Convolutional Neural Networks for Sentence Classification
본 논문은 2월 5일 기준 13251회 인용될 만큼 유명한 논문이다. 저자는 Yoon Kim으로 현재 MIT의 조교수로 재직하고 있다.
Abstract
본 논문에서는 사전 학습된 word vector에 CNN을 사용한 sentence classification모델을 제안하고 있다. 특히 간단한 CNN 모델 + 약간의 하이퍼파라미터 튜닝 & static vector를 통해 여러 벤치마크에서 훌륭한 성과를 거두었다. 또한, 추가적으로 아키텍쳐의 간단한 수정을 통해 task-specific과 static vectors의 사용이 가능하도록 제안하고 있다. 이 모델은 7개의 태스크 중 4개의 태스크(감성분석, 질문 분류 포함)에서 SOTA를 달성했다.
1. Terminology
Sentence Classification Task
- 감성 분류(Sentiment Analysis)
ex. 이번 논문은 대박이야! -> 긍정
이번 음악 너무 별론데? -> 부정- 주제 분류(Subjectivity Analysis)
ex. T1, 전승으로 1황 ‘등극’ -> E-스포츠
엘지에너지솔루션 따상 가나? -> 경제- 질문 분류(Question Analysis)
ex. 지점 A에서 지점 B까지의 거리가 어떻게 되나요? (거리)NUMERIC
한국의 수도는 어디인가요?(도시)LOCATION
CNN
인간의 시신경 구조를 모방한 기술로, 다양한 필터를 통해 다양한 특징들을 뽑아내는 모델.
이미지를 인식하기 위해 패턴을 찾는데 주로 사용되며, 이미지의 공간 정보를 유지한 채 학습을 하게 되는 모델이다.
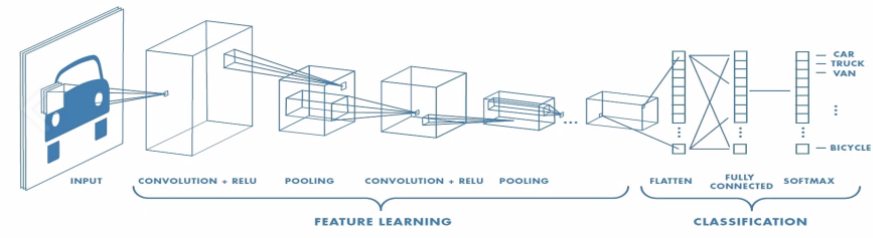
이와 같은 형태로 보통 모델이 진행되는데, CNN은 크게 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나눌 수 있다. 특징을 추출하는 영역은 Conv layer와 pooling layer를 여러 겹 쌓는 방식으로 구성된다. 특징을 추출한 후에 이 특징들을 펼쳐서(Flatten) Fully connected layer에 넣어 최종 분류를 위한 벡터를 산출한다.
- Convolution Layer
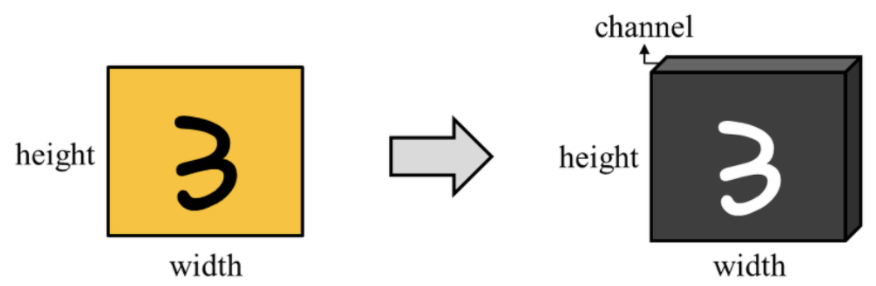
이미지 데이터는 다음과 같이 보통 3차원의 텐서(높이,너비,채널)로 표현된다. 흑백 사진이라면 채널의 크기가 1로, RGB로 표현된 컬러 사진이라면 채널의 크기는 3이 된다.
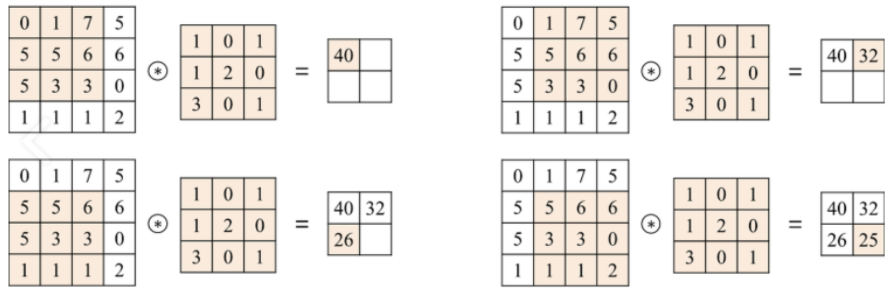
하나의 합성곱 계층에는 입력된 이미지의 채널 개수만큼 필터가 존재한다. 이 필터를 이동하며 입력 이미지의 특징을 추출해낸다. 이 때 얼마나 이동하며 필터를 적용할지는 stride로 결정한다.
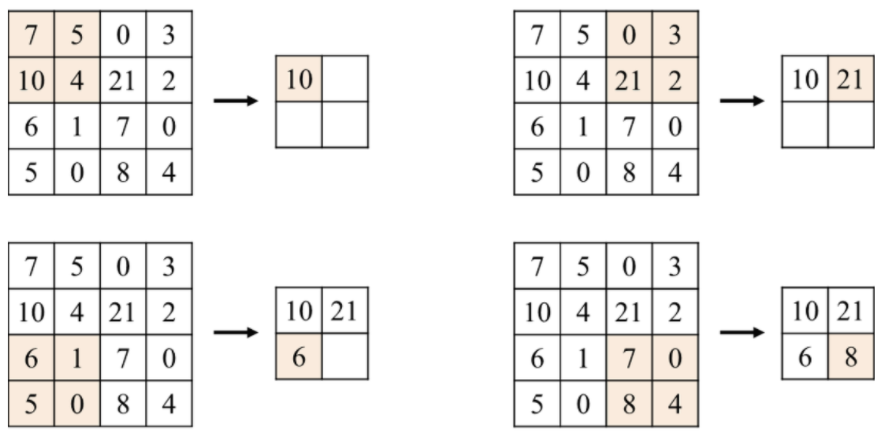
이렇게 필터를 적용한 후에 pooling을 사용해 크기를 조정하면서 특정 feature를 강조하도록 한다.
==> 이와 같이 Conv layer는 필터와 pooling을 통해 feature를 추출!
참고 : https://rubber-tree.tistory.com/entry/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-CNN-Convolutional-Neural-Network-%EC%84%A4%EB%AA%85
Word Embedding
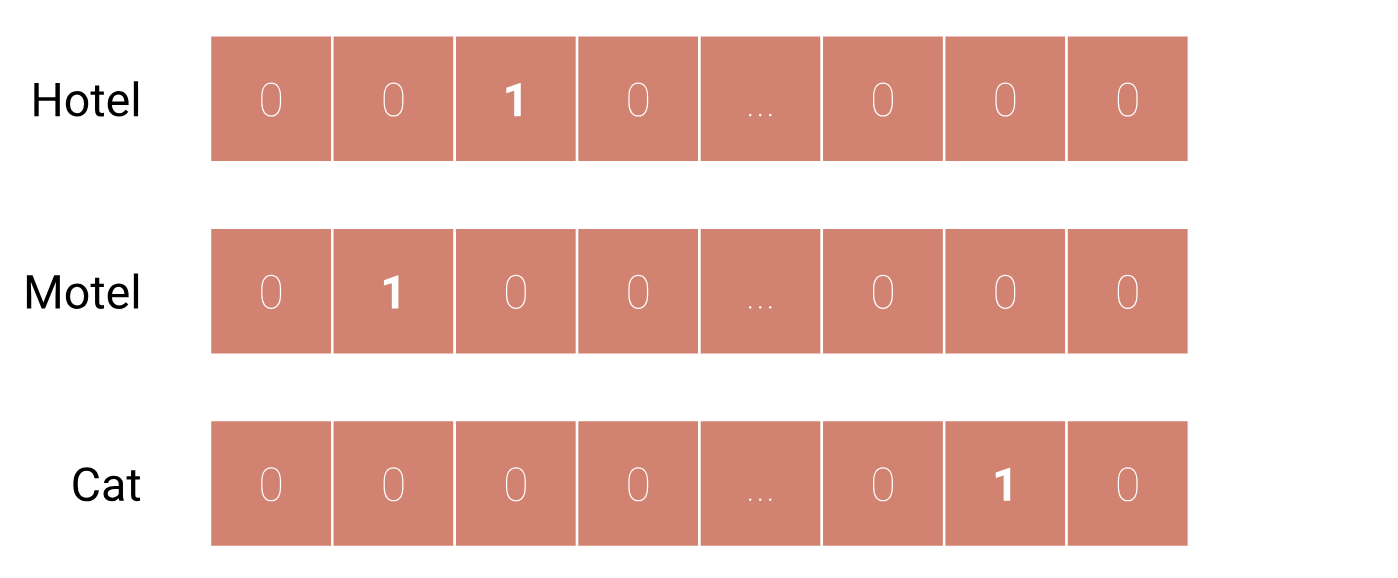
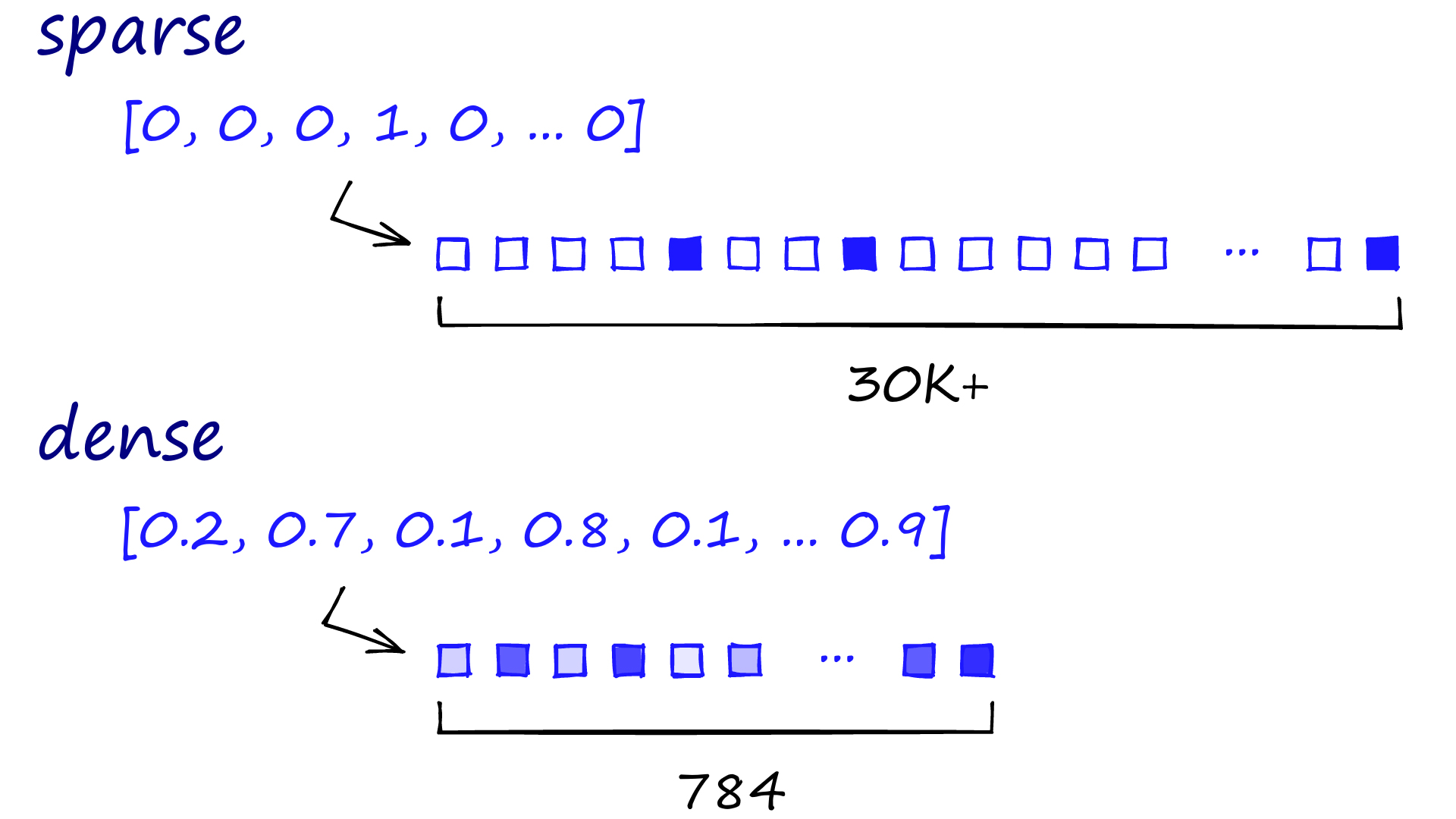
- Sparse Representation(희소 표현)
희소 표현의 한가지 방법은, 다음 그림과 같이 one-hot encoding으로 표현하는 것이다. 하지만 이 경우 단어 집합이 커질수록 단어 벡터의 차원이 커지고, 단어 벡터 내에 실질적으로 표현하는 부분은 단어의 인덱스에 해당하는 하나의 값이고 나머지는 0으로 표현되므로 sparse하다고 한다. 또한, 이렇게 단어를 표현할 경우 단어 벡터를 통해 단어 간의 유사도나 관계를 알아낼 수 없습니다.
- Dense Representation(밀집 표현)
단어 벡터의 차원이 기하급수적으로 커지는 것을 막기 위해 밀집 표현이 고안되었다. 밀집 표현에서 단어 벡터의 차원은 단어 벡터의 크기가 아니다. 사용자가 설정한 값으로 특정 차원으로 단어를 표현하게 되고, 단어 벡터 내의 값은 0 또는 1이 아니라 실수값을 가지게 된다. 이 방식을 임베딩(embedding)이라고 한다.
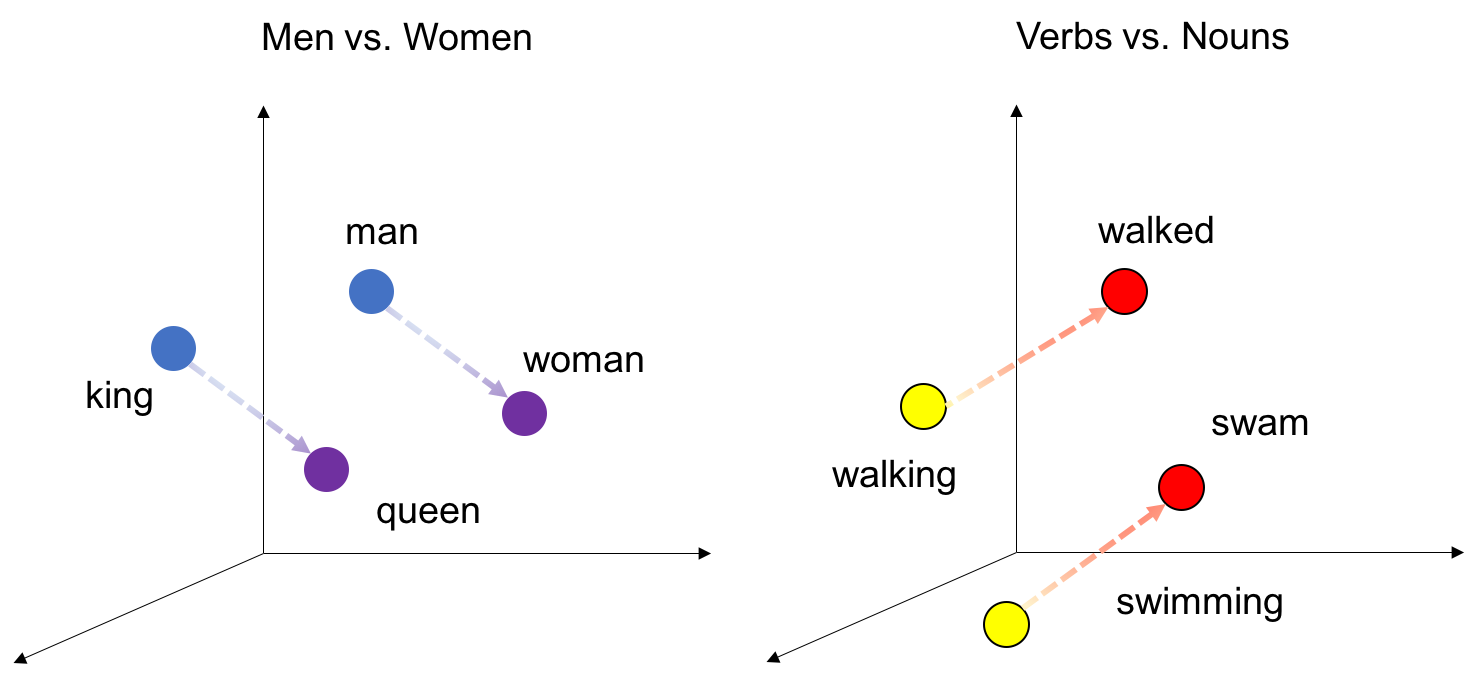
- Distributed Representation(분산 표현)
단어의 의미를 저차원에 분산하여 표현하는 방법. sparse representation에선 각각의 차원이 각각의 독립적인 정보를 갖고 있지만, distributed representation(Dense representation)에선 하나이 차원이 여러 속성으로 섞인 정보를 가지고 있다. 즉, 하나의 차원이 하나의 속성을 명시적으로 표현하는 것이 아니라 여러 차원이 조합되어 나타내고자 하는 속성이 표현되는 것이다. 분산 표현 방법은 기본적으로 분포 가설(Distributed Hypothesis)아래서 만들어졌고, 분포 가설의 핵심정인 주장은 "비슷한 위치에서 등장하는 단어들을 유사한 의미를 갖는다"는 것이다. 즉, 비슷한 의미를 가진 단어는 주변 단어 분포도 비슷하다는 것을 뜻한다. 이를 통해서 단어간 유사도 계산이 가능하며, Algebraic operation이 가능하다.
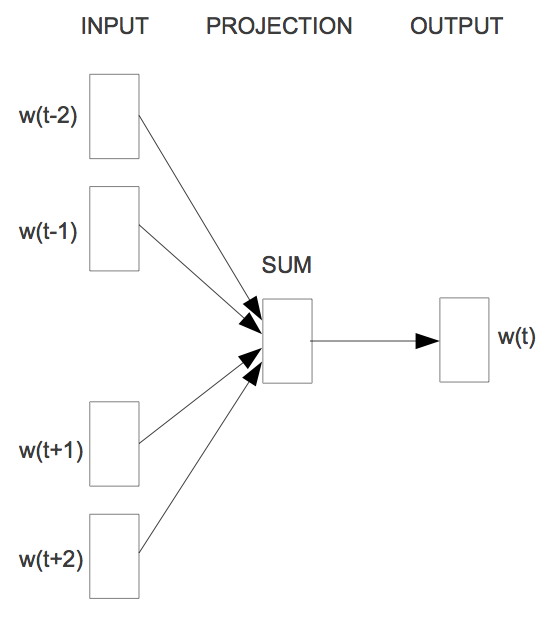
- Word2Vec(CBOW)
CBOW의 기본 아이디어는 주변 단어를 통해 주어진 단어를 예측하는 것이다. 앞 뒤로 (window size)개의 단어를 통해 주어진 단어를 예측한다.
예를 들어, "The fat cat ____ on the mat" 라는 문장이 있다고 하면, ___에 들어갈 단어는 주변 단어를 통해 예측할 수 있다.
1. Introduction
CNN은 지역적 특징에 적용되는 convolving filter를 가진 layer를 활용한다. 원래는 비전 분야를 위해 고안되었지만, 이후 자연어처리에 대해서도 효과적임을 보여주었다.
본 논문에선 unsupervised neural language model에서 얻은 워드 벡터 위에 하나의 레이어를 갖는 간단한 CNN모델을 학습한다. 조금의 하이퍼파라미터 튜닝에도 불구하고, 이 간단한 모델은 여러 벤치마크에서 훌륭한 성과를 냈다. 이는 사전 학습된 벡터들이 다양한 분류 태스크에 활용될 수 있는 'universal' feature extractors라는 것을 보여준다.
2. Model
** 1D CNN vs 2D CNN
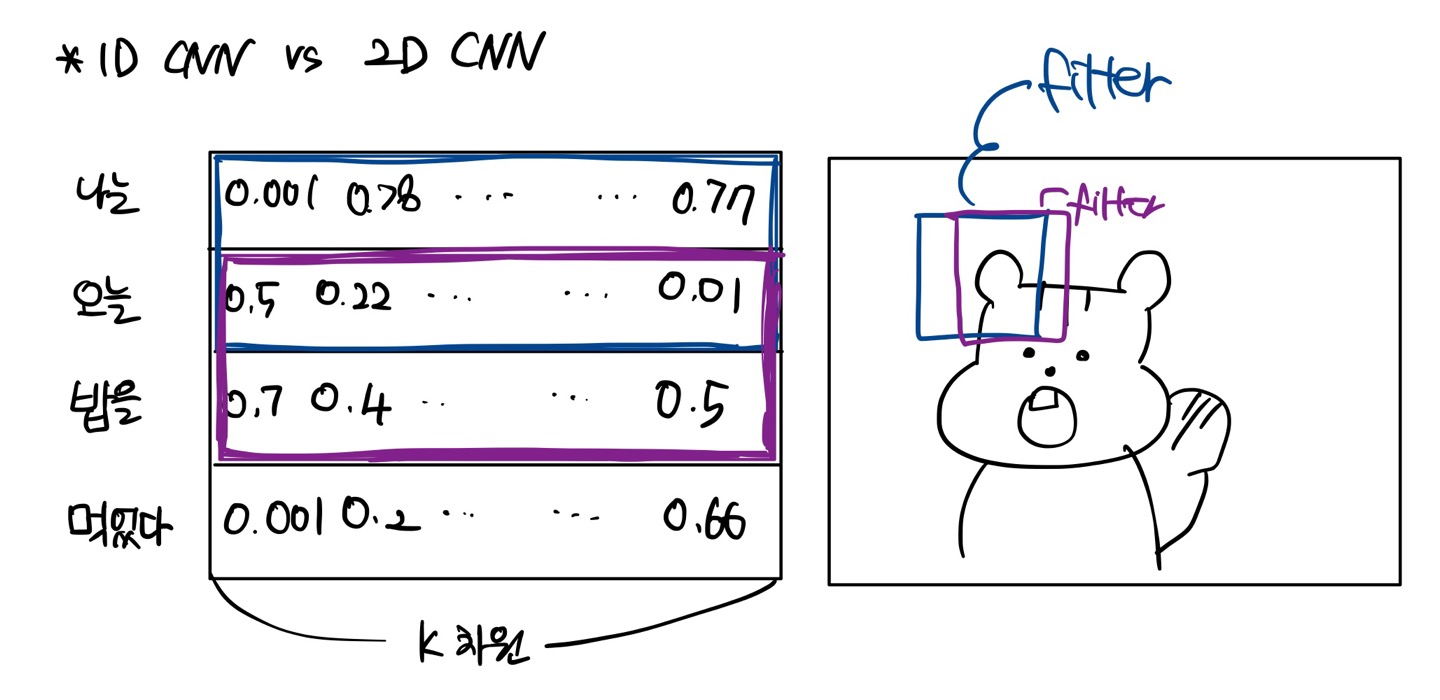
모델 구조는 다음과 같다.
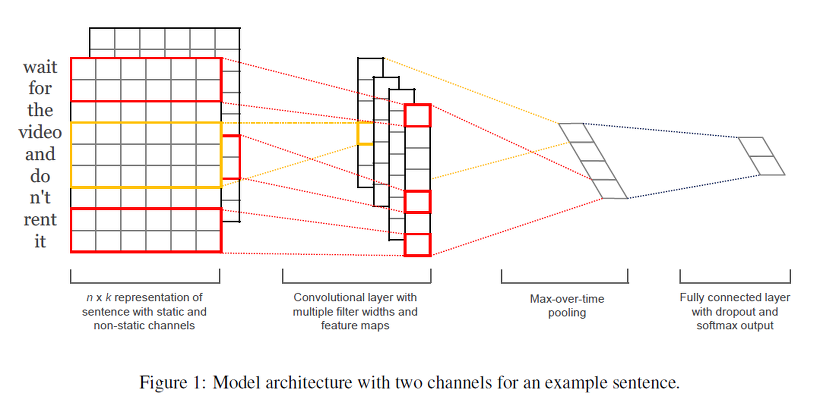
는 번째 단어에 해당하는 차원의 단어 벡터라 하자. 길이가 인 문장은 다음과 같이 표현될 수 있다. 여기서 는 concatenation 연산자이다.
일반적으로 는 번째 단어에서 번째 단어를 concatenation한 것을 의미한다. 하나의 convolution operation은 필터 를 포함하고, 이는 단어의 윈도우에 적용되어 새로운 feature를 만든다.
예를 들어, 특징 가 단어 의 윈도우에서 생성되었다면
라고 표현할 수 있다. 이 때
인 편향항이고, f는 tanh와 같은 비선형 함수이다. 이 필터는 문장에서 가능한 모든 윈도우 각각에 적용되고, 다음과 같은 feature map을 만들어낸다. 이 때 이다.
이후 max-over-time pooling operation을 feature map에 적용해 가장 큰 값 을 특정 필터에 상응하는 특징으로 둔다. 이 풀링 방식은 자연스럽게 가변 문장 길이를 처리한다.
지금까지 하나의 필터에서 하나의 특징을 추출하는 과정을 설명했다. 이 모델은 여러 필터를 사용해 여러 특징을 얻는다. 이러한 특징들은 그림의 끝에서 두 번쨰 레이어를 형성하고, 레이블에 대한 확률 분포가 출력 되도록 fully connected softmax layer로 전달된다.
모델의 변형 중 하나에서 단어 벡터를 2개의 채널로 갖는 실험을 진행했다 - 하나는 학습 동안 단어 벡터를 고정해놓는 것이고, 하나는 역전파를 통해 파인 튜닝 되도록 한 것이다.
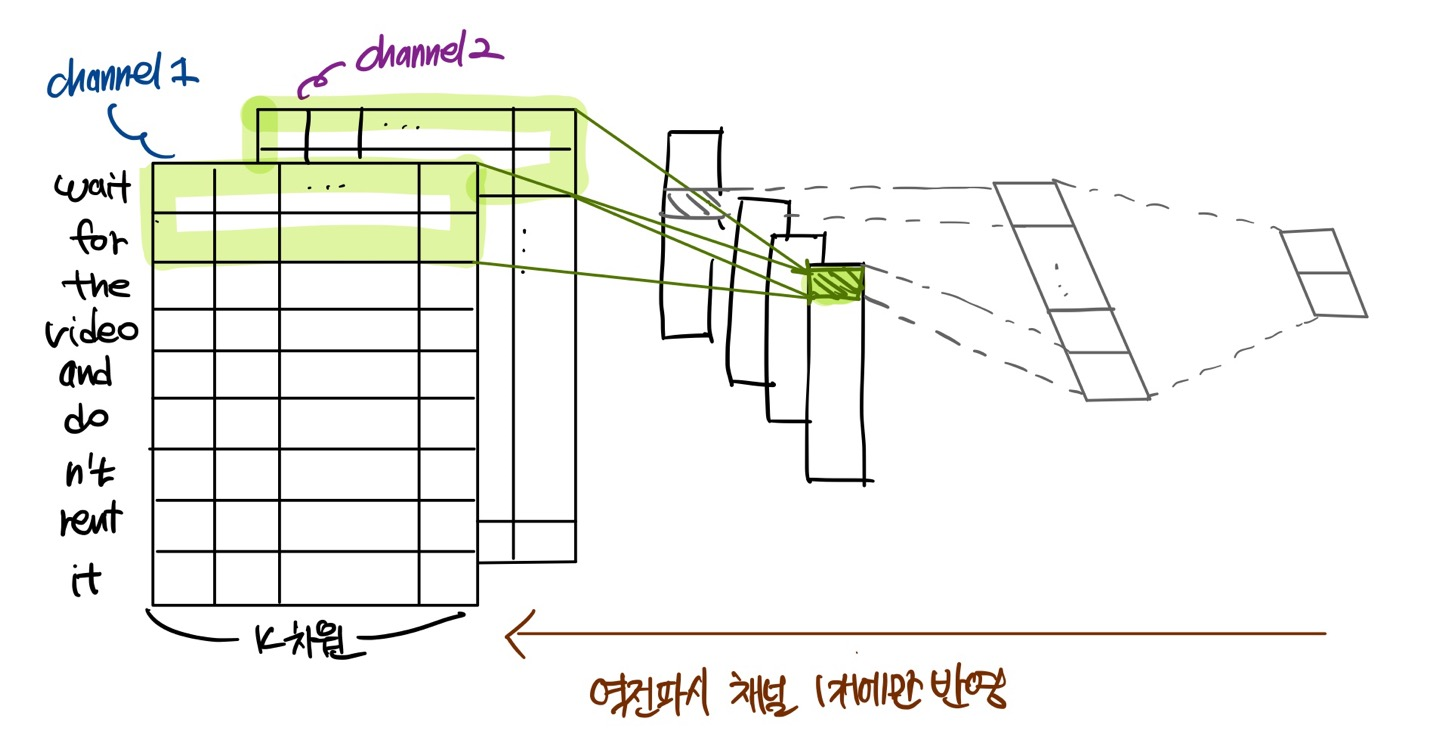
위의 모델 그림과 같은 다채널 아키텍쳐에서 각 필터는 두 채널 모두에 적용되고 각 채널의 결과를 더해 를 계산합니다.
2.1 Regularization
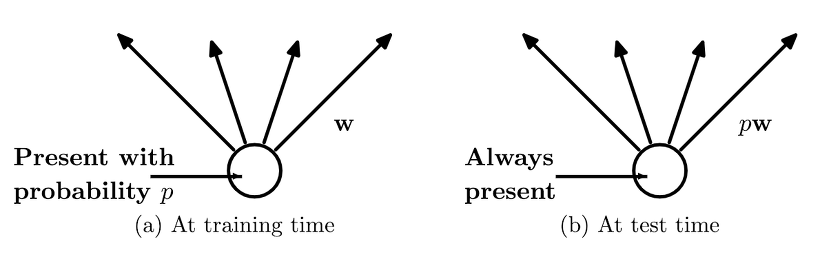
정규화를 위해 끝에서 두번째 레이어에 dropout을 사용합니다. Dropout은 순방향-역전파 동안 은닉 유닛의 비율 p를 무작위로 dropout(0으로 설정)하여 은닉 유닛의 co-adaptation을 방지합니다.
Co-adaptation, 동조화
: 특정 뉴런의 가중치나 바이어스가 큰 값을 갖게 되면, 그 특정 뉴런의 영향이 커지면서 다른 뉴런들의 학습 속도가 느려지거나 학습이 제대로 진행되지 못하는 경우.
즉, 끝에서 두번째 레이어 이 주어졌을 때(m은 필터의 개수),
을 사용하는 대신에,
을 사용한다. 여기서 는 원소별 곱셈을 나타내는 연산자이고, 는 확률 를 가지는 베르누이 확률 변수의 마스킹 벡터이다. 마스킹이 안된 유닛만 사용해 그래디언트가 역전파된다. 테스트시, 학습된 가중치는 에 의해 조정된다()
추가적으로 가중치 벡터의 -norm을 제한하기 위해, 경사 하강 단계(gradient descent step) 후에 일 경우 가 되도록 가중치를 rescaling한다.
3. Datasets and Experimental Setup
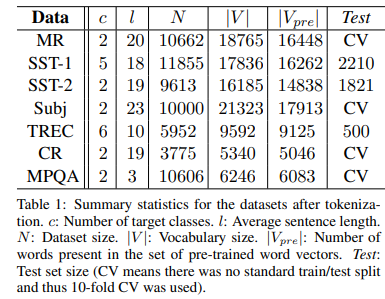
본 논문에서는 모델을 테스트하기 위해 여러 벤치마크를 사용했다. 데이터셋에 대한 요약통계량은 아래 표와 같다.
- MR : 리뷰 당 한 문장인 영화 리뷰 데이터. 리뷰가 긍정인지 부정인지 분류.
- SST-1 : 스탠포드 감정 트리뱅크(Treebank) - MR의 확장 버전 느낌. train/dev/test가 나뉘어 있고, 감성이 좀 더 세밀하게 라벨링 되어 있음(아주 좋음, 좋음, 중립, 나쁨, 아주 나쁨)
- SST-2 : 위와 똑같지만 중립인 리뷰가 제거되고, 이진 라벨
- Subj : 문장이 주관적인지 객관적인지 분류하는 데이터셋
- TREC : TREX 질문 데이터셋 - 질문을 6개의 종류(about person, numeric, location..)로 분류
- CR : 다양한 제품에 대한 소비자 리뷰. 긍정인지 부정인지 맞추는 태스크
- MPQA : MPQA데이터셋에서 하위 태스크인 Opinion polarity detection
3.1 Hyperparameters and Training
모든 데이터에 대해 사용한 것
- Relu
- filter windows(h) of 3,4,5 with 100 feature maps
- dropout rate(p) of 0.5
- constraint(s) of 3
- mini-batch size of 50
(이 설정값들은 SST-2 dev set에 grid search를 사용해 찾음)
early stopping 외에 dataset-specific한 튜닝은 없었음.
standard dev set가 없는 데이터셋에 대해선 training data의 10%를 무작위로 선택해 dev set으로 활용. 학습은 Adadelta update rule을 기반으로 무작위로 섞인 mini-batch에 대해 SGD를 통해 진행됨.
3.2 Pre-trained Word Vectors
unsupervised neural language model에서 얻은 워드 벡터로 초기화. 여기선 word2vec 벡터를 사용함. 벡터는 300 차원이고, CBOW방법으로 학습됨. 사전 학습된 단어 집합에 없는 단어는 랜덤하게 초기화.
3.3 Model Variations
모델을 여러 가지 버전으로 실험!
- CNN-rand : 모든 단어를 랜덤하게 초기화, 학습하면서 단어 벡터도 같이 학습.
- CNN-static : word2vec으로 사전 학습된 단어 벡터 사용. 학습 동안 모든 단어는 변동 X, 모델의 파라미터만 학습
(사전 학습된 단어 집합에 없어서 랜덤하게 초기화한 단어 포함) - CNN-non-static: word2vec으로 사전 학습된 단어 벡터 사용. 사전 학습된 단어가 각 태스크에 맞춰 파인 튜닝 됨.
- CNN-multichannel : 워드 벡터 집합이 2개인 모델. 각 벡터 집합은 "channel"로 처리되고, 각 필터는 두 채널 모두에 적용되지만 역전파는 채널 중 하나만 사용 . 그래서 이 모델은 한 채널은 파인 튜닝이 됐지만, 한 채널은 static을 유지. 두 채널 모두 word2vec으로 초기화 됨.
위의 변화와 다른 임의 요소의 효과를 분리하기 위해 CV-fold 할당, 단어 집합에 없는 단어 초기화, CNN 파라미터 초기화와 같은 임의성을 가지는 요소들을 균일하기 유지.
4. Results and Discussion
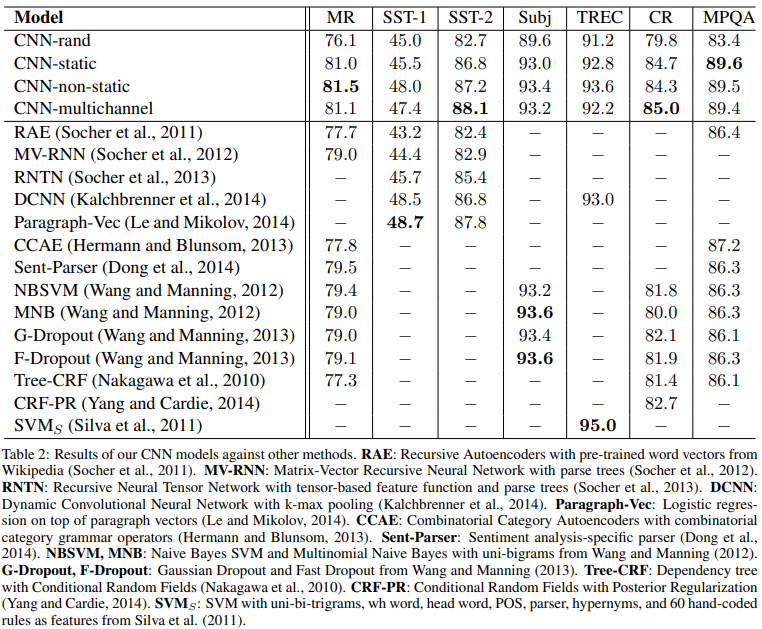
- baseline model(CNN-rand)는 성능이 그리 좋지 않다.
- 성능을 기대했던 사전 학습된 벡터를 사용한 모델은 성능이 좋다.
- static vectors를 사용한 간단한 모델이 다른 복잡한 딥러닝 모델 또는 parse tree가 필요한 모델보다 현저히 높은 성능을 보임.
==>이 결과를 보면, 사전 학습된 벡터들은 good, 'universal' feature extractors이고, 이는 여러 데이터셋에 활용될 수 있다는 것을 알 수 있다. - 각 태스크에 맞춰 파인튜닝하는 것이 대체로 더 좋은 성능을 보임(CNN-non-static)
4.1 Multichannel vs. Single Channel Models
처음에 다채널 아키텍쳐가 오버피팅을 방지해(학습된 벡터들이 원래의 값에서 너무 멀어지지 않게 함), 단일 채널 모델보다 더 좋은 성능을 낼거라고 생각했다(특히 작은 데이터셋에서!). 하지만 결과는 둘이 비등 비등했다! 그래서 여러 채널을 쓰는 것보다 한 채널을 쓰되, 차원을 추가해서 학습가능하게 하는 방식으로 더 연구를 해봐야할거 같다고 한다.
4.2 Static vs. Non-static Representations
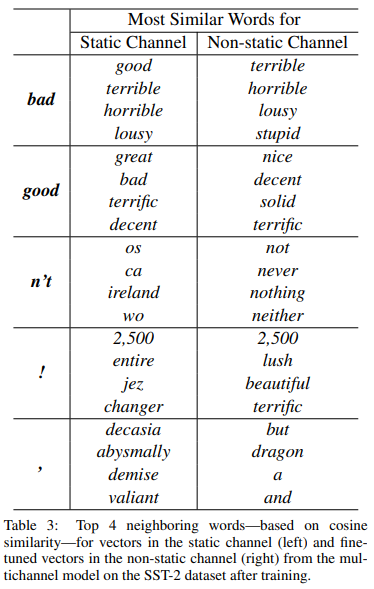
static 모델의 경우 단어 벡터는 학습을 하지 않지만 non-static모델은 단어 벡터까지 학습을 한다. 그래서 이 두 모델의 단어 벡터를 살펴보면, 얼마나 파인튜닝 됐는지를 확인해 볼 수 있다.
- static의 경우 bad와 가장 유사한 단어가 good이지만, non-static에선 terrible이 bad와 가장 유사하다는 것을 알 수 있다.
- 마찬가지로 w2v에서 good이랑 가장 유사한 단어는 great였지만, 파인 튜닝된 모델에서 good과 가장 유사한 단어는 nice였다.
(good은 아마 감정을 표현하는데 있어 great보다 nice에 가깝고, 이것이 실제로 학습된 벡터에 반영되었다고 논문에선 말함.) - 랜덤으로 초기화 된 토큰에 대해 파인 튜닝은 더 의미 있는 representation 학습을 하게 한다.(네트워크는 느낌표가 감탄 관련 표현과 연관되어 있고, 쉼표가 접속사의 의미임을 알게 됨.)
4.3 Further Observation
몇가지 추가 실험 & 관찰에 대한 정리
-
Kalchbrenner et al. (2014)는 본 논문의 단일 채널 모델과 본질적으로 같은 CNN으로 더 안좋은 결과를 기록했다. 예를 들어, 그들의 max-TDNN(Time Delay Neural Network)은 SST-1에 대해 37.4%였지만, 우리 모델은 45%였다. 아마 이 차이는 우리 CNN이 더 높은 수용력(capacity- 여러 필터 너비와 특징맵)를 갖기 때문인 것으로 보인다.
- TDNN은 1D-Convolution과 동치이다.(stride=1)
- TDNN 방법은 한정된 데이터의 time sequence만 학습할 수 있다.(예를 들면 t, t-1,t-2 면 third order)
-
Dropout이 좋은 정규화 수단임이 증명되었다. Dropout은 지속지속적으로 2%-4%정도의 성능을 더했다.
-
word2vec에 없는 단어를 랜덤으로 초기화 할 때, 랜덤으로 초기화 된 벡터가 사전 학습된 벡터와 동일한 분산을 갖도록 a를 선택해 에서 각 차원을 샘플링하여 약간의 개선을 얻었다!
-
다른 사전 학습된 단어 벡터보다 word2vec이 훨씬 좋았다.
-
Adadelta는 Adagrad와 유사한 결과를 주지만 epochs이 더 적게 듦.
5. Conclusion
word2vec위에 간단한 CNN을 사용한 본 논문의 모델은 약간의 하이퍼파라미터 튜닝과 1개의 layer를 가진 CNN으로도 훌륭한 성능을 보였다. 또한 비지도 사전 학습 단어 벡터가 NLP에 중요한 재료가 된다는 근거를 더했다.
