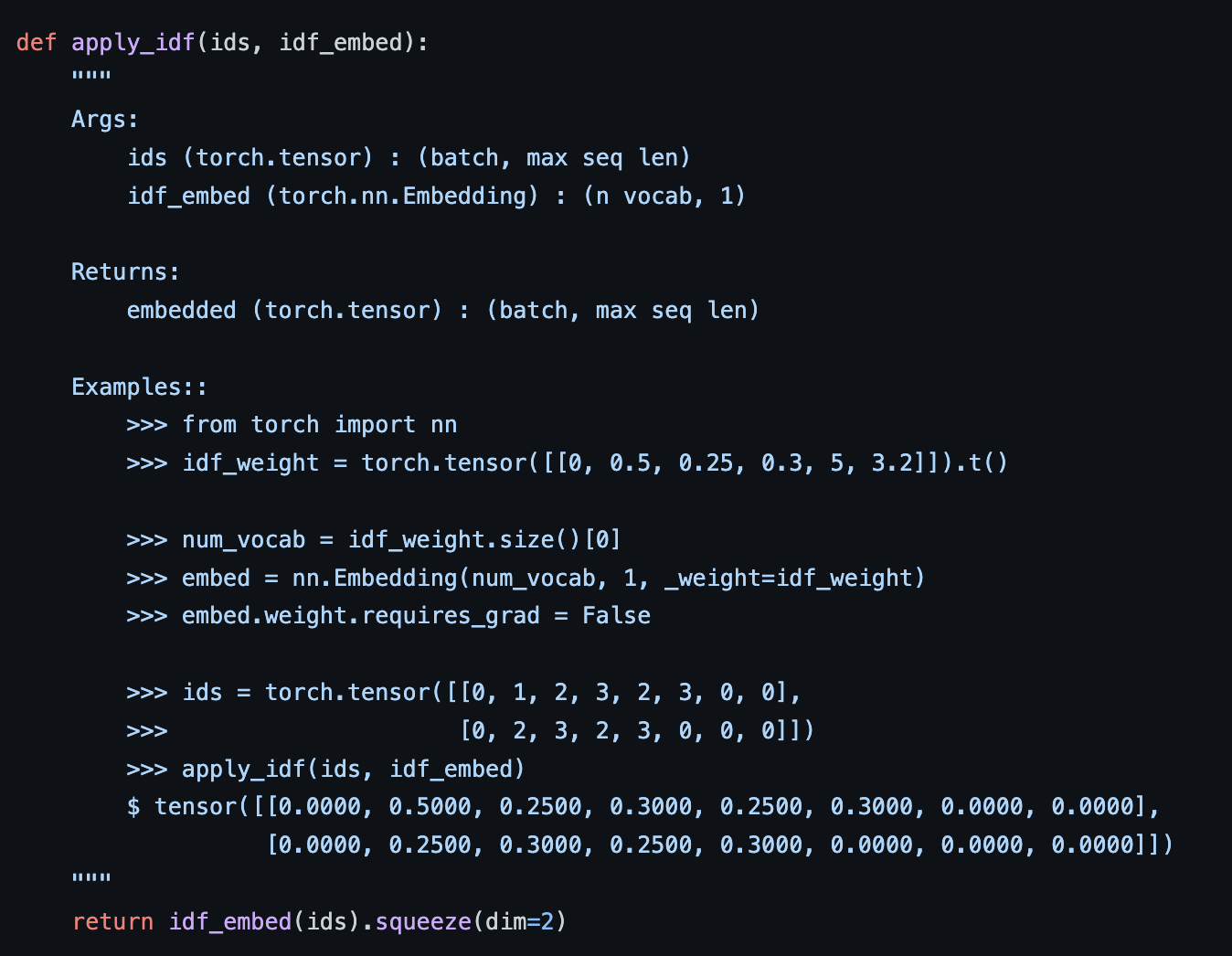
code상으로는 여기서 <CLS>토큰과 <SEP>토큰에서 계산된 cosine-similarity 값이 무시가 됩니다. (idf score 적용안할 시에는 refer_weight_mask가 [0(CLS),1,1,1,0(SEP),0] 이런식으로 계산되어서 element wise로 similarity score랑 곱할 때 영향이 사라짐) ids는 token의 index, ids는 토큰들의 idf score를 저장해놓은 embedding matrix라고 보시면 됩니다. idf-score는 매 배치마다 계산하도록 할 수도 있고, 미리 지정된 것을 가져다 쓸 수도 있습니다.
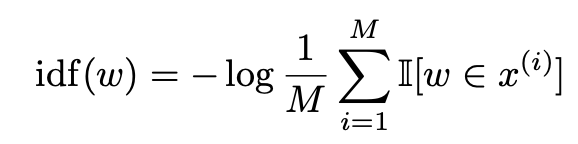
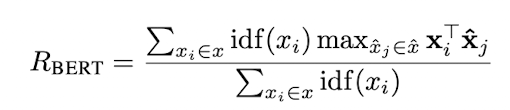
- Baseline Rescaling
cosine-similarity로 score를 계산했기 때문에 bound가 -1 에서 +1 사이의 값을 가지나, 저자들이 실제로 계산 시에는 (-1,+1)보다 작은 구간에서 값들이 형성되었다고 합니다. (초고차원에서 +1,-1에 가까운 값을 갖기에는 매우 어려움) 따라서 저자들은 score의 readability를 높히기 위해 실증적인 lower-bound를 찾아 실제 계산 score가 (-1,+1) 사이로 오도록 rescaling을 진행해주었다고 합니다. (We address this by rescaling BERTSCORE with respect to its empirical lower bound as a baseline. We compute using Common Crawl monolingual datasets. For each language and contextual embedding model, we create 1M candidate-reference pairs by grouping two random sentences. Because of the random pairing and the corpus diversity, each pair has very low lexical and semantic overlapping.4 We compute b by averaging BERTSCORE computed on these sentence pairs.)
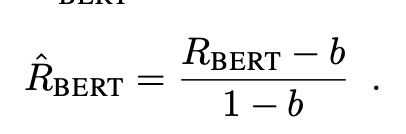
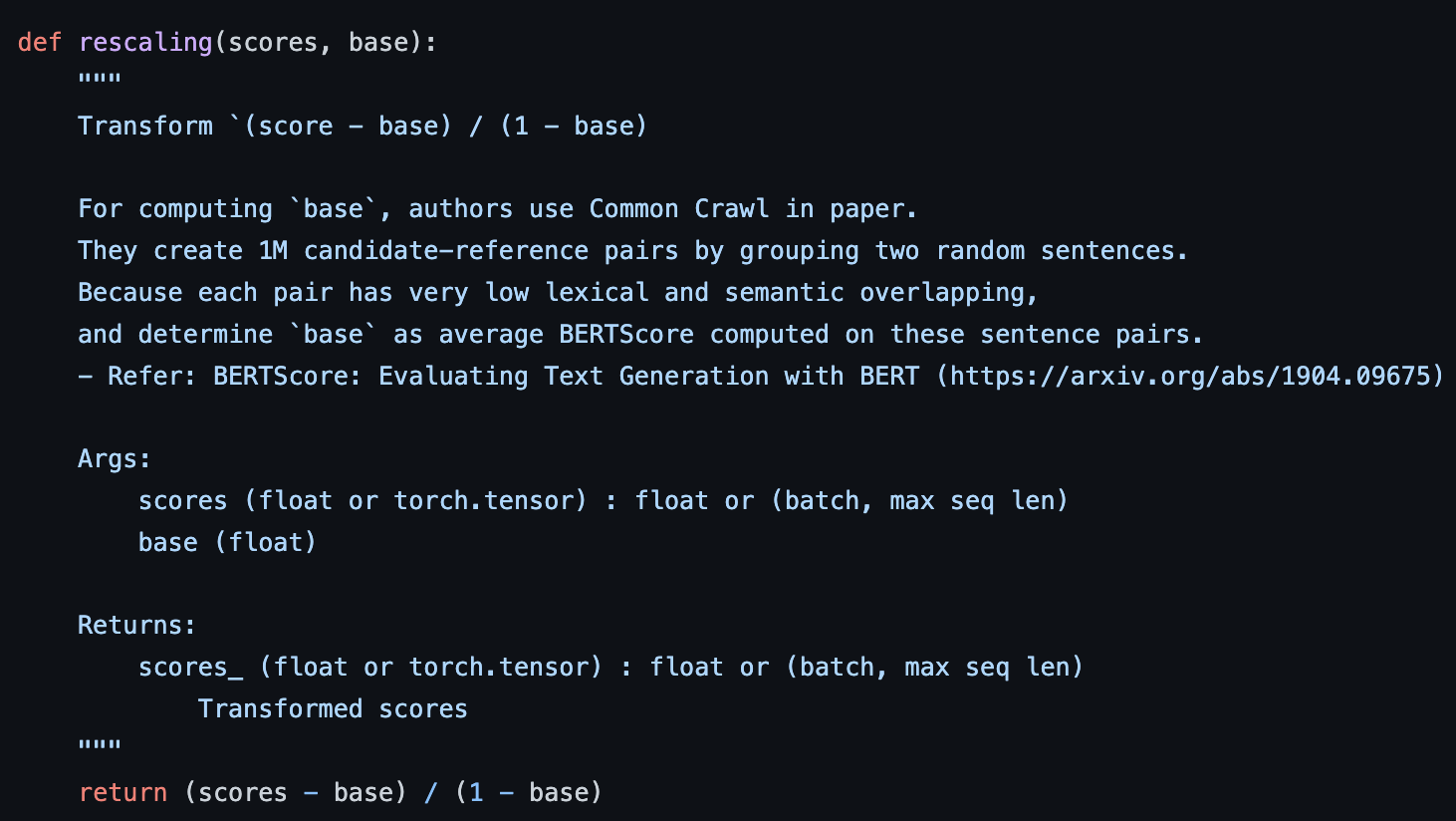
4. Experimental Setup
Contextual Embedding Models
저자들은 BERT, RoBERTa, XLNET, XLM의 총 12개 모델을 실험에 활용했습니다. BERT의 마지막layer embedding보다 intermediate layer가 semantic task에 더 좋다는 선행연구에 따라 WMT16 데이터셋을 validation set삼아 각 모델에서 인간과의 상관관계(BERT F1 Score 기준)가 가장 높은 layer를 선택해 추후 실험에도 사용하였습니다.
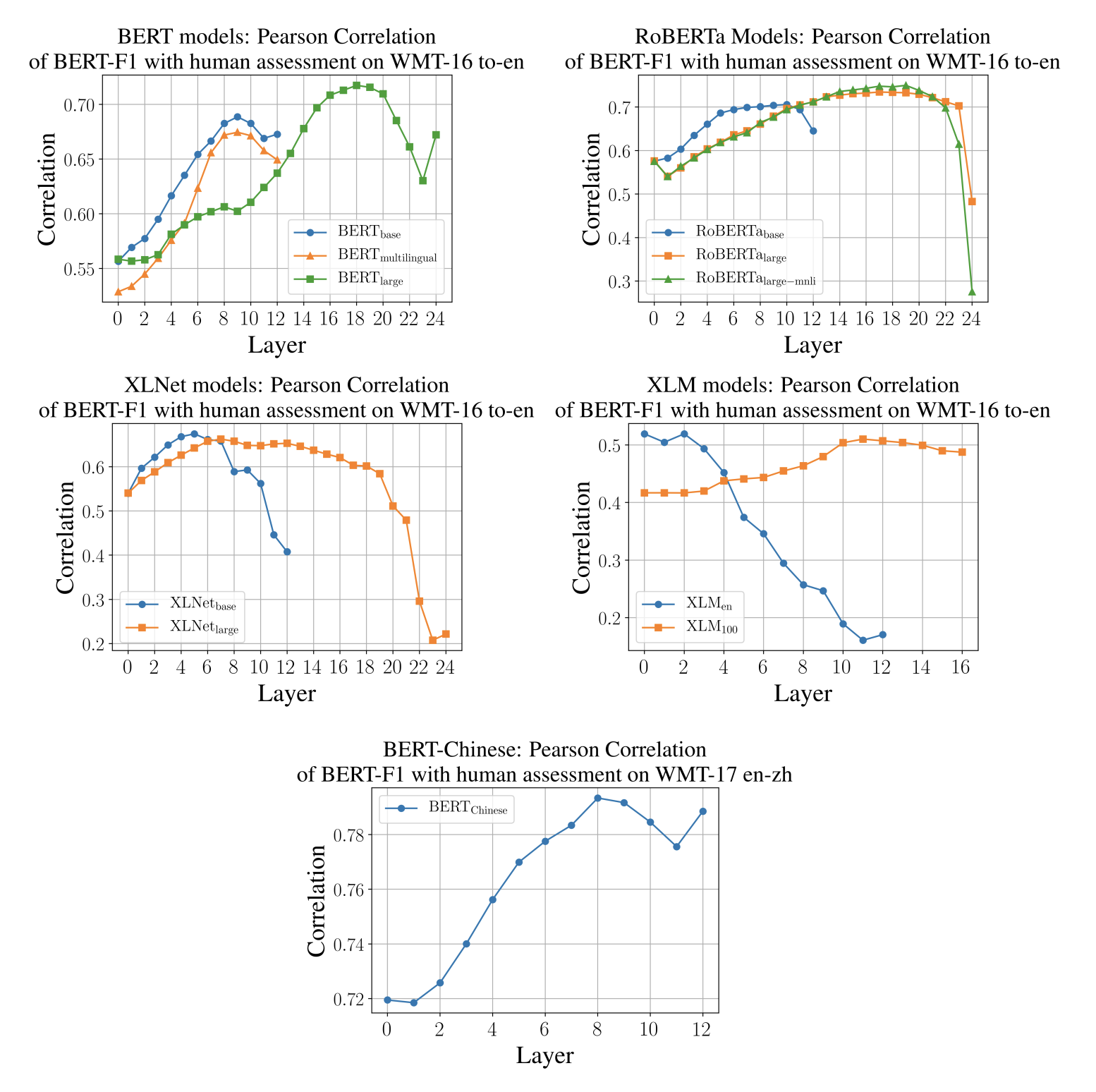
Machine Translation
저자들은 다수의 모델(149개)이 생성한 번역문(=candidate sentence)과 정답 번역문(=reference sentence)이 얼마나 유사한지 사람이 평가한 척도와 Automatic Metric들이 평가한 척도와의 비교를 통해 좋은 Metric을 평가하는 WMT18 Metric Evaluation Dataset을 활용해 BERTScore의 성능을 평가했습니다.
위의 데이터셋을 평가하는 방법에는 총 3가지가 있는데,
1. Segment-level human judgement : 여러 모델이 생성한 번역문(=candidate sentence)과 정답 번역문(=reference sentence)사이의 유사성을 사람이 평가한 Score와 Metric이 평가한 Score로 1:1 비교를 하는 방법
2. System-level human judgement : 모든 데이터에 대해 특정 모델이 생성한 번역문(=candidate sentence)과 정답 번역문(=reference sentence)사이의 유사성 Score(사람 평가/Metric 평가 모두)를 평균내어 모델이 평균적으로 얼마나 정답과 유사한 문장을 많이 만들었는지를 순위화하여 모델의 순위를 맞추는 방법 (이 모델이 평균적으로 인간과 얼마나 유사하게 번역문을 생성하는가?)
3. Hybrid-System : 각 reference sentence마다 1개의 candidate sentence를 선정 (모델 구분 없이 랜덤하게)한 후 순위를 계산. Metric들이 이 순위를 얼마나 잘 tracking했는지 비교하는 방법
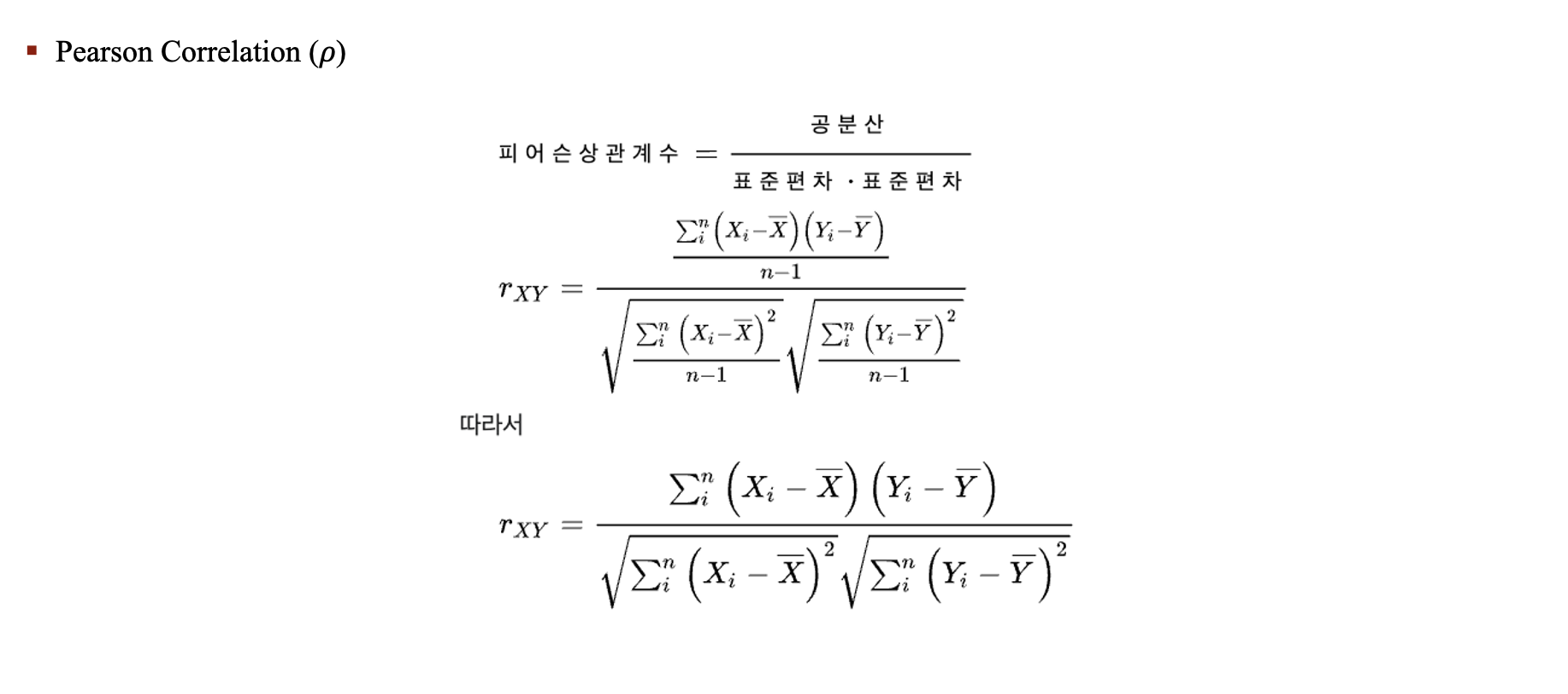
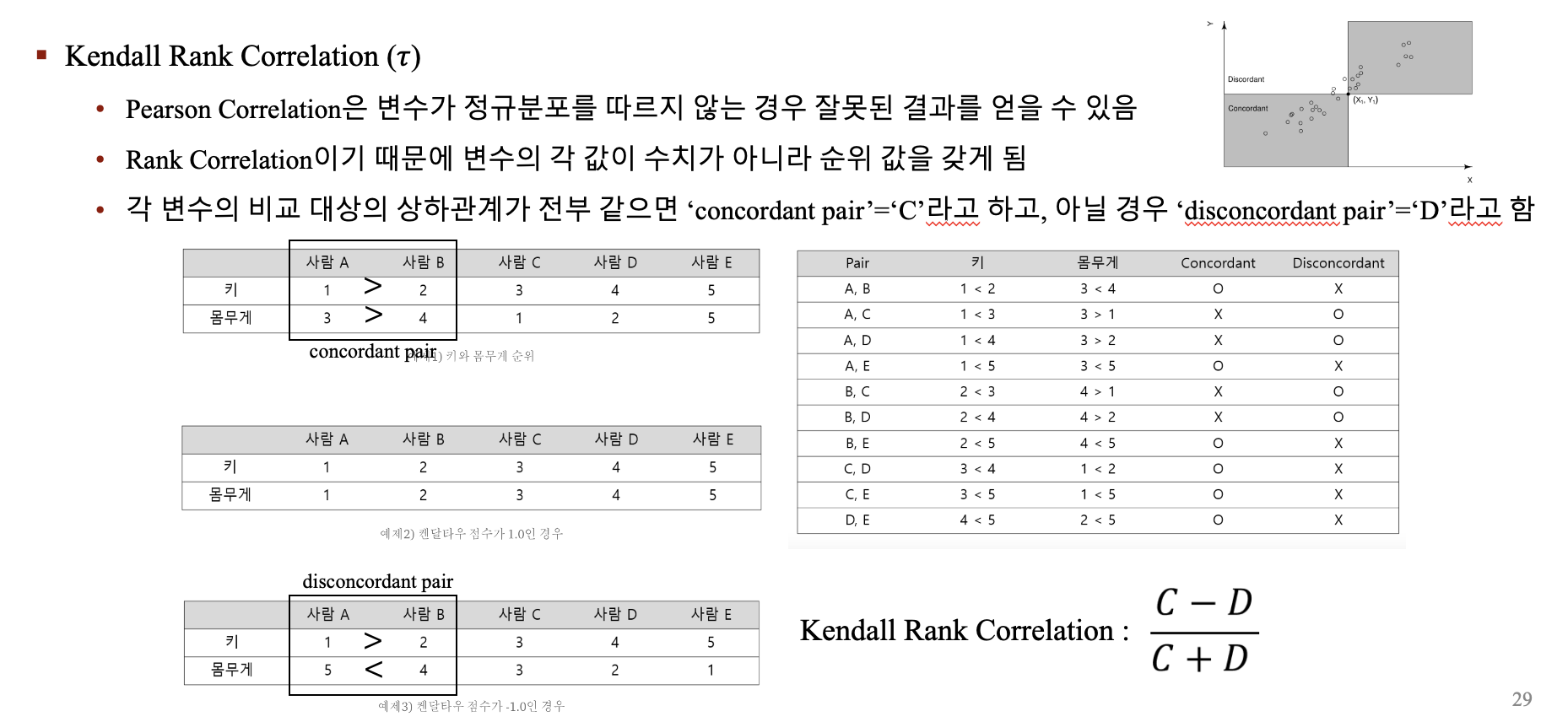
2가지의 지표로 Metric들을 평가
-
Pearson Correlation
-
Kendall Rank Correlation
Results
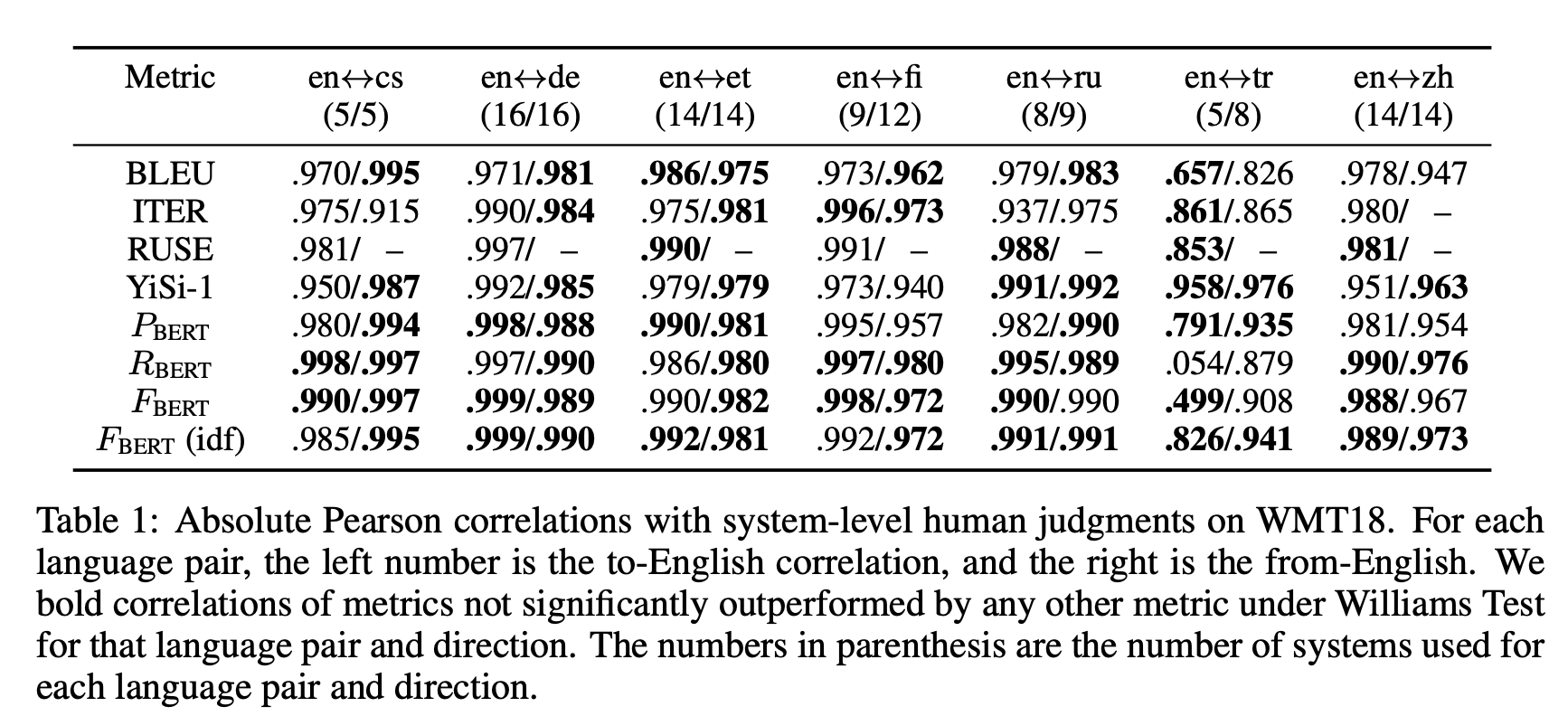
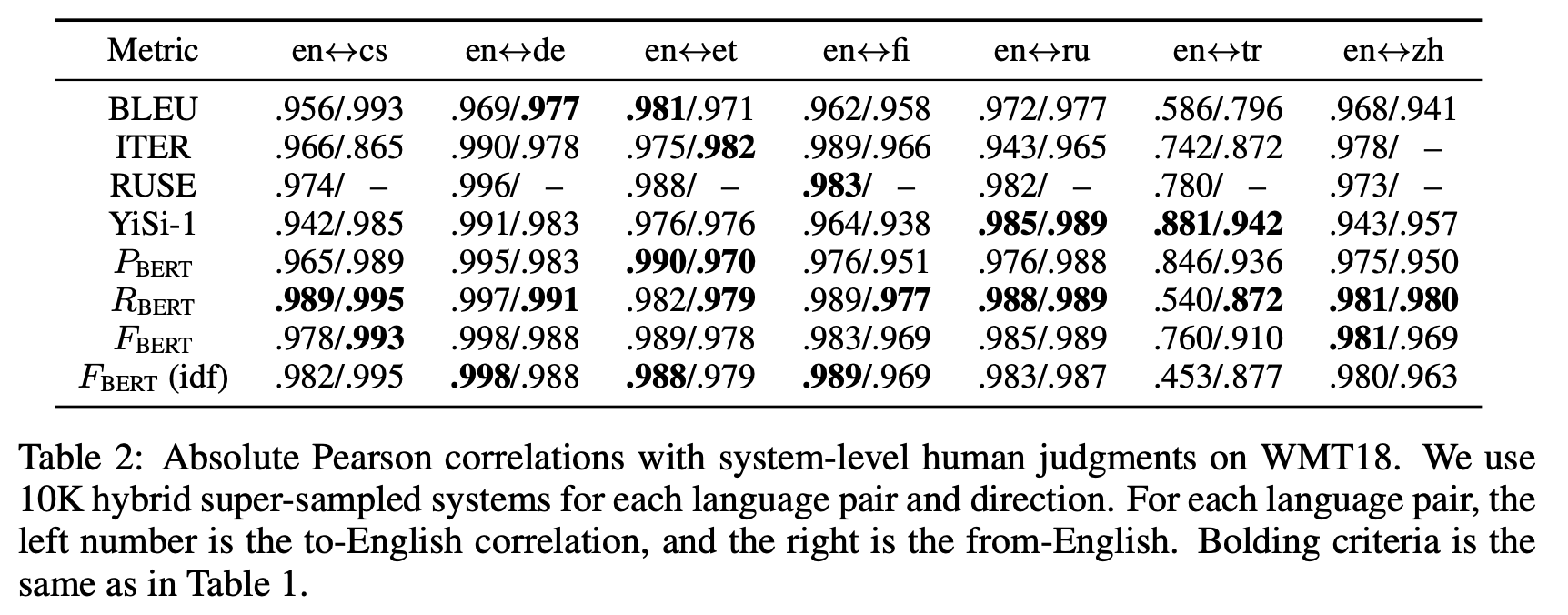
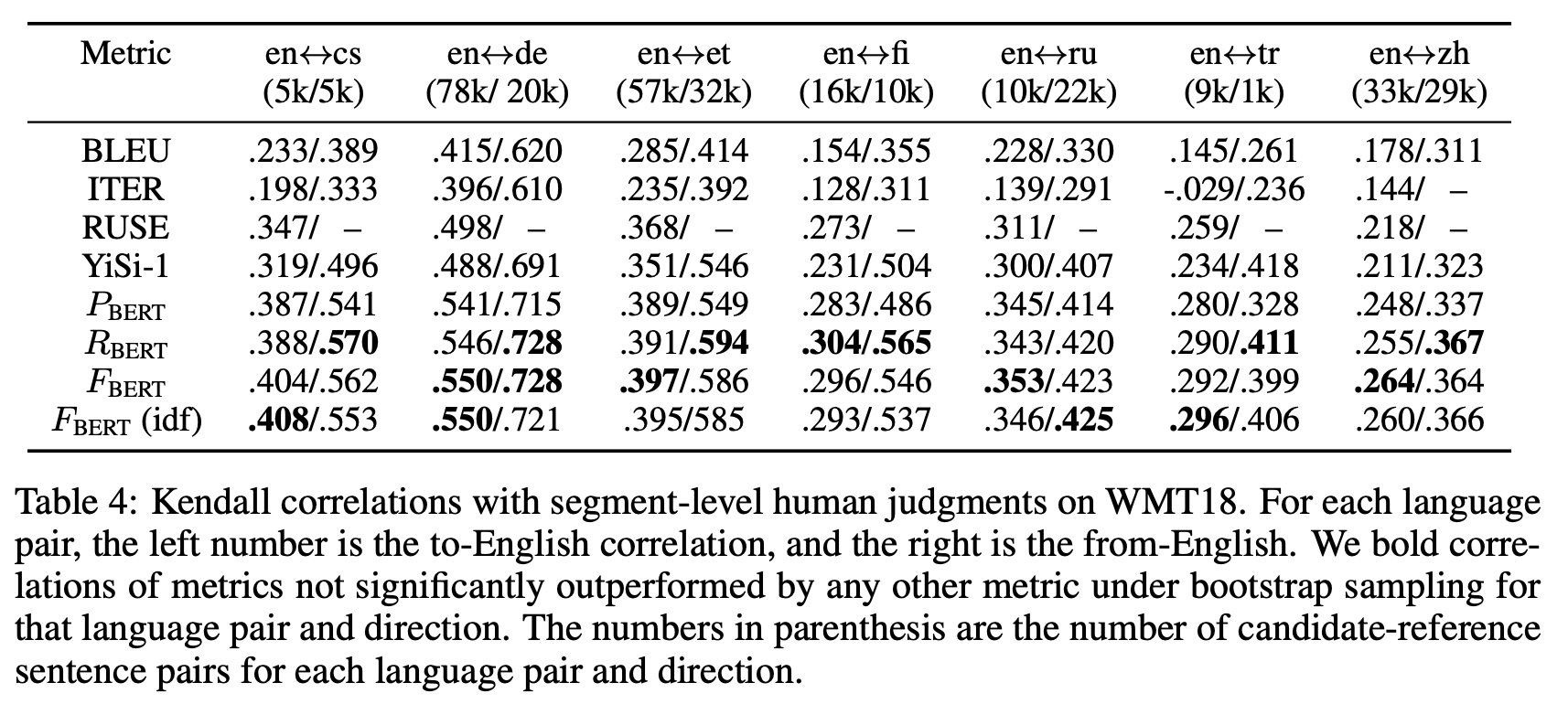
en <-> cs 경우, 왼쪽이 영어로 번여한 문장이고 오른쪽이 영어에서 다른언어로 번역한 문장입니다. (4/5)안의 수는 해당 번역방향으로 사용된 모델의 수, 즉 candidate sentence의 수라고 이해하면 좋을거 같습니다.
논문내 작성된 결과를 요약해보면,
1. RUSE라는 Metric은 기존의 데이터인 WMT16과 WMT15으로 훈련된 Metric이라서 성능이 좋았지만, 기존 데이터에 candidate-reference pair가 없는 경우에는 성능을 측정할 수 없다는 한계가 있다고 지적합니다.
2. 기계번역에서는 IDF weighting이 큰 효과가 없다고 합니다.
3. BERT Precision, Recall, F1 중에서 F1이 안정적으로 좋은 성능이 보여서 F1을 쓸 것을 추천합니다.
Image Captioning
Image를 보고 모델이 생성한 Caption(=candidate sentence)과 5개의 기존 Caption(=reference sentence)이 얼마나 서로 유사한지를 인간이 준 Score과의 상관관계를 바탕으로 평가하는 데이터셋입니다.
2가지의 지표로 Metric들을 평가
- M1 : 모델이 생성한 Caption이 Human Caption 이상으로 평가되는 비율
- M2 : 모델이 생성한 Caption이 Human Caption과 구분이 어려운 비율
(솔직히 봐도봐도 무슨 소리인지 모르겠어서.. 평가지표는 상관관계라 양의 1의 방향으로 높을수록 좋다고 이해하시면 될 거 같습니다.)
Results
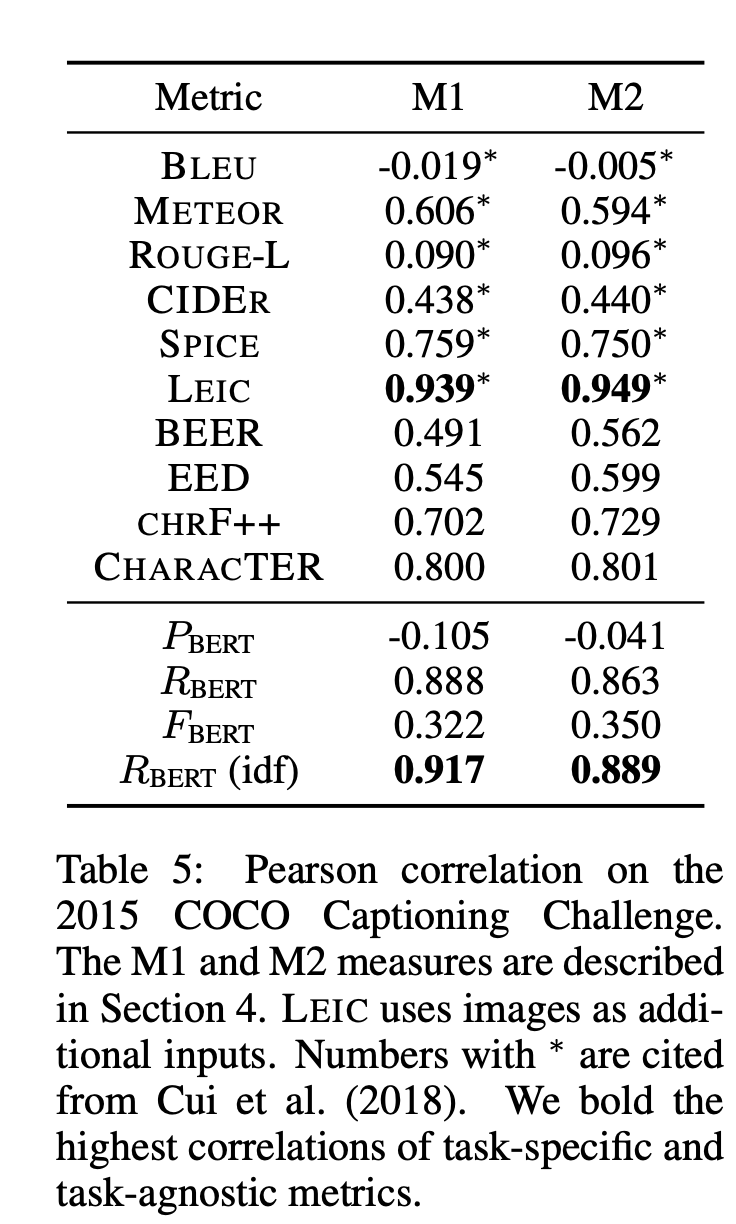
LEIC 지표는 생성된 Caption이 모델이 생성한 것인지를 예측하도록 설계한 Metric이라고 합니다. 따라서 M2지표에서 성능이 압도적으로 좋은거 같습니다.
Image Captioning Task에서 저자들이 주장하는 중요한 keypoint는 기본적으로 캡션은 특정한 단어가 해당 그림을 명확히 설명해주는 경우가 많다보니, IDF weighting을 할 경우 성능향상에 도움이 되었다고 합니다,
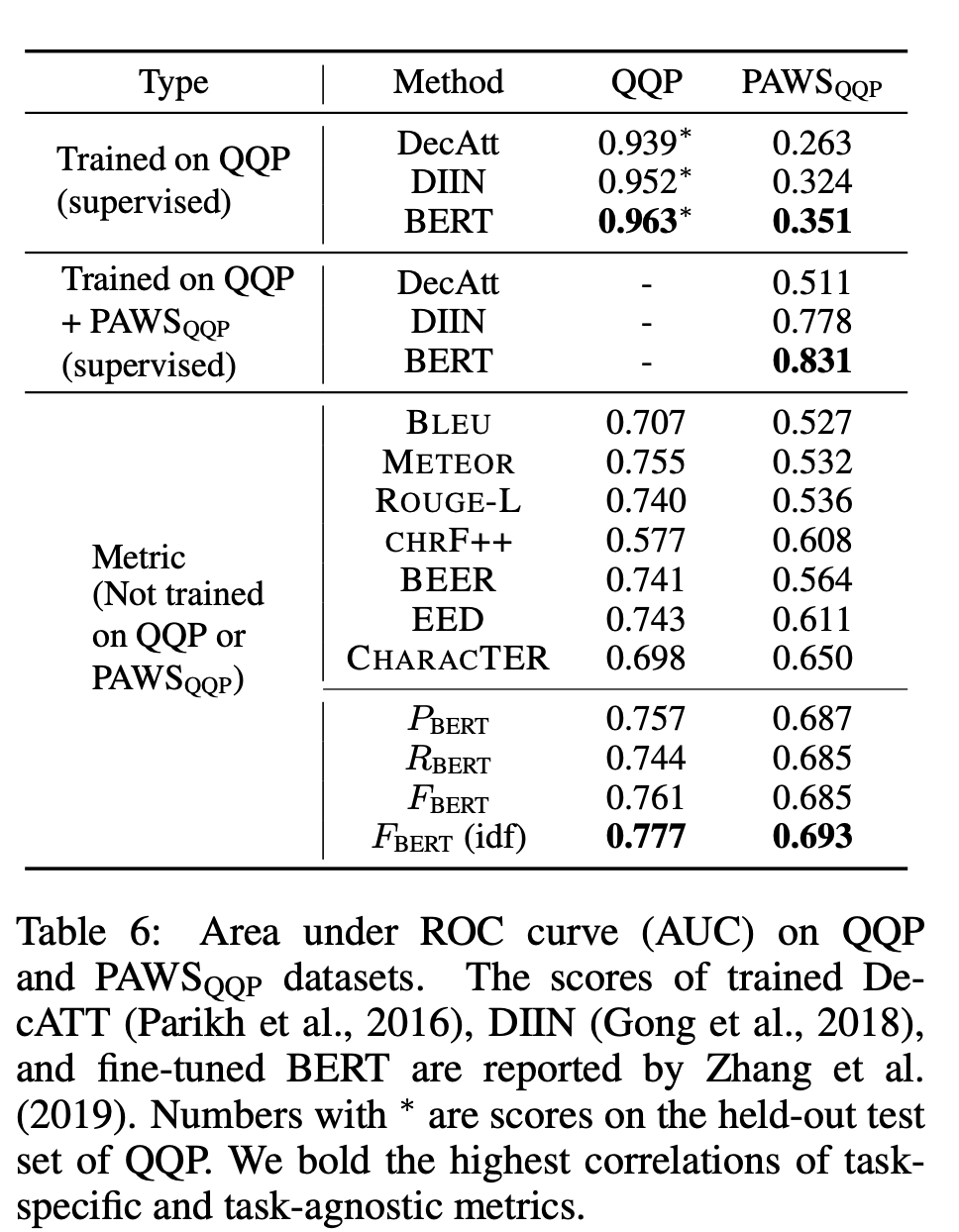
5. Robustness Analysis
저자들은 Paraphrase된 두 문장 혹은 Adversarial하게 Paraphrase된 두 문장이 동일한지 판별하는 dataset인 QQP와 PAWS로 Metric의 Robustness를 평가했습니다.
(For example, in PAWS, Flights from New York to Florida may be changed to Flights from Florida to New York and a good classifier should identify that these two sentences are not paraphrases.)
Metric 중에서는 BERT SCORE가 AUC관점에서 가장 잘 평가하는 것을 확인할 수 있습니다.
6. Discussion
- Simple,Task agnostic, Easy한 NLG Metric을 제시하였다.
- 다른 Metric들보다 여러 실험환경에서 인강보다 높은 correlation을 기록하였다.
- Configuration 설정이 중요하다.
References
