Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (FiD)
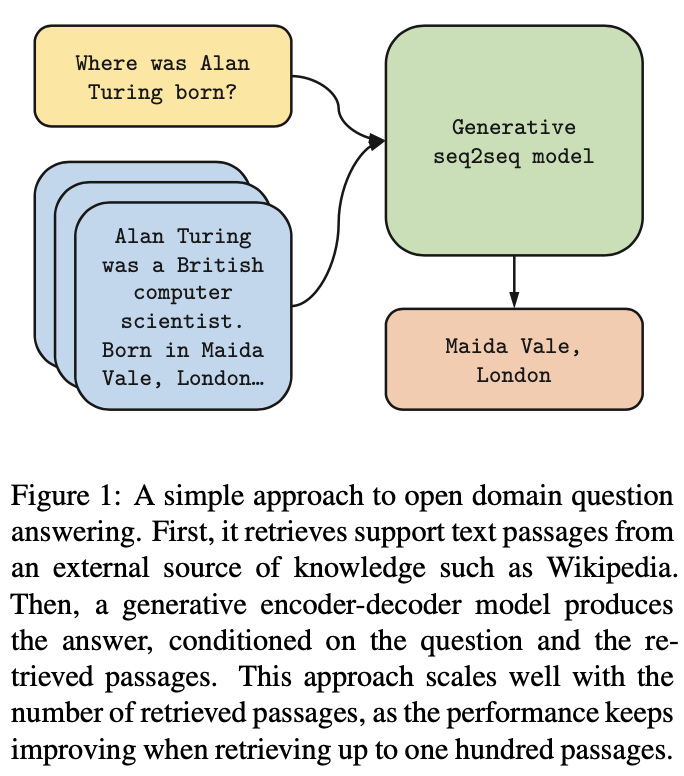
1. Introduction
LLM(Large Langauge Model)들이 factual한 정보들을 담는 능력이 여러 연구에서 확인됨에 따라 open-domain question answering에서도 external knowledge 없이 LLM이 parametrized한 정보를 바탕으로 괜찮은 성능을 내는 연구 경향이 나타나기 시작했습니다.
하지만 현실적으로 다양하고 정확한 factual 정보를 가지고 있는 LLM을 학습하기에는 상당한 비용이 필요하며, 그러한 LLM을 통해서 query를 만드는 것도 많은 메모리가 필요하죠.
이에 따라 이전에 소개드린 RAG와 같이 Question(=Query)를 가지고 supportive한 document를 retreive한 다음, Question과 각각의 Supportive Document를 가지고 정답을 생성한 모델들이 나오기 시작했죠.
기존의 RAG는 Encoder에서 Question과 모든 Document들을 concat해서 처리하는 방식이었는데, 이러한 처리는 상당한 수준의 메모리를 요구하죠. (Self-Attention in Encoder Layer)
FiD는 Encoder에서 Question과 모든 Document들을 한번에 concat해서 처리하지 않고 ([question: question statement. context01: context01 statement. context02 : context02 statement. ... ]), Question과 각각의 Supportive Document를 따로 concat해서 처리하고 [question: question statement. title01: title of context01. context01: context01 statement], [question: question statement. title02: title of context02. context02: context02 statement] ...), 이를 decoder에서 fusion하는 간단한 방식를 통해 각종 ODQA에서 SOTA를 달성했습니다.
그래서 모델이 이름도 Fusion-in-Decoder이라고 명명된거 같네요.
2. Related Work
Open Domain Question Answering
Open Domain Question Answering은 다양한 주제에 대한 대량의 문서 집합으로부터 질문에 대한 답을 해주는 문제입니다. 특히 Model의 Input안에 Answer Span이 없는 경우, 이를 어떻게 처리할 것인가가 해당 task의 가장 key라고 여겨집니다.
Passage Retrieval
결국 Open Domain Question Answering에는 질문에 대한 정답을 하기 위해 질문과 높은 연관성을 보이는 supportive document들을 retrieve하는게 중요합니다.
초기에는 sparse representation인 TF-IDF으로 question과 document를 임베딩한 후에 BiLSTM을 활용해 supervised learning의 형태로 supportive document들을 retrieve하는 방식이 많이 활용되었다고 합니다.
최근에는 BERT를 비롯한 PLM을 활용해 dense representation을 얻은 뒤에, 내적기반의 유사도를 활용해 supportive document들을 retrieve하는 방식이 주로 활용됩니다. (FAISS)
Generative Question Answering
NarrativeQA라는 데이터셋에서 제안하는것처럼 말그래도 answer을 extract하는게 아니라 생성해야하는 문제입니다. 즉 Supportive Document에 answer span이 없는 것을 의미합니다.
GPT와 RAG에서 abstractive generation model들이 이러한 문제에서 좋은 성능을 보였죠.
3. Method
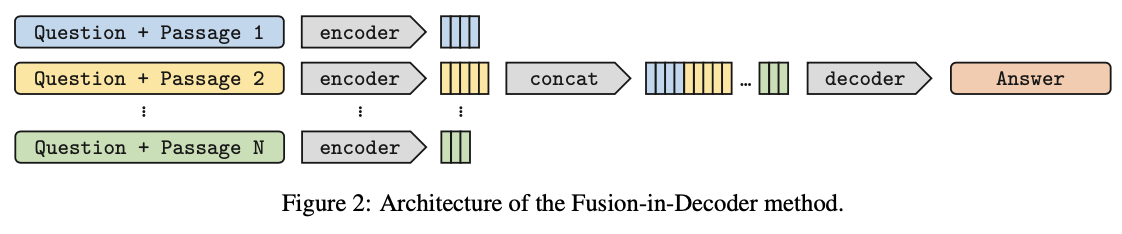
Retrieval
- BM25 (TF-IDF)
Question과 Passage들을 bag-of-word들로 embedding하고 tf-idf기반으로 supportive document들을 retrieval하는 방법입니다.
- DPR (BERT & COSINE SIMILARITY)
이전 RAG에서 설명드린것처럼 Question과 Passage들을 BERT에 통과해 [CLS] 임베딩을 구한 후 내적을 통해 supportive document들을 retrieval하는 방법입니다.
저자들이 conclusion에 'We also plan to integrate the retrieval in our model, and to learn the whole system end-to-end.' 라고 언급한 것으로 보아 retrieval단에는 gradient를 흘려서 학습한 것으로 보이지는 않습니다.
Reading (Fusion-In-Decoder)
Supportive Document들이 retreive된 후에는 각 supportive document들을 아래와 같은 prefix를 주어 독립적으로 encoder에 통과시킵니다.
[question: question statement. title: title of supportive document context: context of supportive document.]
따라서 100개의 supportive document들이 있으면 총 100번 encoder forwarding을 하는 것이죠. (아래 코드를 통해 다시 한번 설명드리겠지만, 실제로는 트릭을 좀 이용하였습니다.)
이렇게 통과된 encoder hidden representation을 decoder에 넘겨줌으로써 decoder는 정답 문장을 생성하면서 모든 supportive document에 attention을 가할 수 있게 됩니다.
따라서 자연스럽게 question의 정보가 중복되어서 활용됨을 알 수 있습니다.
아래는 페이스북에서 제공한 공식 코드(FiD Official Code)를 바탕으로 실제 FiD가 어떻게 mulitple encoder forwarding을 구현했는지 정리해보았습니다.
실제 training command line은 아래와 같습니다.
python train_reader.py \
--train_data train_data.json \
--eval_data eval_data.json \
--model_size base \
--per_gpu_batch_size 1 \
--n_context 100 \
--name my_experiment \
--checkpoint_dir checkpoint \배치마다 1개의 question을 처리합니다.
그리고 실제 FiD Model 코드를 보면 아래와 같은 코드가 있는데,
class FiDT5(transformers.T5ForConditionalGeneration):
def __init__(self, config):
super().__init__(config)
self.wrap_encoder()
def forward_(self, **kwargs):
if 'input_ids' in kwargs:
kwargs['input_ids'] = kwargs['input_ids'].view(kwargs['input_ids'].size(0), -1)
if 'attention_mask' in kwargs:
kwargs['attention_mask'] = kwargs['attention_mask'].view(kwargs['attention_mask'].size(0), -1)
return super(FiDT5, self).forward(
**kwargs
)
# We need to resize as B x (N * L) instead of (B * N) x L here
# because the T5 forward method uses the input tensors to infer
# dimensions used in the decoder.
# EncoderWrapper resizes the inputs as (B * N) x L.
def forward(self, input_ids=None, attention_mask=None, **kwargs):
if input_ids != None:
# inputs might have already be resized in the generate method
if input_ids.dim() == 3:
self.encoder.n_passages = input_ids.size(1)
input_ids = input_ids.view(input_ids.size(0), -1)
if attention_mask != None:
attention_mask = attention_mask.view(attention_mask.size(0), -1)
return super().forward(
input_ids=input_ids,
attention_mask=attention_mask,
**kwargs
)Encoder 자체는 1개의 (x,y) pair, 그리고 x에는 100개의 question, supportive document의 concatenation이 존재하는데, 모델 자체의 입력으로는 (Batch, # of Document * Length of Document)로 들어가나
class EncoderWrapper(torch.nn.Module):
"""
Encoder Wrapper for T5 Wrapper to obtain a Fusion-in-Decoder model.
"""
def __init__(self, encoder, use_checkpoint=False):
super().__init__()
self.encoder = encoder
apply_checkpoint_wrapper(self.encoder, use_checkpoint)
def forward(self, input_ids=None, attention_mask=None, **kwargs,):
# total_length = n_passages * passage_length
bsz, total_length = input_ids.shape
passage_length = total_length // self.n_passages
input_ids = input_ids.view(bsz*self.n_passages, passage_length)
attention_mask = attention_mask.view(bsz*self.n_passages, passage_length)
outputs = self.encoder(input_ids, attention_mask, **kwargs)
outputs = (outputs[0].view(bsz, self.n_passages*passage_length, -1), ) + outputs[1:]
return outputsEncoder를 wrapper로 묶어서 실제 Batch는 1이지만 Encoder를 통과할 때 차원을 (Batch * # of Document, Length of Document)로 변경시켜서 통과해 Encoder를 통과할 때는 실제 # of Document만큼 병렬처리가 되고 나온 output은 다시 (Batch, # of Document * Length of Document, # of hidden-dim)으로 변경해 decoder에 던져줌으로써 모든 supportive document에 대해서 cross attention이 걸리도록 합니다.
4. Experiments
Dataset
Dataset으로는 NaturalQuestions, TriviaQA, SQuAD v1.1을 활용하였습니다.
Experimental Settings
Evalutation Method는 모델이 생성한 정답을 정규화한 이후 해당 정답이 acceptable answers가 포함된 list에 잇는 경우 correct를 주는 exact match (EM)을 활용하였습니다.
Backbone으로는 T5-base와 large를 활용하였고, Fine-tuning시에 스케줄러를 활용하지 않고 constant lr을 쓰는게 개인적으로 신선했습니다.
각각 데이터셋마다 10K의 gradient step으로 학습을 진행하였습니다. (gradient accumulation 썼다는 말이겠죠..?)
Training과 Test시에 모두 100개의 supportive document를 활용하였고, 각 document들은 250 토큰으로 절사해서 사용하였다고 합니다.
NQ와 TriviaQA에는 DPR (dense representation), SQUAD에는 BM25 (sparse representation)을 활용하였습니다.
Comparasion to SOTA
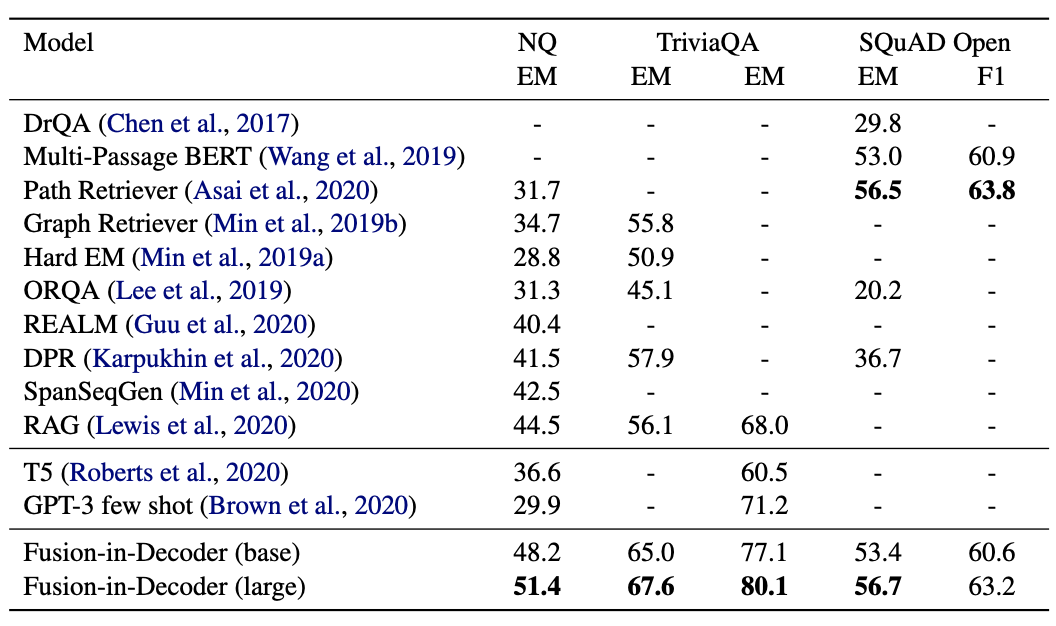
supportive document들을 활용한 generative model의 성능이 extractive model들보다 좋은 성능을 보였습니다.
이 실험을 통해 최소 Open Domain QA에서 만큼은 Encoder로 가능한 많은 passage들을 encoding하고, decoder의 cross attention에서 이를 fusion하면서 정답을 생성하는게 좋은 성능을 보이는 것을 알 수 있습니다.
특히 저자들은 T5-Large와 T5-base를 backbone으로 하는 FiD 둘다 비슷한 메모리를 사용하지만 성능의 차이가 큰 것을 지적하면서 차라리 메모리를 더 쓸꺼면 모델의 크기가 작더라도 encoder에서 정보를 다양한 태우는 것을 추천합니다.
Scaling with number of passages
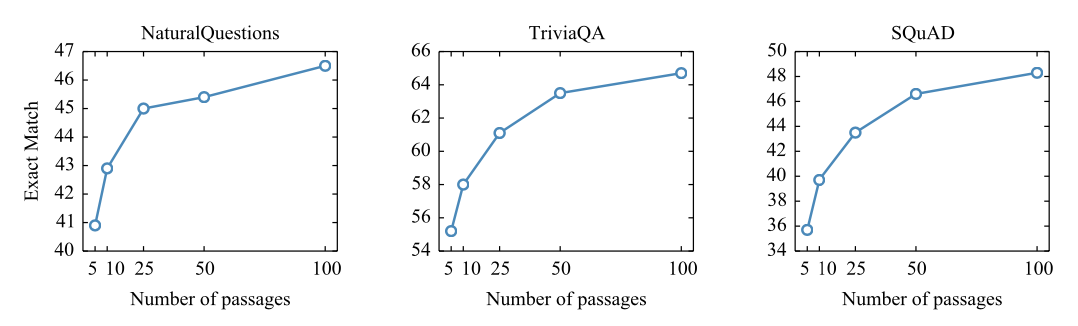
3 데이터셋에서 모두 supportive document를 늘릴수록 성능이 좋아지는 것을 확인할 수 있습니다.
Extractive approach들은 supportive document가 10-20개 사이에서 성능이 수렴하지만, 생성기반의 seq2seq들은 다양한 supportive document을 더 잘 활용하는 것을 알 수 있습니다.
Impact of training passages
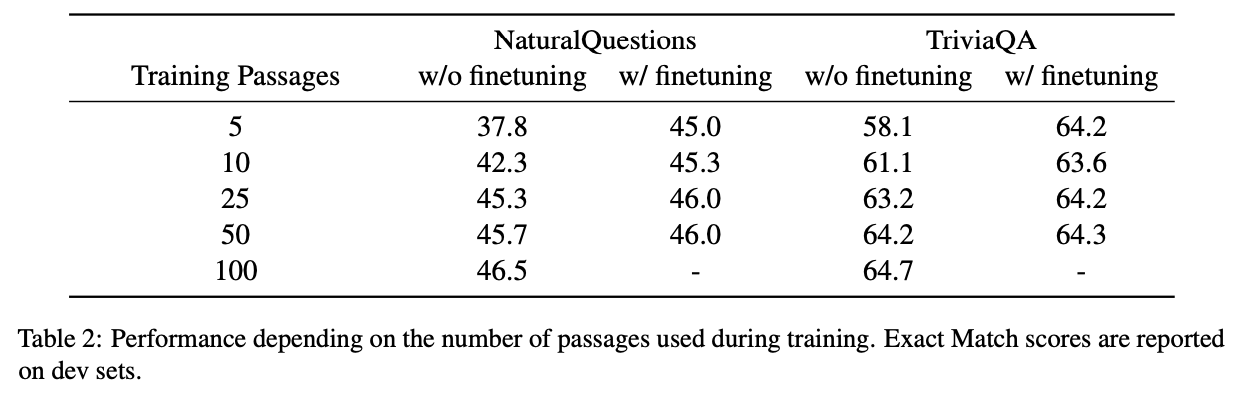
계산적인 비용문제를 완화하기 위해 Training시에는 적은 document들(5,10,25,50,100)로 학습하고 Testing시에는 100개의 supportive document로 평가를 해보았으나 성능이 크게 하락하는 것을 확인하였습니다.
하지만 적은 document들(5,10,25,50,100)로 학습한 모델들에 1000step동안 100개의 supportive document로 fine-tuning한 경우 상당한 성능 향상을 보여, 10K의 gradient step으로 학습한 모델의 성능과 비슷한 수준을 보여 효율적인 학습 방법을 제안합니다.
