Learning to Repair- Repairing model output errors after deployment using a dynamic memory of feedback
Abstract
LLM이 등장함에 따라 많은 task들의 수준 높은 처리가 가능해졌지만, 여전히 LLM은 치명적인 약점들에 노출되어 있습니다. (Inconsistency, Factual Error, Bias answer, ...)
하지만 LLM자체를 재훈련시키는 것은 2가지 측면에서 문제점이 있습니다.
- 재훈련 자체가 엄청난 비용을 야기함
- 새로운 데이터가 모델의 가중치를 어떻게 변경할지를 모름
따라서 해당 논문에서는 freeze된 LLM이 틀린 정답을 내놓을 경우, 사용자가 틀린 정답에 대한 feedback을 주면 feedback과 틀린 정답을 활용해 원래 정답을 생성하려면 어떤 action = edit step이 필요한지를 예측하는 프레임워크를 제시합니다.
이렇게 적용된 feedback은 Memory에 write됩니다.
이러한 프레임워크가 가지는 큰 장점은 향후 유사한 edit이 필요한 경우, 과거 Memory에 저장한 유사한 feedback을 활용해 edit을 생성할 수 있어 효율적인 적용이 가능하다는 것입니다.
자세한 내용은 아래에서 소개드리도록 하겠습니다.
1. Introduction
Abstract에서 언급한 것처럼 LM이 생성한 mistake를 수정하기 위해 모델을 재훈련하는 작업은 상당한 수준의 비용과 불확실성을 요구합니다.
따라서 본 논문에서는 모델이 내놓은 틀린 ouput에 대해서 corrective한 feedback을 주어 output을 교정하는 프레임워크를 제시합니다.
이 프레임워크를 위해서는 아래의 구성요소와 가정이 필요합니다.
- 구성요소
- Growing, Dynamic Memory : 모델이 이전에 생성한 틀린 output들에 대해서 발생한 feedback을 저장해놓는 database. 향후 유사한 erroneous output에 대해서 비슷한 feedback을 활용하면 적절한 edit action을 inference할 수 있음
- Corrector : erroneous output과 자연어 feedback을 입력으로 받아서 edit action을 생성해내는 모델
- 가정
- model의 output이 repairable해야 한다. 즉 특정구조(ex. 그래프)를 가져야 명확하게 정의된 action으로 erroneous output을 edit할 수 있기 때문에.
- 비슷한 erroneous output들에 대해서는 유사한 feedback이 적용될 수 있어야 한다.
이러한 구성요소와 가정을 만족시키기 위해 저자들은 scipt generation이라는 task에 대해서 위의 프레임 워크를 제시합니다.
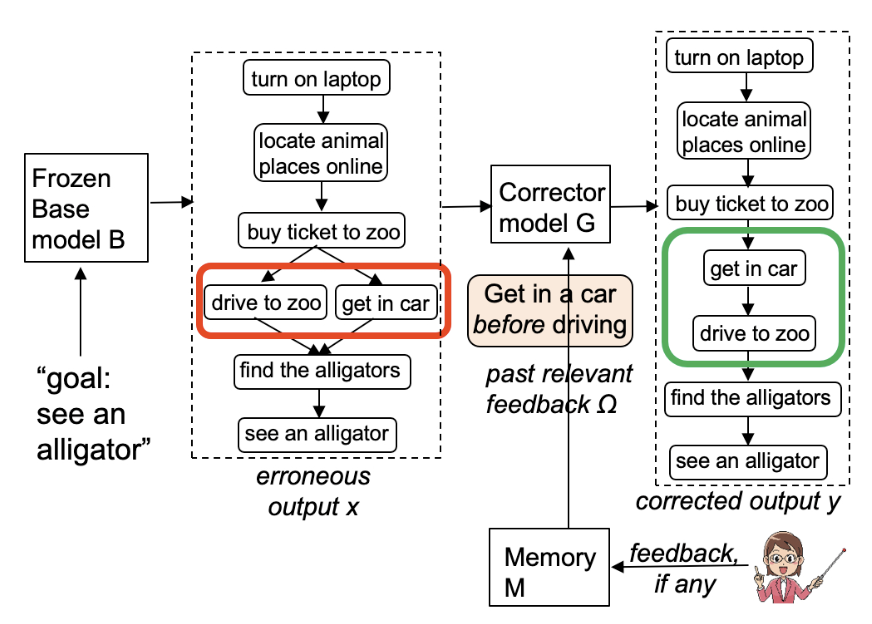
scipt generation은 위의 그림에서 보여주는 것과 같이 'goal: see an aligator' 라는 prefix와 goal의 내용이 주어졌을 때, 이 goal을 위해 수행되어야할 일련의 action들을 생성하는 task입니다.
본 논문에서는 위의 task를 처리할 수 있는 proScript라는 모델을 활용합니다. 위의 모델은 'goal: see an aligator' 라는 입력을 받으면 goal을 달성하기 위해 수행해야하는 'turn on laptop -> locate animal places online -> .... - > see an aligator' 와 같은 일련의 동작들을 생성합니다.
하지만 위의 그림에서 모델이 생성한 답은 'drive to zoo'와 'get in car' 가 어떤 순서로 발생해도 상관이 없다는 error를 내포합니다.
이 error를 보고 user가 get in a car before driving' 이라는 feedback을 주면, Corrector Model G는 erroneous script와 feedback을 가지고 'add partial order type '<get in a car, drive to zoo>' ' 라는 graph edit operation을 생성해야 합니다.
그리고 get in a car before driving' 라는 feedback을 Memory에 저장해서 향후 비슷한 erroneous output을 edit할 때 retrieve하도록 합니다.
저자들은 자신들이 제안한 프레임워크를 FBNET이라고 명명하고, 아래 2가지 측면에서 FBNET을 평가합니다.
- FBNET이 자연어 feedback을 정확히 해석해 올바른 edit을 생성할 수 있는가?
- FBNET이 prior mitake를 통해 unseen한 erroneous output을 올바르게 edit할 수 있는가?
실험결과 질문 1에서는 feedback을 사용하지 않는 경우 댑 3%의 성능 향상을 얻었고 질문 2에 대해서는 7%의 성능 향상을 얻었다고 합니다.
2. Related Work
3. FBNET
3.1 Overview of the Architecture
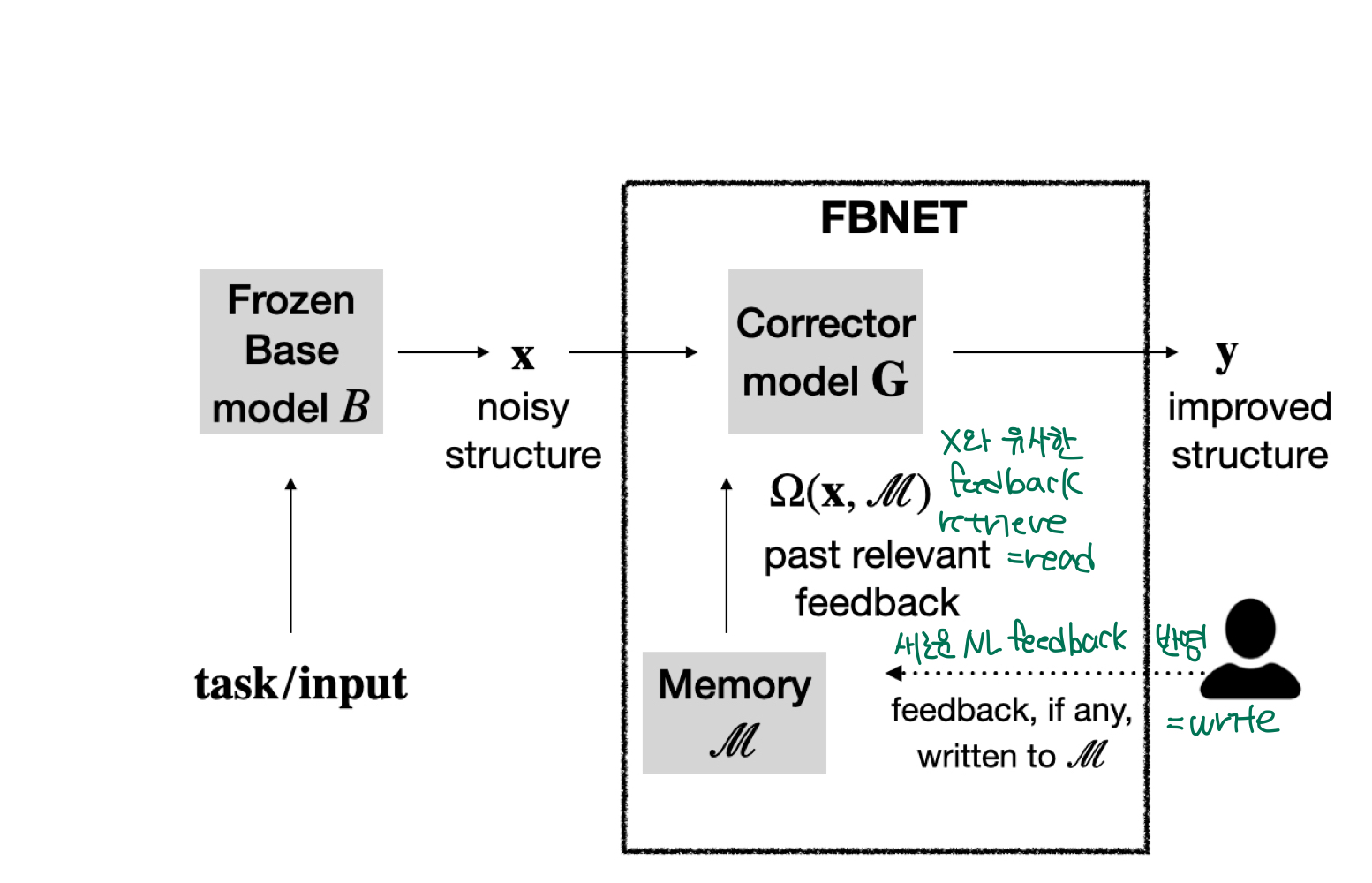
FBNET은 model B가 베포된 환경에서 (model B is freezed) erroneous output 가 주어질 경우 user가 natural language feedback 을 주면 corrector model G 는 와 를 입력으로 받아 edit action 를 생성해 erroneous output 를 correct output 로 수정합니다.
이때 매번 새로운 natural language feedback 는 Memory 에 $key x{i}, - value fb{i} $ 의 형태로 dynamic하게 저장됩니다.
이후에 새로운 query 가 들어올 경우 FBNET은 lookup function 을 활용해 유사한 feedback을 retreive하여 edit action 을 생성하고 erroneous output을 교정합니다.
3.2 Assumptions
FBNET 실험을 위해서는 2가지 가정이 필요합니다.
-
model B의 output은 repairable하다. 즉, model의 output은 구조적으로는 옮으나 (ex. 그래프 구조를 갖추고 있긴한데) 내용적으로는 틀렸다. (잘못된 노드가 있다던가, edge가 틀림)
-
feedback은 reusable해야 한다. retreival funciton 는 유사한 error를 가지고 있는 에 대해서는 상호 작용할 수 있는 feedback 가 retreive되어야 한다.
3.3 Memory M and Omega
natural language feedback 은 Memory 에 저장되며, 새로운 query에 대한 feedback은 error의 유사도를 가지고 feedback을 반환합니다.
3.4 Corrector model G
Corrector model G는 2 step으로 erroneous output을 교정하도록 설계하였습니다.
- erroneous output 와 를 입력으로 받아 edit action 를 생성
- 가지고 erroneous output 를 교정해 correct output 를 생성
이렇게 2 step으로 나누어서 훈련한 이유는 edit ation을 생성하는게 erroneous output 를 직접 수정하는 것보다 간단하고 baseline과의 용이한 비교도 가능합니다.
그리고 당연히 edit action 이 정해지면 correct output 는 deterministic하게 정의되기 때문에 사실상 상관이 없습니다.
3.5 Training and Inference
Corrector model G 훈련을 위해서는 (,,) 의 pair가 필요하고 는 와 의 차이에 의해서 정의됩니다.
또한 와 는 일련의 순서를 갖는 그래프이지만 언어모델로의 학습을 위해 string representation을 갖는 graph description language DOT를 활용해 작성했다고 합니다.
4. Application: Script Generaiton
4.1 Task
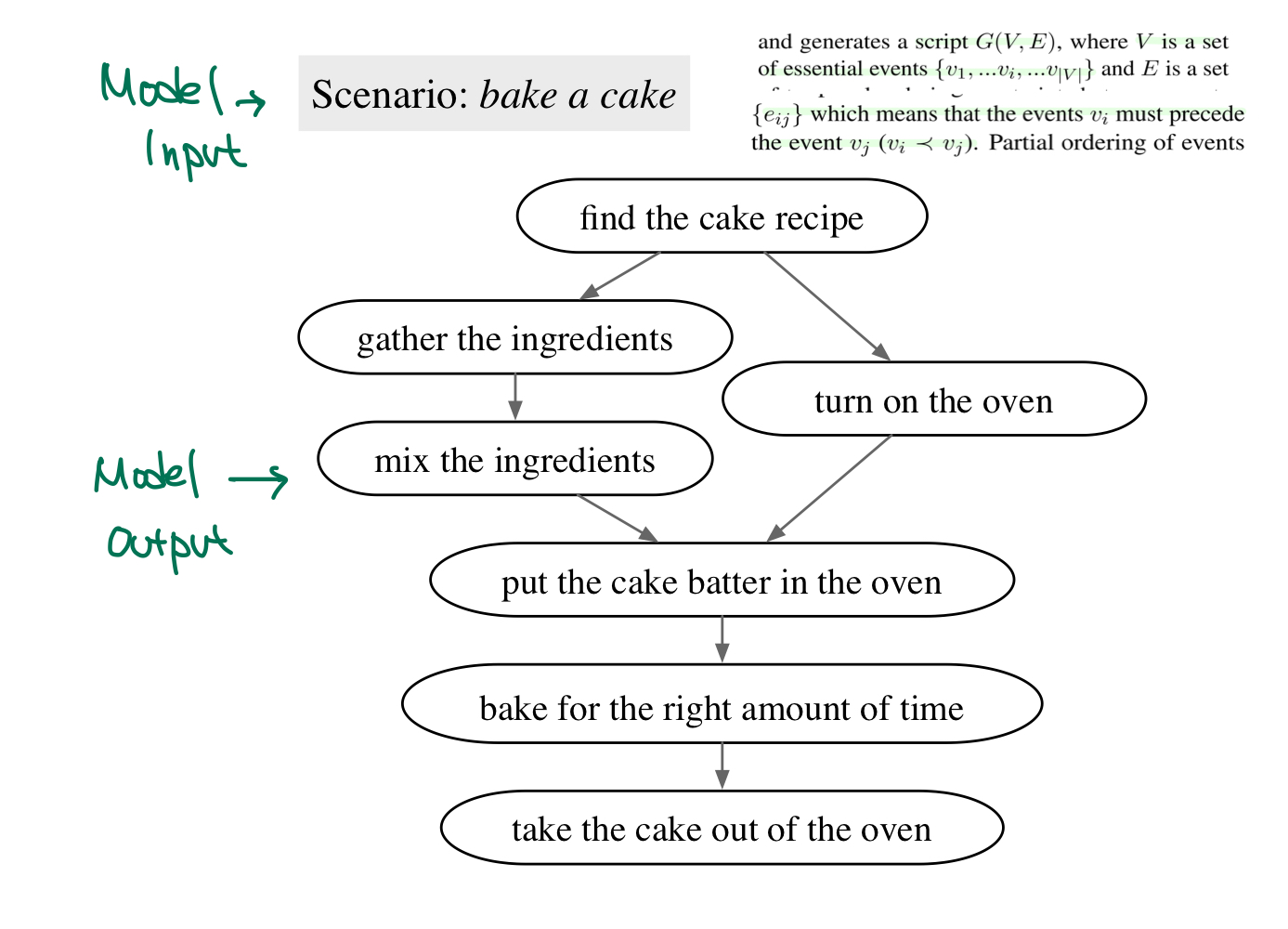
이전에 설명드린 것처럼 scipt description은 bake a cake 라는 Input을 가지고 이를 수행하기 위해 아래의 essential 한 event인 node와 event 발생 순서인 edge를 갖는 graph를 생성하는 문제입니다.
저자들은 위의 데이터셋에 T5-XXL로 훈련시킨 이라는 모델을 활용했으며, 이 모델은 output을 graph를 string format인 DOT format으로 생성합니다.
이 실험에서는 edit이 많이 필요하지 않는 output들에 대해서 FBNET을 훈련시켰다고 합니다.
4.2 Feedback Data Collection
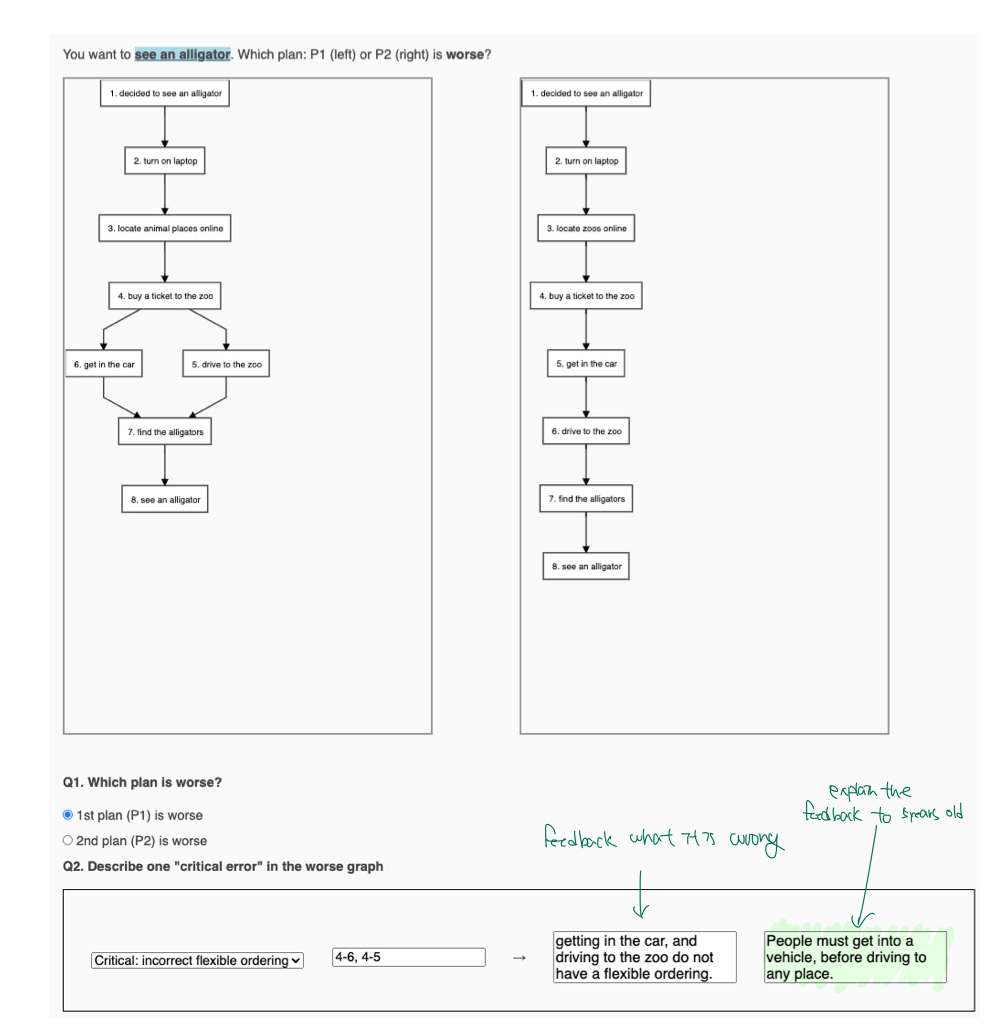
이 생성한 틀린 정답(좌)과 실제 gold label(우)를 활용해 위의 그림의 방법으로 저자들은 erroneous output을 수정할 feedback을 수집했습니다. 위의 장표에서 초록색으로 하이라이트 친 부분이 실제 실험에 활용된 feedback이라고 보시면 됩니다.
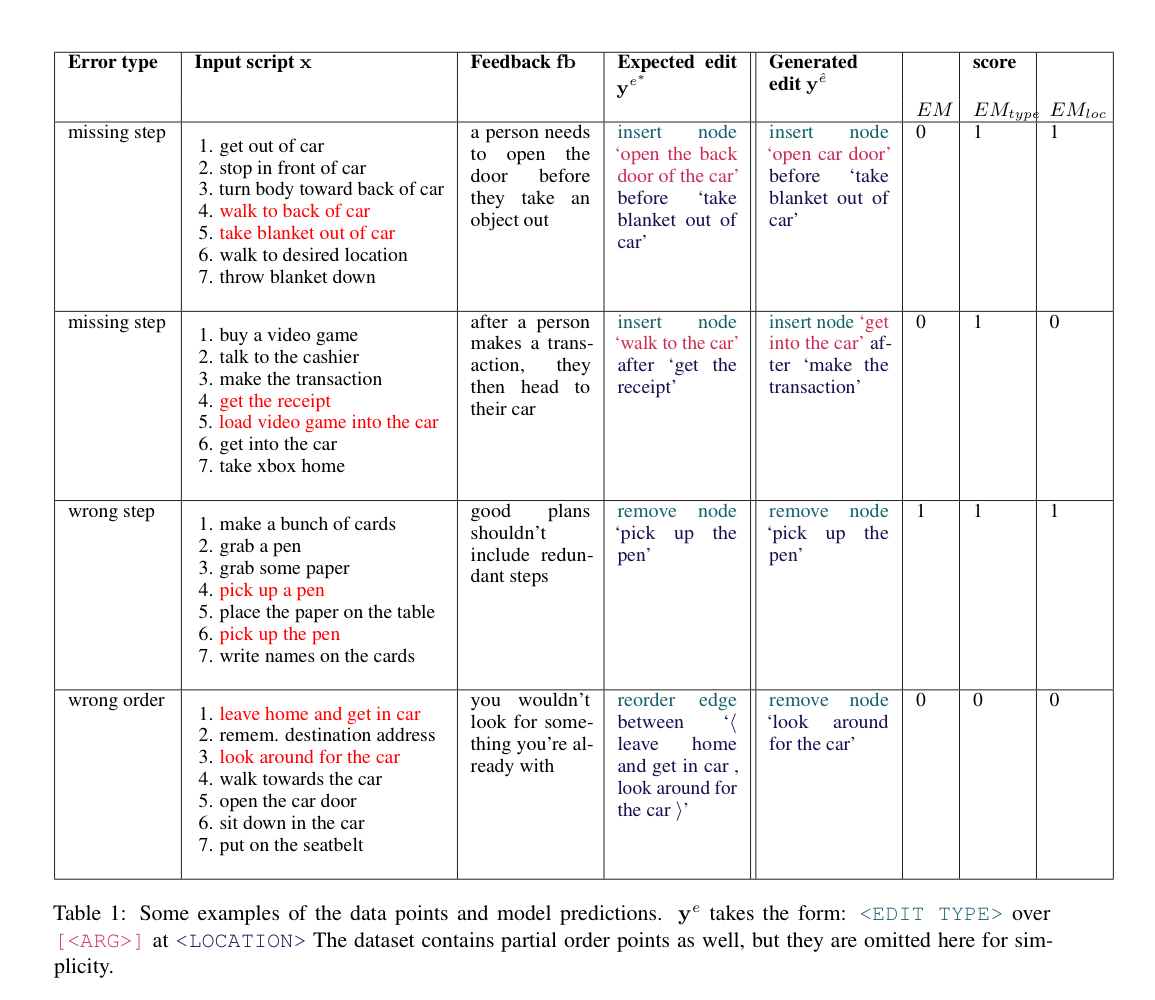
위의 장표가 실험결과이며, 각각의 metric에 대해서는 아래에 설명하도록 하겠습니다.
4.3 Training the Corrector Model
Corrector model G 는 마찬가지로 T5-XXL을 fine-tuning해서 활용하였고, memory 은 Bert-base Sentence Encoder를 활용했고, threshold를 0.9로 둔 cosine-similarity를 활용해 유사한 matchinc key를 retreive했습니다.
5. Experiments
Metric
위의 장표에도 나와 있듯 edit action 은 < Edit Type > over < ARG > at < Location > 을 따르는데, 전부 다 맞게 예측한 Exact Match, Type과 Location만 맞춘 Exact Match, 정답의 일부분만 맞추었는지 확인하는 BLEU와 ROUGE를 평가지표로 활용하였습니다.
Baseline
Baseline으로는 erroneous output 를 input으로 넣고 edit action 을 output으로 하도록 T5-XXL를 훈련했다고 합니다.
5.1 How well does FBNET interpret NL feedback?

Oracle Feedback을 활용할 경우, feedback을 활용하지 않을 때에 비해서 성능이 크게 향상된 것을 알 수 있습니다.
How consistently does FBNET interpret similar feedback?

동일한 pair에 대해서 re-phrase된 feedback이 주어져도 같은 edit 결과를 보여주는 것이 robust 관점에서 중요한데, 60% 정도는 feedback이 re-phrase되어도 동일한 y를 생성했다고 합니다.
또한 위의 장표에서 보시는 것처럼 동일한 y를 생성하지 못하는 것은 re-phrase된 feedback안에 있는 phrase(=node 이름)이 달라서 inconsistent하지 사실상은 같은 결과라고 볼 수 있다고 합니다.
How well can FBNET handle wrong feedback?
lexically 동일하지만 semantically하게 틀린 feedback을 넣어준 경우 EM이 3%대로 하락해 FBNET이 feedback의 퀄리티에 상당히 sensitive함을 보입니다.
How well does FBNET perform across error types?
특정 순서를 제거하거나 삽입하는 'parital order removal or addition'과 새로운 node를 추가하는 'generate missing node'의 EM이 각각 10.5, 2.73으로 여러 노드 간의 관계와 순서를 고려해야 하는 error는 많이 어려운 문제라고 합니다.
5.1.1 Error Analysis
test set에서 발생한 50개의 incorrect edit (EM=0)에 대해서 분석을 했다고 합니다.
Lexical Variation (36%)
Exact Match 특성상 정확히 일치해야 정답이라고 하기 때문에 'insert node picking a book...'이나 'insert node choosing a book to read.'는 사실상 같은 정답이어도 틀렸다고 평가했다고 합니다.
또한 'swapping the order of edges A and B'와 'swapping the order of edges B and A'도 틀렸다고 평가하면서 EM이 모델을 underestimate하는 경향이 있다고 주장합니다.
Challenging feedback (24%)
goal이 'go to loacker room'이고 B가 생성한 정답이 'walk to the locker room'을 반복한 상황에서 'yon can't go where you already are'과 같은 어려운 feedback이 전달될 경우 FBNET이 reorder edge between ‘⟨ walk towards the locker room , walk to the locker room ⟩’과 같은 잘못된 edit action을 생성하는 경향이 있다고 합니다.
Error not localized (20%)
goal이 'buy an xbox' scipt가 ' 1. go to the store 2. talk to the cashier 3. make the transaction 4. get the receipt 5. load the video game into the car 6. get into the car 7. take xbox home.'이고 feedback이 'after a person makes a transaction, they then head to their car.' 일 때 정답 edit은
'insert node ‘walk to the car’ after ‘get the receipt’' 인데 feedback에서 receipt를 확인하지 못해 node를 정확히 localize하지 못한 'insert node ‘get into the car’ after ‘make the transaction’'가 생성된 경우도 있다고 합니다.
Alternative answers (16%)
'insert node ‘X’ before ‘step 4’ '과 ''insert node ‘X’ after ‘step 3’ '는 둘다 같은 의미인데 EM은 틀리게 평가한다고 합니다.
위의 error analysis를 보고 느낀점은 아무래도 새로운 데이터셋과 테스크에 대한 사후 실험이기 때문에 정확한 metric이 없어서 EM을 썼는데, 이게 본인들이 제시한 프레임워크의 효용성을 명확히 보여주는데 많은 아쉬움이 있었던거 같습니다.
5.2 How well can FBNET learn from prior mistakes?

저자들은 72개의 test data에 대해서 perturbation을 주어 유사한 erroneous output들을 만들어 unseen한 erroneous output이 들어왔을때 유사한 feedback으로 올바른 edit action을 생성할 수 있는지를 확인하였습니다.
72개의 test data 중 20%는 inguistic perturbation을 (e.g., box > carton, package), 80%는 유사하지만 조금은 더 어려운 task를 만들어서 (e.g., bus → train, and how to lift blinds → how to open oven door because the event structure is analogical) 실험을 진행했다고 합니다.
위의 장표를 보면 gold feedback만큼은 아니지만 괜찮은 성능을 기록한 것을 볼 수 있습니다.
Continually learning using a memory of errors

위의 알고리즘을 바탕으로 실제 베포 환경에서처럼 unseen한 데이터에 대해서는 유사한 feedback으로 edit action을 생성하고, 생성된 edit action에 대해서 다시 user feedback을 받아 memory에 추가한 상황에서 실험한 결과는 아래와 같습니다.
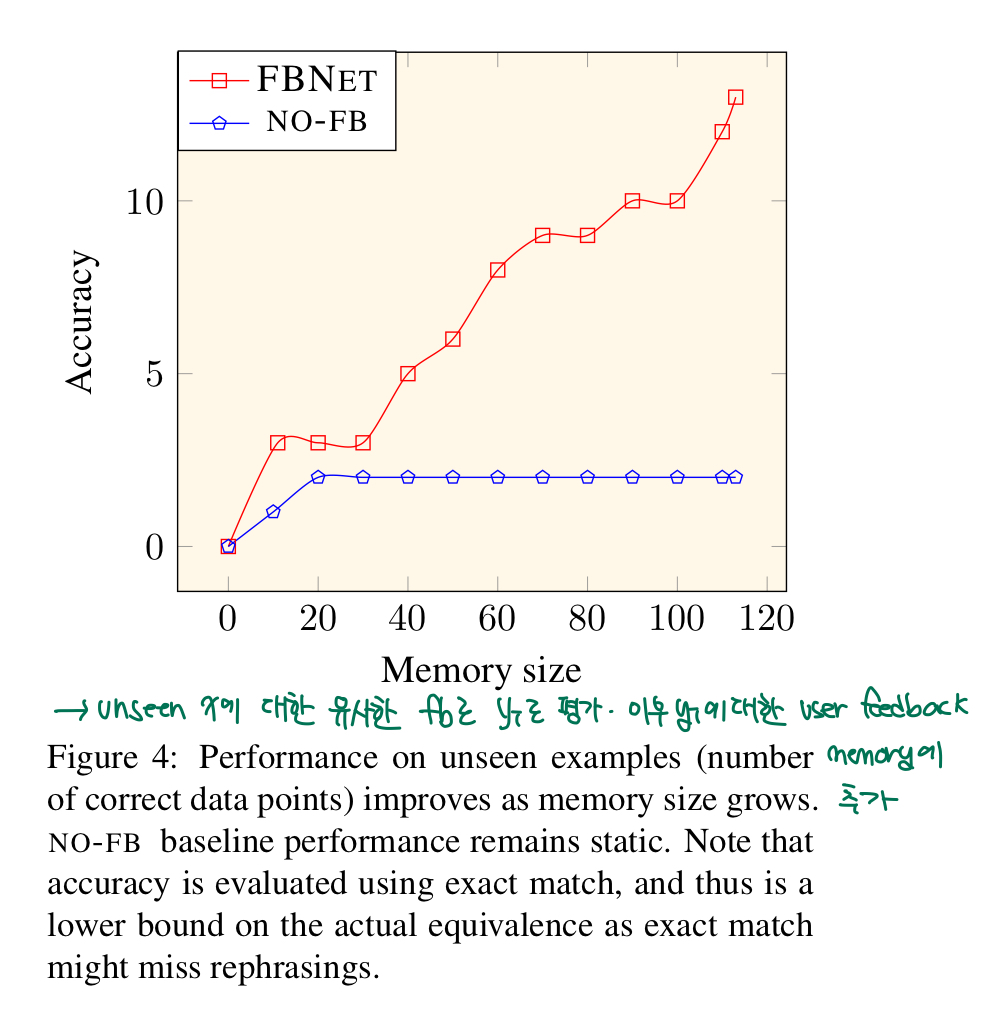
보시면 메모리가 추가될 수록 FBNET의 성능이 계속 좋아지는 것을 볼 수 있습니다.
6. Scope
저자들이 제시한 본 연구의 향후 적용방향성입니니다.
On Assumption A1
저자들은 erroneous output이 lexical하게는 옳지만 semantic하게 틀린 상황을 가정하고 실험을 진행하였습니다.
최근 LLM 모델들이 요약문 생성과 같은 task를 수행할 경우 fine-tuning시에 사용한 요약문의 lexical한 형태를 잘 따지만 내용은 inconsistent한 output을 생성할 때 본 연구에서 제시한 접근법이 좋은 해결책이 되어 보입니다.
On Assumption A2 & Consistent Memory
본 연구에서 저자들은 feeback을 받을때 worker들에게 5살 짜리 애기에게 설명하듯이 작성해달라고 요구했습니다.
또한 이전 실험에서도 보았듯이 잘못된 feedback은 no feedback보다도 성능이 저하되기 때문에 보다 범용적인 상황에서 유사한 error에 대해서 유사한 feedback을 가져오는 환경을 위해서는 보다 개선된 feedback db 구축에 대한 고민이 필요하다고 제시합니다.
Using Multiple Feedbacks
유사한 feedback을 retreive하는데 있어서 더 발전된 방법론 적용이 필요하다고 제시합니다.
