TSDAE : Using Transformer-based Sequential Denoising Auto-Encoder for Unsupervised Sentence Embedding Learning
Abstract
- 사전 학습된 transformer와 Sequential Denoising Auto-Encoder를 기반으로하는 새로운 SOTA 방법을 제안
- in-domain supervised 방법의 93.1%까지 성능 달성
- TSDAE는 강한 domain adaptation이면서 MLM같은 다른 방식들 보다 뛰어난 문장 임베딩을 위한 사전 학습 방식
- 이전 연구에서 가장 큰 문제점은 좁은 평가 방식을 사용했다는 것
- 대부분의 논문에서는 오직 STS만을 사용해 평가
- 하지만 STS는 도메인 지식이 필요하지 않음
=> 제안된 방법이 다른 도메인과 태스크에 일반화할 수 있는지는 불명확!
- 본 논문에서는 이러한 갭을 줄이기 위해 TSDAE와 비교 모델을 다양한 도메인에서 파생된 4가지 데이터셋을 사용해 평가
1 Introduction
-
Sentence embedding은 문장을 고정된 크기의 벡터로 인코딩하는 방식
- 단, 의미적으로 유사한 문장들을 서로 가깝게 맵핑하는게 핵심!
-
지금까지의 성공적인 방식들(InferSent, Universial Sentence Encoder, SBERT)은 보통 문장 임베딩 모델을 학습시키기 위해 라벨링된 데이터에 의존
-
이러한 한계를 극복하기 위해, 학습시 라벨링이 안된 코퍼스를 사용해 문장 임베딩을 학습하는 것을 제안
-
본 논문에서 제안하는 방식 : Transformer-based Sequential Denosiing Auto-Encoder(TSDAE)
- encoder-decoder 구조를 통해 이전 방법보다 뛰어남
- 학습시, corrupted sentence를 encode해서 고정된 크기의 벡터로 나타내고, decoder가 이러한 문장 임베딩에서 원래 문장을 reconstruct하도록 함
- 좋은 reconstruction quality를 위해서, 문장의 의미가 인코더로부터 문장 임베딩에 잘 담겨야 함
- inference에서는 오직 encoder만들 사용해서 문장을 임베딩
-
이전 비지도 방식의 치명적인 단점은 평가
- 주로 STS로 평가하는데, 뒤의 장표를 보면 이 방식이 충분한 평가 방식이 아니라는 것을 알 수 있음
- STS dataset는 도메인에 특화된 정보를 가진 문장을 포함하지 않아 해당 방식이 더 도메인 특화된 데이터에서 잘 될지는 불명확함
- STS는 인위적인 점수 분포를 가지고 있음
=> STS에 대한 성능과 다른 downstream task 성능은 상관관계가 없음
==> 결론적으로 STS 점수만 보고는 다른 task에서 얼마나 잘 될지 모름!!
-
이러한 문제를 해결하기 위해 TSDAE와 이전 비지도 문장 임베딩 방식들을 3가지 다양한 태스크(Information Retrieval, Re-Ranking과 Paraphrase Identification)에 비교
-
TSDAE의 경우 다른 SOTA 비지도 방식보다 6.4점정도 뛰어남
-
TSDAE는 같은 기준 혹은 USE-large와 같은 지도 모델보다도 뛰어남
-
TSDAE는 domain adaptation에서, 그리고 사전 학습 방식에서도 뛰어남
Contribution
-
기존의 SOTA방식보다 6.4점 정도 뛰어난 성능을 보이는 TSDAE를 제안
-
이를 입증하기 위해 다양한 도메인에 대한 여러 태스크에 대해 비지도 문장 임베딩 방식을 비교
-
TSDAE가 사전 학습과 domain adaptation방식으로 MLM을 포함한 다른 방식들보다 더 뛰어남
2 Related Work
Supervised sentence embeddings
- 문장간의 관계에 대한 정보를 제공하는 라벨을 활용
- 문장 임베딩은 문장 쌍의 유사도를 측정하는데에 사용되기 때문에, 보통 문장 간의 유사도를 라벨링
- 많은 연구에서 NLI(e.g. QA, conversational context dataset)가 문장 임베딩을 학습하는데에 성공적으로 사용될 수 있음을 밝힘
- 대표적으로 문장 임베딩 분야에서 사전 학습된 transforemr를 활용해 높은 성능을 달성한 모델이 Sentence-BERT
Unsupervised sentence embeddings
- 학습 동안 unlabeled corpus만 활용
- 최근에 다양한 training objectives와 pre-trained Transformer를 결합한 방식이 STS에서 SOTA를 달성
- Contrastive Tension(CT) : 단순히 동일한 문장을 positive example, 다른 문장을 negative example로 보고, 독립적인 2개의 encoder를 학습
- BERT-flow : Gaussian쪽으로 임베딩 분포를 debiasing하면서 모델을 학습
- SimCSE : contrastive learning을 기반으로 하고, 동일한 문장에 다양한 dropout mask를 적용한 것을 positive exmaple로 봄
==> 이러한 모든 방식은 독립적인 문장을 요구 - DeCLUTR : 문장 수준의 context를 활용하고 학습 시 긴 문서(적어도 2048 token)를 요구
==> 하지만 본 논문에서는 학습시 하나의 문장을 사용하는 방법만을 고려
- 대부분의 논문에서 STS로만 비교
- 비지도 방식이 STS에 대해 특정해 학습되지 않았어도 바로 사용할 수 있는 지도 사전 학습 모델보다 성능이 훨씬 나쁨
- STS에 대한 좋은 성능이 downstream task에 대한 성능을 보장하지 않음
3 Sequential Denoising Auto-Encoder
- Sequential Denoising Auto-Encoder(SDAE)는 머신러닝에서 유명한 비지도 방식이지만, 이를 문장 임베딩 학습을 위해 사전 학습된 transformer와 어떻게 결합시킬지는 명확하지 않음
- 본 논문에서 처음으로 TSDAE의 training objective에 대해 소개하고, TSDAE의 최적 configuration을 제공
3.1 Training Objective
- TSDAE는 입력 문장에 특정 유형의 노이즈(e.g. deleting or swapping words)를 더해서 손상된 문장을 고정된 크기의 문장 임베딩을 학습
- training objective는 다음과 같음
- D : training corpus
- : l개의 token을 갖는 입력 문장
- : 손상된 문장
- : 의 문장 임베딩
- : size of vocabulary
- : hidden state at decoding step
- 원래 transforemr encoder-decoder setup과의 큰 차이는 decoder에서 이용 가능한 정보!
- 우리의 decoder는 encoder에서 만들어진 오직 제한된 크기의 문장 표현만(e.g. [CLS] token) 사용해 decode함
=> encoder에서 모든 contextualized word embedding을 사용하지 않음
=> bottleneck를 야기시켜 encoder가 유의미한 문장 표현을 만들도록 함
3.2 TSDAE
-
TSDAE의 모델 구조는 문장 임베딩만을 cross-attention의 key와 value로 사용
-
modified cross-attention을 식으로 나타내면 다음과 같다
- : 번째 레이어에서 decoding step안의 decoder hidden state, 는 sentence embedding의 크기
- : sentence embedding vector를 포함하는 one-row matrix
- : 각각 query, key, value를 나타냄
-
STS에 대해 다양한 실험 결과, 최적의 조합은 다음과 같음
- deletion을 input noise로, deletion ratio를 0.6으로 설정
- [CLS] token의 결과를 고정된 크기의 문장 표현으로 사용
- 학습 시 encoder와 decoder 파라미터를 묶음
- noise type과 noise ratio에 따른 성능 차이
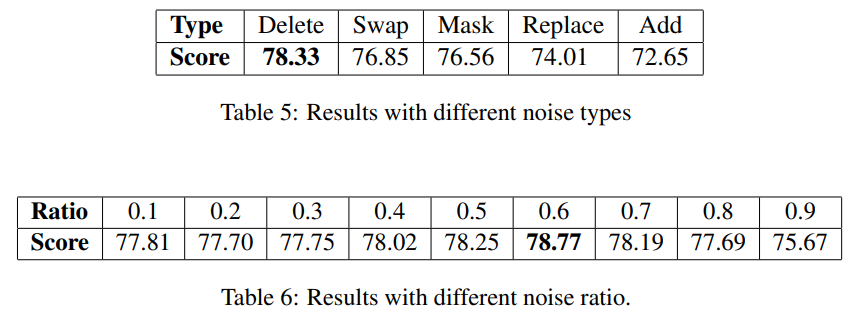
- mean pooling, max, cls에 따른 성능 차이
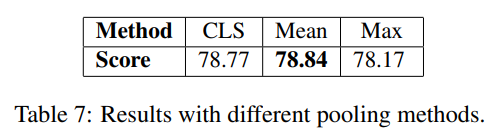
4 Evalution
-
STS dataset에 대한 평가 만드로는 다른 task에 대한 성능을 보장할 수 없음
- STS는 domain 특화 정보를 요구하지 X
- 유사한 쌍, 유사하지 않은 쌍에 대한 분포가 인위적
(현실에서는 dissimilar한 경우가 훨씬 더 많음) - STS에서는 dissimilar와 similar에 대한 rank를 둘다 잘해야 성능이 높지만, 현실에서는 similar에 대한 rank가 더 중요
-
또한, 비지도 학습을 평가하는 경우 몇몇 라벨링된 데이터가 존재하는 것을 무시
- 많은 경우에서, 특정한 task 혹은 유사한 task에 라벨링된 데이터가 존재함
==> 좋은 방식은 몇몇 라벨링된 데이터가 이용 가능할 때도 성능이 나와야 한다.
- 많은 경우에서, 특정한 task 혹은 유사한 task에 라벨링된 데이터가 존재함
-
다음과 같은 3가지 setup에서 비지도 문장 임베딩을 평가
- Unsupervised Learning : target task에서 라벨링 되지 않은 문장들을 가지고 있다 가정하고, 이러한 문장들을 기반으로 우리의 방법을 적용
- Domain Adaptation : NLI와 STS에서 라벨링된 문장과 target task에서 라벨링되지 않은 문장을 가지고 있다고 가정하고 2가지 방법으로 학습
1) NLI+STS data로 학습한 후 target domain에 대해 학습
2) target domain에 대해 학습한 후 NLI+STS data로 학습 - Pre-Training : target task에 대해 라벨링되지 않은 대량의 코퍼스와 target task에 대해 소수의 라벨링된 문장이 있다고 가정
4.1 Datasets
다양한 도메인에서 다양한 task(Re-Ranking, Information Retrieval, Paraphrase Identification)에 대한 3가지 setting을 평가
- AskUbuntu(RR task)
- 기술 포럼 AskUbuntu에서 user post 모음
- 모델은 20개의 후보 질문을 주어지는 input post와 유사한 순으로 다시 ranking해야함
- 평가는 Mean Average Precision(MAP) 사용
- CQADupStack(IR task)
- Stack-Exchange에서 다양한 토픽에 대한 forum post로 구성된 question retrieval dataset
- 세부적으로 12개의 포럼(수학, 영어, 안드로이드, 프로그래머, 통계 등)을 가짐
- 모델은 큰 후보풀에서 중복되는 질문을 찾아내야함
- 평가 지표는 MAP@100
- 모든 포럼에 대해 하나의 모델을 학습
- TwitterPara(PI task)
- 2개의 유사한 데이터셋으로 구성됨 : Twitter Paraphrase Corpus, Twitter News URL Corpus
- 데이터셋은 트윗 쌍으로 구성되어 있고, 그 문장쌍이 paraphrase되었는지에 대한 점수가 라벨링되어 있음
- 평가 지표는 모델이 계산한 유사도 점수와 정답 confidence socre에 대해 Average Precision(AP)
- SciDocs(RR task)
- scientific 논문에 대한 여러 task로 구성된 벤치마크
- 우리 실험에서는 Cite에 관한 task를 사용
- 즉, 주어진 논문 제목에 대해 자주 co-cited/-read/-viewed되는 논문들을 찾는것
- 논문 제목 하나가 query로 주어지면, 모델은 논문 제목 후보 30개 중에서 5개의 관련 논문 제목을 식별
- negative example는 랜덤하게 선택됨
- 평가 지표는 MAP
평가에서, 문장들은 우선 고정된 크기의 벡터로 인코딩되고, 문장 유사도를 계산하기위해 코사인 유사도 사용
또한, 세부 task로 나뉘는 데이터셋의 경우 각 세부 task에 대한 점수를 평균내 final score로 사용
5 Experiments
- TSDAE를 다른 비지도 모델, out-of-the box supervised pre-trained model(라벨링된 데이터로 학습한 후에 domain 특화된 데이터셋으로 평가)과 비교
- 비교군으로는 CT, SimCSE, BERT-flow 사용(각 논문에서 제안된 하이퍼파라미터 사용)
- BERT-base-uncased를 base Transformer model로 사용
- 랜덤성을 줄이기 위해 5개의 random seed에 대해 평균냄
5.1 Baseline Methods
- Glove : 일반적인 도메인에서 큰 코퍼스에 대해 학습된 단어 임베딩을 평균내서 문장 임베딩으로 사용
- Sent2Vec : bag-of-word모델이지만 in-domain unlabeled corpus에 학습됨
- BERT-based-uncased with mean looling
- Universial Sentence Embedding(USE) : NLI와 community question answering을 포함한 여러 지도 데이터셋에 대해 학습됨
- SBERT-base-nil-v2 : SNLI+MultiNLI data에 대해 Nultiple-Negative Ranking Loss(MNRL)을 사용해서 학습됨
- SBERT-base-stsb-v2 : STS bench-mark train set에 대해 MSE로 학습됨
- BM25 : Elasticsearch를 사용
비지도 방법의 상대적인 성능을 더 잘 이해하기 위해, SBERT모델을 in-domain supervised maner로 학습시켜서 이 점수를 upper bound로 봄
AskUbuntu, CQADupStack, SciDocs에 대해서는 상대적인 문장 비교가 라벨링되어 있으므로 in-domain SBERT모델을 MNRL로 학습
MNRL는 in-batch negatives에서 cross-entropy loss
: 연관 있는 문장 쌍의 배치 에서 MNRL는 라벨링된 문장을 postivie로, 다른 배치안의 조합을 negative로 봄
- : 벡터들에 대한 특정 유사도 함수
- : 문장을 임베딩하는 문장 인코더
ex) TwitterPara에서는 관련도 점수가 라벨링되고, in-domain 모델 학습 시 MSE loss를 사용
5.2 MLM
- Masked-Language-Model(MLM)은 BERT에서 소개된 fill-in-the-blank task
- 입력값을 마스킹하고 tarsforemr가 마스킹된 단어를 찾도록 함
- 문장 임베딩을 계산하기 위해, output token embedding의 mean-pooling을 사용
5.3 Contrastive Tension(CT)
-
CT는 contrastive-learning fashion에서 사전학습된 Transformer를 파인튜닝
-
각 문장에 대해서, 같은 문장을 관련 문장으로, K개의 랜덤 문장을 샘플링해서 관련 없는 문장으로 보고 binary cross-entropy를 구축
-
학습 과정을 안정화하기 위해, 각 문장 쌍 에 대해, CT는 같은 초기값에서 시작한 두 개의 독립적인 encoder()를 사용
-
이를 수식으로 나타내면 다음과 같음
-
여기서 는 문장 a가 b와 동일한지를 나타내고, 는 Logistic function을 나타냄
-
간단한 수식에도 불구하고, CT는 STS에서 SOTA 비지도 성능을 달성
5.4 SimCSE
- CT와 유사하게, SimCSE는 같은 문장을 postivie examples로 봄
- 주요한 차이는 SimCSE는 다양한 dropout mask를 샘플링해서 embedding-level positive pair를 생성하고, in-batch negatives를 사용
- 이와 같이, learning objective는 동일하지만, encoder를 공유하고, MNRL-loss를 사용
5.5 BERT-flow
- 사전학습된 transformer의 파라미터를 파인튜닝하는 것 대신, BERT-flow는 distribution debiasing를 통해 이러한 사전 학습된 모델에 의해 인코딩된 의미 정보를 완전히 활용하는 것을 목표로 함
- BERT-flow의 논문에서는 BERT 단어 임베딩이 단어 빈도수와 높은 연관성이 있다고 주장하고, 이는 차례로 MLM을 통해 hidden state에 영향을 끼침
- 결국, 이러한 hidden state에 대한 pooling으로 생성된 문장 임베딩을 편향될 수 밖에 없음
==> 이를 해결하기 위해, BERT-flow는 편향된 문장 임베딩을trainable flow network 에 넣고, BERT model의 파라미터는 유지한 채로 표준 정규 분포에 fiting해 debiasing - training objective는 다음과 같다
- u : biased embedding of sentence x
- : deviased sentence embedding with follows a standard Gaussian distribution
- BERT-flow는 transformer의 파라미터를 업데이트하지 않으므로, 본 논문에서는 BERT-flow에 대해 unsupervised learning과 domain adaptation NLI+STS -> target task에 대한 점수만 보고
- 하지만, 우리가 사용한 다른 평가 setup과는 적합하지 않아 실험하지 않음
6 Result

Unsupervised learning
- TSDAE가 이전 최고 방법(CT)보다 최대 6.4점, 평균적으로 2.6점 높음
- MLM방식이 STS에서는 성능이 안좋지만, 다른 최근 방식(CT, SimCSE, BERT-flow)에서는 2번째로 좋음
- TSDAE와 MLM모다 input에서 단어를 제거해서 네트워크가 robust embedding을 만들도록 함
- 반대로, CT와 SimCSE의 input sentence는 수정되지 않았기 때문에, 덜 stable embedding한 결과를 냄
- 또한, 본 실험에서 out-of-the-box pretrained models(SBERT-base-nli-stsb-v2와 USE-large)의 경우 domain-specific fine-tuning없이 최근에 제안된 비지도 학습 방법을 뛰어 넘는 좋은 성능을 보임
Domain Adaptation
- 모든 비지도 방식에 대해서, target domain에 대해 먼저 학습하고, 이후에 라벨링된 NLI+STS를 사용해서 학습했을 때 더 좋은 결과를 냄
- 모든 방식에 대해, target domain에 대해서만 학습했을 때보다 더 높은 성능을 보임
- 평균적으로, TSDAE에선 1.3점 향상, MLM에선 3점 향상, CT에선 0.6점 향상, SimCSE에선 1.8점 향상
- CT와 SimCSE는 이 환경에서는 out-of-the-box model SBERT-base-nli-stsb-v2보다 약간 높은 성능을 기록
Pre-training
-
평가된 방식의 사전 학습 성능을 비교
-
이용가능한 모든 unlabled sentence에 대해 사전학습을 하고,다양한 unlabseled training set size에 따른 in-domain supervised training성능을 비교
-
평가에 기록된 점수는 development set 기준

-
TSDAE가 MLM보다 AskUbuntu를 제외한 모든 데이터셋에서 훨씬 뛰어남
-
라벨링된 학습 데이터의 크기가 커져도 TSDAE가 일관되게 뛰어남
-
결론적으로, TSDAE가 pre-training방법으로 뛰어나고, 더 큰 학습 데이터셋에서도 성능이 크게 향상됨
-
CT와 SimCSE의 경우 pre-training에서 뛰어나지 않음.
6.1 Result on STS data
-
Wikipedia에서 문장을 샘플링해서 BERT-base-uncased모델을 다양한 비지도 학습 방법을 사용해 학습
-
아래 표를 보면 다양한 domain specific dataset에 대한 평균 성능과 STS test set에 대한 성능이 나타나 있음
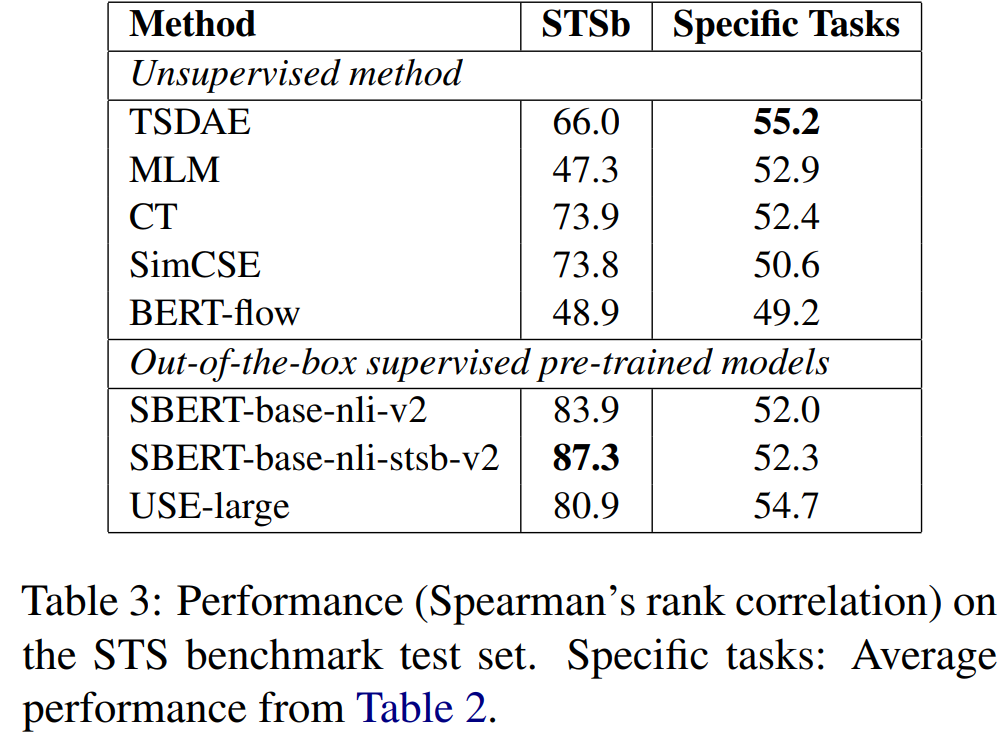
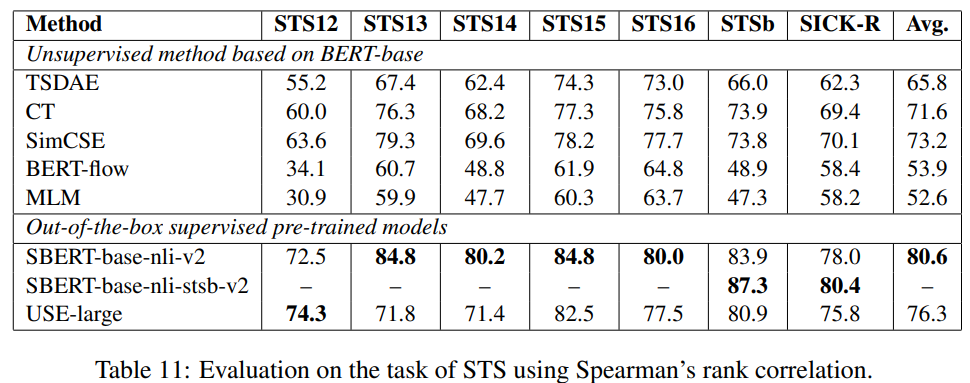
-
STS test set에 대한 성능과 domain specific dataset에 대한 성능이 일관되지 않음을 알 수 있음
- STS에 대해선 CT와 SimCSE가 뛰어나지만, domain-specific real-world task에서는 TSDAE와 MLM이 뛰어남
-
결론적으로, STS data에 대한 높은 성능이 domain-specific task에 대한 좋은 성능을 나타내진 않음
7 Analysis
- 얼마나 많은 학습 문장이 필요한지, 관련 있는 context words가 인식하는지를 분석
- TwitterPara를 제외한 모든 데이터셋에 대해서, development set을 바탕으로 분석
- TwitterPara의 경우, test set을 사용(공식적으로 dev set이 나뉘어 있지 않음)
7.1 Influence of Corpus Size
- 특정 도메인에서, 충분한 수의 문장을 얻는 것이 어려울 수 있음
- 그러므로, 적은 데이터로도 좋은 문장 임베딩을 만드는 것이 중요
- 이를 위해, 다양한 크기의 corpus(128~65536문장)에 대해 비지도 방식을 학습
- 각 실험에서 bert-base-uncased모델을 10epoch, 100 training setp까지 학습
- 모델은 각 epcoh의 끝에서 평가되고, development set에 대해 가장 좋은 점수가 기록됨
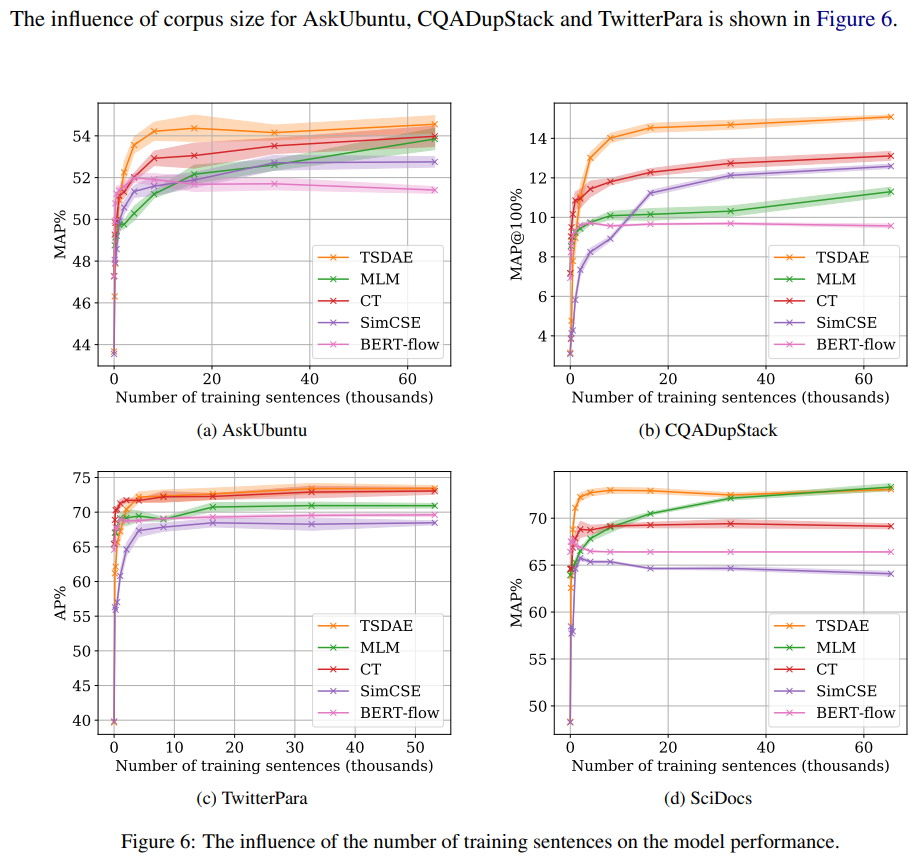
- TSDAE가 이전 비지도 방식보다 1000개의 unlabeled sentence만으로도 거의 뛰어남
- 10K의 unlabled sentences에서, downstream성능은 일반적으로 모든 비지도 방식에 대해 수렴
- CQADupStack에 대해서만 데이터가 많으면 많을수록 도움이 됨
- CQADupStack의 경우 다양한 주제에 대한 글로 구성되어 있으므로 unlabled data가 더 필요한 것으로 여겨짐
- 특정 도메인으로 사전 학습된 트랜스포머를 파인튜닝 하려면 비교적으로 10K 문장의 unlabeled data가 필요한 것으로 보임
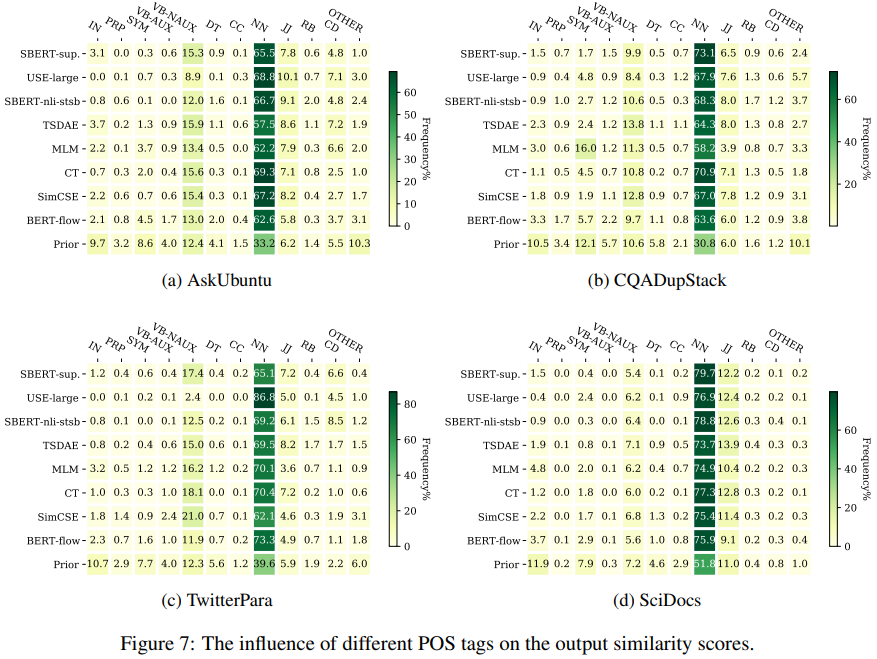
7.2 Relevant Content Words
-
모든 종류의 단어가 문장의 의미를 결정하는데 큰 역할을 하지 않음
- nouns가 문장에서 가장 중요한 content words인 경우가 있음
- 반대로 preposition의 경우 덜 중요, context가 크게 변하지 않으면서 문장에서 빠지거나 더해질 수 있음
-
이번 세션에서는 어떤 단어 종류가 다양한 문장 임베딩 방법에서 가장 relevant한지, 즉, 어떤 단어가 문장 쌍을 유사하다고 판단할 때 큰 영향을 끼치는지에 대해 분석한다
-
이를 위해, 관련 있다고 라벨링 된 문장 쌍 을 선택해 (a,b)에 대한 코사인 유사도 점수를 가장 크게 감소시키는 단어를 찾음
(즉, w가 없으면 유사도가 크게 떨어지는 w를 찾음)
-
이후, 에 대한 POS tag를 기록(CoreNLP사용)하고, 모든 문장 쌍에 대한 POS tag의 분포를 계산
-
아래 결과를 보면, 4개의 데이터셋에 대해 평균한 값이 나타나 있음
-
POS tagging에 대한 in-domain supervised model(SBERT-sup)와 prior distribution를 비교해봤을 때, NN이 문장에서 가장 관련 있는 content word라는 것을 알 수 있음.
-
반면에, Preposition(IN)과 determiniator(DT)와 같은 function word는 모델 예측에서 가장 적은 영향력을 끼친다는 것을 알 수 있음
-
학습 방식마다 POS tagging 분포 차이는 거의 없음
- 즉, 비지도 학습 방식의 경우, 라벨링된 데이터가 없어도 문장에서 어떤 종류의 단어가 중요한지 학습할 수 있다는 것
- 단점으로는, 비지도 방식은 명사가 가장 중요하지 않은 task에서는 문제가 될 수 있음
8 Discussion
- 본 논문에서는 사전 학습된 transformer encoder를 가지고 실험
- 단일 encoder외에, BART, T5와 같은 사전학습된 encoder-decoder 모델도 존재
- 그러나, 이미 일반적인 도메인에 대해 다양한 auto-encoder loss로 학습되었기 때문에, reconstruction behavior에 overfitting될거라 생각
- 이를 증명하기 위해, BART-base와 T5-base model을 TSDAE로 4가지 domain specific dataset에 대해 학습

- T5와 BART 모두 Scratch보다 평균적으로 낮은 성능을 보임
- TSDAE는 single encoder checkpoint에서 시작하는 것이 overffiting을 피하면서 사전 학습된 정보를 활용할 수 있어 더 적합하다는 결론
9 Conclusion
- 사전 학습된 트랜스포머에 기반한 새로운 비지도 문장 임베딩 학습 방법인 TSDAE(Transformers and sequential denoising auto-encoder)를 제안
- TSDAE와 최근의 다양한 SOTA비지도 학습 방법을 4개의 다양한 도메인, 다양한 task를 가진 데이터셋으로 3가지 다양한 환경에서 평가 : unsupervised learning, domain adaptation, pre-training
- TSDAE가 다양한 환경, 데이터셋에서 다른 방법보다 뛰어남
- 현재 비지도 문장 임베딩 학습 방식을 평가하는 방법이(STS 점수만 주로 활용) 충분하지 않음을 보임
- STS에 대한 성능과 다른 특정 task에서의 성능은 상관관계가 없음
