Characterizing the Efficiency vs. Accuracy Trade-off for Long-Context NLP Models
본 논문은 2022 ACL에 실린 논문입니다. 긴 시퀀스를 받는 언어 모델을 만드는 것이 정말 정확도와 효율적인 측면에서 맞는 일인가?에 관한 observation paper입니다. 이 논문은 읽기 전에 longformer, bigbird, summarization task, QA task에 대한 사전 지식이 있으면 이해하기 좋습니다.
Abstract
- 긴 텍스트를 다루는 NLP의 다양한 응용으로, 더 긴 input sequences를 다룰 수 있는 모델의 정확도를 측정하는 벤치마크들이 부상.
- 하지만, 이러한 벤치마크들인 input size 또는 model size가 달라짐에 따라 정확도, 속도 그리고 전력 소비 사이의 trade-off는 고려하지 않음.
본 논문에선, 널리 사용되는 긴 시퀀스의 모델 Longformer-Encoder-Decoder(LED)와 BigBird에 대해 SCROLLS 벤치마크의 4가지 데이터셋에 대해 fine-tuing과 inference를 하며 정확도 대 효율성 trade-off에 관한 구조적 연구를 진행.
- 4개의 시퀀스 길이(1024, 2048, 3072, 4096)과 2개의 모델 크기(base, large)에 대해 비교
실험 결과는 다음과 같다.
- LED가 BigBird보다 낮은 전력 + 뛰어난 성능을 달성했다.
- 요약에서, 우리는 모델의 크기를 늘리는 것이 시퀀스의 길이를 늘리는 것보다 정확도 측면에서 더 효율적 (그러나, inference speed가 크게 떨어짐)
- QA에서, 한정된 자원에서 학습 배치 크기가 더 커지기 때문에 큰 모델보다 작은 모델이 효율적이면서 더 정확함
1 Intrduction
Green AI를 시작으로, 연구자에게 에너지와 계산 효율을 고려하는 것이 요구되었다. 그러나 아직까지 efficiency metric이 LRA, SCROLLS 와 같은 제안된 벤치마크들과 통합되지 못했다.
- 이러한 벤치마크들은 트랜스포머 모델들을 정확도 관점에서만 비교
- 그러나, 향상된 정확도가 모델 크기를 키우거나 입력 시퀀스의 길이를 늘려서 달성된 것일 경우, 이에 따른 에너지 비용은 명확하지 X
- 속도 측면에서의 모델 효율성의 이전 특징들은(in LRA) 오직 inter-model comparisons(e.g. model size, input length)만 집중한다.
그래서 본 논문에서는 하이퍼파라미터를 선택할 때 정확도와 효율성의 trade-off가 모델 내 비교에도 영향을 미친다고 주장한다.
본 논문에서, 우리는 널리 사용되는 long-context NLP models - BigBird와 LED에 대해 효율성과 정확도의 trade-off에 관한 연구를 수행하였다.
- 우리는 효율성을 몇가지 지표(학습 시 소요되는 에너지 소비량, 학습 속도, inference 속도, 전력 효율)를 사용해 나타냈다.
- 우리는 4개의 다른 입력 시퀀스 길이와 2가지 다른 모델 크기에 대해 이 모델들을 비교한다.
실험한 결과는 다음과 같다.
- 전체적으로, 요약에선, 우리는 모델의 크기를 늘리는 것이 정확도를 높이는 측면에서 더 효율적이라는 사실을 밝혀냈다.
- 하지만 inference 속도가 효율성에서 주된 관심사라면, 더 작은 모델이 낫다.
- QA에선 우리는 더 작은 모델일수록 학습 시 배치 크기가 커지기 때문에 효율성과 정확도의 측면 모두에서 더 낫다는 것을 알았다.
2 Background
2.1 NLP Benchmarks
SuperGLUE와 SQuAd와 같은 벤치마크들은 NLP모델의 발전에서 중요한 기반이 되어왔다. 그러나 이러한 벤치마크들은 많은 NLP task(요약, QA..)의 관심사가 긴 문장을 받는 것임에도 불구하고 짧은 문장에 대한 모델의 성능만 포착한다.
최근에, 여러 효율적인 트랜스포머 모델들은 입력 길이에 대해 sub-quadratic() memory와 time complexity가 요구된다는 것이 밝혀졌다.
==> 결과적으로, 새로운 표준화된 벤치마크들은 특히 긴 시퀀스를 이러한 모델이 모델링할 수 있냐(수용력)에 대해 초점을 맞춰왔다.(Long Range Arena(LRA), SCROLLS)
LRA가 긴 시퀀스의 모델을 평가하지만, 이 평가지표는 오직 byte tokenize를 통해 인공적으로 입력 길이를 연장한 2가지 언어의 데이터셋만 포함하고 있다. 또한, LRA는 다른 하이퍼파라미터는 무시한 채 다른 모델 아키텍처들의 속도만 비교한다.
한편, SCROLLS 벤치마크는 요약, QA, 분류를 포함한 긴 길이의 시퀀스에서부터 자연스럽게 합성한 정보(synthesizing information)을 요구하는 언어 태스크에 초점을 두고 있다. 우리의 분석에서, 우리는 SCROLLS에서부터 3개의 요약 태스크와 1개의 QA 태스크를 활용한다.
2.2 Energy Considerations
딥러닝 모델이 늘어나는 수요를 충족시키기 위해 더 복잡해짐에 따라, 모델을 실행시키는데 드는 계산량은 점진적으로 큰 energy cost를 만들어낸다.
==> 이는 SOTA를 유지하면서도 더 높은 에너지 효율을 요구하는 Green AI 관점을 이끌었다.
AI 성능과 에너지 효율의 벤치마크는, 오직 2-layer LSTM과 vailla Transformers에 대해서만 테스트되었다.
- HULK는 pre-training, fine-tuning, inference동안 서너개의 Transformer 모델(BERT, RoBERTa)의 에너지 효율을 평가하는 NLP dataset
- 하지만 긴 입력 길이를 가진 모델은 고려하지 않음
추가적으로, 에너지 효울과 정확도 모두에 대해서 다양한 시퀀스 길이의 효과를 고려하는 벤치마크는 없다. 그러나 우리는 HULK로부터 관찰에서 모델의 사이즈가 커지는 것이 항상 낮은 효율을 암시하지 않는다는 것을 확인했다.
3 Methodology
우리의 주된 contribution은 긴 길이의 트랜스포머 모델들이 fine-tuing하고 inference하는 동안 시퀀스의 길이가 정확도, 전력, 속도 사이의 trade-off에 얼마나 많은 영향을 끼치는지에 대한 분석이다.
우리의 초점이 긴 길이의 NLP task에 있기 때문에, 우리는 다음 4개의 입력 시퀀스 길이에 대해 조사했다 : 1024, 2048, 3072, 4096
3.1 Datasets
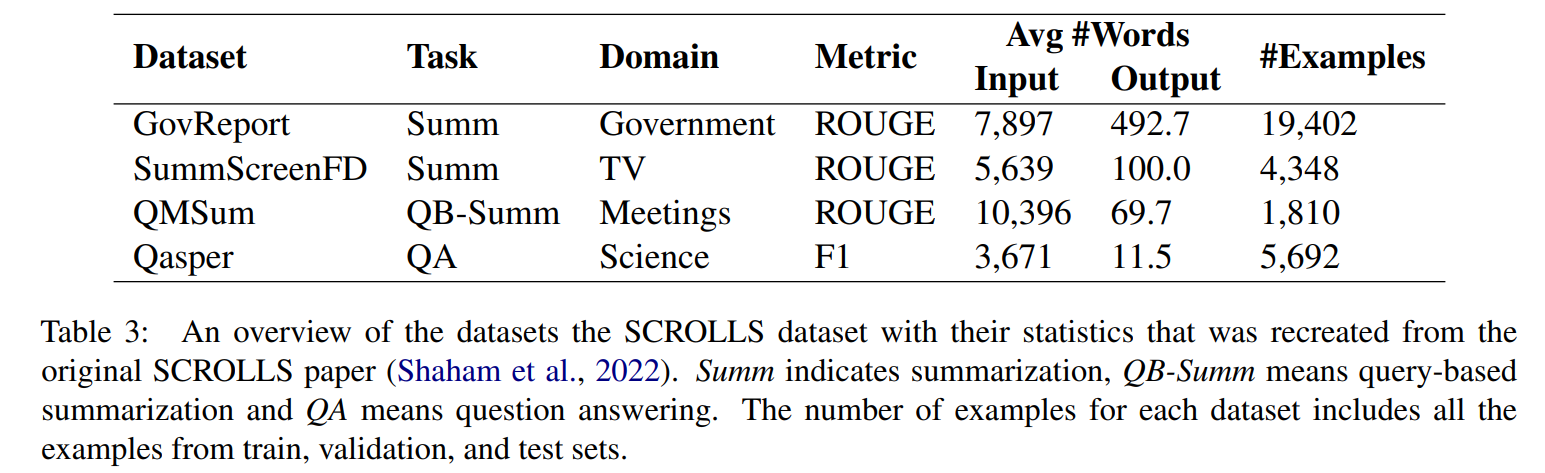
우리는 SCROLLS 벤치마크에서 4개의 데이터셋에 대한 분석을 실행 : GovRepert, SummScreenFD, QM-Sum, Qasper.
이러한 데이터셋은 2개의 태스크를 포괄한다 : 요약과 QA.
- GovReport : U.S. Government Accountability Office(GAO) and Congressional Research Service(CRS)에서 출간된 보고서로 구성된 요약 데이터셋
- SummScreenFD : 에피소드의 스크립트가 주어졌을 때, TV 에피소드의 요약을 생성하는 것을 목표로 하는 요약 데이터셋
- QMSum : 다양한 학술 미팅, 산업 제품 미팅, 공공 정책 미팅과 같은 다양한 회의록으로 구성된 query기반 요약 데이터셋
- Qasper : SCORC(Semantic Scholar Open Research Corpus)에서의 NLP 논문에 대한 QA데이터셋. 논문의 제목과 초록이 주어졌을 때, 모델이 논문에 대한 질문에 답을 생성할 수 있어야 함.
이러한 데이터셋에 대한 요약과 세부 내역을 Table 1과 Appendix A에 있음.
3.2 Models
pre-trained model로 시작에서 시작해, fine-tuning과 inference로 실험을 제한했다. 우리의 태스크가 sequence-to-sequence format을 채택하기 때문에, 긴 길이의 NLP에 대해 널리 사용되는 2개의 encoder-decoder model를 선택했다 - Longformer-Encoder-Decoder(LED)와 Big Bird. 전형적인 사용 방법을 따라하기 위해, 우리는 HuggingFace library에서 2개의 사전 학습된 모델을 얻었다. - 그러므로 우리의 분석은 어느 HuggingFace model에 대해서도 쉽게 확장 될 수 있다.
Longformer-Encoder-Decoder(LED)
우리는 원래 논문에서 나온 LED의 base와 large버전 모두를 분석했다. LED model의 버전은 Longformer-chunks 구현을 활용한다. 이는 한 번의 행렬곱 연산만 필요하도록 키 및 쿼리 행렬을 chunk하여 더 높은 메모리 비용으로 높은 계산 효율성을 달성한다.
BigBird
원래 BigBird 논문에서의 encode-decoder setup을 따라, 우리는 PubMed 데이터셋(Pegasus-large에서 시작)에 대해 사전 학습된 BigBird-large버전을 활용했다. 우리는 오직 large viersion에 대해서만 실험을 실행했다.(base는 HuggingFace에 발매 안됐기 때문)
3.3 Hardware Resources Provisioned
LED-base 모델에 대한 초기 연구는 QA에선 높은 정확도를 얻기 위해 큰 배치 사이즈는 필수적이다, 하지만 요약은 그보다 덜하다는 것을 제안(Table 2).
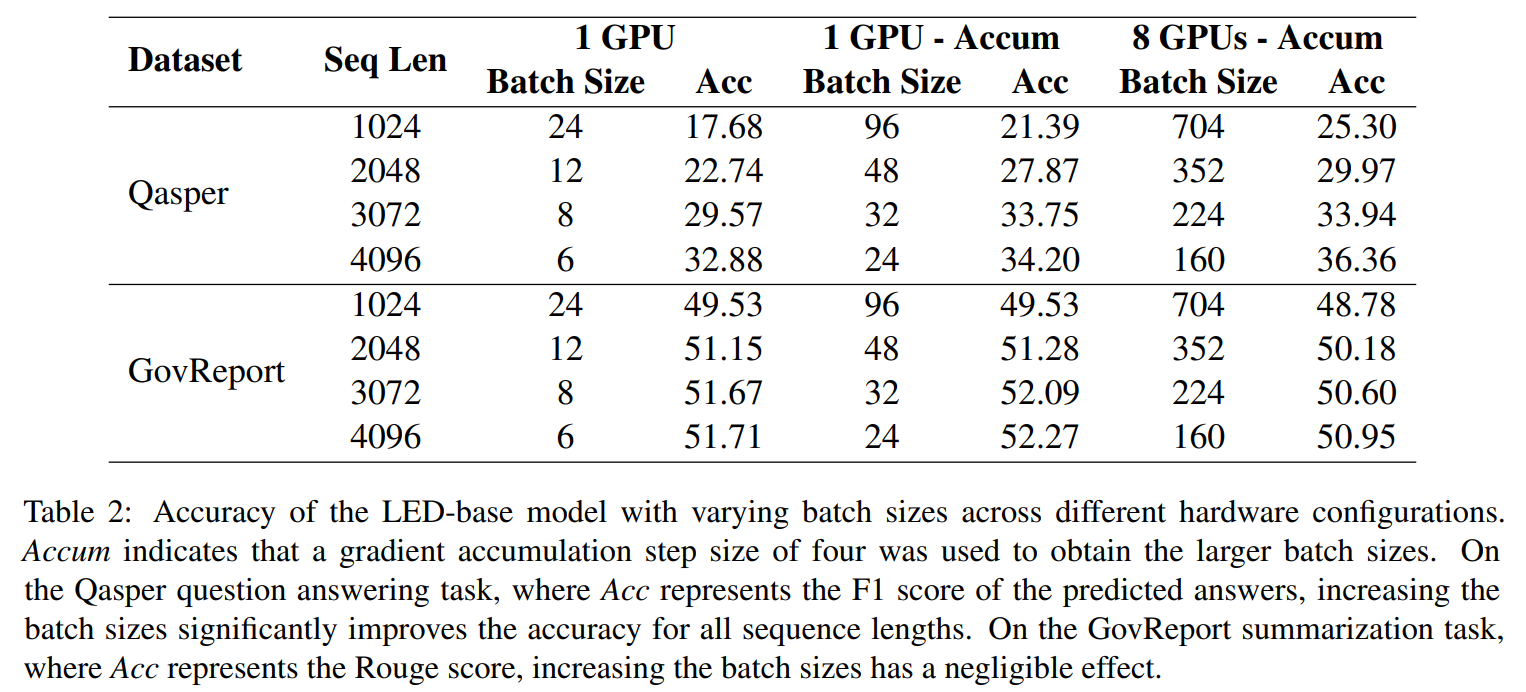
- Qasper(QA)에 대해 배치 사이즈를 x4 하는 것(gradient accumulation step size를 4로 함)은 입력 시퀀스 길이에 상관없이 2에서 4 point만큼 오름
- 입력 시퀀스 길이 1024를 예로 들면, 우리는 한 GPU에 24배치를 fitting할 수 있었다.(fine-tuning시 oom에 고통받지 않고, 17.68달성) - 배치 사이즈를 96으로 늘렸을 때, 모델의 정확도는 21.39로 증가
- 더 많은 GPU를 사용해 배치사이즈를 키웠을 때 F1 점수는 4에서 7%point 정도 증가
- 같은 트렌드가 Qasper dataset에 대해서 입력 길이에 관해서도 유지됨
- 배치사이즈를 4배씩 키우는 것은 GovReport 요약 데이터셋에선 무시할만한 Rouge scores점수를 만들었다(GPU 여러개 쓰는 것도 별 영향 없음).
이렇게 알려진 초기 실험에서 요약 태스크에 대해 fine-tuning과 inference하는 데에 GPU숫자가 accuracy에 긍정적인 영향을 끼치지 않다는 것을 바탕으로 Nvidia RTX A6000 GPU 1대로 자원을 고정하였다.
대신에, QA 태스크에서는 배치가 커질수록 모델 accuracy가 높아졌기 때문에, 8대의 Nvidia RTX A6000 GPU를 사용했다.
3.4 Fine-tuning
3.2에서 언급된 모든 사전 학습 모델들은 수렴할 때 까지 모든 데이터셋에 대해 mixed preicision 또는 gradient checkpointing없이 fine-tuned되었다.
- 한 모델은 accuracy가 같거나 3 validation call에 대해 더 나빠졌을 때 수렴했다.
- 우리는 요약의 경우 500 steps마다, QA의 경우 10 steps마다 validation을 수행했고, 모델은 지표가 계속 같거나 요약은 1500steps, QA는 30 step에 대해 나빠졌을 경우 수렴했다.
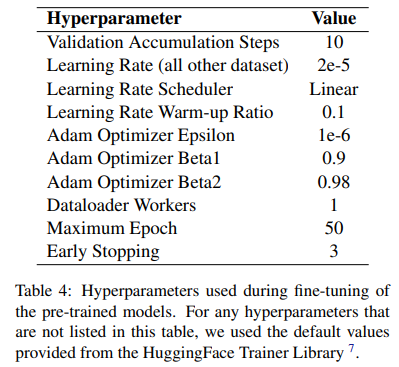
하이퍼파라미터 관점에서, 우리는 SCROLLS벤치마크에서 batch size를 제외한 LED-base model에 대해 같은 파라미터를 적용했다.
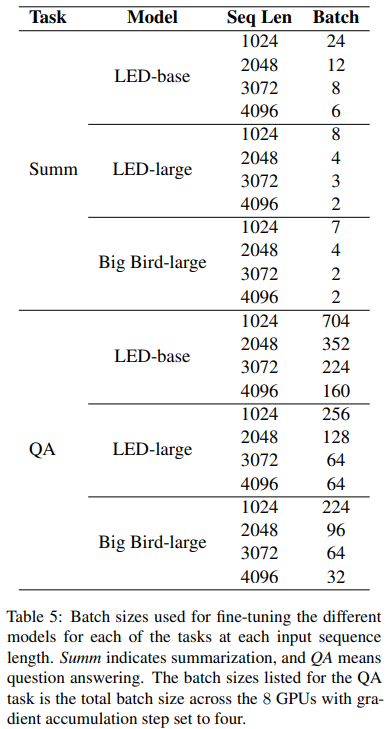
batch size에 대한 자세한 내용은 아래 표와 같다.
- 메모리로 인한 효과를 통제하기 위해, 48GB A6000 GPU에 fit할 수 있는 가장 큰 배치사이즈 선택.
- QA태스크에서, 그 배치 크기는 각각의 8GPUs가 최대화 되는 미니 배치를 보고 결정됨.
- QA에서 각각의 미니배치의 효율적인 크기를 더욱 늘리기 위해서, 우리는 4번마다 accumulation steps를 세팅함.
하이퍼파라미터에 대한 더 자세한 정보는 Appendix B에 기술되어 있다.
(배치를 다 다르게 하면 비교를 어떻게.. LED-large랑 BigBird-large는 배치가 같아야 비교가 되는게 아닌가? 라는 의문이 있음)
3.5 Inference
우리는 SCROLLS의 테스트셋에서 label을 사용하지 않았기 때문에, inference는 validation set에 대해서만 실행됬다. 모든 inference는 배치 크기를 16으로 두고 실행됨.
3.6 Evaluation Criteria
Accuracy
각 데이터셋에 대해 모델의 정확도에 대한 우리의 평가 지표는 SCROLLS 논문에서 언급된 것을 따른다.
- GovReport, Summ-ScreenFd, QMSum은 ROUGE를 사용
- Qasper은 predicted와 ground-truth answer strings에 대해 normalizing후 token-level의 F1 score를 사용
*SCROLLS에 따르면 ROUGE는 각 단일값으로 제공되는 다른 종류의 rouge(Rouge-1, Rouge-2, Rouge-L)를 기하 평균 냄.
Efficiency
각 효율성 지표에 대해서, 우리는 학습시
- 전력 효율성(number of samples trained per second per Watt)
- 전체 학습 에너지 요구량(average x training time)
- 학습 속도(number of samples trained per second)
- inference 속도(number of samples inferenced per second)
를 측정한다.
학습과 inference 속도는 HuggingFace 라이브러리에 의해, 전력 효율성과 전체 에너지 소비량은 Weights and Biases tool(wandb)에 의해 제공된다.
머신러닝 플랫폼에서 사용되는 중요한 산업 표준 지표중 하나이기 때문에, 우리는 전력 효율성을 우리의 지표중 하나로 선택했다. 클라우드 제공자들은 보통 40-50%의 비용을 전기 뿐만 아니라 서버를 powering and cooling하는데 사용하고, 이 비용은 더 늘어나고 있다. 그러므로, 전력 사용의 유용성을 최대화하는 것(watt당 처리되는 데이터의 수를 늘리는 것)은 NLP 연구에서 탄소 발자국을 줄이는데에 중요하다.
4 Results
4.1 Summarization Datasets
Figure 1은 각 요약 데이터셋 대 이에 상응하는 1024부터 4096까지의 입력 시퀀스 길이에 대한 학습 accuracy를 묘사하고 있다. 다음과 같은 관찰을 할 수 있다.
1. 전력 효율성은 입력 시퀀스 길이와 음의 상관관계를 가진다
2. BigBird-large는 LED-large와 유사한 전력 효율성을 보지만, BigBird의 rouge 점수가 훨씬 낮다.
==> 즉, 요약 태스크를 학습시킬 때 LED를 선택하는게 더 낫다.
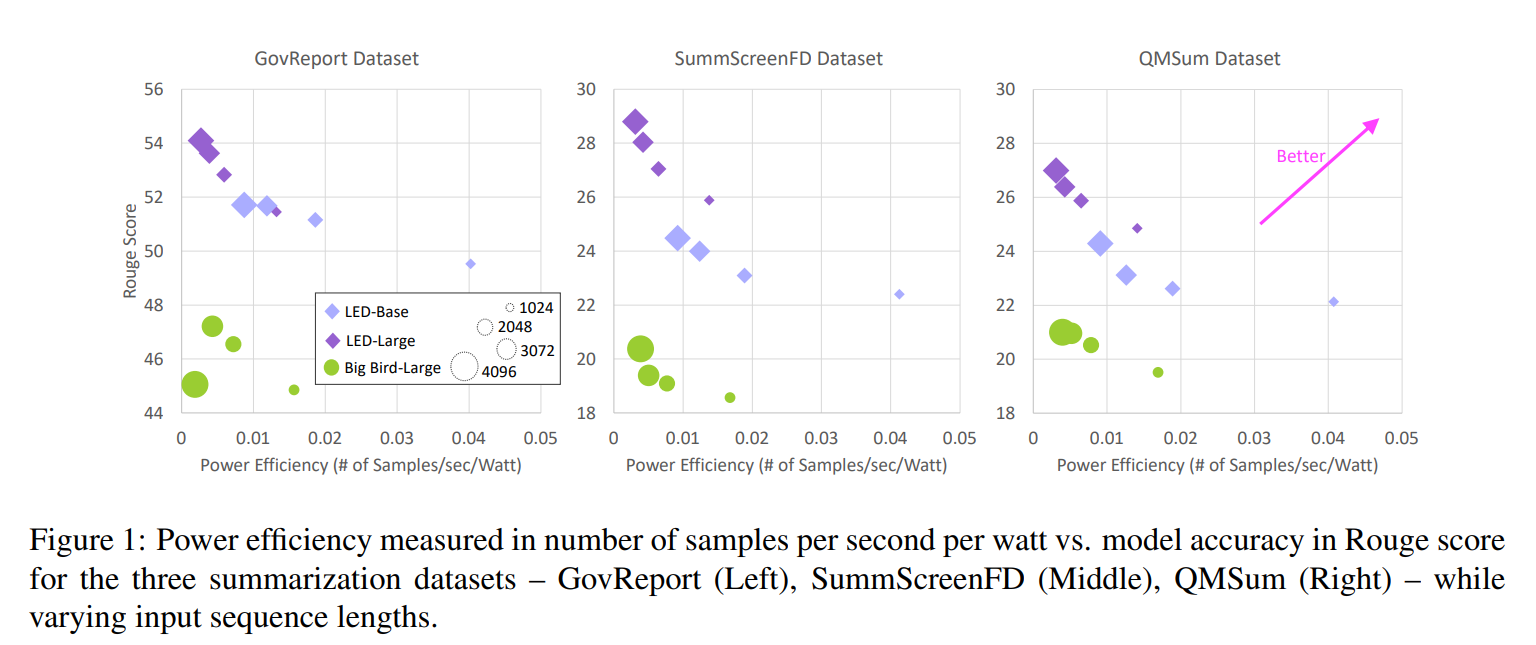
Figure2는 3가지 요약 데이터셋 각각을 학습하는데 드는 전체 에너지 소비량을 보여준다.
- GovRepert와 QMSum에 대해서 LED-large, input 1024가 더 긴 길이의 LED-base모델보다 더 효율적이고 높은 accuracy를 보임
- LED-large의 입력 시퀀스 길이를 늘리는 것은 정확도가 증가하고, 동시에 LED-base 모델의 길이를 늘리는 것보단 더 효율적
- 우리는 BigBird가 에너지는 더 사용하면서 rouge는 낮다는 것을 알 수 있었음.
요약에서 이는 짧은 길이를 가지는 더 큰 모델을 사용하는 것이 더 높은 정확도를 얻으면서 에너지 친화적인 방법이다.

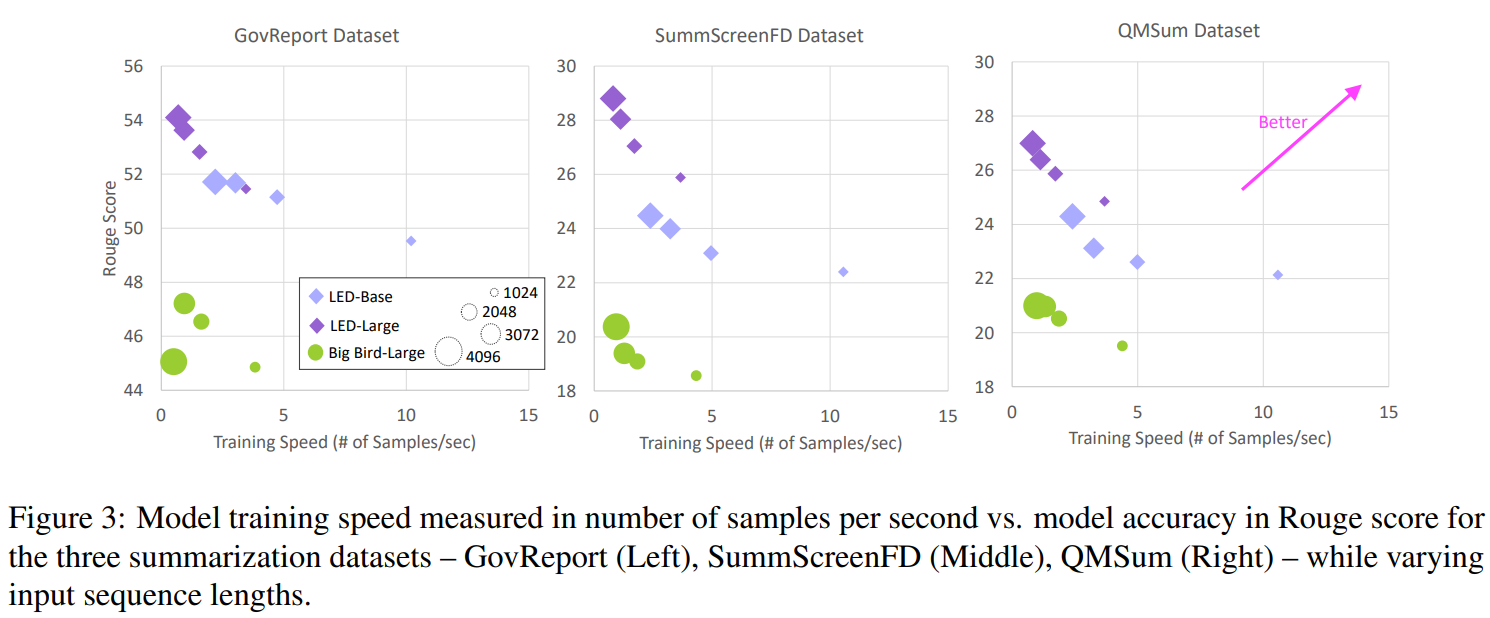
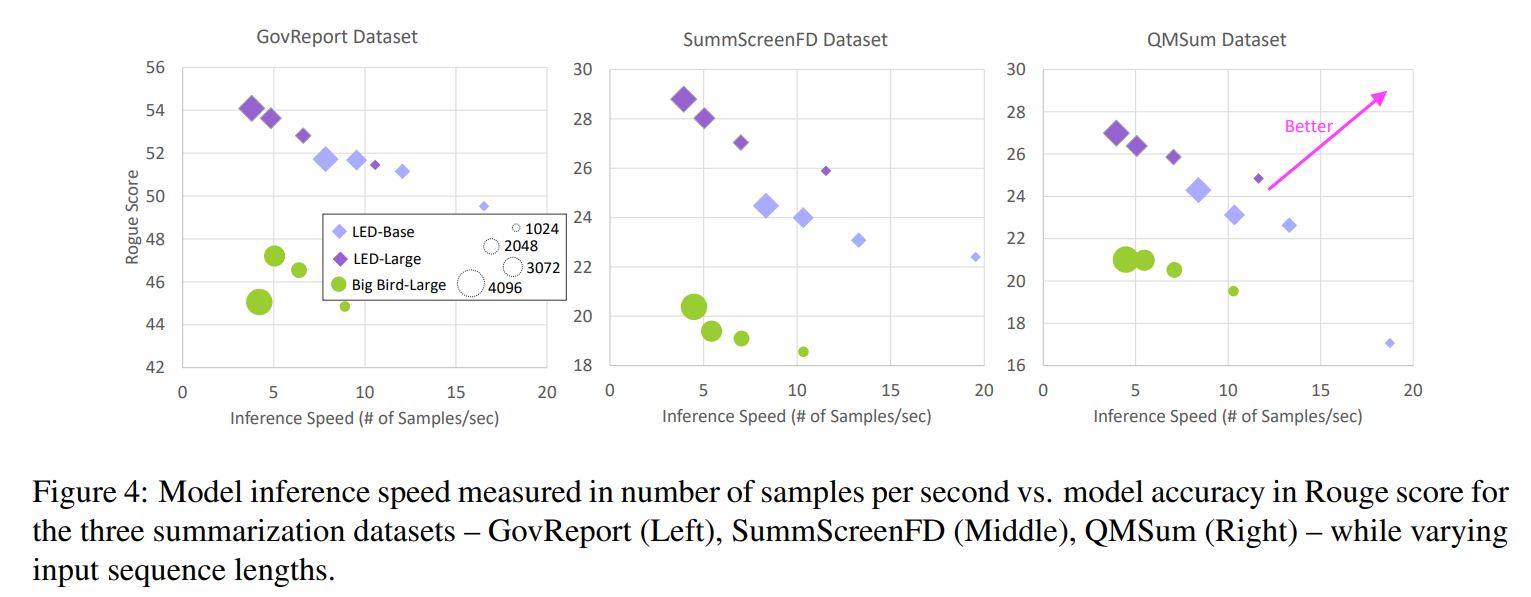
요약 데이터셋에 대한 학습 속도(Figure 3)과 inference 속도(Figure 4)는 유사한 경향을 보인다.
- 입력 시퀀스 길이가 늘어남에 따라, 이러한 효율적인 트랜스포머 모델에 사용된 attention mechanism에서 나타나는 sub-quadratic runtime complexity로 인해 학습 및 추론 속도가 감소한다.
- 학습 시 에너지와 달리, 추론 속도는 모델의 크기가 더 작을수록, 정확도가 낮아질수록 빨라진다. 그러나 종종 짧은 입력 길이(1024) + LED-large 보다 긴 입력 길이(2048) + LED-base모델이 유사한 정확도를 얻기도 한다.
4.2 Qasper Dataset and Scaling Up Resources
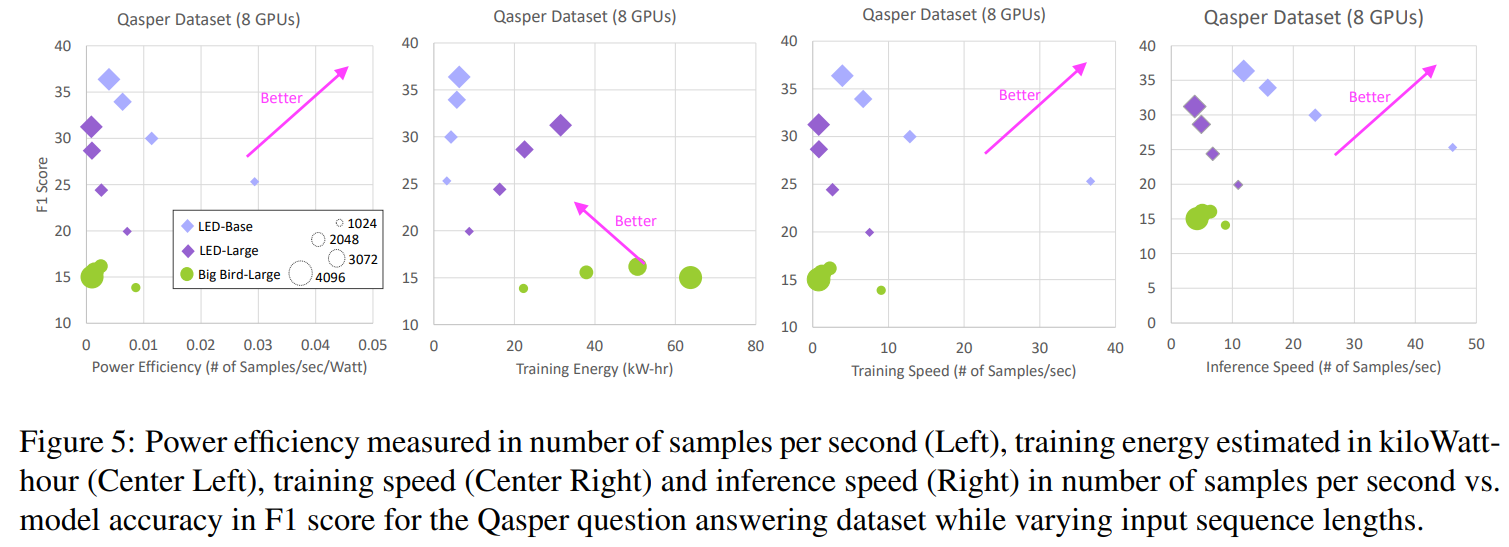
Figure 5는 Qasper QA task에 대해 4개의 효율성 지표를 보여준다.
- LED model이 BigBird보다 전반적으로 F1 score가 높음
- 한정된 적은 자원에서, LED-base가 LED-large보다 더 뛰어남(배치 크기 때문인걸로 추정)
즉, 이 태스크에선 작은 모델을 사용하는 것이 효율적이고 더 정확하다!
입력 시퀀스 길이를 늘리는 것은 정확도에서는 작은 증가를 가져왔지만, 학습 에너지에선 많은 비용을, 속도 측면에서도 훨씬 느려지는 단점을 보였다.
4.3 Energy Consumption Deep Dive
하드웨어 플랫폼의 에너지 소비를 이해하기 위해, 우리는 GovReport 데이터셋에 대한 더 깊은 분석을 제시한다. 우리는 GPU 활용 정도(average over the entire training run), GPU 메모리 사용(average over the entire training run), 그리고 학습 시간(in seconds)를 Figure 6에 그래프로 표현했다.
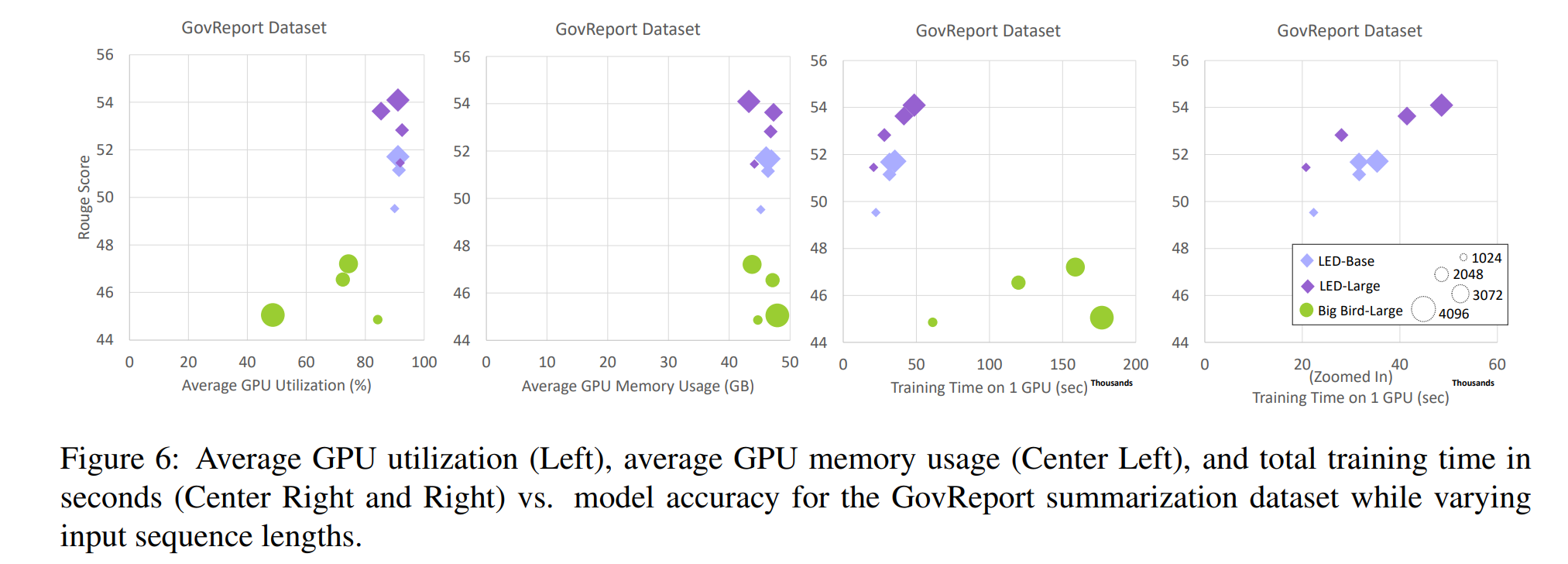
- GPU 활용 정도는 LED모델이 높음
- BigBird의 경우 input sequence가 4096일 때 GPU 활용 정도가 가장 낮음
==> GPU 활용 정도가 낮아서 에너지 비용 자체는 낮지만, 학습하는데 시간이 매우 오래 걸림(4096, large기준 LED보다 거의 4배 차이가 남) - 일반적으로 GPU에 대한 학습 시간은 전체 에너지 소비와 유사한 경향을 보임
5 Conclusion
우리는 accuracy vs efficiency trade-off에 대한 구조적인 연구를 제시했다. NLP 벤치마크에서 흔하게 사용되는 모델 구조들을 비교했고, 우리는 4개의 다른 시퀀스 길이와 2개의 모델 크기에 따라 모델을 비교하는데 초점을 두었다. 우리는 실무자들이 제한된 자원 환경에서 하이퍼파라미터를 선택하는데 활용될 수 있기 희망하면서 몇가지 키포인트를 강조했다.
- 긴 길이를 갖는 것보다 큰 모델을 사용하는데 에너지 효율도 좋고 요약 태스크에서 정확도도 높다.(추론 속도는 관심사가 아닐 때)
- QA에선 작은 모델에 긴 길이의 시퀀스를 활용하는 것이 더 높은 효율과 정확도를 보였다.
