Improving Language Understanding by Generative Pre-Training (GPT1)
오늘은 Transformer가 고전논문 취급받는 요즘 (2017년에 나온 논문인데;; 최근에는 BERT가 너무 유명해서 BERT부터 사용하는 사람들이 많아 RNN계열을 잘 모르고도 쓰는 사람이 많은데, 이런 사람들에게 RNN관련 공부는 기본이라고 스스로 알아서 하는거라고 한다...) PLM 고전 3대장인 Transformer(Seq2Seq), BERT(AE), GPT(AR)중 GPT에 대해서 다루어보려고 한다.
'Transformer, BERT, GPT의 Embedding Indexing, (Mask) Self-Attention, Postition-wise FFN가 정확히 어떤 벡터연산으로 계산되는지 모르겠다면 Jay Alamar의 블로그를 참고해보자 "https://jalammar.github.io/". 필자도 처음에 저 블로그로 개념 잡는데 큰 도움이 되었다.'
논문 발표 순서는 Transformer > GPT1 > BERT 순서이지만 (Google이 BERT 내면서 GPT 엄청 까기 시작해서 2017-2019동안 새로운 SOTA PLM 나올때마다 서로 엄청 깠던거 갔은데..ㅎㅎ) 사실상 Transformer전에 나온 ELMO에서부터 본격적으로 쓰이기 시작한 contextual embedding이라는 개념을 이해해야 GPT의 도입부를 이해할 수 있다. GPT Introduction과 Related Work에서 계속 high-level semantic representation이라는 말을 하는데, 그냥 contextual embedding을 말하는 거다.
0. Contextual Embedding & Semi-supervised Learning : Pre-training to Fine-tuning
0.0 Contextual Embedding
ELMO는 'Deep contextualized word representations' 라는 논문에서 제안된 모델입니다. 얼마 되지 않아서 Transformer가 나와서 바로 쓸모없는 모델이 되는 비운을 가졌지만, ELMO에서 사실상 contextual-embedding의 개념이 처음으로 쓰이기 시작했습니다. 다음주 발표자가 자세히 설명해주겠지만, ELMO의 구조를 자세히 살펴보면 아래와 같습니다.
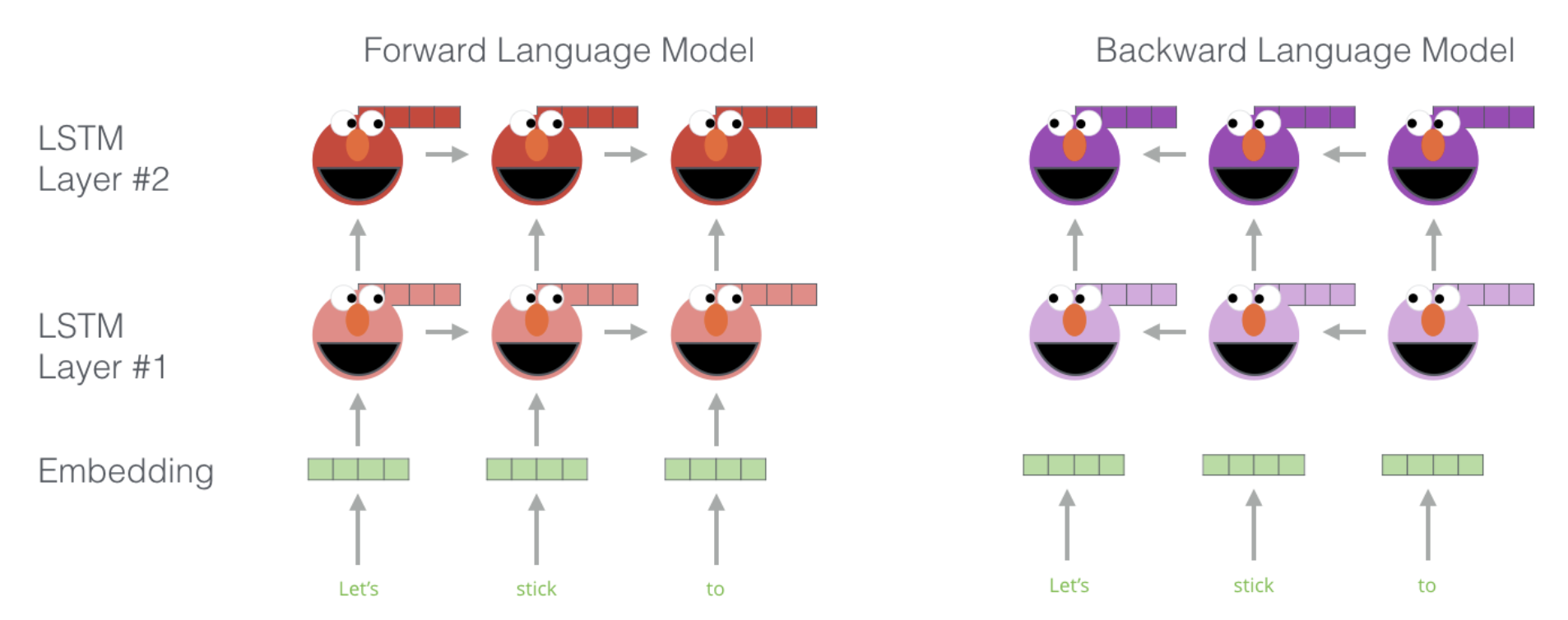
ELMO는 특정 문장에 여러개의 bi-directional LSTM을 쌓은 후 가장 상위 level의 LSTM hidden state를 쓰면 해당 단어의 맥략적인 의미를 반영할 수 있다고 하면서 해당 embedding(+각 layer)으로 다양한 NLP Task에서 성능이 향상됨을 보여주었습니다.
0.1 Semi-supervised Learning : Pre-training to Fine-tuning
또한 이쯤부터 많은 사람들이 NLP에서도 본격적으로 pre-training & fine-tuning이라는 개념을 활용하기 시작했습니다. 사실 이는 이미 Word-Embedding이 나온 이후부터 등장한 개념이기는 하나 이때는 pre-training, fine-tuning이라는 용어를 그렇게 자주 썼던거 같지는 않았던걸로 기억합니다. Word-Embedding에서의 pre-training은 embedding matrix를 unlabeled-data를 계속 순회하면서 학습하는 것을 의미하고 (unsupervised), fine-tuning은 훈련한 Embedding을 downstream-task(ex. classification, MT, Summarization,...)에 맞게 훈련해 해당 matrix를 따로 저장해서 동일한 task를 푸는데 활용할 때 사용했던 개념이었습니다.
반면, PLM(Pre-trained Model)에서의 pre-training과 fine-tuning은 아래의 그림을 통해 설명됩니다.
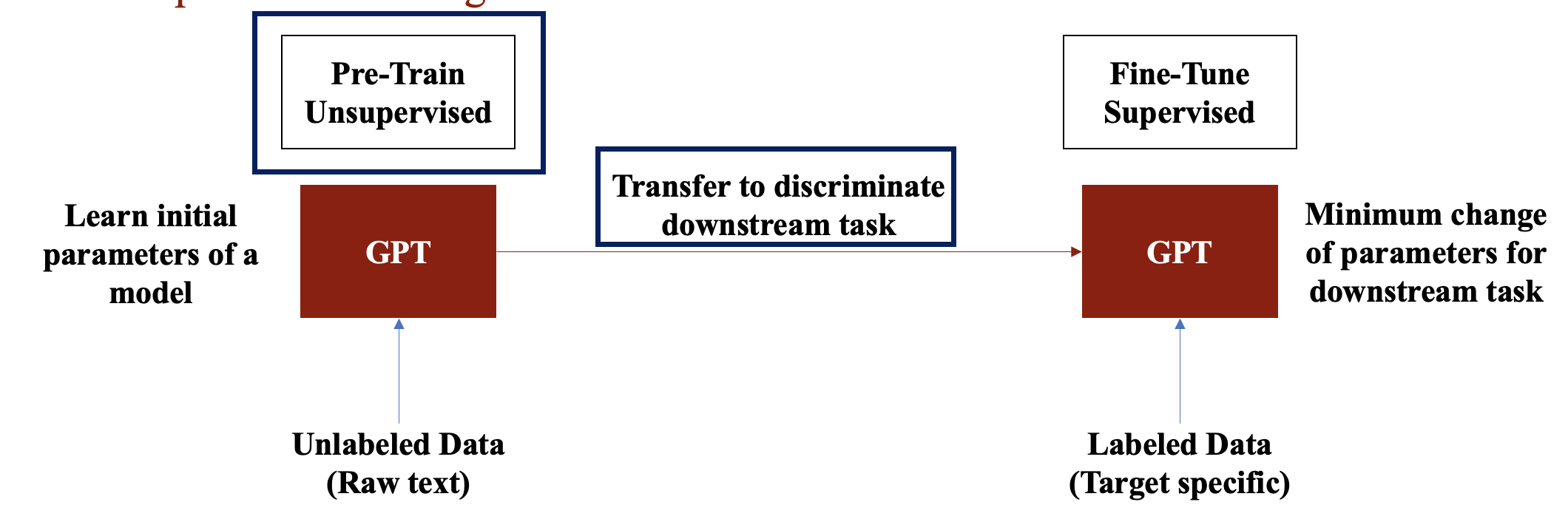
큰 모델(GPT)이 방대한 양의 Unlabeld Data(=Raw text)에 대해서 Pre-training을 통해 언어에 대한 맥락을 이해할 수 있도록 학습한 후에, 해당 모델을 Labeled Data로 Fine-Tuning해 Downstream Task를 푸는 전략이죠. 그렇다면 어떤 큰 모델이 좋은 모델일까? 저자들은 아래의 2가지 물음에 대한 대답을 통해 GPT를 제시합니다.
- 어떤 목적함수로 unsupervised learning을 진행하는게 좋은가? > LM-Based
- Fine-tuning Input으로는 어떻게 넣는게 가장 효과적인가? > 그냥 붙혀서 넣자
1. Introduction
Deep Learning으로 문제를 해결하려면 대량의 Labeled Data가 있어야 하는데, 이 부분이 현실적으로 제일 어려운 부분이죠. 따라서 Vision에 이에서 NLP에서도 unlabeled-data로 unsupervised learning을 해 어느정도 언어에 대한 일반화된 의미를 학습하도록 한 이후에, labled-data로 fine-tuning을 해서 downstream task에 대한 성능을 향상시키는 전략이 취해져 왔습니다. 하지만 이러한 전략은 대부분 word-embedding 단위에서 진행되었죠. 더 어려운 문제를 해결하기 위해서는 고도화된 embedding이 필요했지만 다음의 2가지 문제는 지속적으로 지적되어 왔습니다. 1. 어떤 목적함수로 unsupervised learning을 진행해야 supervised learning으로 tranfer시킬 때도 효과적인가? 2. Fine-tuning input으로는 어떻게 넣는게 가장 효과적인가? 1번 질문의 경우 'Deep contextualized word representations' 에서는 LM, ' Learned in translation: Contextualized word vectors' 에서는 MT로 목적함수를 두었습니다. 2번 질문의 경우 기존의 모델들은 복잡한 learning scheme를 쓰거나 'Semi-supervised multitask learning for sequence labeling' 에서 처럼 auxiliary learning objectives를 추가해 fine-tuning을 진행해왔습니다. 하지만 이렇게 task별로 구조를 다르게 하면 일반화된 semi-supervised learning 방법론을 제시하기에는 한계가 있죠.
서두에서 언급한것처럼 저자들은 2가지 질문에 대해서 다음과 같이 답합니다.
- Unsupervised learning시에 Language Modeling 목적함수를 활용하며 Transformer Decoder 구조를 차용한다.
- Fine tuning시에 여러 entity를 그냥 순서대로 넣는다. (ex. [Premise $ Hyphothesis] in entailment task)
다들 아시는 것처럼 GPT는 엄청한 performance boosting을 가져오면서 PLM시대의 서막을 알리죠. (8.9% on commonsense reasoning (Stories Cloze Test), 5.7% on question answering (RACE), 1.5% on textual entailment (MultiNLI) and 5.5% on the recently introduced GLUE multi-task benchmark.)
2. Related Work
2-1. Semi-supervised learning for NLP
GPT 이전에 많은 연구자들에 의해서 Word-embedding 기반의 semi-supervised learning(pre-training > fine-tuning)이 효과적임이 보여졌다고 합니다. 하지만 아직 해당 embedding은 word-level이라는 한계를 지적하죠.
2-2. Unsupervised Learning
unsupervised learning은 supervised learning이전에 좋은 initial point를 찾아주는 작업입니다. (아무래도 randomly initialize embedding으로 task를 학습할때보다 어느정도 의미가 내포된 embedding을 가지고 task를 학습할 때 좋겠죠?) 또한 'Why does unsupervised pre-training help deep learning?' 에 의하면 이러한 pretraining은 DNN에서 regularization의 역할을 해준다고 합니다.
이전에도 이러한 접근방법이 많았지만 LSTM기반이라 결국 long-term dependency, vanishing graident problem으로부터 자유로울 수는 없었죠. 저자들은 이를 해결하기 위해 Transformer Decoder의 구조를 차용합니다.
2-3. Auxiliary training objectives
PLM이 유행하기 이전까지는 1개의 downstream task를 해결하기 위해 여러가지의 목적함수를 동시에 활용하는 경우가 많았습니다.(Collobert and Weston used a wide variety of auxiliary NLP tasks such as POS tagging, chunking, named entity recognition, and language modeling to improve semantic role labeling.)
저자들 역시 auxiliary objective function을 사용하나, pre-training objective function과 jointly optimize를 통해 성능 향상을 유도하였습니다.
3. Framework
3-1. Unsupervised pre-training
GPT의 pre-training 방법은 굉장히 간단하다.
- corpus를 tokenization
- (where f is word embedding layer)
즉 transformer decoder의 forwarding 방법 (masked multi-head self-attention을 기반으로 한 Language Modeling 구현 = autoregressive modeling)을 통해 token의 contextual embedding을 학습한다. 저자들은 autoregressive objective function 구현시 앞쪽에 K개의 token에만 conditioned 되도록 수식을 일반화해서 작성한 것을 확인할 수 있다. (아래 hugging face code를 살펴보면, n_ctx로 window size(=k)를 지정해주는 것을 확인할 수 있다.)

GPT논문의 transformer decoder에 대한 설명이 너무 불친절해 Jay Alamar의 블로그를 참조해서 설명을 살짝만 추가하도록 하겠다.
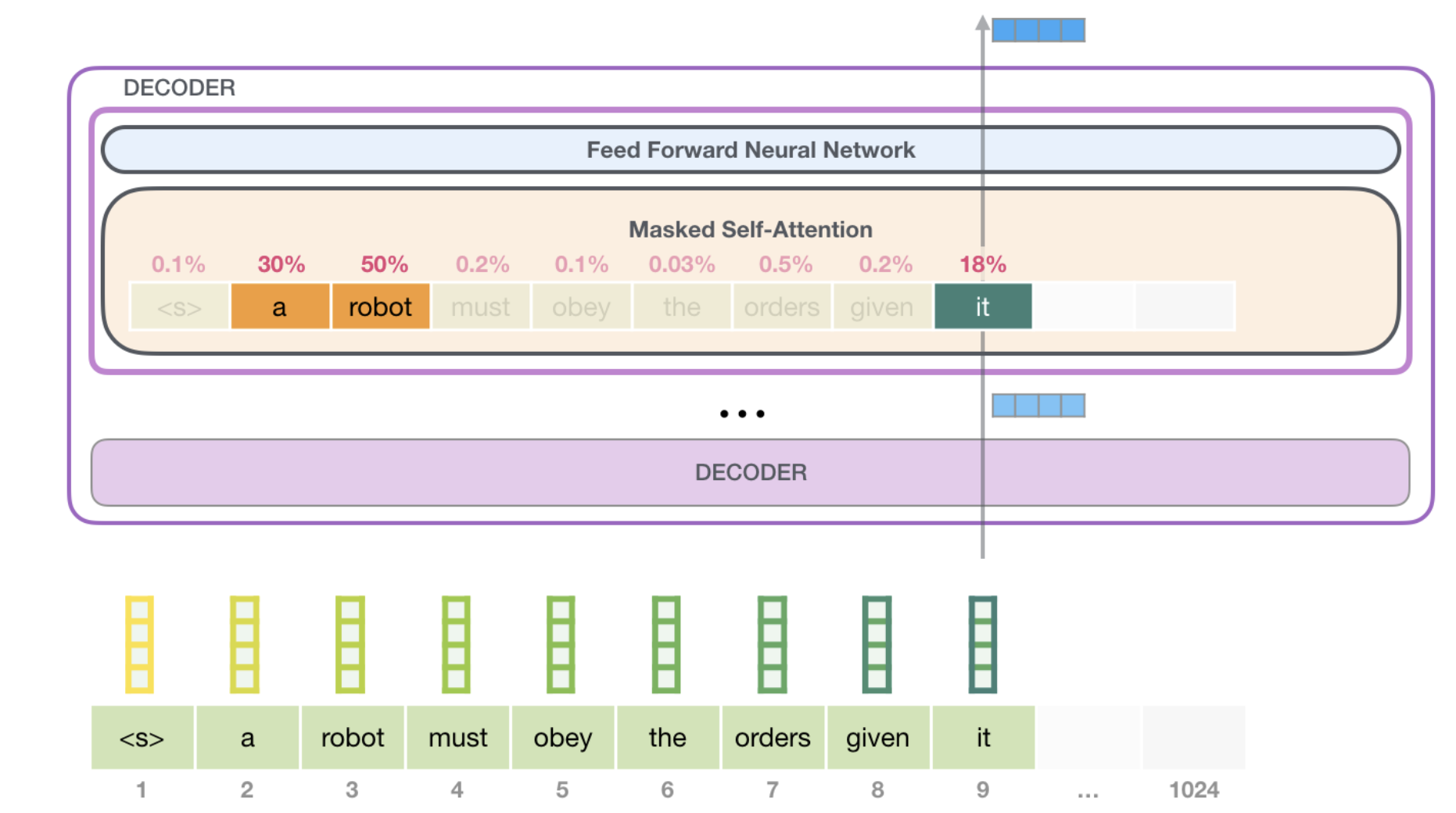
위에서 언급한 바와 같이 transformer의 decoder block은 masked multi-head self-attention을 기반으로 연산된다. masked multi-head self-attention은 multi-head self-attention시에 자기보다 미래에 생성되는 token의 정보를 masking해 token에 대한 contextual embedding 학습시에 앞쪽의 token에만 attention을 주도록 하고 있다.
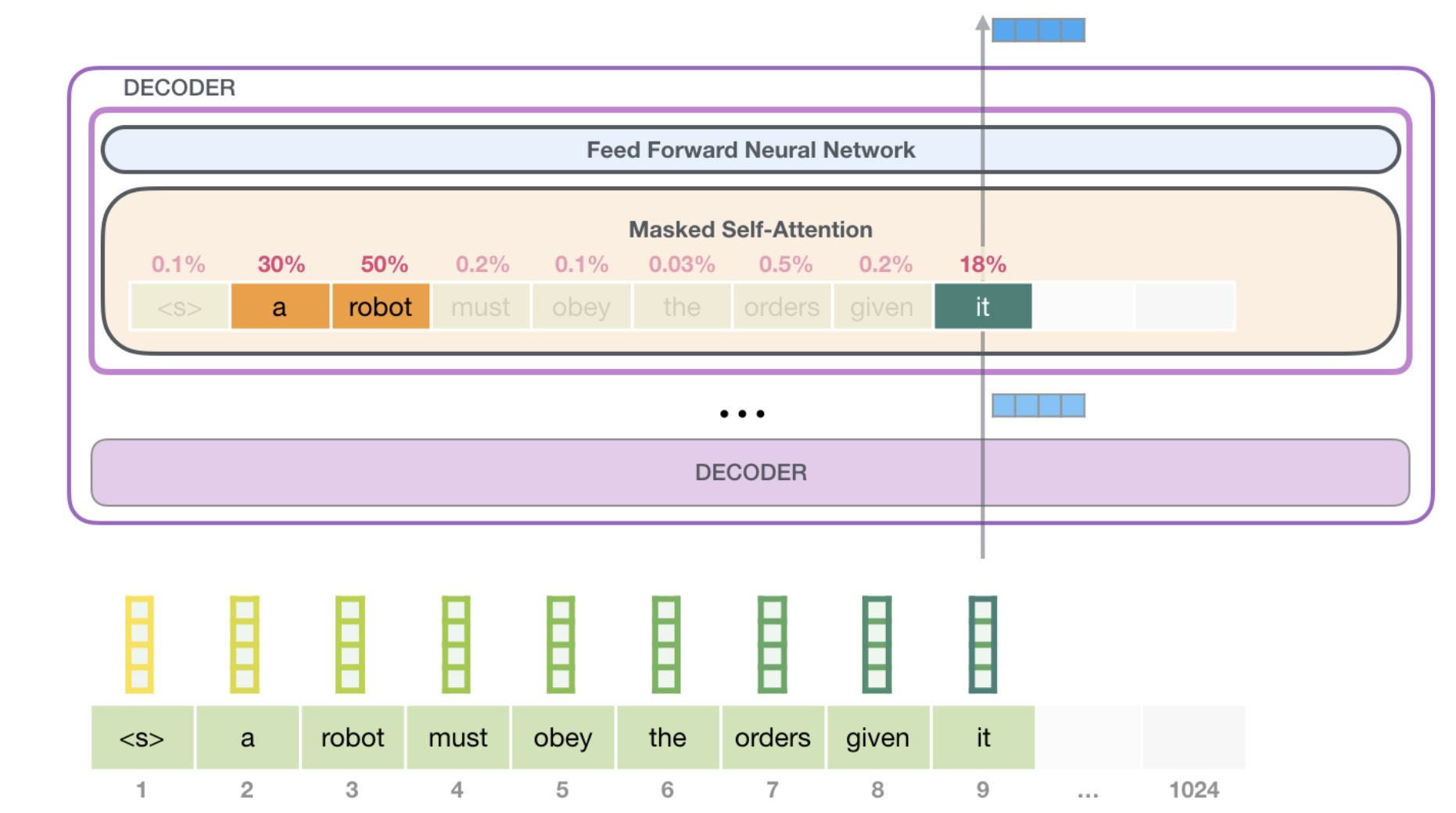
masked multi-head self-attention의 실제 계산은 아래와 같이 attention score matrix의 주대각선 오른쪽 값을 -inf로 변경해서 softmax 계산시에 매우 낮은 확률이 생성되도록 한다.

Hugging Face에 올라온 code를 보면서 이해하도록 해보자
(원래 code에 하나씩 쓰면서 설명해주면 이해하기 편할거 같은데 너무 작업이 많아서 세미나때 설명하도록 하겠습니다...)




3-2. Supervised fine-tuning
3.1에서 소개된 방법으로 pre-training후, GPT 모델은 아래의 수식으로 fine-tuning을 진행합니다. Input=x의 길이가 m일 경우, 마지막 token의 마지막 Layer의 embedding 값 ()에 Linear Transform > Softmax를 거쳐 y값과의 cross entropy를 통해 fine-tuning을 진행합니다.
GPT의 경우 저자들이 fine-tuning시에 pre-traing에서 활동했던 loss()를 auxiliary training objectives로 추가해 lambda()로 가중치를 주면서 jointly하게 학습한다고 합니다. 이러한 technique은 supervised model의 generalization, convergence acceleration에 이점이 있다고 합니다.

3-3. Task-specific input transformations
downstream task의 경우, 여러개의 문장을 input으로 받는 경우가 많은데 GPT는 pre-training시부터 여러 문장을 input으로 받기 때문에 큰 변형 없이 downstream task를 처리할 수 있습니다. 단지 여러 문장을 구분해줄 'deliminator' token만 문장 사이에 추가해주면 됩니다. 기존의 다른 모델들처럼 task-specific한 처리를 할게 거의 없다는 장점이 있죠. 저자들은 4개의 downstream task에 대한 input 형태를 아래와 같이 보여주고 있으며, 모든 downstream task의 input의 처음과 끝에는 random initialize된 <S> token 과 <E> token 을 추가해줍니다.
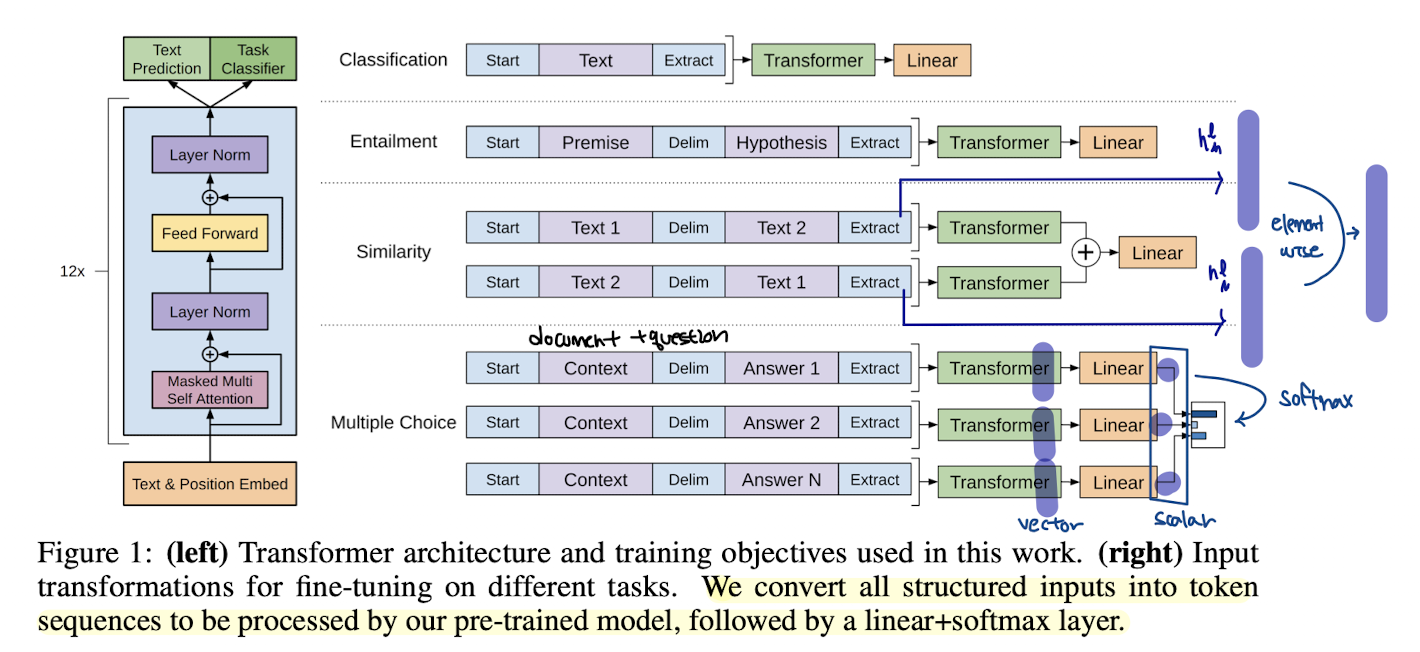
- Textual entailment
we concatenate the premise p and hypothesis h token sequences, with a delimiter token ($) in between.
- Similarity
there is no inherent ordering of the two sentences being compared. To reflect this, we modify the input sequence to contain both possible sentence orderings (with a delimiter in between) and process each independently.
- Question Answering and Commonsense Reasoning
For these tasks, we are given a context document z, a question q, and a set of possible answers {ak}. We concatenate the document context and question with each possible answer, adding a delimiter token in between to get [z; q; $; ak]. Each of these sequences are processed independently with our model and then normalized via a softmax layer to produce an output distribution over possible answers.
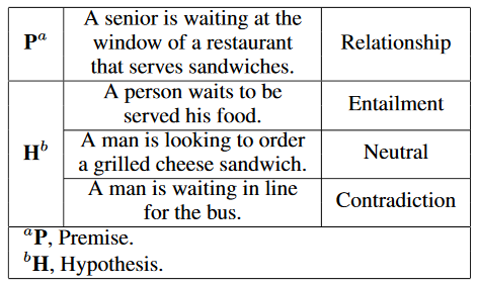
Textual Entailment?
Premise(전제)와 Hypothesis(가정)의 관계가 entailment(함의)인지, neutral(중립)인지, contradiction(모순)인지를 분류하는 문제. 높은 NLU 성능을 요구하는 문제이다. 예시를 보면 바로 이해가 된다.
4. Experiments
4.1 Setup
Unsupervised pre-training
Pre-training시에 BooksCorpus dataset을 활용했는데, 해당 데이터셋은 의미가 이어져 있는 문장 들이 많아서 long-range information을 학습하기에 용이했다고 합니다. 또한 ELMO가 활용한 Word Benchmark도 사용했는데 GPT는 해당 데이터셋에서는 18.4의 낮은 perplexity를 기록했다고 합니다.
Perplexity?
LM이 얼마나 높은 확률로 문장을 생성했는지를 보여주는 지표. Perplexity 문장 생성확률의 역수를 취함으로 낮을수록 좋은값이다. 하지만 '문장 생성 확률' 이라는 것은 데이터마다 다를 수 있다. (ex. domain마다 쓰이는 단어나 구가 다를 것으므로). 따라서 일반적인 성능을 평가하기에는 한계가 있다고 알려져 있지만 많이 쓰이는 지표이다.


Model Specifications
- 12 layers
- 768dim | 12 heads | 3072 FFN intermediate
- Adam Optimizer with linear scheduling
- train for 100 epochs on minibatches of 64 randomly sampled, contiguous sequences of 512 tokens (=max_len)
- bytepair encoding (BPE) vocabulary with 40,000 merges
- Gaussian Error Linear Unit (GELU)
- PE : learned position embeddings
Fine-tuning details
- add dropout to the classifier with a rate of 0.1
- model finetunes quickly and 3 epochs of training was sufficient
for most cases - was set to 0.5
4.2 Supervised fine-tuning
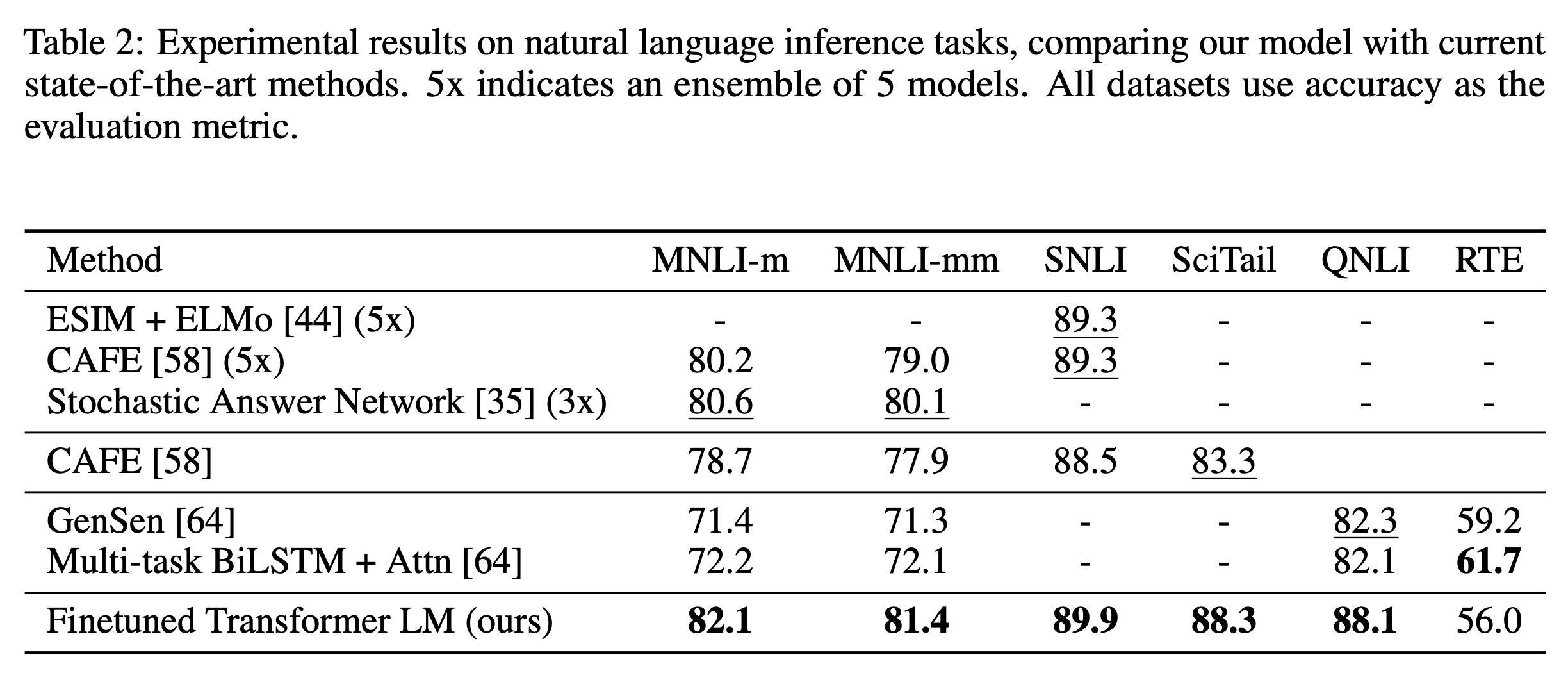
NLI (Natural Language Inference)
두 문장(Premise(전제)와 Hypothesis(가정))의 관계가 entailment(함의)인지, neutral(중립)인지, contradiction(모순)인지를 분류하는 문제. lexical entailment, coreference, and lexical and syntactic ambiguity을 모두 고려해야 되어서 어려운 문제이다. RTE를 제외하고 SOTA를 갈아치웠다.
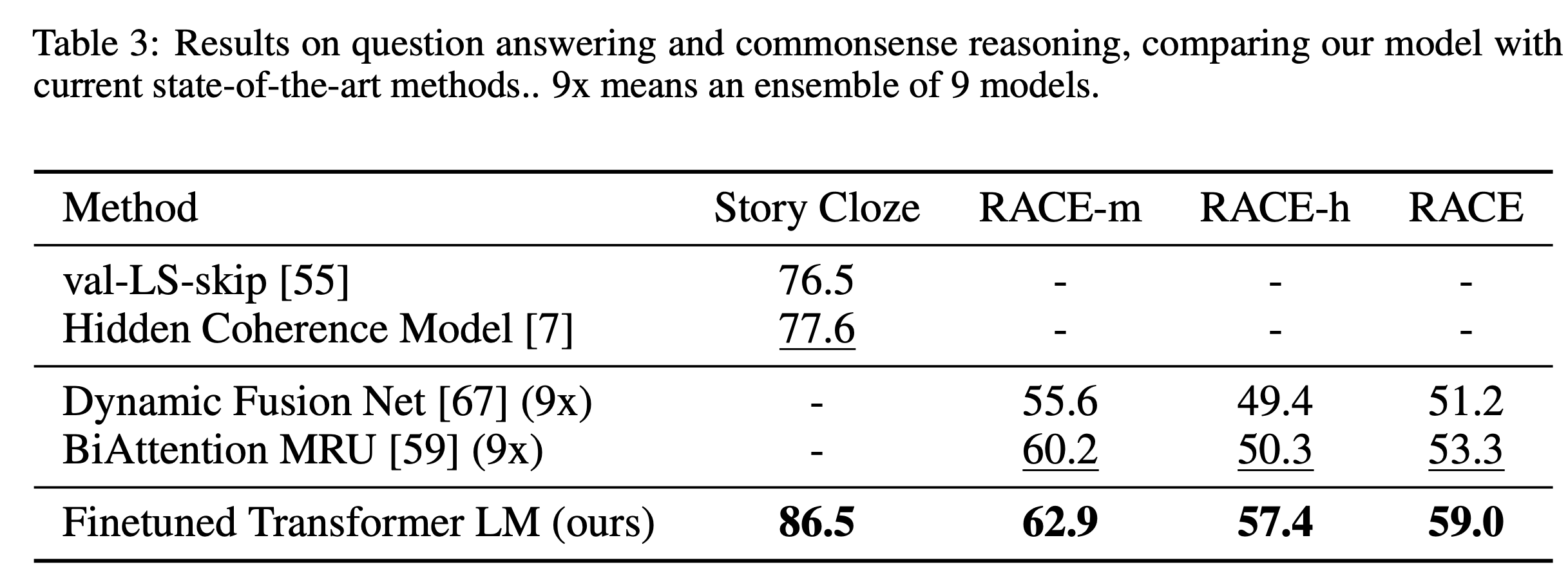
Question Answering and Commonsense Reasoning
QA dataset으로는 CNN/SQUAD보다 상위 수준의 추론능력을 요구하는 Race dataset(-m:middle school/-h:high school)과 multi-sentence stories로 구성된 문제에서 2가지 ending 중 더 적절한 ending을 고르는 Story Cloze dataset을 활용했다. 두 데이터셋에서 모두 SOTA를 갈아치웠다.
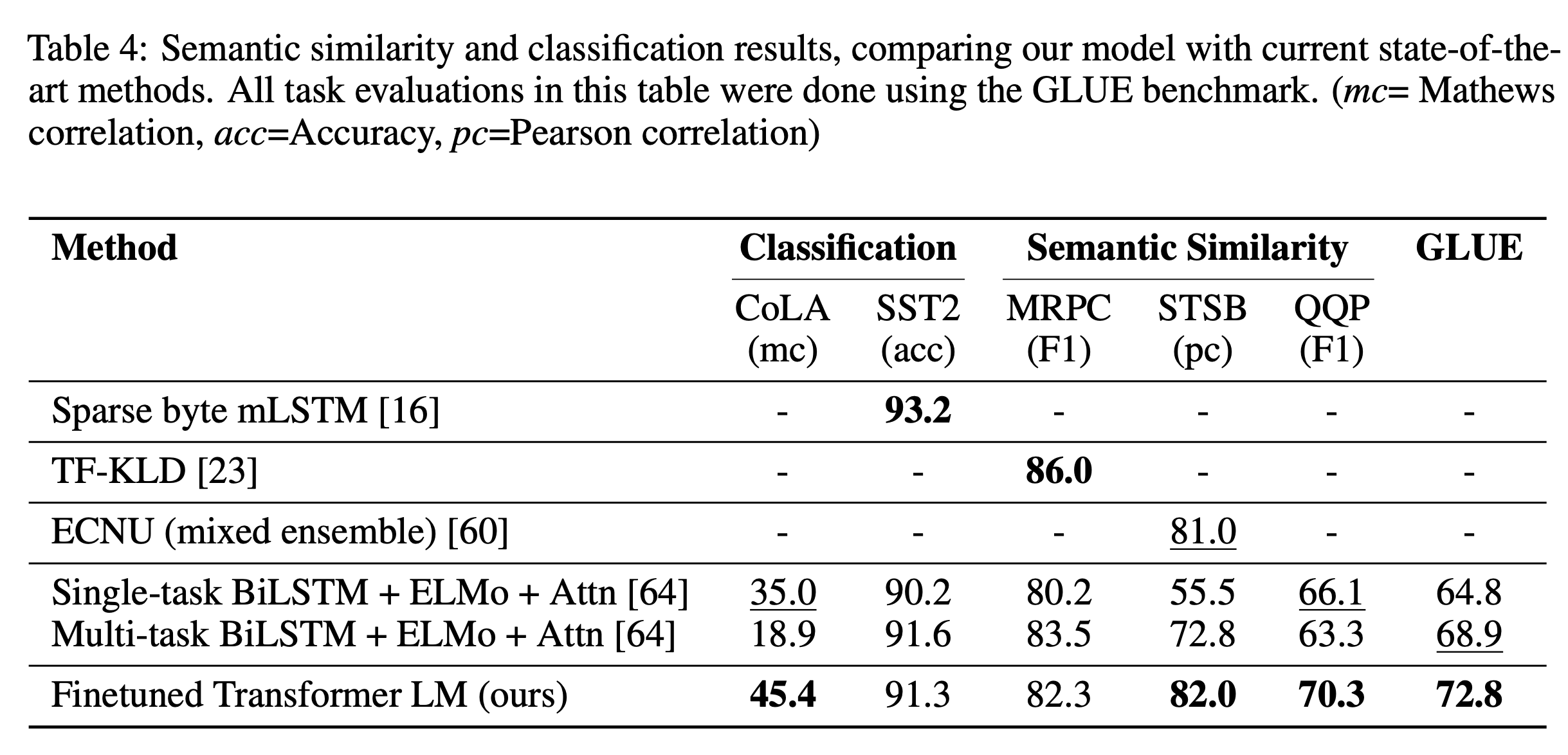
Semantic Similarity
두 문장이 의미적으로 동일한지 판별하는 문제. 해당 문제는 rephrasing of concepts, understanding negation, and handling syntactic ambiguity에 대한 능력을 요구한다. 3개 중 2개의 dataset에서 SOTA를 갈아치웠다.
Classification
CoLA dataset (contains expert judgements on whether a sentence is
grammatical or not, and tests the innate linguistic bias(bias되었는지 평가) of trained models)과 SST-2 (is a standard binary classification task=감성분석), GLUE benchmark에 대해서 실험을 진행. 결과는 아래와 같습니다.
5. Analysis

Impact of number of layers transferred
pre-training시에 사용했던 layer을 fine-tuning 시에 더 많이 전이시킬수록 성능이 향상됨을 보임 (이런 당연한.. 정량적으로 보였으니 좋은건가?)
Zero-shot Behaviors
저자들은 tranformer구조의 학습능력을 평가하기 위해 LSTM과 GPT의 Zero-shot(model to perform tasks without supervised finetuning) 성능을 비교했다. 4개의 dataset에 대해서 보다 구조적으로 강건한 transformer구조가 LSTM에 비해서 pre-training step이 길어질수록 Zero-shot 성능이 향상됨을 보였다. (이래서 향후에 데이터 무지하게 때려넣고 Zero-shot된다고 한거였군... GPT3을 위한 큰그림..)
Ablation Study
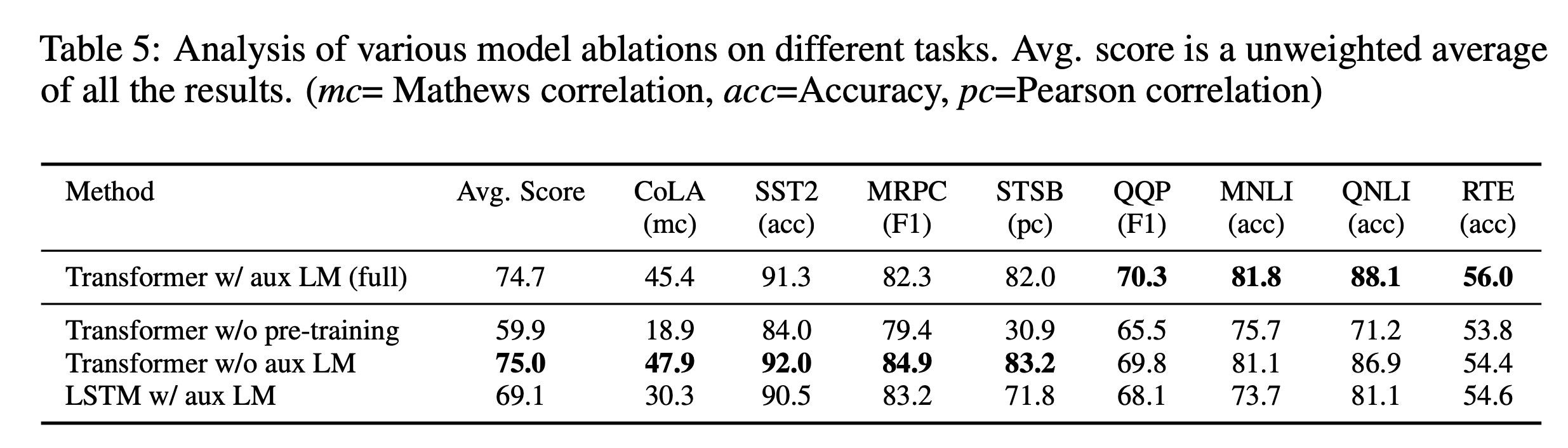
- Auxiliary(=pre-training) loss가 큰 데이터셋에는 효과적이지만 작은 데이터셋에는 그렇지 않다. (작은 데이터셋은 그 데이터에 맞게 weight가 더 shift되어야 성능이 향상될꺼니까?)
- LSTM기반 모델은 Transformer을 이길 가능성이 매우 희박하다.
- Pre-training은 매우 중요하다.
6. Conclusion
GPT는 Transformer가 MT에서 전세계를 놀라게 한 이후에 어쩌면 이런 Transformer 구조가 long-term dependecy를 해결함으로써 수많은 downstream task에서 엄청난 능력을 보여준 것을 보여준 첫번째 논문이 아닐까 싶습니다. GPT2,3에서 계속 데이터를 때려넣어서 성능을 높힌것은 맞지만 (정확히는 안읽어봐서 모름) 4,5년이 지난 지금도 AR의 기본은 GPT, AE의 기본은 BERT인 것을 보면 NLP계의 역사를 바꾼 하나의 논문임에는 분명한거 같네요.
Reference
https://jalammar.github.io/illustrated-gpt2/
https://wikidocs.net/21697
