Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
이번에 발표할 논문은 2020 NIPS에 발표된 'Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks'로 pre-training으로 미처 parameterize하지 못한 외부의 지식들을 활용할 수 있는 general한 seq2seq 구조를 제안한 논문입니다.
0. Prerequisite
본격적인 리뷰에 앞서 논문에 대한 원활한 이해를 위해 자주 쓰이는 용어를 아래에 정리해 두었습니다.
(제가 이해한 바를 바탕으로 작성하였으니, 가볍게 참고만 해주시면 감사하겠습니다.)
- Parameterizing : 모델의 가중치에 지식을 주입하는 과정입니다. 우리가 다양한 목적함수를 바탕으로 Large Model을 Pre-training하는 이유가 결국 knowledge를 parameterizing하기 위함이라고 볼 수 있죠.
- Knowledge Intensive Tasks : 사람조차도 외부지식 (ex. 위키피디아 검색) 없이 해결하기 어려운 문제를 일컫습니다. 즉 모델의 관점에서 보면, parameterized되지 못한 외부 지식이 필요한 문제입니다.
- MIPS : Maximum Inner Product Search의 약어로, 우리에게 vector space에 mapping된 query 가 있고 여러 외부 정보들 가 있다고 가정할 때 query 와 내적(or 코사인 유사도)가 높은 외부 정보들 를 찾는 과정을 의미합니다. 최근의 Facebook의 FAISS가 이를 빠르게 구현해놓은 좋은 라이브러리로 각광받고 있습니다.
1. Introduction
기존 PLM 모델들이 다양한 목적함수를 활용해 데이터에 내포된 지식 지식을 학습하는데에는 뛰어난 성과를 보였으나, 기사의 정정보도와 같이 새로운 사실을 바탕으로 모델이 학습한 지식을 수정하거나 확장하는 일은 여전히 해결해야할 문제점으로 남아있습니다.
일반적으로 이를 해결하기 위해 연구자들은 전체 framework를 parametric memory (=PLM Model)과 non-parametric memory (=retrieval-based)로 나누어서 설계해 위에 언급한 문제들에 대처하려고 하였죠.
하지만 기존의 방법들(REALM, ORQA)은 open-domain extractive question answering에서만 국한적으로 활용되어 왔기에, 본 연구자들은 이러한 접근법을 일반적으로 활용할 수 있는 framework를 제시합니다.
저자들이 제시한 framework를 QA System으로 한정지어 예시를 들어보면, 우선 question을 BERT에 태운 후 [CLS] Token을 빼와서 query vectory를 만든 후, wikipedia 각 document 역시 BERT(question encoding한 BERT와 다른 객체)를 태워 [CLS] Token을 빼와서 DB를 구축합니다. 다음, query vectory와 가장 유사한 (=내적 값이 큰) k개의 document vector에 해당하는 문서를 retrieve 합니다. 마지막으로 retrieved된 document와 question을 concat해 seq2seq의 encoder 입력에 넣은 후 answer을 decoder에서 generate하도록 훈련합니다.
자세한 모델의 구조는 다음절에서 설명하도록 하겠습니다.
2. Method
페이스북에서 제공한 RAG의 전체적인 학습방법은 다음과 같습니다.
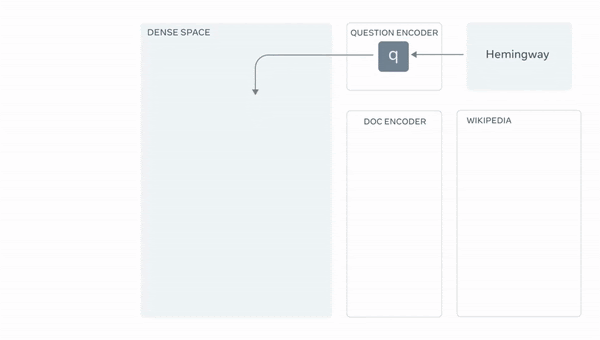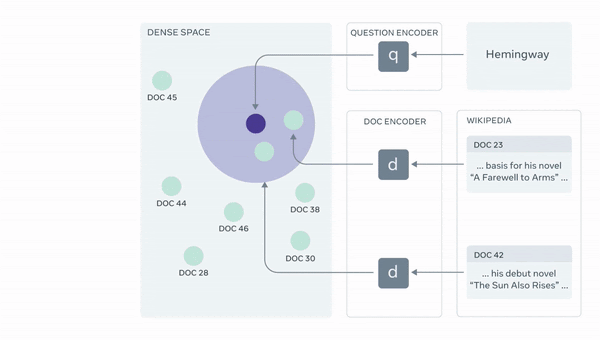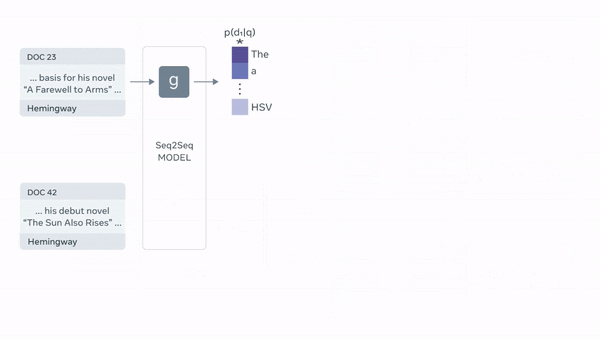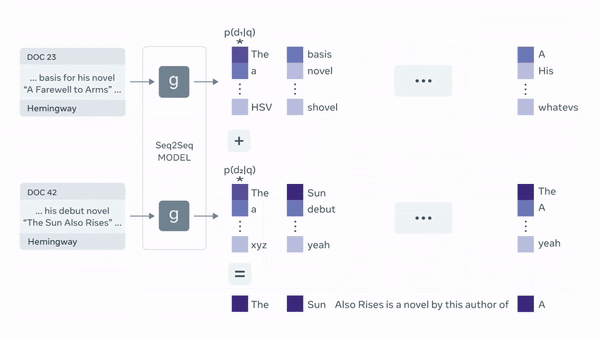
아래는 RAG의 전반적인 구조를 보여줍니다.
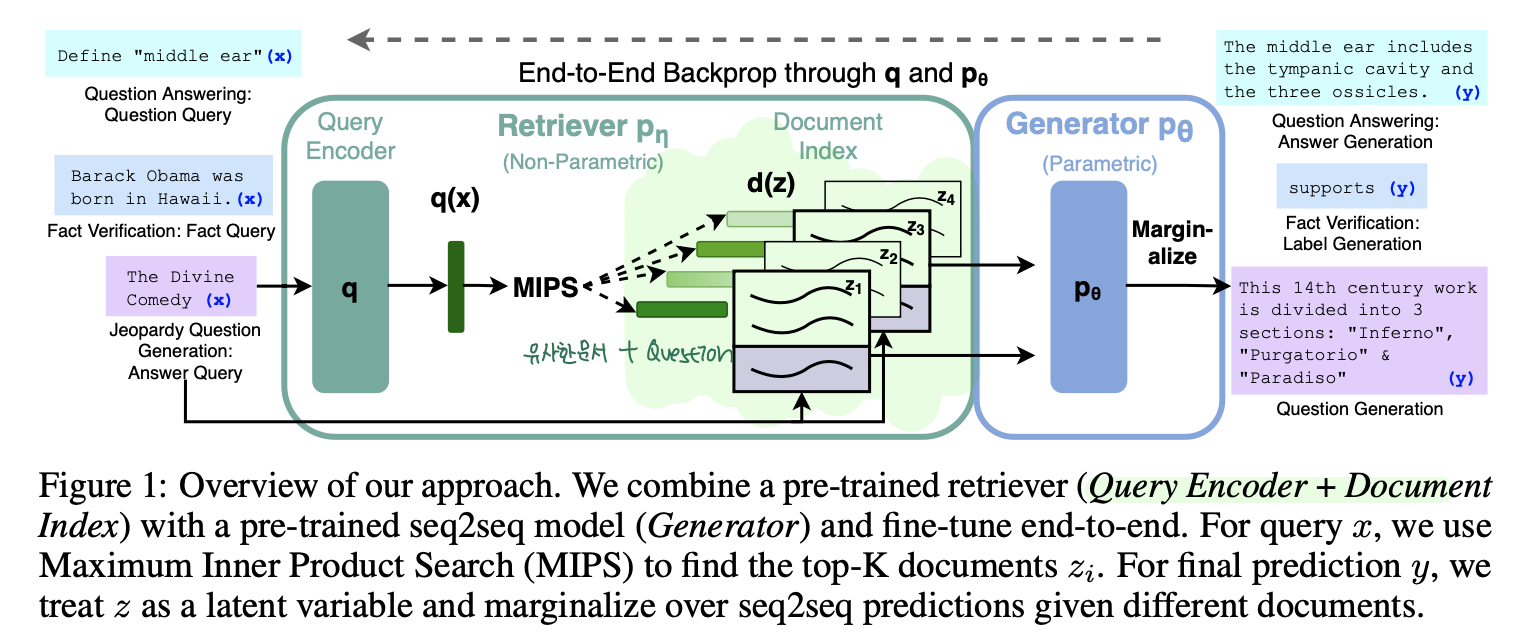
앞서 언급드린거처럼 RAG는 크게 2가지 모델로 나누어집니다.
1. Retriever : question 를 기반으로 유사한 document 를 retrieve하는 모델 (=)
2. Seq2Seq Generator : Retriever가 반환한 유사한 document 와 question 를encoder에 넣고 decoder에서 answer 를 generate 하는 모델 (=)
여기서 의문이 드실텐데요, 아까 분명히 K개의 유사한 document들을 가져와서 answer를 generate하는데 활용한다고 했는데 이 K개를 어떠한 식으로 concat하는가? 일 것입니다.
저자들은 이를 2가지 방법으로 나누어서 제안합니다. (위 그림의 파란색 부분의 marginalize가 해당 부분을 명시합니다.)

2.1 Models
2.1.1 RAG-Sequence Model
맨 처음에 question vector 와 유사한 document를 뽑고 각 document 1개랑 question vector 를 concat시켜서 총 K개의 forwarding을 진행한 후 이를 marginalize하는 방법입니다. 수식의 오른편을 보면 하나의 유사한 document 에 대해서 answer y를 generate한 후 그 document와 question의 유사도인 와 곱한 후 이를 모든 documents에 대해서 marginalize해 가중 평균하는 구조이죠.
2.1.2 RAG-Token Model
이번에는 매 target token마다 다른 document를 retreive하면서 answer를 생성하는 방법입니다. 수식의 오른편을 보시면 매 time-step마다 유사한 K개의 document가 각각 question vector 와 concat해서 output token 에 대한 확률을 계산하고 마찬가지로 document와 question의 유사도인 와 곱하면서 marginalize해 가중 평균하는 구조입니다.

2.2 Retriever: DPR
Retrievers는 상당히 직관적입니다. 이전에 설명드린것처럼 question과 document를 서로 다른 BERT를 통과해 [CLS] Token을 계산한 후 내적을 통해 유사도를 구하는 모델입니다. 저자들은 이미 wikipedia document로 pre-trained된 모델을 활용했다고 하며, 각각 document index를 non-parametric memory로 지정하였습니다.
2.3 Generator: BART
Generator로는 BART-large를 활용했고, 이전에 언급한 것처럼 [document;question]식으로 concat된 encoder input을 만들어 answer를 generate 하였습니다.
2.4 Training
저자들은 매 question마다 유사한 K개의 document에 대한 정답 label 없이 훈련을 진행하였고, DPR의 경우 question을 encoding하는 BERT만 gradient를 흘리고 document를 encoding하는 BERT는 학습하지 않았습니다.

2.5 Decoding
2.5.2 RAG-Token Model
Token 별로 새로운 document를 condition해주는 모델인 RAG-Token Model은 기존의 beam-search를 그대로 활용해주어도 됩니다. 왜냐하면 어짜피 각 hypothesis가 이미 이전 time-step까지 도출해낸 text-sequence는 주어져 있고, 와 새롭게 retrieve된 document 와 함께 다음 time-step의 vocab distribution을 계산하는 것은 추가적인 input만 생길 뿐, 기존의 beam-search에서 벗어나는게 없기 때문입니다.
2.5.2 RAG-Sequence Model
문제는 RAG-Sequence Model입니다. 애초에 answer을 generate할 때 하나의 document 은 서로 다른 answer을 generate할 것이기 때문에 기존의 beam-search에서 이를 marginalize하기는 불가능합니다. 따라서 저자들은 우선은 각각의 document 에 대해서 beam-search를 진행하고, 모든 document 가 공통된 beam을 갖도록 각 document 에 등장한 beam에 대해서 추가적인 forward pass를 진행해주고, 이를 와 곱하면서 marginalize해준다고 하였습니다. 하지만 이렇게 계산해줄 경우, 각 document별로 수많은 beam을 generate하는 forward pass를 진행해주어야 함으로, 저자들은 애초에 question 와 document 에서 등장하지 않는 beam은 전부 등장확률을 0으로 지정했다고 합니다. (저도 마지막 부분은 아직 명확하지 않아 추후에 이해가 되면 수정하도록 하겠습니다.)
3. Experiments and Results
3.1 Open-domain Question Answering
Open domain QA는 다양한 주제에 대한 대량의 문서 집합으로부터 질문에 대한 답을 해주는 문제입니다. (여기서 해준다고 표기한 이유는 문서를 기반으로 정답을 생성할 수도 있고, 문서 집합에서 정답을 추출할 수도 있기 때문입니다.) 저자들은 retrieval과 extractive system에만 의존하는 non-parametric model과 외부 정보 없이 parameter에만 의존해 정답을 생성하는 pure parametric model과의 비교 실험을 진행했습니다. (사실상 둘다 쓴 RAG가 성능이 잘 나오는 것은 당연한거 아닌가..?) 총 4개의 데이터셋에 대해서 실험을 진행했는데, SOTA를 거의 갈아 치웠습니다.
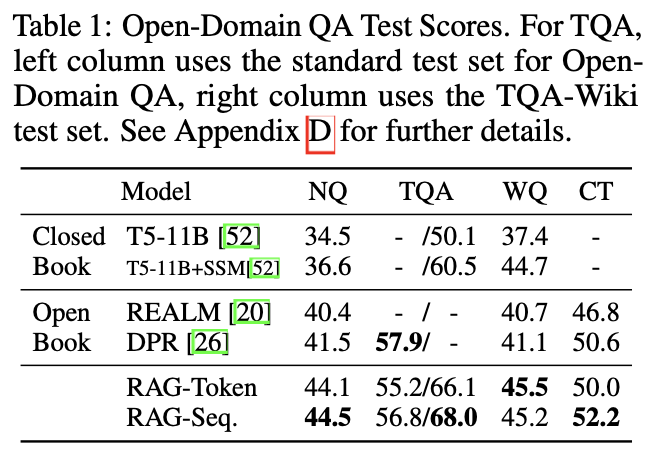
저자들은 본인들의 방법이 추출된 document들에 질문에 대한 힌트는 있지만 말그대로의 정답 (=verbatim)은 없는 경우, retrieve된 여러 문서들과 질문을 기반으로 답변을 생성하는 RAG가 상대적으로 좋은 성능을 보인다고 합니다.
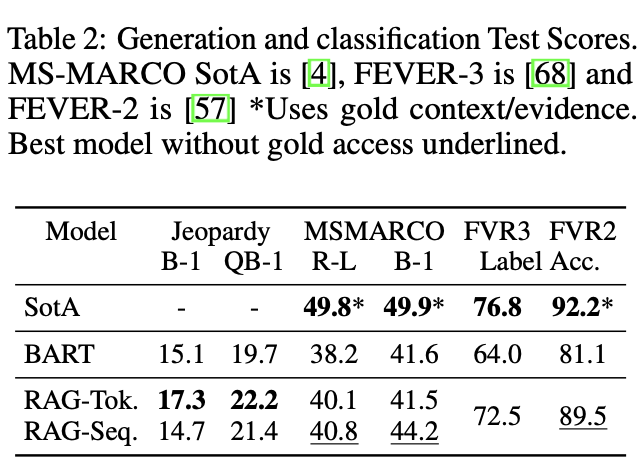
3.2 Abstractive Question Answering
위의 open domain 문제는 extract 기반의 정답 생성 모델이기에 저자들은 free form 형태의 QA로 RAG의 성능을 측정하고자 했습니다. MSMARCO NLG task v2.1를 활용하였는데, 이 문제는 Question과 Question을 검색 엔진에 검색했을 때 나오는 10개의 golden passage, 그리고 이를 바탕으로 생성한 full sentence answer로 구성되어 있습니다. 저자들은 golden passage를 활용하지 않았는데, 이럴 경우 자신들이 활용하는 DB인 위키피디아만으로는 question에 대한 정확한 답을 추출할 수 없는 문제도 있기에 이때 RAG의 parametric한 모델에 성능을 기대한다고 글을 작성하였습니다. 실제로 실험 결과, golden passage에 의존하지 않는 RAG가 SOTA를 달성했다고 합니다.
3.3 Jeopardy Question Generation
Jeopardy Quesion Generation은 주어진 정답 entity를 가지고 그 정답에 상응하는 질문을 만드는 문제입니다. 예를 들어,
- Answer - "The World Cup"
- Question - "In 1986 Mexico scored as the first country to host this international sports competition twice."
의 Pair에서 Question을 생성해야 함으로 굉장히 까다로운 문제입니다.
저자들은 matching entity에 더 높은 가중치를 주어 BLEU보다 Question Generation에서 인간과의 더 높은 상관관계를 보이는 측정지표인 Q-BLEU-1과 인간을 통해 Faculty(실제 외부 사실을 바탕으로 생성된 질문이 사실인지를 평가)와 Specificity(Answer와 생성된 Question간의 상호 의존성을 평가)를 평가했다고 합니다.

3.4 Fact Verfication
Fever라는 데이터셋은 자연어 claim에 대해서 위키피디아에서 적절한 문서를 가져와 해당 claim이 supported되는지, refuted되는지, 아니면 위키피디아에 충분한 정보가 없는지 판별하는 문제입니ㅏ다. 이 문제는 상당한 수준의 기계추론을 요구합니다. 왜냐하면 1) claim에 대응하는 적절한 문서를 위키피디아에서 retrieve 해야하고, 2) retrieve된 문서를 바탕으로 정확하게 claim에 대한 추론을 해야하기 때문입니다. 저자들은 real-world에서는 어떤 claim이 주어졌을때 어떤 문서가 이와 관련 있는지에 대한 정보가 없기 때문에 retrieve 문서에 대한 supervise learning은 진행하지 않고, 학습을 진행했다고 합니다. SOTA모델들은 FEVER을 위해 특화된 구조를 가지고 있지만, RAG는 범용성 높은 구조로 괄목할만한 성능을 보여주었습니다.
4. Additional Results
Retrieval Ablations
저자들은 RAG가 가진 neural retrieval mechanism이 아닌, overlap 기반의 BM25 retrieval, freezed neural retrieval로 ab test를 진행하였습니다.
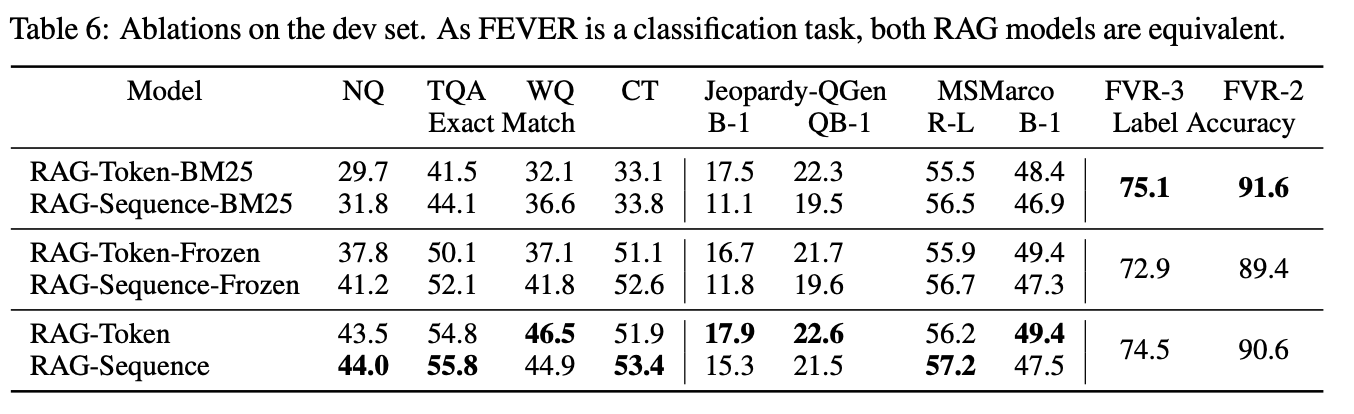
Fever의 경우, 특정 entity가 claim을 평가하는데 중요한 역할을 하여 overlap 기반의 retrieval이 성능이 높았지만 open domian QA의 경우 학습하는 neural retrieval의 성능이 높은 것을 확인할 수 있습니다.
Effect of Retrieving more documents
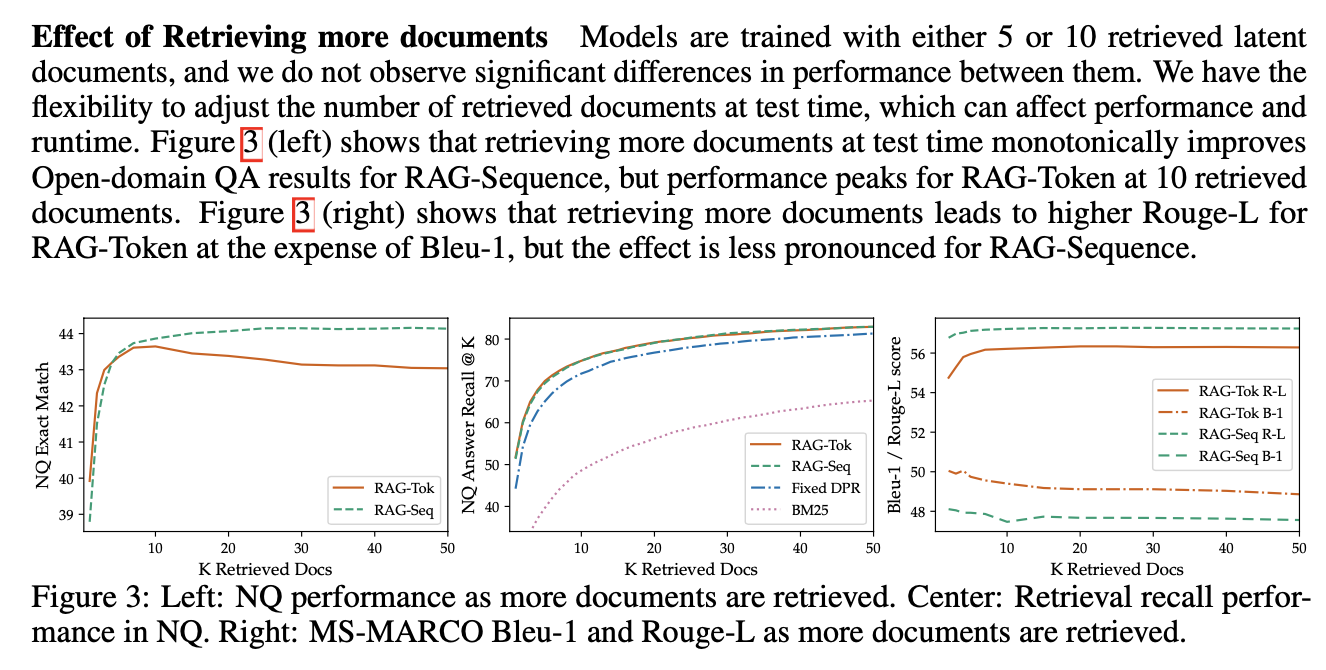
Ab test를 통해 항상 더 많은 document들을 retrieve할수록 성능이 향상되지 않음을 보였습니다.
