Deep contextualized word representations (ELMo)

이번에 리뷰할 논문은 바로 ELMo의 시작, "Deep contextualized word representations(2018)"입니다.
Abstract
본 논문에서는 새로운 타입의 deep contextualized word representation을 소개하고 있습니다.
deep contextualized word representation
1) 단어 사용의 복잡한 특성(syntax and semantic)
ex. present 단어 뜻 - 선물, 현재 등..
2) 이러한 단어 사용이 언어적 맥락에서 얼마나 다양한지(model polysemy - 모델 다형성(다의성))
를 모델링 한 것!
ex. 문맥에 따라 present의 의미가 달라져야 함. ("Here is your b-day present" vs "Live in present not past")
본 논문의 word vectors는 대량의 corpus로 사전 학습된 deep biLM의 internal state의 학습된 함수로 표현할 수 있습니다. 이러한 representation은 현재 있는 모델에 쉽게 더해질 수 있고, 이를 다양한 데이터셋에 대해서 실험한 결과 6개의 task에서 SOTA를 달성했습니다.
Terminology
LSTM(Long Short-Term Memory)
RNN의 vanishing grdient problem을 극복하기 위해 고안된 모델!
LSTM은 RNN의 hidden state에 cell-state를 추가한 구조입니다.
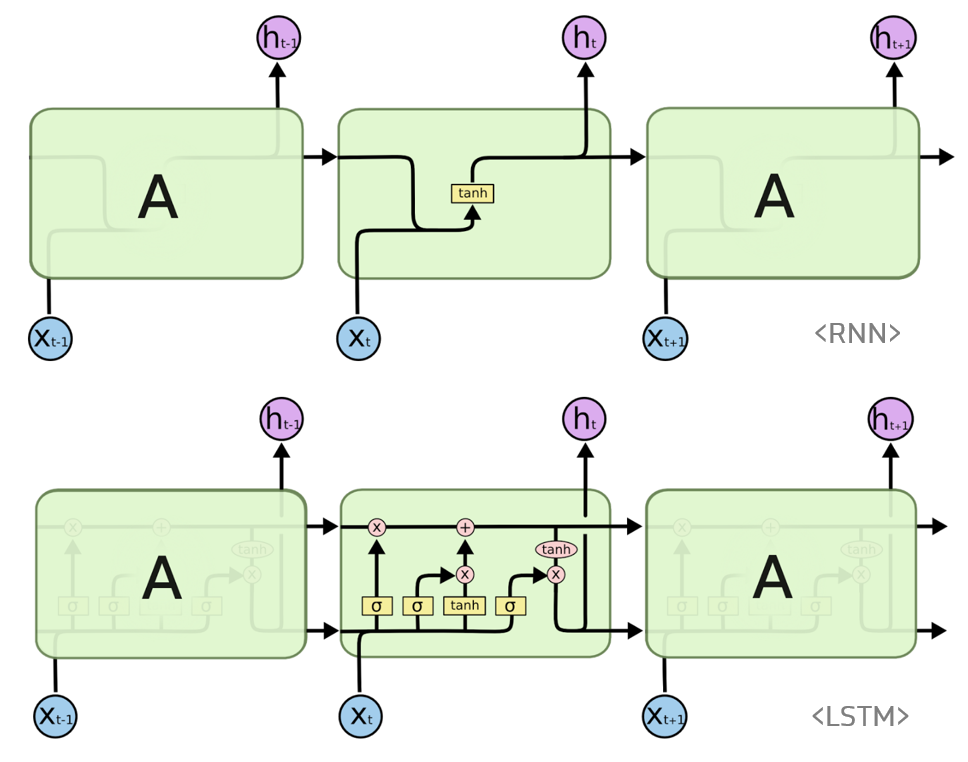
LSTM의 기본 구조는 다음과 같은데, 기본적인 RNN에 비해 안에 여러 gate가 추가되어 있는 걸 볼 수 있습니다. 이제 gate별로 자세히 살펴보도록 하겠습니다.
forget gate
forget gate는 '과거 정보를 잊기 위한' 게이트입니다. 과 를 받아 시그모이드를 취한 값이 forget gate가 내보내는 값이 됩니다. 시그모이드 함수의 출력 범위는 0부터 1사이이므로, 어떠한 확률값이 나간다고 볼 수 있는데, 그 값이 0이라면 이전 상태의 정보를 다 잊는 것이고, 1이라면 이전 상태의 정보를 온전히 기억하게 됩니다.
Input gate
input gate 는 ‘현재 정보를 기억하기 위한' 게이트입니다. 과 를 받아 시그모이드를 취하고, 또 같은 입력으로 하이퍼볼릭탄젠트를 취해준 다음 Hadamard product(원소별 곱) 연산을 한 값이 바로 input gate가 내보내는 값이 됩니다.
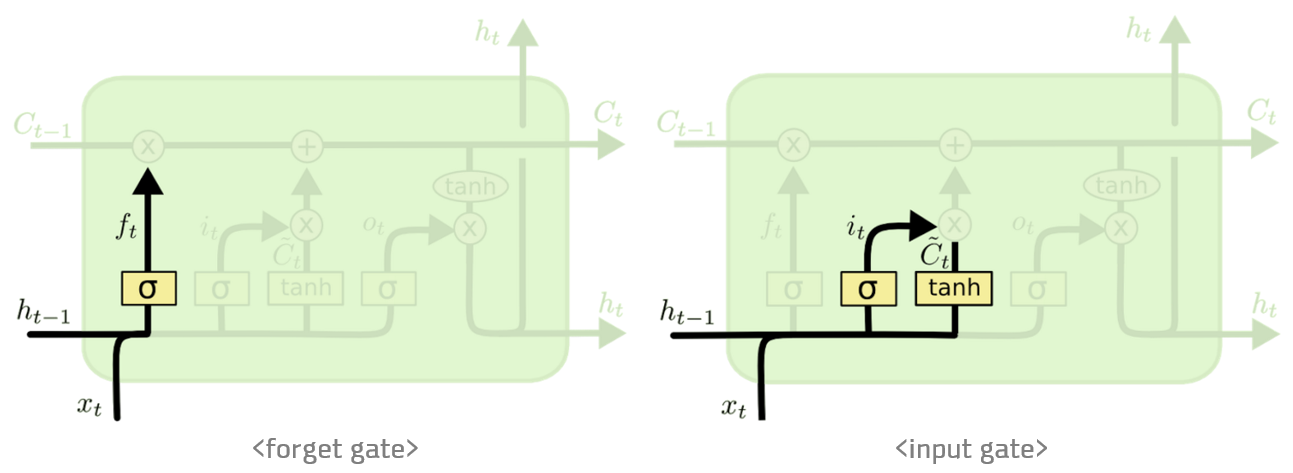
output gate
output gate 는 cell state를 바탕으로 필터링 해 output으로 내보내기 위한 게이트입니다. 먼저 을 계산하고, 이 후 cell state값에 tanh에 태워 -1에서 사이의 값을 받아 와 원소별 곱을 해 원하는 부분만 output으로 내보내게 합니다. (output == hidden state)
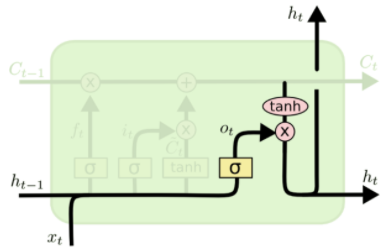
종합하면,
- forget gate와 직전 cell state값을 원소별 곱하고, input gate값을 더해 현재 cell state값이 산출됨
- 이후 현재 cell state을 tanh에 태우고, output gate값과 원소별 곱을 해 output 값, 현재의 hidden state값이 산출됨
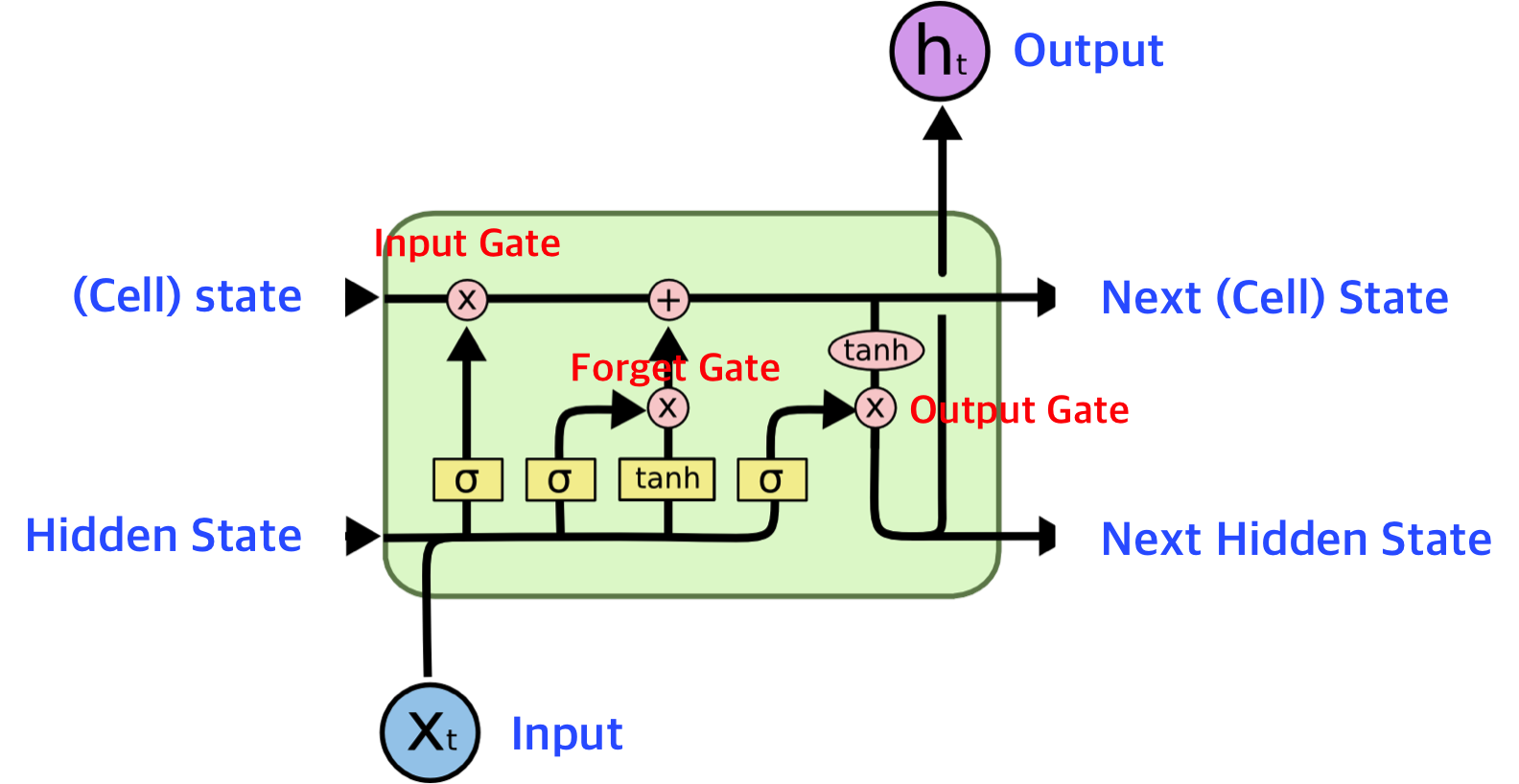
input gate와 forget gate위치 바뀜
참고자료
https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
1. Introduction
NLP에서 사전 학습된 word representaion은 key point가 되어 가고 있습니다. 하지만, 높은 퀄리티의 representation을 학습하는건 어려운 일이었습니다. 여기서 높은 퀄리티의 representation이란 1) 단어 사용의 복잡한 특성(syntax와 semantic) 2) 이러한 단어 사용이 언어적 문맥에서 얼마나 다양한지(모델의 다의성)를 이상적으로 모델링한 것입니다.
본 논문에서 주장하는 representation은 각 토큰을 전체 입력 문장의 함수로 표현한다는 점에서 다른 전통적인 word embedding과 다릅니다. 본 논문에선 대량의 코퍼스로 학습된 한쌍의 LM, bi-LSTM에서 파생된 벡터를 사용합니다. 이러한 단어 표현을 ELMo(Embeddings from Language Models) representation이라고 합니다.
ELMo는 biLM의 모든 내부 레이어에 대한 함수라는 deep!하다고 말할 수 있습니다. 더 구체적으로 말하자면, 각 입력 단어 위에 쌓인 벡터들의 선형 결합을 학습합니다.(마지막 layer만 쓰는 것 보다 좋음 / 각 레이어가 갖고 있는 정보가 다르니까!)
internal state를 합쳐 사용해 풍부한 단어 표현이 가능
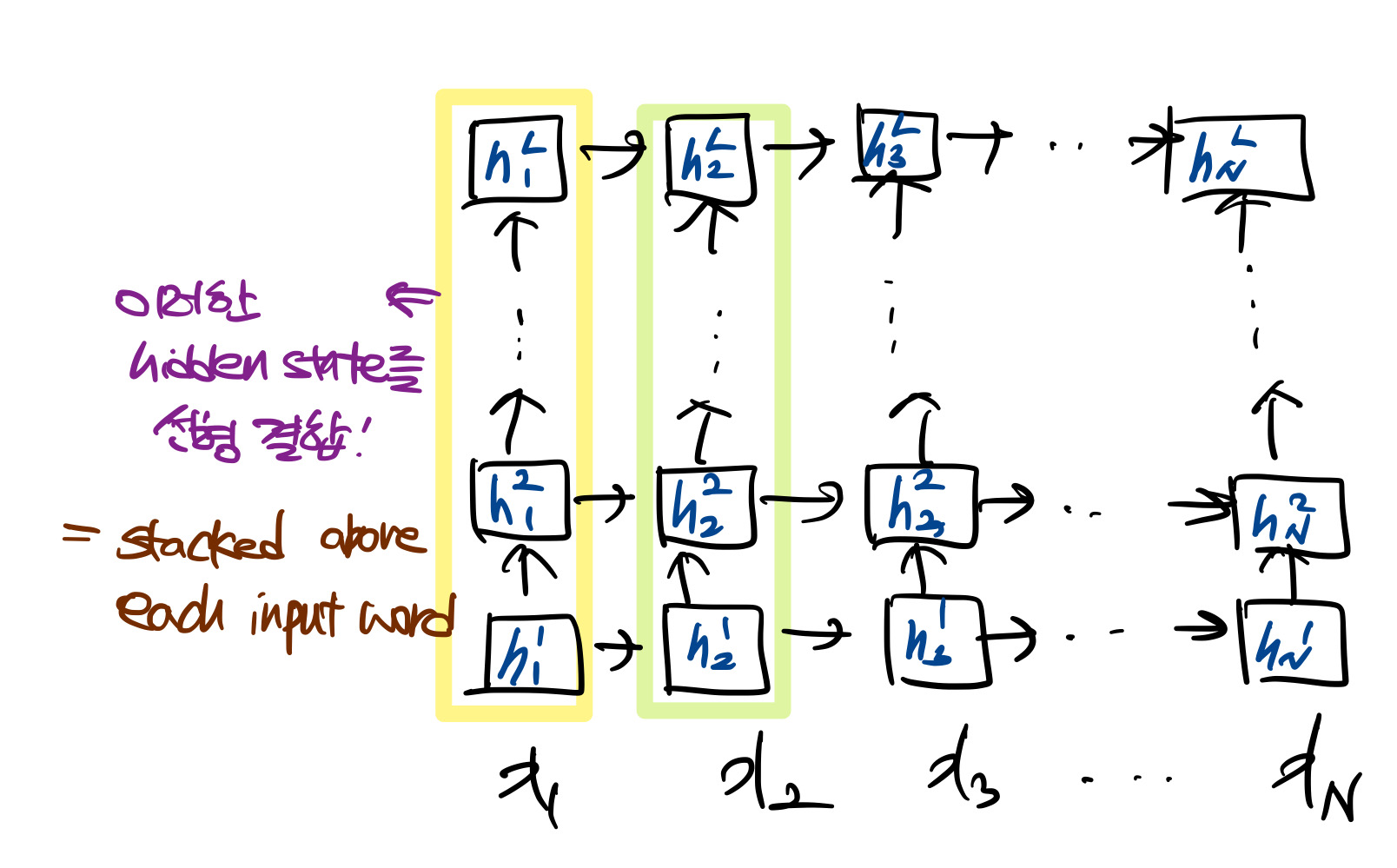
higher-level의 LSTM state 문맥에 의존한 단어 의미를 포착하고, lower-level의 LSTM state는 syntax 측면의 의미를 포착합니다. 이러한 시그널을 각 end task에 가장 유용하도록 적절히 선택합니다.
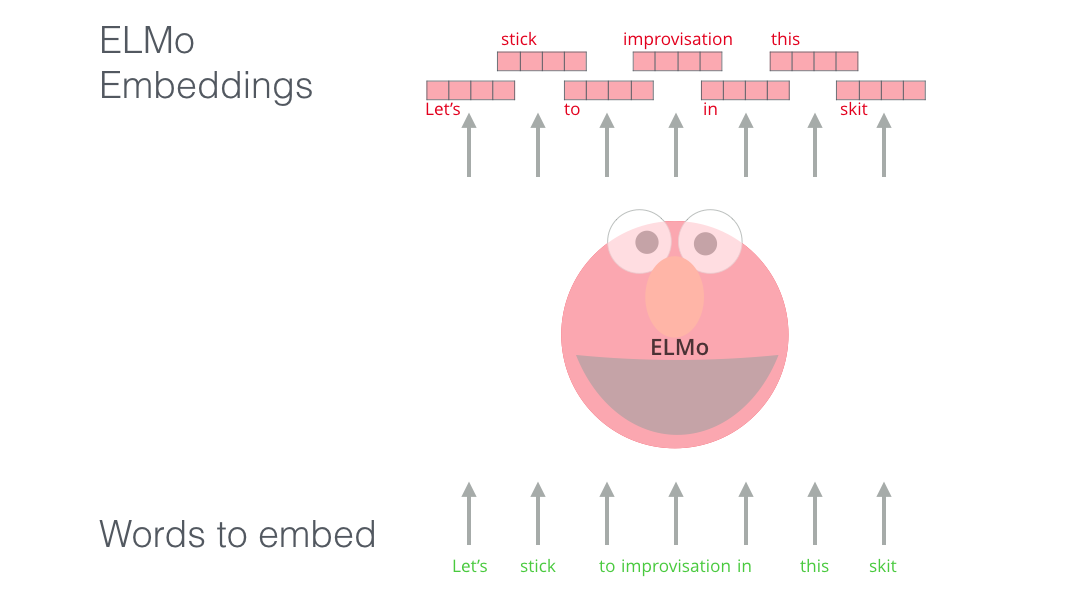
ELMo가 실전에서 아주 훌륭한 representation이라는 것을 증명하기 위해, 6가지 task에 대한 기본 모델에 ELMo를 추가하였습니다. 실험 결과, ELMo가 CoVe보다 뛰어났고, 마지막 레이어 하나만 쓰는 것보다 deep representation을 쓰는 것이 더 좋다는 사실을 밝혀냈습니다.
2. Related work
기존의 사전 학습된 단어 벡터는 syntax & semantic과 같은 정보를 잘 포착하고 있어, 뛰어난 성능을 보였습니다. 하지만 이러한 방법은 오직 각 단어에 대한 하나의 context-independent representation만 생성할 수 있다는 단점이 있었습니다.
학습 시엔 주변 단어를 고려해 단어가 임베딩되지만, 학습 후 이를 사용할 땐 문맥을 고려하지 않음. 또한 present라는 단어가 사전 학습된 word vector로 표현 되었다고 했을 때, 이것이 현재 문맥에 맞는 의미를 가진(현재 or 선물) 적절한 표현인진 알 수 없음.
그래서 한 단어를 subword information을 이용해서 다양한 뜻을 표현할 수 있도록 하거나, word sense별로 서로 다른 representation을 생성하는 방법 등을 제안되었습니다. 이번 논문에서 제안하는 방식도 subword information을 character convolution을 통해 단어를 학습하게 됩니다.
Chracter-Aware Neural Language Models
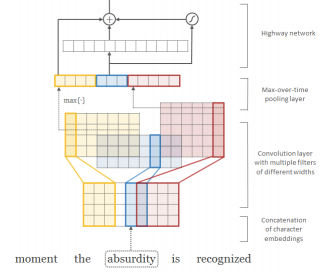
각 단어를 character-level로 표현. 각 문자를 벡터로 바꾸고, 문자 벡터들을 concat. concat 후에 CNN 1D를 사용해서, h=2,3,4등이 다양한 크기의 필터를 사용해 subword feature 추출. 이후 이를 concat해서 단어를 나타내는 초기 벡터로 사용.
다른 최근 연구도 Context-dependent representation 학습에 집중하고 있습니다. Context2vec 은 bidirectional LSTM을 사용해서 중심이 되는 특정한 단어 주변의 문맥을 임베딩하게 됩니다. 다른 연구에서, 문맥에 중심이 되는 단어까지 포함해서 문맥을 임베딩하고 supervised MT의 인코더에 넣어 계산한 CoVe라는 모델도 있었습니다. 하지만 MT는 병렬 코퍼스이기 때문에 크기가 한정되었다는 단점이 있는데, 본 논문에선 풍부한 단일 언어 코퍼스를 사용했습니다.
과거의 연구들도 deep biRNN의 서로 다른 layer은 서로 다른 특성을 임베딩한다는 것을 발견했습니다. 높은 LSTM layer(higher-level)는 문맥에서 단어의 의미를 학습하게 되고, 낮은 layer(lower-level)은 단어의 문법적인 측면(POS 등)을 학습하게 됩니다. ELMo도 이와 같은 시그널이 있었기 때문에, 이들을 잘 섞어 기존의 task에 적용해 사용하면 더 좋은 성능을 보였습니다. 본 연구에선 biLM을 unlabeled data로 사전 학습한 후, 가중치는 고정하고 추가적인 task-specific model capacity를 추가해 비록 task에 대한 데이터가 작더라도 풍부하고 범용적인 biLM representaion을 통해 더 효율적으로 모델을 사용할 수 있게 하였습니다.
3. ELMo : Embedding from Language Models
3.1 Bidirectional language models
개의 토큰이 주어질 때, , 한 forward language model은 주어진 과거 을 이용해 토큰 의 확률을 모델링 해 sequence의 확률을 계산합니다. 이를 식으로 표현하면 다음과 같습니다
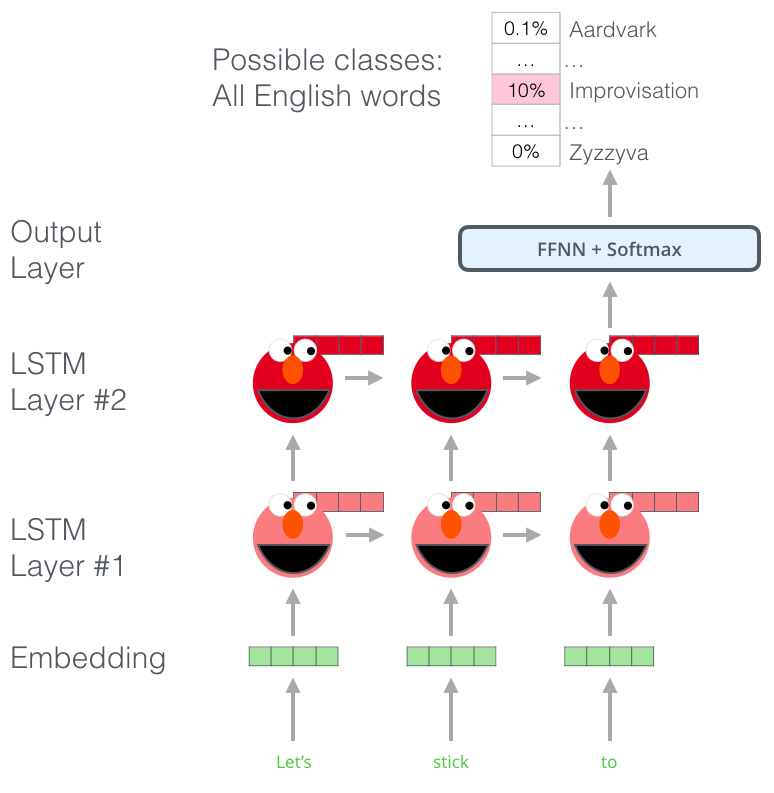
최근의 SOTA neural language model에서는 문맥에 독립적인 token representaion (token embedding 또는 CNN over chacracters)을 계산하고, forward LSTM의 L개의 레이어를 거칩니다. 각 위치 에서, 각 LSTM 레이어는 문맥에 의존적인 표현
울 산출합니다(j=1,...,L). 가장 상단의 LSTM 레이어의 output 은 softmax layer에 태워 다음 token 을 예측하는데 사용됩니다.
backward LM은 forward LM과 유사하게 sequence를 역으로 넣어서 미래 context가 주어질 때 아전 token을 예측하는 방식입니다.
이는 forward LM과 유사한 방식으로 실행될 수 있고, L개 레이어의 deep model에서 각 backward LSTM layer 은 이 주어질 때 을 통해 을 산출합니다.
이제 이 두 방향을 결합하고 즉, 두 식을 곱한 후에 가 위치할 최대 우도(Maximum Likelihood)를 구하면 됩니다.
위 식에 로그를 취해주면 다음과 같은 식이 나오게 됩니다.
위 식에서 token representation에서 쓰는 파라미터()와 softmax layer에서 사용하는 파라미터()는 두 방향 모두에 같은 파라미터가 적용된다. 은 각 방향 LSTM층에서 사용되는 파라미터로 방향마다 다른 파라미터가 학습됩니다.
3.2 ELMo
ELMo는 biLM의 intermediate layer representations의 task specific한 결합(combination)입니다. 각 token 에 대해 L-layer biLM은 representations의 집합을 계산합니다.
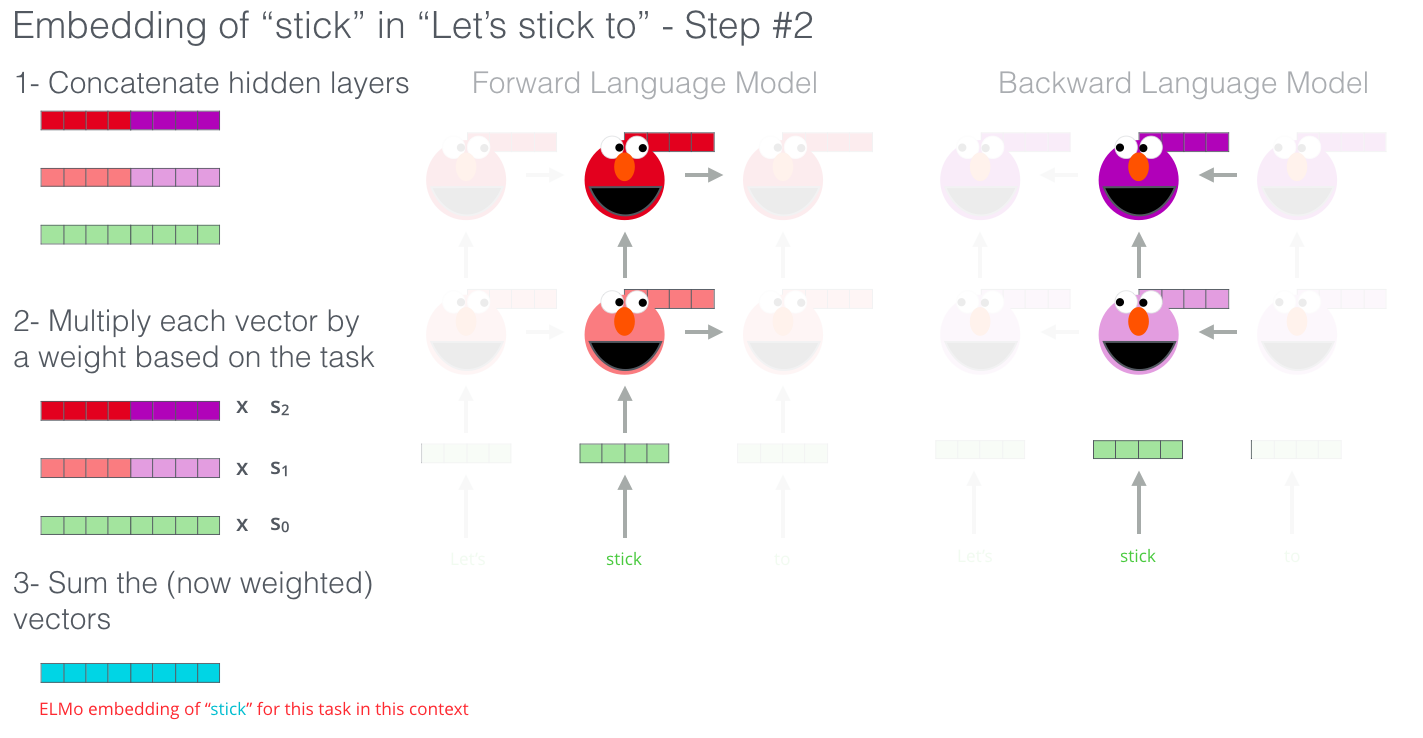
이 때, 은 token layer이고, 각 biLSTM layer에 대해 입니다.
downstream model에서 포함하기 위해, ELMo는 에서 모든 layer를 하나의 벡터로 합칩니다. 이를 로 표기합니다. 가장 간단한 경우 ELMo는 최상단의 layer를 선택한 것과 같습니다(, TagLM과 CoVe가 이 방법 사용!). 더 일반적으로 우리는 모든 biLM layers에 task specific한 가중치를 계산합니다.
여기서
- 는 softmax-normalized weights
- 는 scalar parameter
: 는 세 벡터를 가중합하여 나온 최종 벡터의 요소를 얼마나 증폭 혹은 감소시킬 것인지에 대한 Scale factor이며 태스크에 따라서 달라지게 됩니다. - 각 biLM layer의 activation가 서로 다른 분포를 갖는 것을 고려할 때, 어떤 경우엔 가중치를 부여하기 전에 각 biLM layer에 layer normalization을 적용하는게 도움이 되었다고 합니다.
3.3 Using biLMs for supervised NLP tasks
사전 학습된 biLM과 target NLP task에 대한 supervised architecture가 주어질 때, task model을 향상시키기 위한 biLM을 사용하는 것은 간단한 프로세스입니다.
-
biLM을 실행하고, 각 단어에 대해 모든 layer representations를 기록한다.
-
end task model이 아래처럼 representations의 선형 결합을 학습한다.
- 대부분의 supervised NLP모델은 가장 하단 레이어의 아키텍처를 공유 여기에 ELMo 붙이자!
- 토큰 시퀀스 이 주어질 때, 사전 학습 word embedding과 선택적으로 character-based representations을 사용해 각 token position에 대한 context-independent token representation 를 형성
- 이후, 모델은 context-sensitive representation 를 형성하고, 이 때,보통 bidirectional RNNs, CNNs, 또는 feed forward neworks를 사용
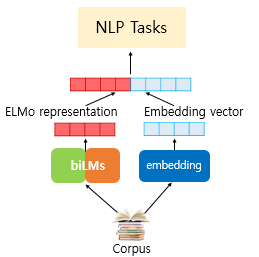
ELMo를 supervised model에 더하기 위해, 우선 biLM의 가중치를 freeze하고 와 을 concatenate해서 을 task RNN에 넣습니다.
특정 task(SNLI, SQuAD)에서 ELMo를 task RNN의 output단계에도 포함, 대신 로 바꾸는게 더 좋습니다.
마지막으로 ELMo에 적절한 droput을 추가하는 것이 좋고, 때때로 loss에 를 더해 ELMo 가중치를 정규화하는게 좋습니다. 이는 모든 biLM레이어의 평균이 가깝도록 ELMo 가중치에 inductive bias를 부과합니다.
3.4 Pre-trained bidirectional language model architecture
본 논문에서 pre-trained biLMs는 양방향을 함께 학습하고, LSTM layer사이에 residual connection을 추가하였습니다.
모델 크기에 따른 언어 모델 perplexity와 computational requirements를 조절하기 위해 여기선 단일 최고 모델인 CNN-BIG-LSTM의 모든 embedding과 hidden dimensions을 이등분했습니다. 최종 모델은 L-2 biLSTM layers with 4096 units and 512 dimension preojection과 첫번째에서 두번째 레이어 사이에 residual connection을 추가해 완성했습니다. 결로적으로 biLM은 각 입력 토큰에 대해 representation의 3-layers를 제공합니다(BiLSTM2, CNN1).
또한, 1B Word Benchmark에 대해 10 에폭 학습 후엔, 평균적인 forward와 backward의 perplexities는 39.7을 기록하였습니다.(CNN-BIG-LSTM은 30.0) 일반적으로, forward와 backward perplexities는 근사적으로 동일했고, backward가 아주 조금 더 낮았습니다.
사전학습한 후에 biLM은 어떤 task에 대해서든 representations을 계산할 수 있습니다. 몇몇 경우에서, biLM을 domain specific data에 대해 fine tuning했더니 perplexity는 낮아지고, task performance는 증가한 것을 볼 수 있었습니다. 즉, biLM을 가지고 한 일종의 domain transfer라고 볼 수 있습니다.
4. Evaluation & Analysis
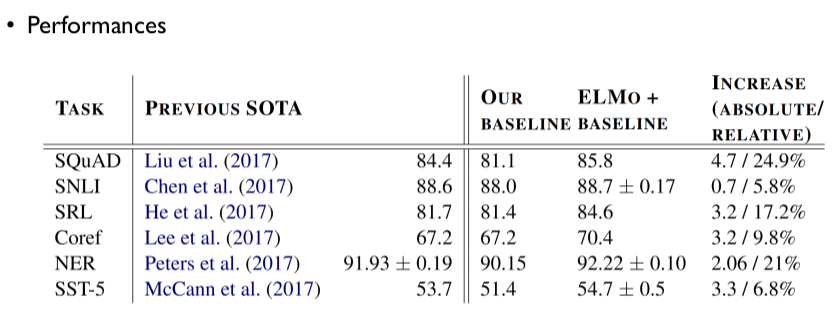
아래는 다양한 태스크에서 ELMo가 보여준 성능을 기록한 것입니다. 몇몇 태스크에 대하여 당시의 SOTA모델보다 좋은 성능을 보였음을 알 수 있습니다.
-
Performances
-
sample efficiency
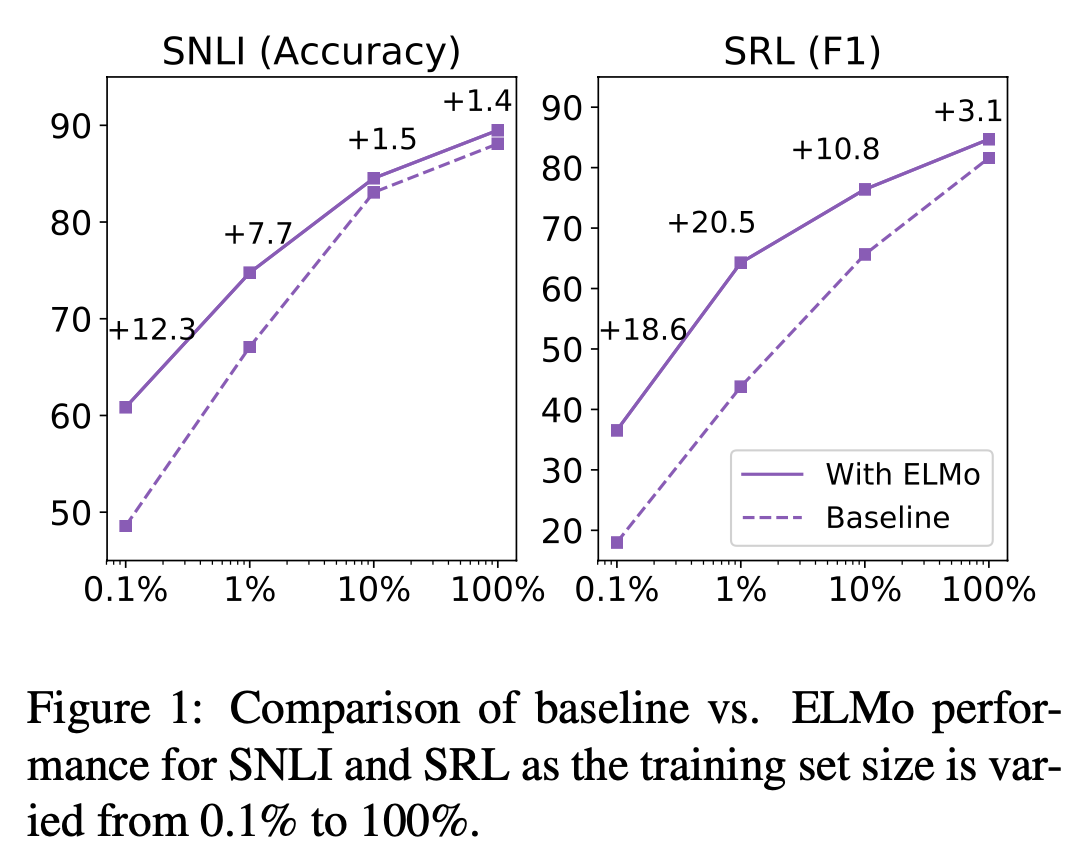
ELMo의 사용은 일정 수준 이상의 성능 달성에 필요한 parameter update 횟수 및 전체 training set size를 획기적으로 줄여줍니다. SRL task에 있어서 ELMo 사용 이전 baseline model의 경우에는 486 epoch가 지나서야 score가 수렴했는데, ELMo를 추가하고 난 뒤에는 10 epoch만에 baseline model의 score를 능가했습니다.또한 위의 그림을 보면, 같은 크기의 dataset에서 ELMo를 사용하는 경우가 훨씬 더 좋은 성능을 낸다는 것을 보여줍니다. SRL task에서는 학습 데이터셋의 단 1%를 학습했을 때 달성한 수치와 baseline model이 학습데이터셋의 10%를 학습했을 때의 수치가 동일하다는 것을 알 수 있습니다.
-
visualization of learned weights
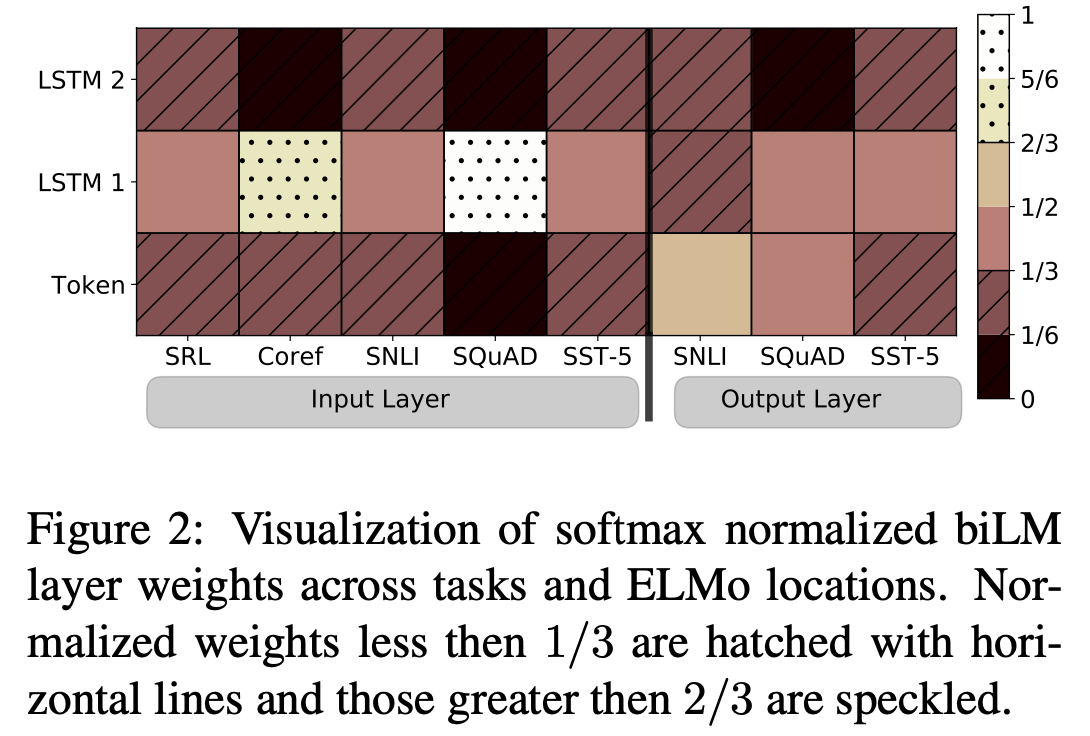
위 그림은 softmax-normalized parameter 를 시각화한 자료입니다. ELMo를 biRNN의 input과 output에 사용했을 때를 각각 나눠서 비교했습니다. ELMo가 input에 사용되었을 떄는 대부분 first LSTM layer가 가중치가 높다는 것을 볼 수 있습니다. 반면 ELMo가 output에 사용된 경우엔 하단 layer가 더 높은 가중치를 갖고 있음을 볼 수 있습니다. -
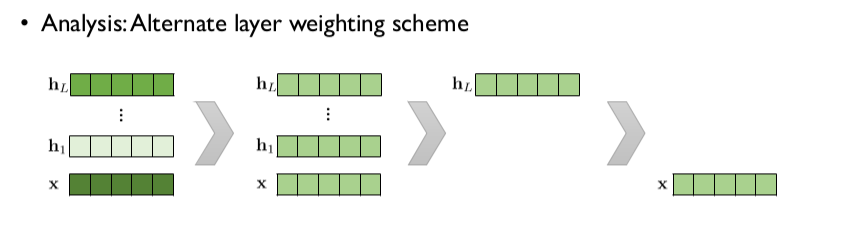
"임베딩 벡터와 은닉 벡터에 가중치를 어떻게 부여할 것인가?"
논문에서 적용했던 것과 같이 개의 벡터에 모두 다른 가중치를 적용했을 때의 성능이 가장 좋은 것을 볼 수 있습니다. 이는 개의 벡터에 모두 같은 가중치를 적용했을 때보다 성능이 높고, 최상단 hidden layer가 생성한 벡터를 사용하는 것이 그냥 단어 임베딩 벡터를 사용하는 것보다 좋다는 연구 결과가 있습니다.
-
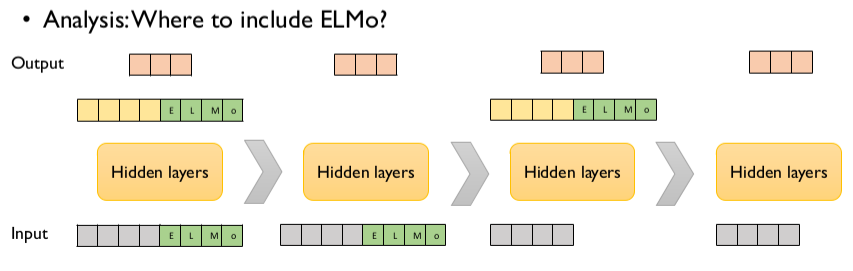
“ELMo 임베딩 벡터를 어떤 단계에 Concatenate하는 것이 좋은가?”
입출력 단계에 모두 ELMo 임베딩을 적용하는 것이 가장 좋은 것을 볼 수 있습니다. 입, 출력 벡터 중 하나에만 적용하는 경우는 모두 적용한 경우보다는 떨어지지만, 아무것도 사용하지 않은 모델보다는 좋은 성능을 보여주는 것을 알 수 있습니다.
-
"biLM의 representation에서 무슨 정보가 포착되는가?"

직관적으로 biLM은 문맥을 사용해 단어의 의미를 명확하게 할 것입니다. "play"라는 단어를 생각해보면, 굉장히 여러 의미가 있다는 것을 알 수 있습니다. GloVe를 사용하여 "play"를 임베딩할 경우 "play"의 여러 의미와 표현("player","playing" 등)이 퍼져있지만, 대체로 sport에서 쓰는 "play"의 의미에 초점이 맞춰져 있는걸 볼 수 있습니다. 표에서 2행에 있는 "play"는 GloVe가 판단한 것과 동일한 "스포츠(경기)"를 의미하고 있으며 마지막 행에 있는 "play"는 "(a Broadway)play"를 의미하고 있습니다. 즉, ELMo는 "play"를 문맥에 맞게 잘 판단하고 있는 것으로 볼 수 있습니다.
ELMo를 시작으로 대량의 코퍼스에서 좋은 임베딩 벡터를 만드는 모델이 많이 사용되었습니다. ELMo는 이후 나오는 트랜스포머 기반의 BERT나 GPT보다 많이 사용되진 않지만 이렇게 좋은 임베딩 벡터를 바탕으로 적절한 Fine-tuning후에 여러 태스크에 전이 학습(Tranfer learning)의 시초로 의의가 있습니다.
참고자료
https://yngie-c.github.io/nlp/2020/07/03/nlp_elmo/
https://www.youtube.com/watch?v=zV8kIUwH32M
