Extractive summarization as Text Matching (MatchSum)
0. Abstract
기존 Extractive Summarization은 source document에서 독립적으로 문장을 추출하고 문장들 사이의 관계를 모델링하는 방향으로 이루어져 왔습니다. 본 논문에서는 이러한 기존의 framework를 사용하지 않고 summarization task를 semantic text matching 문제로 다시 정의하며, source document와 candidate summary들이 semantic space 상에서 굉장히 유사한 위치에 있어야 한다고 주장합니다.
1. Introduction
본 논문에서는 일반적으로 의미론적 및 문법적으로 올바른 문장을 생성하고 계산 속도가 더 빠른 extractive summarization에 초점을 맞췄습니다. 현재 대부분의 extractive summarization은 soruce document에서 문장을 하나하나 점수화해서 추출하고, 문장들 사이의 관계를 모델링한 다음, 전체 document에서 몇 개의 문장을 선택하여 요약을 추출하고 있습니다.
- Related Work
(2016~2017) Sequence labeling problem encoder-decoder frame work
→ Sequence labeling problem으로 정의 (encoder와 decoder가 존재해서 2가지가 상호작용하면서 문장을 뽑아내는 식으로 만들어짐)
→ 각 문장에 대해서 독립적인 binary decision을 진행하기 때문에 중복이 많이 발생
(2018) Auto regresseive decoder 도입
→ 문장을 점수화하여 서로 다른 문장들의 점수가 각 문장들에게 영향을 미치게 함(상호관계를 가지면서 학습이 됨) & 중복 문제 조금 해결
(2017,2019) Trigram blocking
→ 이전에 선택한 문장과 중복이 되는 경우, 문장을 건너뛰어서 요약문을 추출 & 중복 문제 해결
(2018,2019) Reinforcement learning
→ 강화학습을 통해 문장 요약을 해내고, 요약하는 과정을 하나의 리워드로 취급해서 좋은 요약문을 뽑아내는 과정
⇒ 기존의 모델들은 sentence-level에서 수행되는 extractor의 역할을 했었기 때문에 summary 문장들은 서로 semantic한 relation을 고려하지 못한다는 문제점을 가지고 있었습니다. (전체 요약문의 semantic을 고려한 것이라 보긴 어려움)
- MatchSum Framework
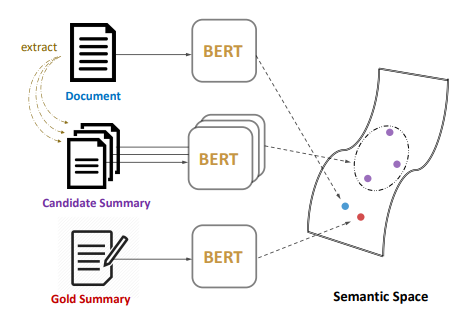
MatchSum의 Framework를 살펴보면, 3가지 요소가 존재합니다. document가 존재하고, 이 document로부터 candidate summary가 존재하며, gold summary가 존재합니다. 결국 Semantic text matching을 통해서 summary level의 framework를 만들어내고, 이 3가지가 semantic space 상에서 굉장히 유사한 위치에 있어야 한다는 것이 이 논문의 목적입니다.
2. Related Work
2.1 Extractive Summarization
MatchSum은 Extractive Summarization을 목적으로 하는 문서 요약 모델이며, BERT 모델을 기반으로 발전된 Extractive summarization 모델 2가지를 살펴보도록 하겠습니다.
1) Bert-ext (Bae et al., 2019)
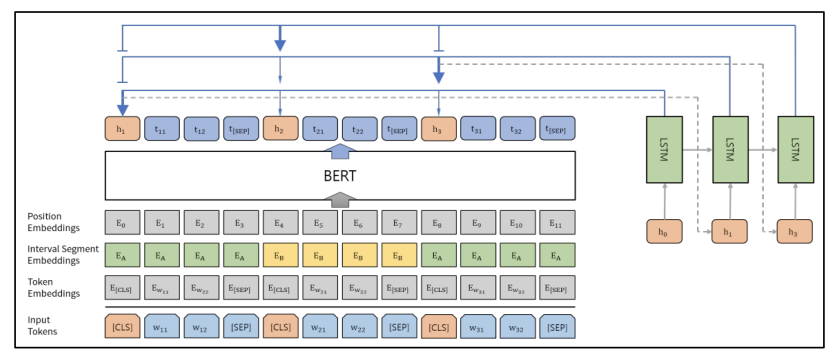
먼저 기존 BERT와 다른 점을 살펴보면, 기존 BERT에서는 첫번째 문장의 시작 부분에만 [CLS] 토큰을 추가했지만 요약 task에서는 BERT 모델에 여러 문장을 입력하고 입력한 모든 문장에 대한 표현이 필요합니다. 따라서 모든 문장의 시작 부분에 [CLS] 토큰을 추가하고 [CLS] 토큰 위치의 출력 벡터는 해당 문장의 feature를 함축하게 됩니다. BERT-ext는 BERT를 통과한 다음에 나오는 [CLS] 토큰에 해당하는 벡터들을 LSTM에 넣어서 sequence를 고려한 후 요약을 진행합니다.
2) BERTSum (Y Liu et al., 2019)
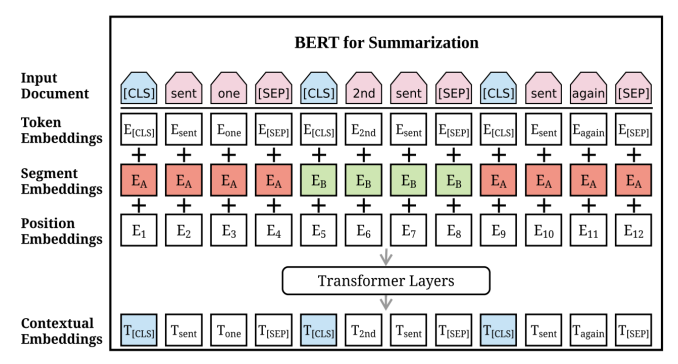
BERTSum도 마찬가지로 [CLS], [SEP] 토큰을 각 문장마다 사용하는 형태를 가지고 있으며 BERT-ext와 다른 점은 LSTM을 통과하는 것이 아니라, 마지막 벡터들이 transformer layer를 한번 더 거친다는 것입니다. 여기서 사용하는 transformer layer는 encoder만 있는 2개의 레이어를 의미하고, 이 레이어를 거친 다음에 [CLS] 토큰이 binary classification을 통해서 summarization으로 선택이 될지 안될지를 판단하는 방식으로 진행됩니다.
2.2 Two-stage Summarization
JECS (Joint Extractive and Compressive Summarizers, Xu et al., 2019)
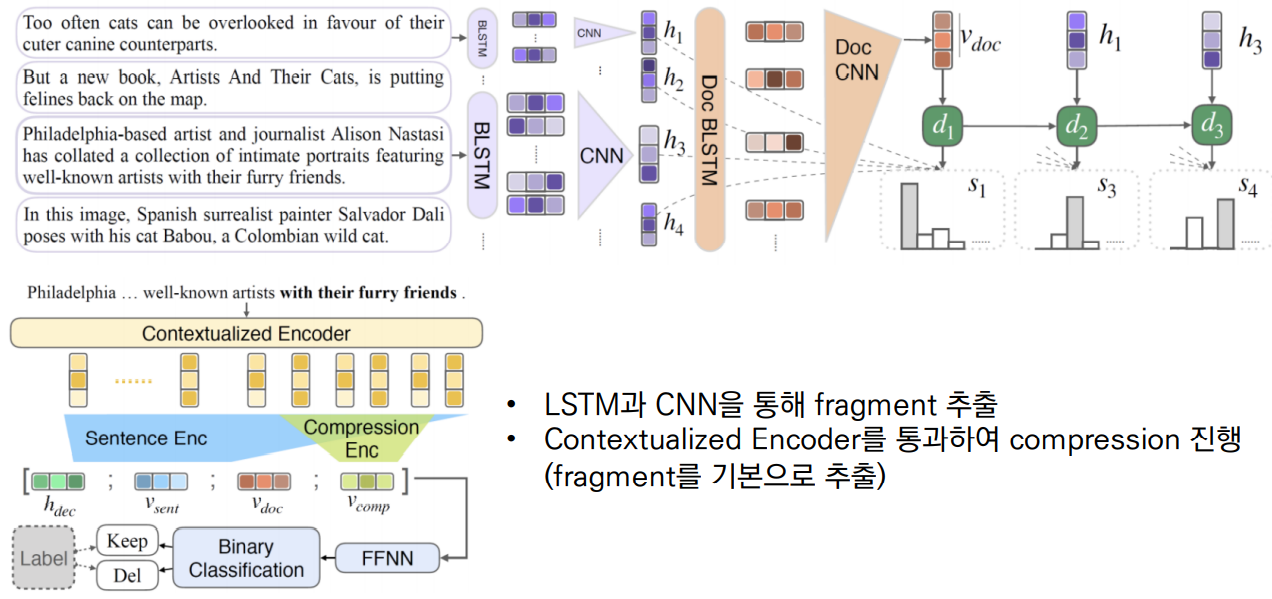
MatchSum에서는 기존 모델들과는 다르게 Two-stage summarization을 진행합니다.
- stage-1 : document로부터 candidate가 될 수 있는 summary를 추출
- stage-2 : 추출한 문장들 사이에 matching을 진행하는 과정을 거침
JECS는 LSTM과 CNN을 통해 document로부터 fragment들을 추출하고 Contextualized encoder를 통해서 compression을 진행한 다음, fragment를 기본으로 문장을 추출하는 방식으로 진행됩니다.
3. Sentence-Level or Summary-Level? A Dataset-dependent Analysis
본 논문에서 저자가 던지는 2가지의 질문은 다음과 같습니다.
1. Extractive Summarization에서 summary level extractor가 sentence level extractor보다 우수한가?
2. 데이터셋이 주어지면 데이터의 특성을 기반으로 어떤 extractor를 선정해야하고, 두 extractor 사이의 inherent gap은 무엇인가?
본 논문에서는 해당 질문들을 바탕으로 6개의 benchmark dataset에 대한 sentence level과 summary level method 간의 차이를 조사했습니다.
3.1 Definition
본 논문에서는 첫번째 질문인 “Extractive Summarization에서 summary level extractor가 sentence level extractor보다 우수한가?”에 대해 정량적으로 판단하기 위해 몇 가지 정의를 내립니다.
→ n개의 sentence으로 구성된 single document
→ document에서 추출한 k개의 sentence를 포함하는 candidate summary
→ document의 gold summary
: C(gold summary)가 있는 document D가 주어졌을 때, C와 C 사이의 ROUGE 값을 2가지 수준(sentence-level/summary-level)으로 계산하여 C를 측정합니다.
1) Sentence-Level Score
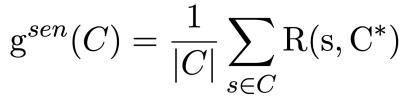
→ C에 포함되어 있는 sentence
→ sentence의 수
⇒ sentence level score는 candidate summary(C)안에 있는 어떤 sentence(s)가 실제 gold summary(C*)와의 ROUGE score를 구했을 때, 이 값이 얼마 정도되느냐에 대한 것으로, 여러 개의 candidate summary가 존재할 때 이 candidate summary의 평균적인 score를 sentence level의 score로 이해할 수 있습니다.
2) Summary-Level Score
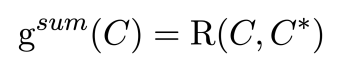
⇒ candidate summary(C)와 gold summary(C*) 사이의 ROUGE score를 구해서 정의합니다.
- Pearl-Summary
기존에는 summary level로 판단하지 않고 sentence level로 어떤 summary를 만들어내는 과정을 거쳤는데, summary level(MatchSum 초점)에 대한 것을 설명하기 위해서 저자가 새로 제안하는 것이 pearl-summary입니다. Pearl-Summary는 sentence level score는 낮지만 summary level score는 높은 summary로 정의합니다.
- Definition 1
Candidate Summary C는 다음과 같은 부등식을 만족하는 Candidate Summary C’가 존재한다면, Pearl-Summary로 정의됩니다.
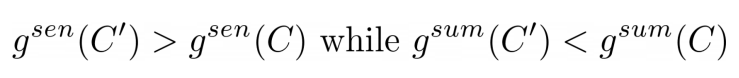
→ C가 C’에 비해 setence level score는 작지만, summary level score보다는 크다는 것을 의미하는 부등식
→ 따라서 어떤 document로 부터 몇가지의 sentence를 추출한 후, 추출한 문장들이 sentence level score는 조금 낮지만 summary level score로 판단했을 때는 조금 더 높은 점수를 가지면 Pearl-Summary로 정의합니다.
→ Pearl-Summary의 경우, sentence level extractor가 이를 추출하기는 어렵습니다.
-
Best-Summary
Best-Summary는 모든 candidate summary 중에서 가장 summary level score가 높은 summary를 의미합니다.
-
Definition 2
Summary 는 다음을 만족할 경우, Best-Summary로 정의됩니다.
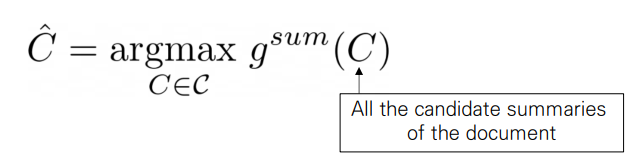
→ document의 모든 candiate summary인 C의 summary level score의 argmax값인 Summary 을 Best-Summary로 정의합니다.
3.2 Ranking of Best-Summary
각 document에 대해 모든 candidate summary들을 sentence level score를 기준으로 내림차순 정렬 한 다음, Best-Summary 의 순위를 z라는 변수로 정의합니다.
1) if z = 1 (즉, Best-summary()의 순위가 1위일 때),
sentence-level extractor로 좋은 summary 추출이 가능하다는 것을 의미합니다.
2) if z > 1 (Best-Summary()의 순위가 낮을 때),
Best-summary가 Pearl-Summary임을 의미합니다.(sentence level score는 낮지만, summary level score는 높으니까)
→ z가 증가할수록, sentence level score가 best-summary보다 높은 candidate summary들을 더 많이 찾을 수 있으며, 이는 sentence level extractor 학습의 어려움으로 이어지게 됩니다.
⇒ 항상 pearl-summary가 좋다고 주장하는 것이 아닌, summarization에 대해 여러가지 benchmark 데이터셋이 존재하는데 이 데이터셋의 특성에 따라 데이터의 속성이 달라진다고 주장하고 어떤 extractor가 효과적인지 상이하다고 주장한 점이 추출 요약의 새로운 방향을 제시했다고 생각합니다.
- 본 논문에서는 6가지 benchmark dataset으로 실험을 진행했습니다.
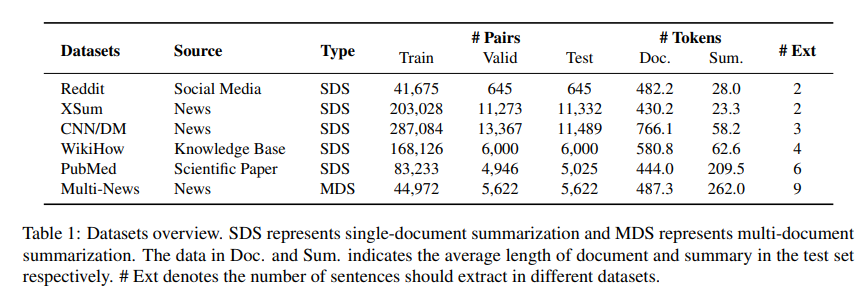
SDS : single-document summarization / MDS : multi-document summarization
Doc. : test dataset의 평균 문서 길이 / Sum. : test dataset의 평균 요약 길이
#Ext : 서로 다른 데이터셋에서 추출해야하는 문장의 수
- 앞에서 정의한 식을 기반으로 score를 매기고 데이터셋에 적용했을 때, 그래프로 확인할 수 있습니다.
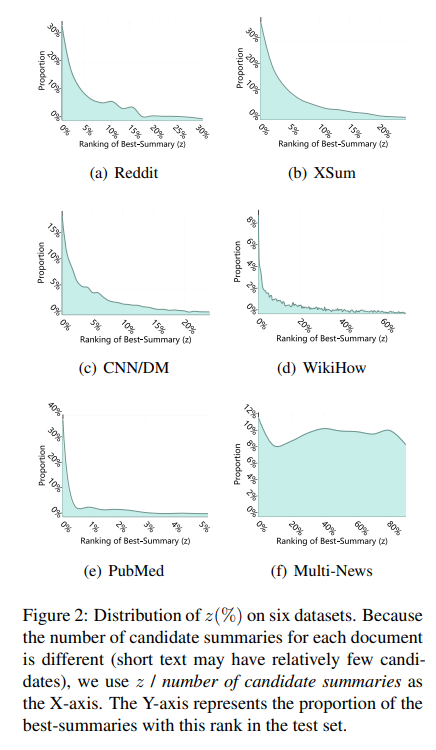
그래프의 x축은 z(best summary ranking) / candidate summary의 개수, y축은 best-summary의 비율입니다. 위 그래프는, sentence score가 높은 요약문이라고 반드시 best summary는 아님을 보여줍니다. 즉, 우리가 그동안 정의내려왔던 것보다 이 논문에서 제시하는 pearl-summary인 경우가 조금 더 많을 수 있다는 점을 시사하고 있습니다.
- z=1 위치는 sentence score가 가장 높은 지점 (요약문 후보를 sentence level score로 정렬)
- z>1 은 pearl summary가 best summary인 지점들을 의미
PubMed는 Best Summary가 sentence-level scoring에 따른 순위 상위권에 밀집해 있으며,이는 sentence-level로도 충분히 성능을 보일 수 있음을 의미합니다. 반면에, WikiHow와 Multi-News는 Best Summary 분포를 보았을 때, sentence-level extraction으로는 Best Summary를 추출하기 어렵다는 것을 알 수 있었습니다. 특히, summarization task에서 가장 많이 사용하는 CNN/DM 같은 경우는 18.9%만 z=1인 상황에 속했습니다. 즉, 거의 대부분이 pearl-summary가 best summary인 경우가 많았다는 것을 의미합니다. 이를 통해 pearl summary의 비율이 데이터를 나타낼 수 있는 속성으로 사용될 수 있음을 시사합니다.
정리하면, 기존에 없었던 pearl-summary라는 개념을 제시함으로써 데이터셋 자체의 속성을 파악할 수 있는 지표로 사용할 수 있게 되었고, 앞으로 summarization task에 어떠한 extractor를 적용해야하는지를 명확히 시사할 수 있다고 생각할 수 있을 것 같습니다.
3.3 Inherent Gap between Sentence-Level and Summary-Level Extractors
Inherent gap은 2번째 질문인 “데이터셋이 주어지면 데이터의 특성을 기반으로 어떤 extractor를 선정해야하고, 두 extractor 사이의 inherent gap은 무엇인가?” 에 대한 대답이 될 수 있습니다.
“ Inherent Gap”은 sentence level과 summary level의 정량적인 개선 정도를 정의한 개념으로 정의됩니다. 저자가 첫번째 질문에 대한 답으로 대부분의 데이터셋은 summary level로 판단하는 것이 조금 더 옳다고 했는데 이 주장을 뒷받침하기 위해서는 어느 정도의 gain이 있는가를 알아봐야 합니다. 따라서 potential gain을 정의하고, 이 potential gain에 따라서 어떤 extractor가 적합한지를 판단할 수 있습니다.
1) Document 단위로 inherent gap 정의
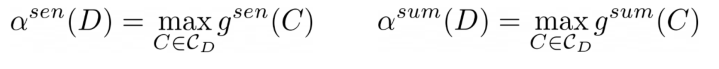
: sentence level score의 max값을 의미
: summary level score의 max값을 의미
2) Document 단위의 potential gain 정의
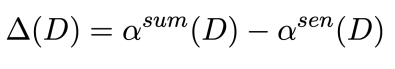
: summary level에서 나온 에서 을 뺀 값(차이)으로 정의 → document에서 개선될 수 있는 gain을 의미
3) Dataset 단위의 potential gain 정의
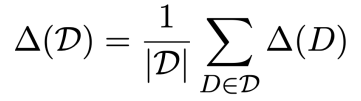
D : 특정 데이터셋 / |D| : 데이터셋의 document 수
: 데이터셋은 여러개의 document로 구성되어 있으므로 모든 document를 합친 후에 document의 개수로 나누도록 정의
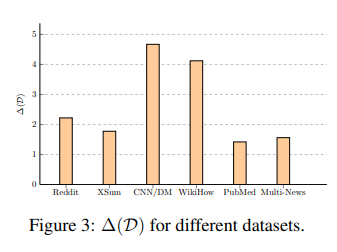
summary level method의 performance gain은 데이터셋마다 다르며, CNN/DM에서 최대 4.7로 향상되었음을 알 수 있습니다. 또한 figure3과 table1을 통해 performance gain이 reference summary의 길이와 연관되어 있음을 알 수 있습니다.
짧은 요약(Reddit & XSum)의 경우, pearl-summary의 완전한 식별이 큰 개선으로 이어지지 않고 긴 요약(PubMed & Multi-News)의 경우, 여러 문장은 이미 semantic overlap의 정도가 커서 summary level method로 인한 개선은 상대적으로 적습니다. 하지만 중간 길이의 요약(CNN/DM & WikiHow)의 경우, performance gain이 큰 것을 통해 summary level 학습이 의미있음을 확인할 수 있습니다.
MatchSum의 Framework를 정리하면, source doument, candidate summary, gold summary가 존재할 때, pearl-summary라는 개념을 새로 도입해서 이것들을 어떻게 정량적으로 판단할 수 있는지에 대해서 알 수 있었습니다. 이렇게 나온 값들이 semantic space 상에서 matching되어야 한다고 주장하는데 이제 summarization as matching에 대해 살펴보도록 하겠습니다.
4. Summarization as Matching
본 논문에서는 extractive summarization task를 semanctic text matching 문제로 정의하며, 여기서 source doument와 이로 부터 추출된 candidate summary는 semantic space에서 matching 되어야 합니다. 다음 섹션에서는 siamese based architecture를 사용하여 제안된 matching summarization framework에 대해 살펴보도록 하겠습니다.
4.1 Siamese-BERT
본 논문에서는 matching을 진행하기 위해 BERT를 여러개 사용하고 있습니다. matching을 정확히 하기 위해서 siamese BERT라는 개념을 도입합니다.
- Siamese network
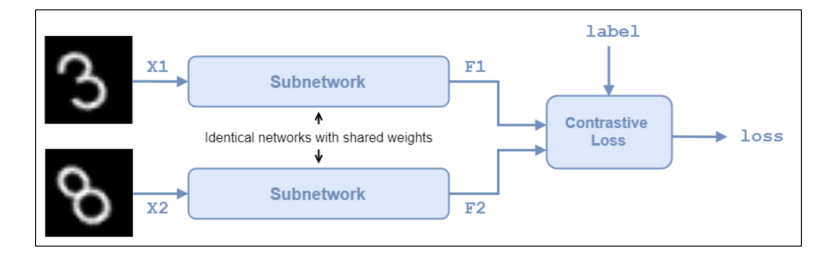
서로 다른 input을 받아 Vectorization을 한 후, 벡터간의 유사도를 반환하는 네트워크로 샴 네트워크의 포인트 3가지로는 1) 서로 다른 input을 넣고, 2) weight를 공유하는 subnetwork를 거친 다음, 3) similarity를 최적할 수 있도록 학습하는 것입니다.
- Siamese-BERT
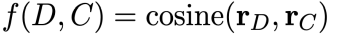
: document의 embedding / : candidate summary의 embedding
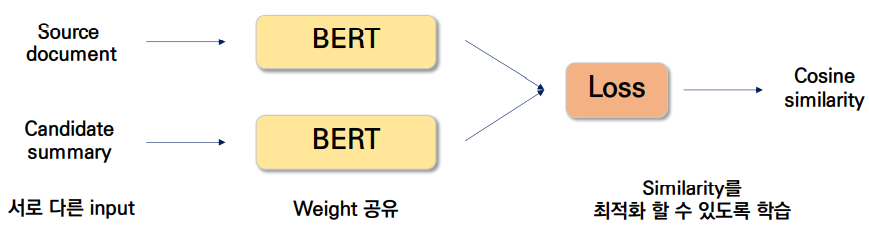
이 구조를 어떤 식으로 siamese-BERT라고 정의했는지 살펴보면, BERT-ext, BERTSum과는 다르게 sentence-level representation을 얻을 필요가 없기 때문에 original BERT를 이용해서 subnet을 구성하고, source document와 candidate summary 사이에서 의미론적으로 의미있는 embedding을 구합니다. 즉, source document가 가지는 의미는 결국 candidate summary가 가지는 의미와 유사해야한다는 것에서 출발한 개념입니다. 기존에는 source document는 input, gold summary는 target으로 teacher forcing하는 방식으로 진행되어 왔습니다. 하지만 본 논문에서는 좋은 summary를 만들어내는 것도 중요하지만, 결국 의미적으로 유사할 수 있는 summary를 가지고 오는 것도 매우 중요한 작업이기 때문에 제안한 네트워크 구조입니다. 이렇게 서로 다른 input에 source document와 candidate summary를 넣고, weight를 공유한 BERT를 지나, cosine similarity를 최적화할 수 있도록 학습을 진행하는 것입니다.
- Siamese-BERT : Loss function
1) Loss term 1 (margin-based triplet loss )
→ candidate summary (C) 와 document(D) 간 consine simarity, gold summary(C*) 와 (D) 간 cosine similarity 비교
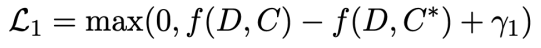
Loss function은 margin based triplet loss를 활용하여 학습을 진행했습니다. triplet loss는 어떤 클래스가 같은 것과 클래스가 다른 데이터가 존재할 때, 클래스가 같은 것은 더 가까운 위치에, 클래스가 먼 것은 멀리 있는 위치에 학습시킬 수 있도록 고안된 loss 입니다. 여기서 triplet loss에 초점을 맞춰서 summarization으로 본다면, 직관적으로 생각했을 때 gold summary는 source document와 의미적으로 가장 가까워야한다는 것을 의미합니다.
2) Loss term 2 (pairwise margin loss)
→ 각 candidate summary와 gold summary의 ROUGE score를 측정하여 정렬한 후, i번째 순위의 candidate summary *와 j* 번째 순위의 에 대해 candidate pair간 loss 측정
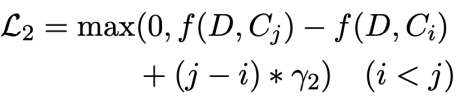
두번째 포인트로는 ROUGE score를 통해 내림차순으로 정렬한 candidate ranking이 큰 candidate summary의 margin이 크도록 학습하는 loss term 입니다. 여기서는 gold summary와 거리를 가깝게 하는 것이 아니라, candidate summary와 document를 가까운 위치에 오도록 하는 것입니다. gold summary에 따른 ranking gap (j−i)이 크고, 와 의 document similarity의 차가 클수록 loss 값이 증가합니다.
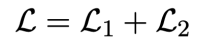
첫번째 loss와 두번째 loss를 더해서 최종 loss를 계산합니다. Loss의 기본 아이디어는 정답 요약문을 가장 높은 매칭 스코어를 가질 수 있게하고, 이와 동시에 후보 중에서 더 나은 후보가 있다면 상대적으로 더 좋은 스코어를 가질 수 있게 하는 것이다.
4.2 Candidates Pruning
Pruning은 데이터에서 가지치기를 한다는 의미인데, 대부분 summarization에서는 content selection을 이용해서 사용할 document에서 필요없는 부분을 제거하는 과정을 거칩니다. 본 논문에서는 BERTSum 모델을 사용해서 Candidates Pruning을 진행합니다.
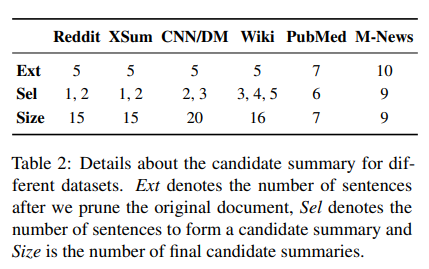
Ext : source document에서 pruning 진행 후 남은 문장의 수
Sel : candidate를 구성할 문장의 수
Size : candidate summary의 수
데이터셋에 적용해보면, Ext가 5개인 경우(Reddit, XSum)에 selection하는 것이 2가지 케이스로 나뉘어질 수 있습니다. 사이즈를 구하는 것은 5C1과 5C2를 더하는 케이스라고 보면 됩니다.
5. Experiment
5.1 Datasets
본 논문에서는 6가지 benchmark dataset으로 실험을 진행했습니다.
1) CNN/DailyMail : 뉴스 기사 및 관련 하이라이트를 요약으로 포함
2) PubMed : scientific papers에서 수집되었으며 긴 문서로 구성됨
3) WikiHow : 온라인 지식 베이스로부터 추출된 다양한 문서
4) XSum : “What is the article about?”라는 질문에 답하기 위한 한 문장 요약 데이터셋
5) Multi-News : 비교적 긴 요약을 가진 다중 문서 뉴스 요약 데이터셋
6) Reddit : 소셜 미디어 플랫폼에서 수집된 매우 abstractive한 데이터셋
5.2 Implementation Details
- Adam Optimizer &
- batch size of 32, wm denotes warmup steps of 10,000, γ1 = 0 and γ2 = 0.01
- 본 논문에 나열된 모든 실험 결과는 three run의 평균
- CNN/DM에서 siamese-BERT 모델을 얻기 위해 use 8 TeslaV100-16G GPUs for about 30 hours of training
- 데이터셋의 경우, 빈 문서 또는 요약이 있는 샘플을 제거하고 문서를 512개의 토큰으로 잘라냄
5.3 Experimental Results
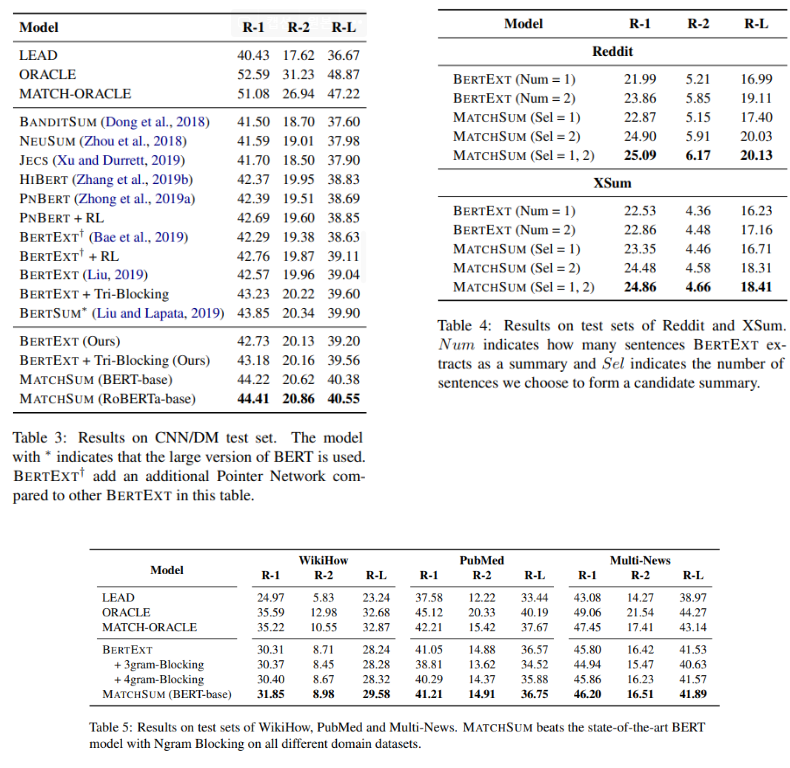
CNN/DM과 다른 Short summary, Long summary로 결과표를 구분해서 보여주고 있습니다. CNN/DM의 경우, BERT-EXT를 새로 구현하고 tri-blocking을 진행했을 때의 성능을 따로 체크했습니다. 이렇게 했음에도 불구하고 MatchSum이 훨씬 더 좋은 성능을 나타내는 것을 확인할 수 있습니다. 또한 base model을 RoBERTa로 사용한 경우, 더 좋은 성능을 나타내는 것을 확인할 수 있었고, RoBERTa가 6,300만 개의 뉴스 기사를 사용하여 pretrained 되었기 때문이라고 생각했습니다. ****short summary로 대표되는 Reddit, Xsum에서도 좋은 성능을 나타냈으며, long summary로 대표되는 PubMed, MultiNews에서도 좋은 성능을 나타내는 것을 확인할 수 있습니다.
5.4 Anlaysis
이 논문은 experiment 파트에서 anlaysis를 더 진행하는데, Ranking을 나타내는 변수인 z를 조절해서 BERT-EXT와 MatchSum의 성능을 비교합니다.
BERT-EXT에 대해 성능을 비교한 이유는 MatchSum이 나오기 전에 가장 좋은 성능을 기록한 모델이기 때문입니다. 성능의 기준은 ROUGE score의 차이로 볼 수 있고, pearl-summary가 best-summary인 경우에 MatchSum이 더 좋은 성능을 보였습니다. 여기서 MatchSum이 더 좋은 성능을 보였다는 것의 의미는 summary level의 summarization이 타당한 접근법이라는 것임을 의미합니다. z를 크게 하면 할수록 어느정도 ROUGE score가 증가하는 모습을 볼 수 있었습니다.

성능의 개선 정도를 식으로 나타내어 비교도 진행하였습니다.
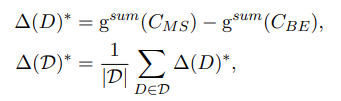
: document D에서 MatchSum에 의해 선택된 candidate summary
: document D에서 BERT-EXT에 의해 선택된 candidate summary
: 데이터셋 D의 BERT-EXT을 기준으로 MatchSum에 의한 개선 정도
sentence level과 summary level extractor 사이의 Inherent gap과 비교하여 MatchSum이 데이터셋 D에서 학습할 수 있는 비율을 다음과 같이 정의합니다.
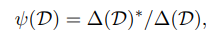
: sentence level과 summary level extractor 사이의 inherent gap
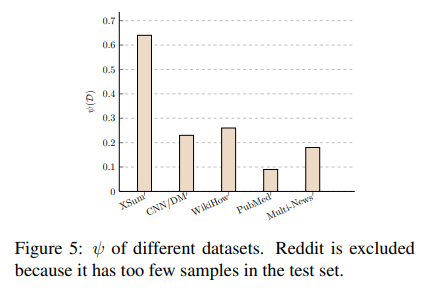
각 데이터셋의 MatchSum에 따른 성능의 개선 정도를 식으로 나타내어 비교도 진행하였는데 이 경우에도 높은 성능 변화가 있음을 확인할 수 있었습니다. PubMed와 Multi-News의 성능 개선 정도가 0.2 이하인 것을 보아, 길이가 긴 Summary에 대해서는 MatchSum의 성능이 크게 향상되지 않음을 알 수 있습니다. 이 중에서도 Multi-News가 PubMed 보다는 성능향상 정도가 높은데, 이는 Best Summary의 분포에 따른 것으로 볼 수 있습니다(요약 길이가 일정하고 고르게 분포되어 있을 때 모델이 더 잘 수행되는 경향 존재).
6. Conclusion
MatchSum은 기존의 문서 요약 모델 구조를 벗어나 새로운 구조를 제안한 모델로, 기존의 모델들이 sentence level extractor의 역할을 했었다면, MatchSum은 Semantic text maching을 도입하여 source document와 gold summary가 의미적 유사도를 가질 수 있도록 학습해야 한다는 목적을 가지고 있습니다. 또한 candidate summary를 기존 SOTA 모델인 BERTSum을 이용해 pruning하여 좋은 후보군을 생성했으며, Siamese-BERT를 제안하여 similarity를 학습할 수 있도록 모델을 구성했습니다. 데이터셋의 특성을 구분할 수 있는 지표를 제안하고 우리 모델이 어떻게 데이터의 특성에 더 잘 적합할 수 있는지를 보여주기 위해 분석을 수행했습니다. 마지막으로 6가지 benchmark dataset에 대해서도 좋은 성능을 기록했습니다.
7. References
https://www.youtube.com/watch?v=8E2Ia4Viu94
https://velog.io/@aqaqsubin/MatchSum-Extractive-Summarization-as-Text-Matching
https://aimaster.tistory.com/47
https://ryanong.co.uk/2020/06/08/day-160-nlp-papers-summary-extractive-summarization-as-text-matching/
